開発PCのVSCode(Codex)からローカルLLM(Ollama)が動作する別PCに接続して、コーディング支援してもらえるように環境構築できたのでその手順をご紹介したいと思います。
Ollama PCのセットアップ
ローカルLLM PCでOllamaのインストールをしておきます。
使用するモデルはこちらの gpt-oss:120b を使用します。
以下のコマンドでモデルのダウンロードを行います。
ollama pull gpt-oss:120b
必要あればかステムモデルの作成も検討します。
▶手元のカスタムモデルについて(クリックで展開)
※ 場合によってはVSCodeから接続できるようにファイアウォールの設定など別途行う必要があるかもしれません。
VS Code PCのセットアップ
拡張機能のインストール
VS Codeの拡張機能: Codex – OpenAI’s coding agent をインストールする
拡張機能の設定
初期表示ではログインするか API Key を入力するかの画面が表示されます。(この画面からOllamaに接続する設定を行えないため一旦無視します。)

公式サイトのConfiguring Codexを見ると IDE拡張でも使用できる記載があるためこれを使って拡張の設定を進めます。
自分の環境では WSL2(Ubuntu 22.04)に Railsアプリケーションのファイルを配置してVS Codeからアクセスしているため、下記のパスにファイルを格納しています。
- 格納先:~/.codex/config.toml (Codex CLIでも参照してる config.toml の格納先です。)
profile = "gptoss-local"
model = "gpt-oss:120b"
[model_providers.Ollama]
name = "Ollama"
base_url = "http://192.168.10.182:11434/v1" # 別PCのIPアドレスを調べて書き換え
[profiles.gptoss-local]
model_provider = "Ollama"
ファイルを作成するところまでできれば、VSCodeを再起動します。
(参考)公式サイトのAdvanced configurationにOllamaに接続するサンプル等色々な例が掲載されています。
動かしてみる
実際に問い合わせてみる
下の Ask for follow-up changes に問い合わせたい内容を入力して Enterする。
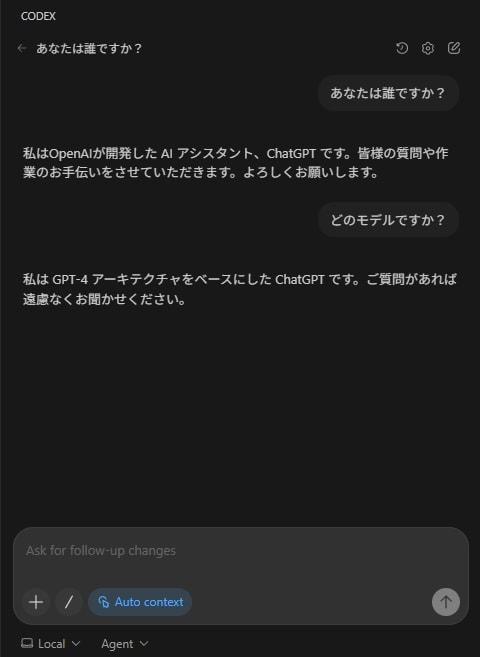
gpt-oss-120b モデルは、単一の80GB GPU で効率的に稼働しながら、コア推論ベンチマークで OpenAI o4-mini とほぼ同等の結果を達成します。
回答内容は正しそうなのでOllamaに接続できてそうですね。
Rubyの簡単なプログラムを作ってもらう
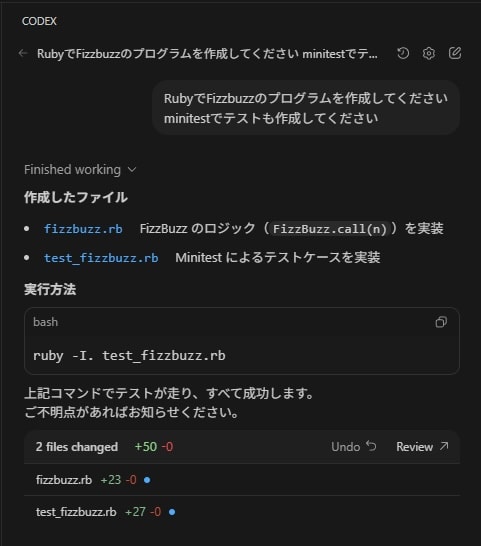
1分もかからないぐらいで作ってくれました。
簡単なプログラムなので時間がかかっていませんが実際に大きなシステムで動かすと時間がかかりそうな気がします。
▶作成してもらったファイル(クリックで展開)
- fizzbuzz.rb
# frozen_string_literal: true
# FizzBuzz のロジックを提供するモジュール。
module FizzBuzz
# 与えられた整数 n に対し、以下の文字列を返す。
# n が 3 の倍数 && 5 の倍数 -> "FizzBuzz"
# n が 3 の倍数 -> "Fizz"
# n が 5 の倍数 -> "Buzz"
# それ以外 -> n.to_s
def self.call(n)
case
when (n % 15).zero?
'FizzBuzz'
when (n % 3).zero?
'Fizz'
when (n % 5).zero?
'Buzz'
else
n.to_s
end
end
end
- test_fizzbuzz.rb
require 'minitest/autorun'
require_relative './fizzbuzz'
# FizzBuzz の動作を検証するテストケース。
class FizzBuzzTest < Minitest::Test
def test_fizz
assert_equal 'Fizz', FizzBuzz.call(3)
assert_equal 'Fizz', FizzBuzz.call(6)
end
def test_buzz
assert_equal 'Buzz', FizzBuzz.call(5)
assert_equal 'Buzz', FizzBuzz.call(10)
end
def test_fizzbuzz
assert_equal 'FizzBuzz', FizzBuzz.call(15)
assert_equal 'FizzBuzz', FizzBuzz.call(30)
end
def test_number
assert_equal '1', FizzBuzz.call(1)
assert_equal '2', FizzBuzz.call(2)
assert_equal '4', FizzBuzz.call(4)
end
end
最後に
実際にVSCodeのCodexからOllamaに接続して動かすことができました。
問題なさそうな回答が返ってきたので今回はここまでにしたいと思います。
VSCodeのCodexを初めて開いたときに ChatGPTへのログインか APIキーの設定しかできなさそうなのを見て焦りましたが、 config.toml で Ollamaへの接続設定ができて良かったです。
config.tomlを設定していれば、Codex CLIからOllamaにも接続することができました。
ちなみに 下記のように 全て小文字で ollama と書くと ずっと localhost にアクセスしようとするので焦りました 😇
profile = "gptoss-local"
model = "gpt-oss:120b"
[model_providers.ollama]
name = "ollama"
base_url = "http://192.168.10.182:11434/v1"
[profiles.gptoss-local]
model_provider = "ollama"
実際に使って確認していく予定でしたが会社から GPT5を使えるようにしてもらったのでこちらを使ってコーディング支援をしてもらっています。
VSCodeのCodexをローカルLLMで動かしてみたい人は試してみてはいかがでしょうか
関連記事

Modelfile を作成
gpt-oss:120bの初期コンテキスト長では少ないため80000にするModelfile を以下の内容で作成しています。(フォルダは
C:\Users\y-kuki\ollama_models\gpt-oss-120bに作成しています。)※ modelfile については こちらを参照してください。
カスタムモデルの作成
以下のコマンドでカスタムモデルを作成しています。
ollama create gpt-oss-120b-ctx80k -f C:\Users\y-kuki\ollama_models\gpt-oss-120b\Modelfileカスタムモデルの確認
ollama lsでカスタムモデルが作成されているか確認します。実際に起動するとコンテキスト長が変更されていることが確認できます。