Rails: テストスイートとCIの実行時間を半分に削減するテクニック集(翻訳)
はじめに
私たちEvil Martiansは、顧客であるWhop様のテストスイート実行時間を半分に削減いたしました。本記事では、「隠れたロガーをプロファイリングで見つけ出す」「factoryのオーバーヘッドを削減」「よりスマートなパラレル化手法への切り替え」、そしてその作業で明らかになった不安定なテストの修正方法について解説します。
🔗 パート1: プロファイリング探偵が決定的証拠を押さえた瞬間
遅いテストスイートを修正するには、テストのどこで実際に時間がかかっているかを把握しなければなりません。推測は時間の無駄であり、プロファイリングこそが決め手です。今回の調査では、お馴染みTestProfに加えて、TestProfとシームレスに統合できる強力なサンプリングプロファイラであるStackProfを用いています。


🔗 調査
テスト実行の内幕を最初に確認するため、ランダムなサンプル200件を指定してプロファイリングを実行する以下のコマンドを実行しました。
TEST_STACK_PROF=1 SAMPLE=200 bundle exec rspec spec
ここではサンプリング数を指定することが重要です。テストが数千件にものぼるスイート全体を実行していると、意味のない巨大データが生成されてしまいます。
上のコマンドを実行すると、tmp/test-prof/ディレクトリにstack-prof-report-wall-raw-total.jsonファイルが生成されます。このファイルは、ブラウザで無料の素晴らしいツールであるspeedscope.appからも開けます。
Evil Martiansは、クリエータ向けのマーケットプレースプラットフォームであるWhop様の重大なパフォーマンス問題の解決に取り組みました。私たちはデータの非正規化戦略を実装し、evil-seedツールを用いてデータシード用ソリューションを開発し、同社の開発エクスペリエンスを強化したことで、同社の急速な成長をサポートいたしました。
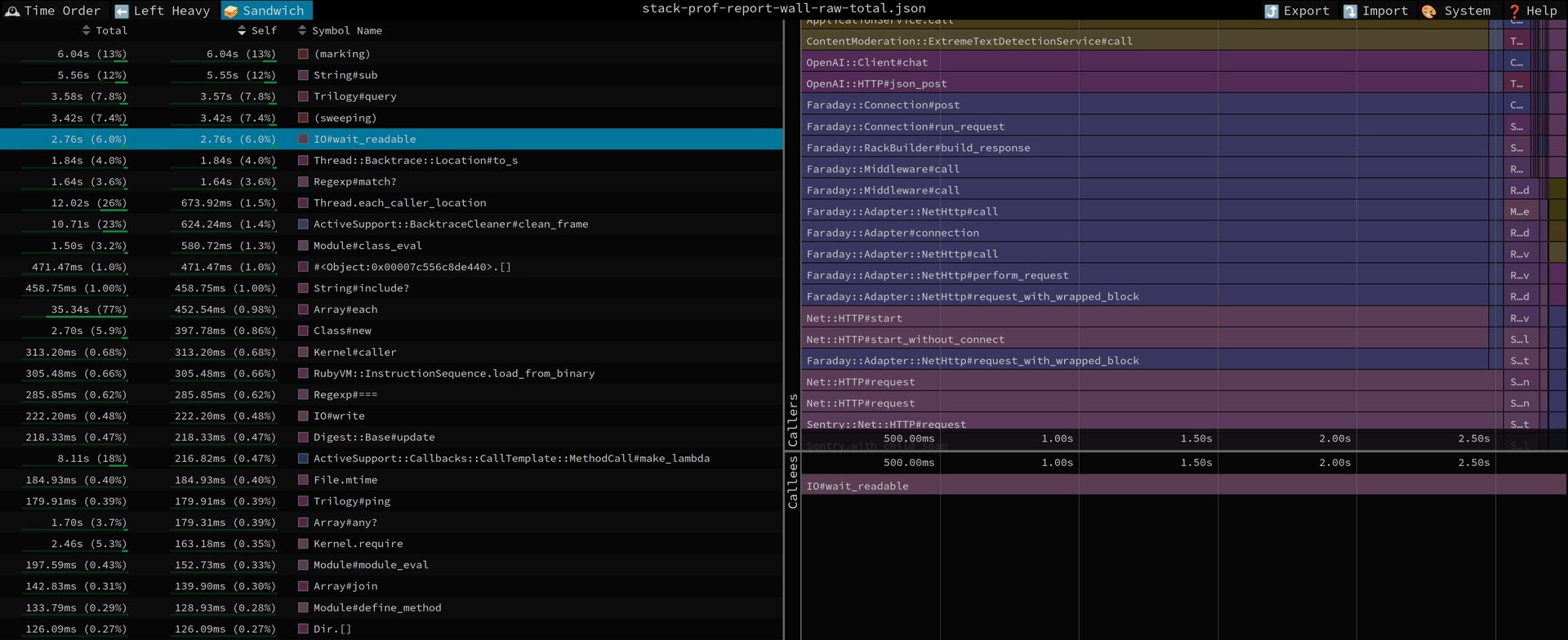
speedscope.appの「サンドイッチ」ビューが最も多くの知見を提供します。このビューには、メソッドのリストが「メソッド内(およびそこで呼び出された別メソッド)で消費した合計時間」の順に表示されます。
最初のプロファイリングで、早速数人の容疑者が絞り込まれました。
- データベース処理(
Trilogy#query)が重いことから、factoryやクエリが多数あることが考えられる - StripeやOpenAIなど、モックすべき外部サービス呼び出しがある
- 最も興味深い点: ログ出力にかなりの時間が費やされている
🔗 隠れたロガーを発見
test環境でのログ出力は、ほぼ確実にオーバーヘッドにしかなりません。StakProfのレポートでは、ロガー関連のアクティビティの多さが指摘されており、主犯はRails自身の冗長なSQLログ出力に潜んでいることが判明しました。
それによると、ありとあらゆるデータベースクエリがせっせとディスクに書き込まれていたのです。このような細かなログは開発中のデバッグには便利ですが、テスト実行時に数千件のクエリが含まれているとI/Oボトルネックが莫大になります。
