こんにちは、hachi8833です。Ruby 2.4.1リリースおめでとうございます。

多くの修正・変更点の中から、私にとって関心の高い非包含演算子を取り急ぎチェックしてみました。結構奥が深そうなので、何かわかったら別途記事にするかもしれません。
「特定の文字列を含まない文字列にマッチする」なんて夢のようじゃありませんか。
参考情報
- 公式ニュース: Ruby 2.4.1 Released
- 2.4.0以降のコミット: Comparing changes
公式のコミットはmergeばかり並んでいて読みづらいので、RubyFlowの速報も参照しました。
Ruby 2.4.1 Onigmoアップデートで非包含演算子が導入
Rubyの正規表現エンジンとしておなじみのOnigmoはRubyとは独立してメンテされていますが、6.0.0から6.1.1へのアップデートにともない、ある意味で正規表現の掟破りとも言えるabsent absence operator(非包含演算子)が導入されました。

#82では、田中哲(akr@fsij.org)さんのスライド「正規表現における非包含オペレータの提案」が参考として挙げられています。私の理解では、1.現実の文字セットが有限であり、2.必ず補集合を取れる、ということがこの演算子が成立する根拠であるようです。
非包含演算子のコードを読むのは今夜の楽しみに取っておきますが、Onigmoの非包含演算子(?~正規表現)は同等の既存の正規表現をエイリアスしたものを組み立てて使っているのではないかと現時点で仮説を立てています(追記: 実装はそのようにはなっていませんでした)。
Onigmoの非包含演算子の使い方
上のスライドでは!(正規表現)という演算子を用いていますが、Onigmoでは(?~正規表現)というlook ahead/behind風の演算子表記を採用しています。
以下はスライドを大急ぎで読んだだけで動かして確認した動作なのでご了承ください。実際にはnilが出力されていますが、コード内の出力結果からは取り除いてあります。
# 非包含演算子なしで普通に書いた場合
puts "/*コメントコメント*/".match(/\/\*[\p{L}\p{P}]+\*\//) #=> /*コメントコメント*/
puts "/*コメント*/コメント*/".match(/\/\*[\p{L}\p{P}]+\*\//) #=> /*コメント*/コメント*/
# 非包含演算子を使った場合
puts "/*コメントコメント*/".match(/\/\*(?~\*\/)\*\//) #=> /*コメントコメント*/
puts "/*コメント*/コメント*/".match(/\/\*(?~\*\/)\*\//) #=> /*コメント*/
非包含演算子なら"/*コメント*/コメント*/"の場合でも見事に"/*コメント*/"にマッチしています。

なお、最初の2つの正規表現にある[\p{L}\p{P}]+は、.+と似たようなものでして、単なる私の趣味の反映です。私は宗教上の理由から.+や.*のような雑なマッチが嫌いなだけなので、皆さまは.+とか.*を存分にお使いいただいてかまいません。
非包含演算子の中の正規表現は順序が保たれる
上の例では文字クラスによるマッチを使いましたが、非包含演算子のもっともありがたいところは「中に書いた文字列の順序を保って否定マッチできる」という点でしょう。多くの開発者がときたま発作的に欲しくてたまらなくなる「"○☓"という文字列を含まない文字列にマッチする」正規表現を素直に書けるようになります。
puts "うらにはにわにわにはにわにわとりがいる".match(/(?~にわにはにわ)/)
#=> うらにはにわにわにはに
puts "うらにはにわにわにはにわにわとりがいる".match(/(?~にわにわにわ)/)
#=> うらにはにわにわにはにわにわとりがいる
上の例では対象に"にわにはにわ"が含まれているので、マッチは"うらにはにわにわにはに"で止まります(後述)。
"にわにわにわ"は対象に含まれていないので、"うらにはにわにわにはにわにわとりがいる"全体にマッチします。

否定条件を文字クラスの否定[^文字集合]で表すと文字の順序を指定できないので、非包含演算子(?~)なしでこういうマッチを書くのは一苦労です。
否定のlook ahead(?!なんちゃら)や否定のlook behind(?<!なんちゃら)を使って工夫すれば部分的には同じことはできますが、非包含演算子(?~)ならまったく素直に書けます。
(?~)に*や+は不要
非包含演算子(?~)は、それ自体がquantifier(量指定子・量化子)を兼ねているので、*とか+などを後ろに付ける必要はありません。非包含演算子は文字クラスではありません(と思う)ので、うっかり.*や.+を付けると事故るかもしれません。
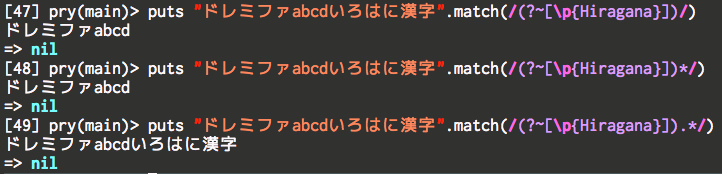
puts "ドレミファabcdいろはに漢字".match(/(?~[\p{Hiragana}])/) #=> ドレミファabcd
puts "ドレミファabcdいろはに漢字".match(/(?~[\p{Hiragana}])*/) #=> ドレミファabcd
puts "ドレミファabcdいろはに漢字".match(/(?~[\p{Hiragana}]).*/) #=> ドレミファabcdいろはに漢字
私の推測ですが、!(正規表現)だと*や+をつい付けて事故る人が続出しかねないので、quantifierを付けないのが普通のlook ahead/behindに似た書式を採用したのではないでしょうか。こういうデザインって大事だと思います。
追記: 表記の由来
Onigmoの中の人による記事「鬼雲に非包含オペレータを実装した話」によると、「Perl の流れをくむ正規表現では、文法を拡張する際には、\ + アルファベット 1 文字 あるいは、(?...) 形式のいずれかを使うことになっています」だそうです。
(?~)は全範囲の「除外」ではない
非包含演算子(?~)は、条件を満たさない文字に突き当たったらそこで終わって後続の正規表現に処理を譲ります。
ii = "ドレミファabcdいろはに漢字".match(/(?~[a-z])/) #=> ドレミファ

