Railsスケーリング(3): GVL競合を計測してプロセスごとの理想的なスレッド数を決定する(翻訳)
本記事は、「Railsをスケーリングする」シリーズのパート3です。
パート1では、Rails アプリケーションに最適なプロセス数を見つける方法について説明しました。
パート2では、理想的なスレッド数を理論的に見つけるのに役立つアムダールの法則について学びました。
本記事では、現実のproductionアプリケーションで一連のテストを実行し、各プロセスの実際のスレッド数がどれくらいになるかを確認します。
パート1では、GVLが存在することと、スレッド切り替えの概念について解説しました。GVLの相互作用に基づいて、スレッドは3つの状態のいずれかになります。
- 実行中(running): そのスレッドがGVLを保持してRubyコードを実行している
- アイドル(idle): スレッドがI/O操作を実行しているため、GVLを必要としない
- ストール(stalled): スレッドがGVLを要求しており、GVL待ちキューで待機している
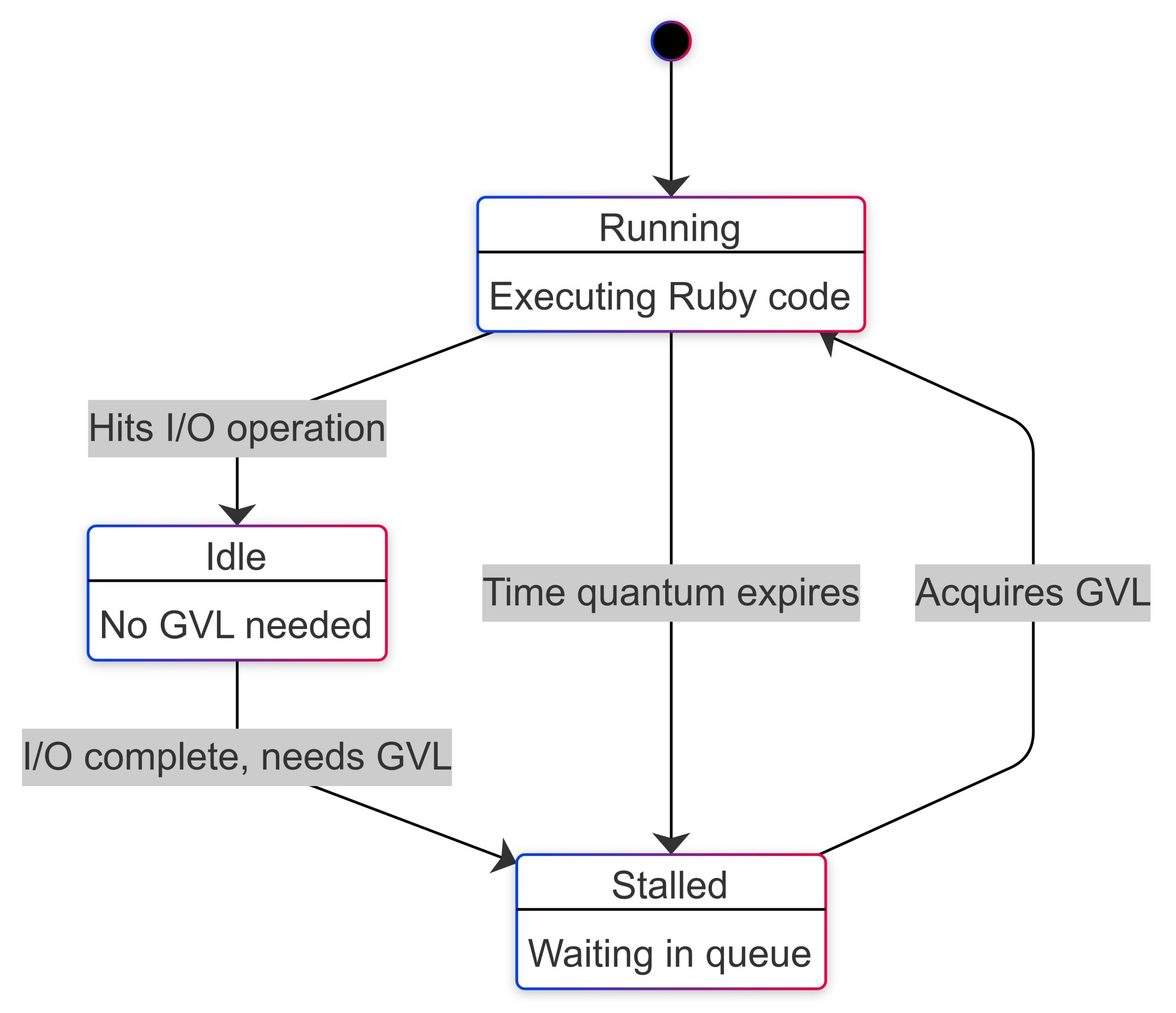
上の図に基づくと、idle timeはだいたいI/O timeと等しくなります。
🔗 perfmでGVLを計測する
Jean BoussierによるGVL instrumentation APIの取り組み(#18339)と、John Hawthornによるgvl_timingツールへの取り組みのおかげで、Ruby 3.2 以降で実行されているアプリのスレッドが各状態でどれだけの時間を消費しているかを測定できるようになりました。

私たちはお二人の素晴らしい成果を活用してperfmというツールを作成しました。これはアプリケーションの負荷に基づいたPumaの最適なスレッド数を割り出すのに役立ちます。

Perfmは、RailsアプリケーションにRackミドルウェアを挿入します。このミドルウェアはGVLを計測して必要なメトリクスを収集し、テーブルに保存します。また、収集したデータに関するレポートを生成するためのPerfm::GvlMetricsAnalyzerクラスもあります。
🔗 perfmでアプリケーションのI/O実行時間が占める割合を計測する
perfmを使うには、Gemfile に次の行を追加する必要があります。
gem 'perfm'
続いてbin/rails generate perfm:installコマンドを実行します。これによって生成されるperfm_gvl_metricsというマイグレーションは、リクエストレベルのメトリクスを保存するのに使われます。
次に、以下のイニシャライザファイルを作成します。
# config/initializers/perfm.rb
Perfm.configure do |config|