このログ出力機能を無効にすることで、プロジェクト全体で最大のパフォーマンス向上を達成できました。以下のようにconfig/environments/test.rbで手軽に修正できます。
# config/environments/test.rb
# この2つの設定が速度低下の主因だった
config.active_record.verbose_query_logs = false
config.active_record.query_log_tags_enabled = false
# ついでにログレベルを引き上げてI/Oを削減した
config.log_level = :fatal
しかし調査中に、他にも小さなログ発生源が存在することに気づきました。
Sentryのメインgemをtest環境で無効にしていたにもかかわらず、Sentryのカスタムロガーapp/services/sentry_log.rbが有効なままだったのです。
第2のオーバーヘッドを解消するため、Sidekiq::Testing.fake!を参考にして、テスト中にSentryを完全に無効にするメソッドを実装しました。
# spec/rails_helper.rb
RSpec.configure do |config|
config.before(:suite) do
# ... その他のセットアップ
Sentry::Testing.fake!
end
end
🔗 2倍のスピードアップを達成
これらの修正は、たちまち驚くべき効果を発揮しました。テスト時間全体が半分にまで削減されたのです。
単一プロセス実行:
- 修正前
- 最大25分
- 修正後
- 最大12分
CI実行(16プロセスによるパラレル化)
- 修正前
- 最大4分
- 修正後
- 最大2分
冗長なクエリログを無効にするだけで多大な効果が得られ、Sentry周りを最適化したことでさらに効果が得られました。主にActive Recordが発するログ出力のノイズを排除したことで、テスト速度が2倍になりました。
最大のボトルネックを解消できたので、次はもっと小さな勝利を重ねていくことにします。
🔗 パート2: factoryという猛獣を飼いならす
ログ出力モンスターを退治したので、すぐに予測のつく第2の犯人像がプロファイリングで浮かび上がってきました。すなわちオブジェクト生成です。
Railsテストスイートでオブジェクトが生成される場合、そのほとんどはFactoryBotによるものです。ここでの目標は、テストのたびに生成される、高コストなデータベースレコード件数を削減することです。

🔗 TagProfで俯瞰的な情報を得る
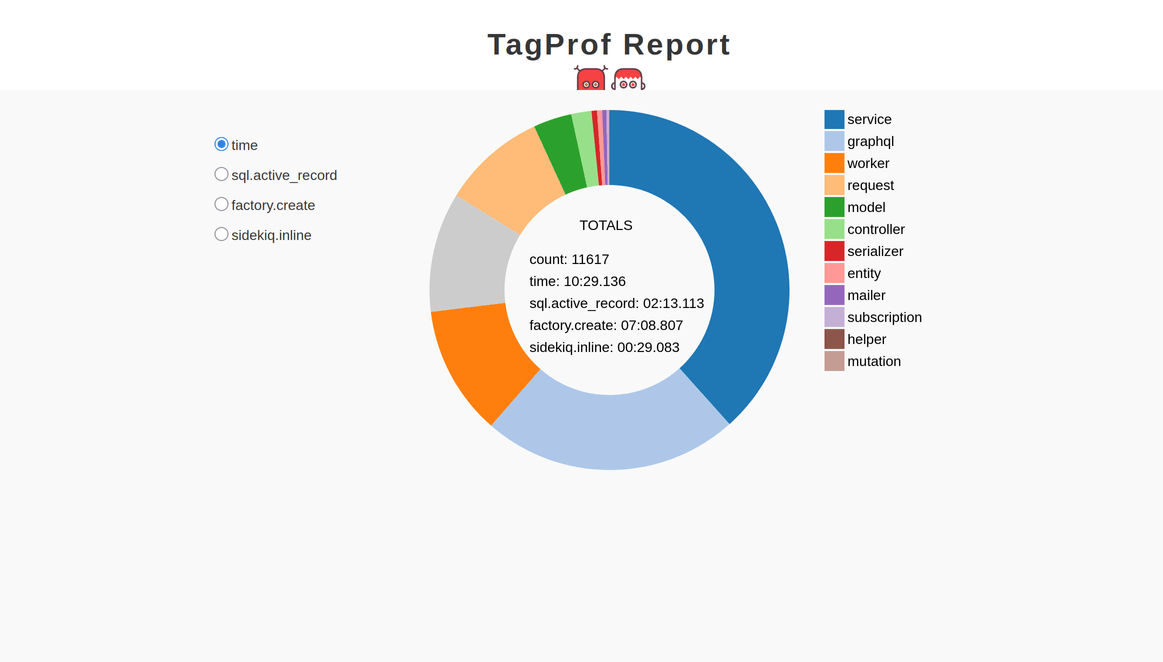
まずは容疑の裏付けを取る必要があります。TestProfのTagProfはこの種のタスクにうってつけです。TagProfはデータを「タグ付け」する形でグループ化し、どのイベント種別が最もコスト高であるかを把握できるようにします。
ここでは監視対象を「Active Recordクエリ」「factory作成」「Sidekiqジョブ」にするよう設定します。
TAG_PROF_FORMAT=html TAG_PROF=type
TAG_PROF_EVENT=sql.active_record,factory.create,sidekiq.inline