非包含演算子(?~)は最長一致的にはマッチしませんので、単体では対象の全範囲から「除外」した文字列とマッチするわけではありません。
上の例の場合、abcdを取り除いた"ドレミファいろはに漢字"にはなりません。
マッチした文字列をさらに取り出したい場合には注意しましょう。
「除外」した文字列が欲しい場合は、マッチした後に#gsubで削除するなどした方が早いと思います。
注意: 「ある文字列を含まないかどうか」という存在チェックは別物として考えよう
正規表現に限らず、否定表現はどうしてもややこしくなってしまいます。私も危うく思い違いしてしまうところでしたが、非包含演算子(?~)は「ある文字列を含まないかどうか」という存在チェックに直接単独では使わない方がよいと思います。
以下を実行してみると、どちらもtrueになります。すわバグか?と思いがちですが、これは正常な動作です。
"うらにはにわにわにはにわにわとりがいる".match?(/(?~でも)/) #=> true
"うらにはにわにわにはにわにわとりがいる".match?(/(?~には)/) #=> true
なぜなら、どちらにも「"には"を含まない部分文字列」があるからです。なかなか巧妙な罠です。
- 「途中にxxという部分文字列を含まない文字列があるかどうか」をチェックするには、以下に追記したように
#match?で他の正規表現の間にサンドイッチしましょう。 - 単に「xxという文字列を含まない場合は
true、含む場合はfalse」という結果が欲しい場合は、非包含演算子を単独で使わずに、普通に#matchで取って結果を!で反転させる方がコードとしても読みやすいと思います。
追伸: 実用的な非包含演算子の利用例
Onigmoの中の人から「非包含演算子を単独で使うのはあんまりよくないかも」と教えていただきました。
確かに、実用上も他の正規表現の間に非包含演算子をサンドイッチするのが普通だと思います。本記事の上の例ではたまたま単独利用ばかりでしたので、実用的な例も貼っておきます。
puts "うらにはにわにわにはにわにわとりがいる".match(/にわ(?~には)にわ/)
#=> にわにわ
puts "うらにはにわにわにはにわにわとりがいる".match?(/にわ(?~には)にわ/)
#=> true
ありがとうございます!
取り急ぎまとめ
非包含演算子、取扱いに注意は必要だと思いますが素晴らしいです。
オートマトン的にはいろいろあるのかもしれませんが、否定的な正規表現マッチを素直に書けるというのは大変なメリットです。その場限りのオレオレハックではなく、理論上のバックグラウンドがあるのも頼もしい点です。
linuxコマンドのgrepなどであれば-vオプションで簡単に否定マッチを実現できますが、コード中で否定正規表現をまともに書こうとすると大変な苦しみを味わうことになりがちでした。
今回パフォーマンス面はまったくチェックしていませんが、効率はそれほど高くないであろうことはうっすら予測できます(追記: 中の人も同意見でした)。新機能なのでまだバグが潜んでいるかもしれません。正規表現ライブラリのテストであらゆるパターンを網羅するのはものすごく大変です。
そういうわけで、非包含演算子はここぞというときにだけ、控えめに使うのがよいと思います。
ちょっと引っかかるのは、需要はかなりあるにもかかわらず非包含演算子がこれまで一般の正規表現に実装されてこなかった点です。もっと早く登場してもよさそうなものですが、もしかするとパフォーマンス以外にもまだ何か難点が潜んでいるのかもしれません。
私は別のやむを得ない理由から、非包含演算子(?~)がPCREレベルに普及するまで使うことはないと思いますが、忙しいときに「これさえあればもっと楽に書けるのに」と多くの開発者が待ち望んでいた非包含演算子がいち早くRuby 2.4.1で使えるようになったことがうれしくて仕方ありません。
お疲れさまでした!
参考記事
- 鬼雲に非包含オペレータを実装した話 -- Onigmoの中の人の記事です
- The New ‘Absent Operator’ in Ruby’s Regular Expressions -- 本記事よりわずかに早く出た非包含演算子についての記事です
関連記事
- [連載:正規表現] Unicode文字プロパティについて(1)
- [連載:正規表現] Unicode文字プロパティについて(2) — Pの一族
- [連載:正規表現] Unicode文字プロパティについて(3) 文字プロパティとは
- [連載:正規表現] Unicode文字プロパティについて(4) 勉強会資料