config.enabled = true
config.monitor_gvl = true
config.storage = :local
end
Perfm.setup!
このコードをproduction環境にデプロイした後、分析に十分な個数のデータポイントを取得するためにリクエストを2万件ほど収集する必要があります。それが終わったら、テーブルがこれ以上大きくならないよう、config.monitor_gvlをfalseに設定してGVL監視を無効にできます。
リクエストデータを収集したら、次は分析に進みます。
Railsコンソールで以下を実行します。
irb(main):001* gvl_metrics_analyzer = Perfm::GvlMetricsAnalyzer.new(
irb(main):002* start_time: 2.days.ago, # configure this
irb(main):003* end_time: Time.current
irb(main):004> )
irb(main):005>
irb(main):006> results = gvl_metrics_analyzer.analyze
irb(main):007> io_percentage = results[:summary][:total_io_percentage]
=> 45.09
これで、I/O処理に費やされた時間の割合を得られます。私たちのNeetoCalというアプリケーションのproduction環境で実行したところ、45%という値を得られました。
パート2で解説したように、アムダールの法則は、負荷のうちパラレル化可能な部分がどのぐらいあるかに基づいて、理論上の最大速度向上を示します。
式は以下の通りです。
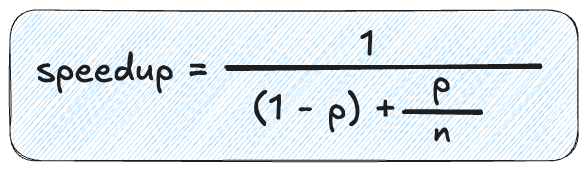
p: パラレル化可能な割合(この場合は0.45)N: スレッド数(1 - p): シーケンシャルに実行しなければならない部分(この場合は0.55)
p = 0.45とおいて、さまざまなスレッド数における理論的な高速化を計算してみましょう。
| スレッド数(N) | 高速化 | 直前の結果からの改善率(%) |
|---|---|---|
| 1 | 1.00 | - |
| 2 | 1.29 | 29% |
| 3 | 1.43 | 11% |
| 4 | 1.52 | 6% |
| 5 | 1.57 | 3% |
| 6 | 1.60 | 2% |
| 8 | 1.64 | <2% |
| 16 | 1.69 | <1% |
| ∞ | 1.82 | - |
スレッド数を4よりも増やすと、改善率が5%を下回ることがわかります。
つまり、max_threadsに指定する値は4が適切であるということです。この値をRAILS_MAX_THREADS環境変数に設定するとよいでしょう。