bundle exec rspec
これによって出力されるHTMLレポートは、factory.createイベントがテスト実行時間の半分以上を占めていることを明確に示しています。
🔗 戦略1: let_it_beヘルパーを使う
テストでは、あるグループ内のすべてのexampleに対して同じ基本データを作成するパターンがよく使われます。
TestProfのlet_it_beはそのためのソリューションです。RSpec標準のletと異なり、let_it_beはdescribeブロック全体で1度だけレコードを作成し、それをすべてのexampleで使いまわします。
let_it_beは強力なツールですが、万能ではないことにご注意ください。テストの中でステートが改変されるオブジェクトには使わないよう注意が必要です。さもないと、ステートが次のテストに「漏洩」して、テスト結果が不安定になる可能性があります。
🔗 戦略2: FactoryDefaultを使う
第2の問題は、冗長な関連付けが作成されるという、より微妙な問題です。
あるモデルのfactoryが、関連付けられるモデルを多数トリガーすることがよくあります(あるエクスペリエンスがボットを作成し、そのボットがユーザーを作成するなど)。
このようなケースを特定するために、以前突き止めておいた重いテストファイルに対してFactoryDefaultのプロファイラを利用しました。
FPROF=1 FACTORY_DEFAULT_PROF=1 bundle exec rspec spec/services/some_heavy_spec.rb
上のコマンドで出力される2つの表は、実に便利です。
表その1はFactory associations usageです。これは、他のfactoryの副作用としてどのオブジェクトが作成されているかを示します。
以下の結果から、関連付けのためだけにuser、app、botがそれぞれ20回以上作成されていて、テストが10秒ずつ余計に時間を食っていることがわかります。

表その2は、factory全体の利用状況を示します。ここでは、トップレベル(明示的)の作成と、関連付けを含む「合計」数を区別しています。
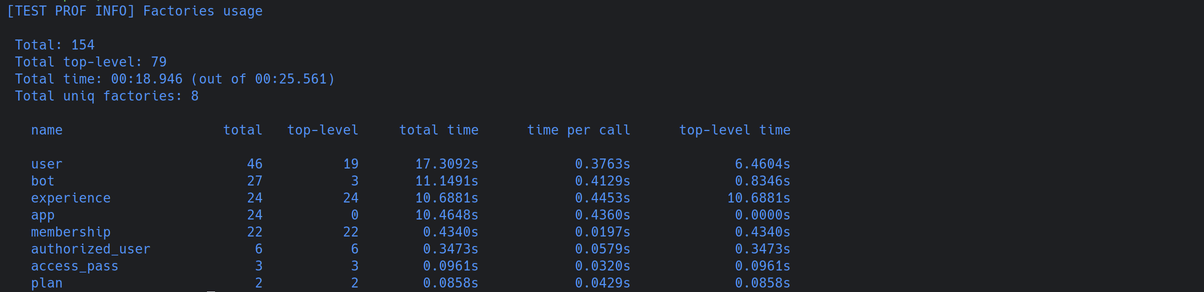
この表のデータから多くのことがわかります。factoryの明示的な(トップレベル)作成が19回であるにもかかわらず、factory全体では46回も作成されています。この差分(暗黙で27回作成されている)は、表その1の関連付けの利用状況と完全に一致しています。
これを修正するには、create_defaultを使います。これにより、利用頻度の高い関連付けのインスタンスを1個作成して、以後のテストの全factoryでもインスタンスを新規生成せずにこのインスタンスを使い回すよう指示します。
# spec/services/some_service_spec.rb
describe "Some Service" do
# :userを必要とする全factoryで、このインスタンスが再利用される
# これにより、毎回インスタンスを新規作成しなくなる
let!(:user) { create_default(:user) }
it "does something with a widget" do
