Railsスケーリング(1)Puma、コンカレンシー、GVLのパフォーマンスへの影響を理解する(翻訳)
本記事は、「Railsをスケーリングする」シリーズのパート1です。
rails newでRailsアプリケーションを作成したときのデフォルトWebサーバーは、Pumaになります。PumaがHTTPリクエストをどのように処理するかを説明しましょう。

🔗 Pumaがリクエストを処理するしくみ
Pumaは受信リクエストをTCPソケットでリッスンします。
リクエストが到着すると、そのリクエストはそのTCPソケットのキューに入れられます。次に、そのリクエストがPumaのプロセスによって取得されます。Pumaのプロセスとは、Railsアプリケーションのインスタンスを実行する、独立したOSプロセスです。
原注
Pumaの公式ドキュメントでは、PumaのプロセスをPumaワーカーと呼んでいます。
「ワーカー(worker)」という用語は、SidekiqやSolidQueueなどのバックグラウンドワーカーと紛らわしくなる可能性があるため、本記事の一部では曖昧さを避けるためにPumaプロセスと呼んでいます。
それでは、Pumaがリクエストをどのように処理するかを、順を追って見てみましょう。
Pumaの内部構造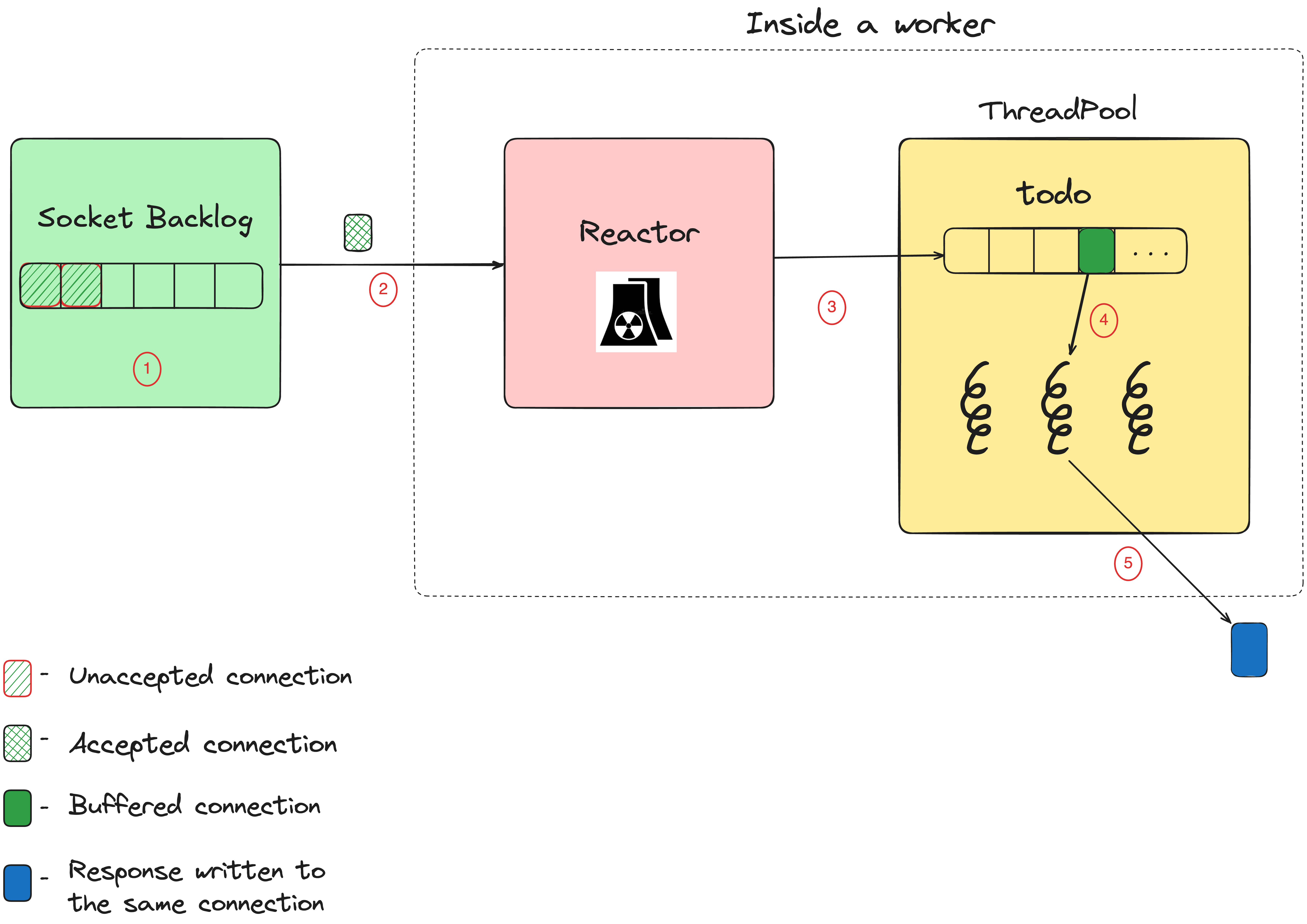
- すべての受信コネクションは、ソケットバックログ(socket backlog)に追加されます。ソケットバックログは、保留中のコネクションを保持するOSレベルのキューです。
-
Pumaの