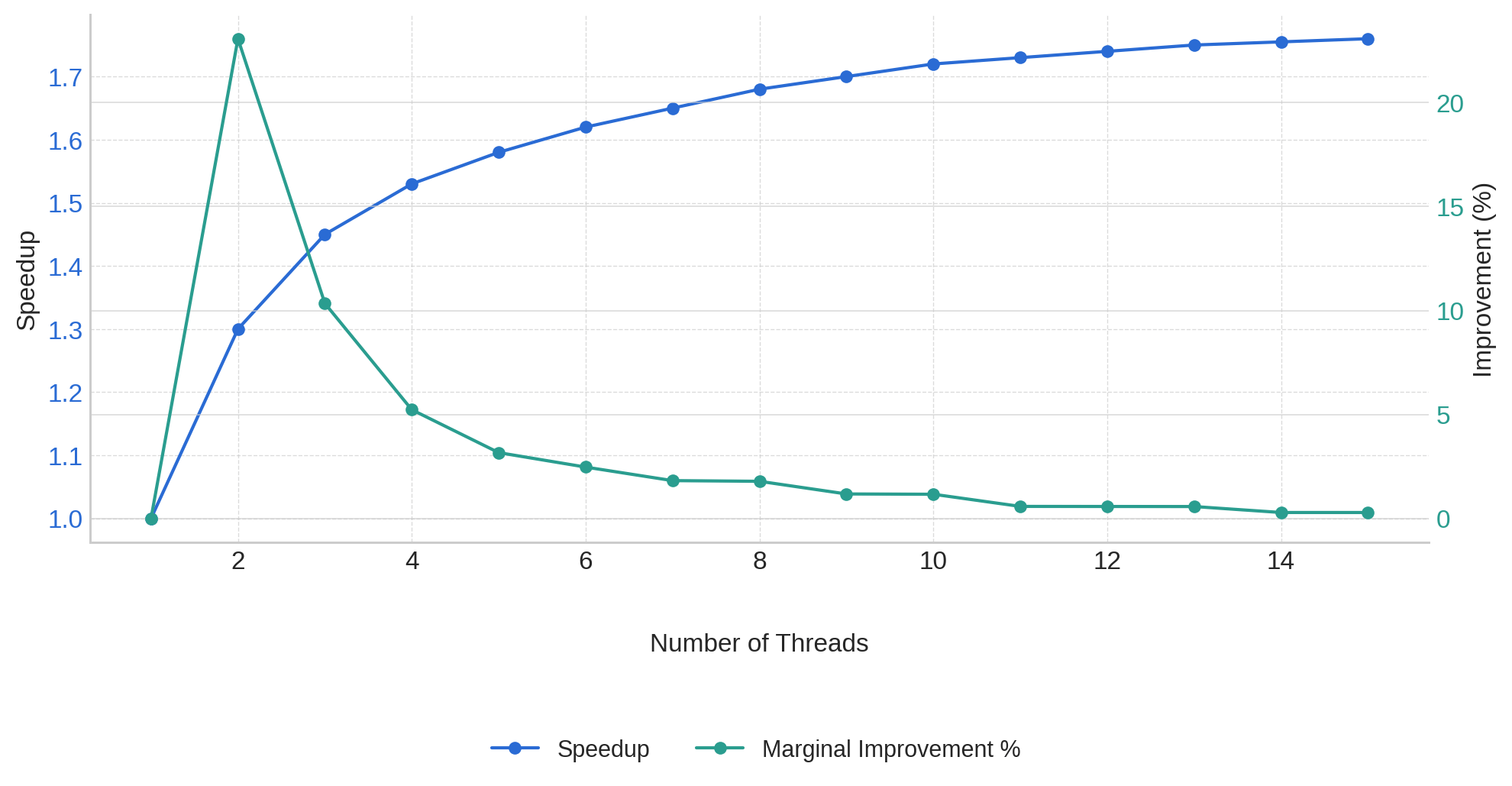
この表を見ると、5つ目のスレッドを追加してもパフォーマンスは3%しか改善されません。ここから、これ以上スレッドを追加しても、それに伴ってメモリ使用量やGVL競合が増加する可能性に見合わないと考えられます。
なお、I/Oパーセンテージを入力すると、グラフ表示とともに最適なスレッド数を把握できる小さなアプリケーションも作成しました↓。
参考: Amdahl's Law Thread Calculator
🔗 スレッド数をストール時間で検証する
アムダールの法則のおかげで4という値を理論的に導き出せました。
今度はこの法則を検証してみましょう。4という値が実際に適切かどうかを現実に確かめることにします。
まず、RAILS_MAX_THREADS環境変数(Pumaのmax_threads)を4に設定して、この値によってGVL競合が最小限に抑えられるかどうかを確認する必要があります。GVL競合とは、スレッドがGVLを待機する時間、つまりストール時間を指します。
つまり、ストール時間が長いほど、スレッド数の設定値が大きいことを意味します。スレッドの待ち時間をむやみに増やしてレイテンシが急増するような事態は避けたいものです。ストール時間は短いほど望ましく、容認可能なストール時間は75msです。
平均ストール時間はperfmの分析結果から得られます。既に私たちのNeetoCalアプリからデータを収集してありますので、ここから平均ストール時間を取得してみましょう。
irb(main):001* gvl_metrics_analyzer = Perfm::GvlMetricsAnalyzer.new(
irb(main):002* start_time: 2.days.ago,
irb(main):003* end_time: Time.current,
irb(main):004* puma_max_threads: 4
irb(main):005> )
irb(main):006> results = gvl_metrics_analyzer.analyze
irb(main):007> avg_stall_ms = results[:summary][:average_stall_ms]
=> 110.24
この110.24というストール時間は少し長すぎるようです。
RAILS_MAX_THREADS環境変数の値を1減らして、再度データポイントを収集してみましょう(2万リクエスト程度)。これでRAILS_MAX_THREADSの値は3に減りました。
以上の手順を、ストール時間が75msを下回るまで繰り返す必要があります。