widget = create(:widget) # 暗黙でデフォルトのuserを使う
# ...
end
it "does something with a gadget" do
gadget = create(:gadget) # これも暗黙でデフォルトのuserを使う
# ...
end
end
以下の方法で、最も遅いテストファイルを徹底的に最適化できました。
- 最初に、最も遅いテストを特定する(
rspec --profileやTestProfのTPSProf(time-per-exampleプロファイラ)を利用) - 次に、それらに対して
FactoryDefaultを実行する
ここまで着実に進捗を出していますが、そろそろ収穫逓減の限界に近づきつつあります。ここからパフォーマンスを飛躍的に高めるためには、個別のテストを高速化するだけではなく、すべてのテストを同時実行することで効率を高める必要があります。
🔗 パート3: パラレルテストの世界に入る
プロファイリング、パッチ適用、最適化を行ったことで、ここまでに2倍の高速化を達成しました。テストスイートは既に高速化しましたが、さらなる高速化は可能であると見込みました。
最後のフロンティアは、真のパラレル化(parallelization)です。
🔗 parallel_testsの限界
多くのRailsプロジェクトと同様、Whopプロジェクトでも由緒正しいparallel_tests gemが使われていました。このgemは実に働き者なのですが、1つ根本的な制約が存在します。すなわち、テストファイルを複数のプロセスに分割する形で実行するという点です。

そのため、あるワーカーが受け取ったグループがたまたま重いfeature specだった場合、そのワーカーは、他の軽い単体テストたちが終了してアイドル状態になった後も長期間処理を続行します。そして全体のビルド時間は、常に最も遅いワーカーによって左右されます。
🔗 より公平なtest-queueモデルへの乗り換え
この問題を解決するため、従来よりずっと効率のよいtest-queueというテスト実行モデルに切り替えることを決定しました。
test-queueモデルでは、従来のようにファイルを事前に割り当てる代わりに、中央キューを作成して、個別のテストexampleをそこにまとめます。あるワーカーのテストが終了したら、そのワーカーは即座に次のテストをキューから取り出します。これにより、すべてのワーカーが最後までビジー状態を維持するようになり、CI実行時間を20〜40秒短縮できるはずです。
🔗 赤い荒海
さて、私たちはtest-queueへの切り替えを実装して変更をpushし、CIパイプラインの実況状況を見守っていました。そして結果は...大混乱でした!
100件以上のテストが失敗し、おかしなエラーがランダムに発生しているらしく、私たちの変更内容の明確な関連は見当たりませんでした。
6) Types::Output::CreatorDashboardTableType ... returns the correct traffic sources Failure/Error: expect(subject["..."]["trafficSource"]).to eq("direct") Expected "whop" to eq "direct".
