正規表現記事を書いていて発見したregular-expressions.info↓という神サイトをちびちび読んでいました。
regular-expressions.infoより

すると、「Ruby(つまりOnigmo)では以下のように&&という特殊なメタキャラクタを使うと、文字セットのintersect演算、つまり共通集合を取れる」という記述が目に入り、思わず息を呑みました。
[class&&[intersect]]
文字セットの演算機能といえば、.NET Frameworkの[class-[class]]という記法で文字セットの差分を取る機能ぐらいしかないと思っていたのが、まさかRubyにもあこがれの文字セット演算があるなんて。目を疑いました。早速試しました。
今さらですが、正規表現の文字セットと文字クラスは同じものを指します。
1. 文字セットのintersect
急いで作ったので実用的ではありませんが。[\p{Han}]はUnicodeのあらゆる漢字を表す文字セット、[\p{N}]はUnicodeのあらゆる数値リテラルを表す文字セットです。両方の共通集合を取ってみると見事取れました。
- 例: /
[\p{Han}&&\p{N}]/というパターン(Rubular)
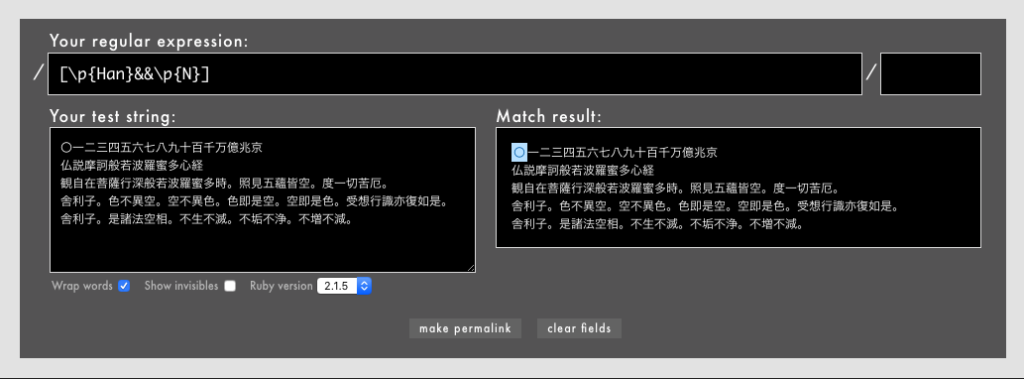
急いだので、つい\p{N}を文字セット[]に入れるのを忘れていましたが、確かに両者に共通する漢数字の「〇」(ゼロ)だけにマッチしています。もちろん[]に入れても結果は同じでした(Rubular)。
2. 文字セットのintersectで文字セットの「差分」を取る
文字セット[]とくれば、否定の文字セット[^]が使えるじゃないですか。同サイトからのいただき情報ですが、これを使えば長年欲しかった文字セットの差分をRubyの正規表現だけで表せるのです。
- 例: /
[\p{Han}&&[^〇一二三四五六七八九十百千万億兆京]]/(Rubular)
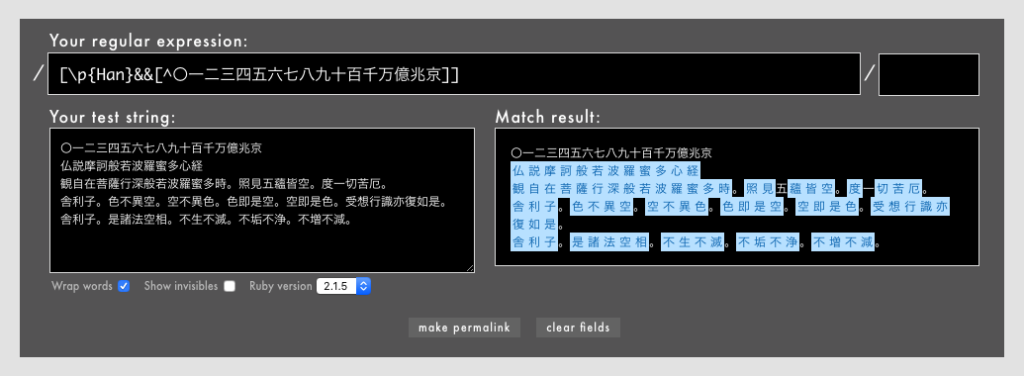
取れました(´;ω;`)ブワッ。
超巨大な文字セットである[\p{Han}]から、漢数字「〇一二三四五六七八九十百千万億兆京」のみを除いた文字セットを簡潔に作り出せました。
同じ要領で、今後は巨大な文字セットからいくつかの文字を除外するRuby正規表現をラクラク作れることになります。
しかし
しかし私の場合に限って、この[class&&[intersect]]という超強力な記法を使うにはまだためらいがあります。というのも、Ruby以外ではほとんど使えない方言だからです。
私は複数の正規表現ライブラリにまたがって同じ正規表現を使いたい欲張りさんなので、これを使ったばかりに他のライブラリで動かなくなったら便所で泣いてしまいそうです。
intersectを取れない正規表現ライブラリをコードから使う方は、当分の間コード側で工夫するしかなさそうです。
おたより発掘
Perlもできりゅhttps://t.co/Q0pkU681Af https://t.co/L4KTCnQ4zK
— Chihiro Fukazawa (@query1000) November 16, 2018
情報ありがとうございます!🙇