irb(main):001* gvl_metrics_analyzer = Perfm::GvlMetricsAnalyzer.new(
irb(main):002* start_time: 2.days.ago,
irb(main):003* end_time: Time.current,
irb(main):004* puma_max_threads: 3
irb(main):005> )
irb(main):006> results = gvl_metrics_analyzer.analyze
irb(main):007> avg_stall_ms = results[:summary][:average_stall_ms]
=> 79.38
今度の79.38は、75 msにかなり近くなりました。
これで、RAILS_MAX_THREADS環境変数の値は3で確定できます。この値をさらに1減らして2に設定すればストール時間はさらに短縮されますが、アプリケーションのコンカレンシー(同時実行数)が制限されます。ここはトレードオフが必要な部分です。
私たちの目標は、あくまでGVL競合を最小限にしつつコンカレンシーを最大化することです。しかし、アプリの処理の大半がI/O処理に費やされている場合は(例: コントローラから直接外部API呼び出しを頻繁に行うプロキシアプリケーション)、アプリサーバーをFalconに切り替える方法も使えます。Falconは、このようなI/O処理の比重が大きいユースケースに最適です。

大まかには、I/Oを実行するリクエストに費やされる時間を最小限に抑えるために、次の項目に注意する必要があります。
- N+1クエリをなくすこと
- 実行に時間のかかるクエリをなくすこと
- コントローラから直接行っているサードパーティAPI呼び出しをバックグラウンドジョブプロセッサに移動する
- 計算処理が重い部分をバックグラウンドジョブプロセッサに移動する
Railsアプリケーションを十分最適化した場合のmax_threads値はおよそ3になります。Railsアプリケーションでこの3という値がデフォルト値として使われている理由がこれです。この値に落ち着くまでに、以下のissueで長期に渡る議論が行われました↓。実に興味深い内容なので、ぜひ全文を読んでみることをおすすめします。
参考: Set a new default for the Puma thread count · Issue #50450 · rails/rails
本記事でわかりにくい点がありましたら、LinkedIn、Twitter、BigBinaryサイトまでお問い合わせください。私たちは、Railsアプリケーションをスケールさせる方法を誰もが理解できるよう、わかりやすく書くことを目指しています。
概要
元サイトの許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。