7) Discovery::FetchContentRewardsCampaigns returns the campaigns ordered newest correctly Failure/Error: expect(result[0].id).to eq(low_paid_campaign.id) Expected 691 to eq 693.
個別のテストは問題なく実行できたのに、ハイコンカレンシーなtest-queue環境下の真にランダムな状態では動かなくなったのです。
私たちは、ランナーを切り替えるだけでは済まなくなり、テストスイートを顕微鏡で1つ1つ丁寧に調べて、背後に潜む依存関係や、テスト間のステートのあらゆる「漏洩」を容赦なく解明しました。
こうして、パフォーマンス追求の旅は、一転してデバッグの旅へと変貌したのです。テストを高速化するには、最初にあらゆるテストを完璧に分離しなければなりませんでした。
不安定なテストという野獣どもを、1匹ずつ確実に仕留めるときがやってきたのです。
🔗 パート4: テストを分離するためのガイド
テストスイートがどんなに高速でも、不安定であっては役に立ちません。test-queueセットアップを導入したことで、長年にわたる隠れたステート漏洩があらわになりました。ここからの仕事は、「不安定さ」という野獣を逃すことなく一匹一匹仕留めて、テストを完璧な形で分離することでした。
ここからは、私たちの猛獣狩りの話が始まります。
🔗 ケーススタディ1: タイムトラベルとタイムパラドックス
私たちの場合、混乱を招く不安定なテストの中で最も多かったものは、ことごとく時間に関係していました。
🔗 グローバルなステート漏洩
当初、dateフィルタに関連するテストが広範囲にわたって失敗していました。その原因はシンプルで、テストでTimecop.freezeを呼んでいたにもかかわらず、Timecop.returnを呼んでいなかったせいでした。つまり、"frozen"状態の時間が、そのワーカーで実行される次のテストに漏洩していたのです。
修正は、rails_helper.rbファイルでグローバルなフェイルセーフ機能を組み込む形で堅実に行いました。
# spec/rails_helper.rb
RSpec.configure do |config|
config.after(:each) do
Timecop.return
end
end
🔗 Doorkeeperで発生する謎のエラー
Timecopのフェイルセーフのおかげで大半のエラーは解消しましたが、最も厄介な謎がまだ残っていました。Doorkeeperを利用しているコントローラのspecで403 Forbiddenエラーがランダムに発生するという問題です。

このステート漏洩の原因を探るべく、RSpecの究極ツールである--bisectオプションを使うことにしました。CI実行に失敗したときにseed番号をこのオプションに与えることで、エラーを再現する最小限のテストシーケンスを自動的に特定できました。
bundle exec rspec spec/controllers --bisect --seed 12345
RSpecはevents_controller_spec.rb内のテストを指していました。根本原因は微妙ですが、パラレルワールドでは致命的です。
パラレルワーカー上で別のテストが有効なDoorkeeperトークンを作成した時点では、トークンはたしかに作成されていました。しかしトークンのバリデーションを行ったときに、他のテストで"frozen"になっていた過去の時間からはトークンが失効しているように見えたため、403エラーが発生していたのです。
修正は驚くほどシンプルでした。そもそも、そのテストのアサーションではTimecop.freezeを呼び出す必要がなかったのです。その行を削除するだけで、テスト失敗の嵐がぴたりと止みました。
🔗 ケーススタディ2: グローバルなステート汚染を浄化する
他のいくつかの問題も、同じようなパターンを辿っていました。つまり、テストによって何らかのグローバルステートが改変され、その後のクリーンアップに失敗するというパターンです。
🔗 1: 定数の競合
2つの異なるテストファイルで、同じ定数名に対して異なる値が定義されていたためにNoMethodErrorが発生していました。定数はグローバルであるため、最後に実行されたものが優先されます。
修正方法: 定数名が各ファイル固有になるようリネーム。
🔗 2: キャッシュや設定の漏洩
PermissionsManagerがロールをメモリ内でグローバルにキャッシュしていたため、テスト同士の間で古いデータが漏洩していました。
修正方法: rails_helper.rbファイルにクリーンアップ用のフックを追加して、実行前に必ずPermissionsManager::SystemRoles.clear_cache!を呼び出すようにした。
🔗 3: gRPCのリセット忘れ
あるspecでグローバルなgRPCを初期化していましたが、その後リセットされていませんでした。
修正方法: 設定をnilにリセットするafterフックを追加。
🔗 4: Sidekiq Enterpriseのunique!モードが漏洩
これは特に興味深いケースでした。
問題は、あるテストでSidekiq Enterpriseのunique!モードの振る舞いを検証しなければならなかったことです。このグローバルな変更が「漏洩」していたことで、まったく無関係なconnected_account_spec.rb内のテストが失敗するようになりました。原因は、エンキューされるはずのジョブがuniquenessロジックで暗黙的にフィルタで除外されていたためでした。
ここでもジレンマに陥りました。Sidekiq Enterpriseの公式ドキュメントでは、この点について明確に警告していて、「困った事態になることを避けるために」テストではuniquenessを無効にするようアドバイスしています。しかしWhopプロジェクトでは、このuniquenessロジックのテストそのものが重要だったので、この警告を単純に無視するわけにはいきませんでした。
修正方法: ここでの課題は、「テスト不可能な」機能をどのように完全に分離した形でテストするかでした。解決方法は、一時的に安全な「サンドボックス」を作成するフックを慎重に作成することでした。
# 公式ドキュメントでは推奨されていないため、「要塞」を構築することにした。
# このフックは、Sidekiq Enterpriseのuniqueジョブ機能を他のテストに漏洩せずに
# テストするための完全なサンドボックスを作成する。
around do |example|
# 1. グローバルなuniqueジョブミドルウェアをオンにする
Sidekiq::Enterprise.unique!
# 2. このunique-enableステートの内部でテストを実行する
example.run
ensure
# 3. 確実にクリーンアップする(テストが失敗した場合であっても)
# 最初にミドルウェアを完全に削除する...
Sidekiq.configure_client do |config|
config.client_middleware do |chain|
chain.remove Sidekiq::Enterprise::Unique::Client
end
end
# 4. ...続いてSidekiqのテストをデフォルトのステートにリセットする
Sidekiq::Testing.fake!
end
ここで鍵となるのは、テストが実行後にクリーンアップを実行することをensureブロックで保証していることです。これは単にテストモードをリセットするだけではなく、unique!によってクライアントのコンフィグに追加された特定のミドルウェアを完全に除去しています。
これにより、インフラストラクチャのロジックを確信を持ってテストできるようになるとともに、テストスイートの他の部分の安定性に一切影響を与えないようになりました。
🔗 より速く、より強く、より優れたテストを目指して
Whopプロジェクトのテストスイートを高速化する取り組みは、「テストを高速化する」というシンプルな目標から始まりました。
私たちはテストスイートを単に高速化しただけではなく、テストの堅牢性と信頼性を高めるとともに、テストの秩序を整えたのです。
当初、隠れたロガーを修正してテストを2倍高速にできたのは大きな成果でしたが、本当の成果は不安定なテストを退治したことで得られたのです。test-queue実行モデルに切り替えたことで、ありとあらゆる抽象化の漏洩やステート依存を克服せざるを得なくなり、その結果、テストスイートは飛躍的に強化されました。
今回のタスクで得られた教訓をいくつか以下にメモしておきます。
- パフォーマンスのボトルネックは、予想通りの場所で見つかることはめったにない。コードを修正するより先に、StackProfなどの信頼できるツールを従前に活用して調査することが大事。
-
factoryは2番目に大きなボトルネックになりがち。
let_it_beやcreate_defaultなどのツールを活用することで、冗長な操作を大幅に削減できる。 -
隠れたI/Oに用心すること。ログ出力はパフォーマンスを低下させることで知られている。Railsのデフォルトのログ出力のみならず、Sentryなどのサードパーティgemがディスクやネットワークにログを書き込んでいる可能性があるかどうかも詳しく調べること。
-
test-queueなどの公平なパラレルランナーは強力な最適化だが、テストスイートにとっては究極のストレステストでもあり、テストのあらゆる不完全な分離が容赦なくあぶり出される。
-
どんなテストでも、テスト後の後処理を怠ってはならない。
rspec --bisectなどのマスターツールを駆使してステートの漏洩を退治し、aroundフックなどの堅牢なパターンを活用して、グローバルステートを変更するテストを封じ込めることが大事。よき市民として、行儀の良いテストを書くこと!
概要
元サイトの許諾を得て翻訳・公開いたします。
日本語タイトルや見出しは内容に即したものにしました。