Reactorクラスで作成される個別のスレッドが、ソケットバックログのコネクションを読み取ります。Reactorはその名の通り、Reactorパターンを実装します。このリアクターは、ノンブロッキングI/Oとイベントドリブンアーキテクチャによって、複数のコネクションを一度に管理できます。 -
受信リクエストがメモリで完全にバッファリングされると、そのリクエストがスレッドプールに渡されます(このリクエストは
@todo配列内にあります)。 -
スレッドプール内のスレッドが、
@todo配列内のリクエストを取得して処理します。このスレッドはRackアプリケーション(ここではRailsアプリケーション)を呼び出して、レスポンスを生成します。 -
次に、レスポンスが同じコネクション経由でクライアントに返されます。これが完了すると、スレッドがスレッドプールに解放されて、
@todo配列にある次の項目を処理します。
🔗 Pumaの動作モード
- 1. シングルモード: Pumaプロセスは1個だけ起動し、追加の子プロセスは存在しません。トラフィックの少ないアプリケーションにのみ適しています。
シングルモード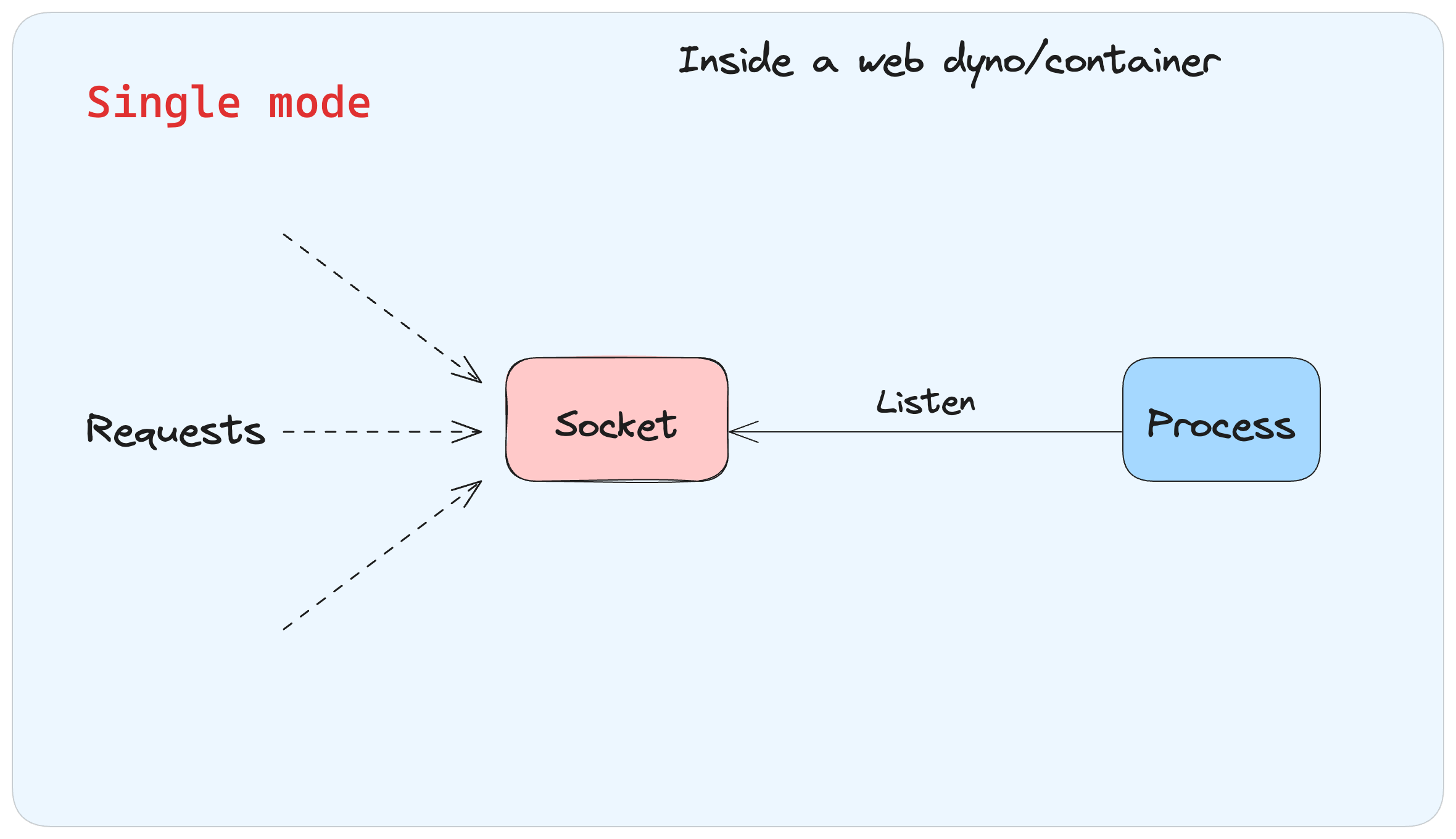
- 2. クラスタモード: Pumaはマスタープロセスを1つ起動し、このマスタープロセスはアプリケーションを準備してから、
fork()システムコールを呼び出して子プロセスを1つ以上作成します。作成された子プロセスはリクエストの処理を担当し、マスタープロセスはそれらの子プロセスを監視・管理します。
クラスタモード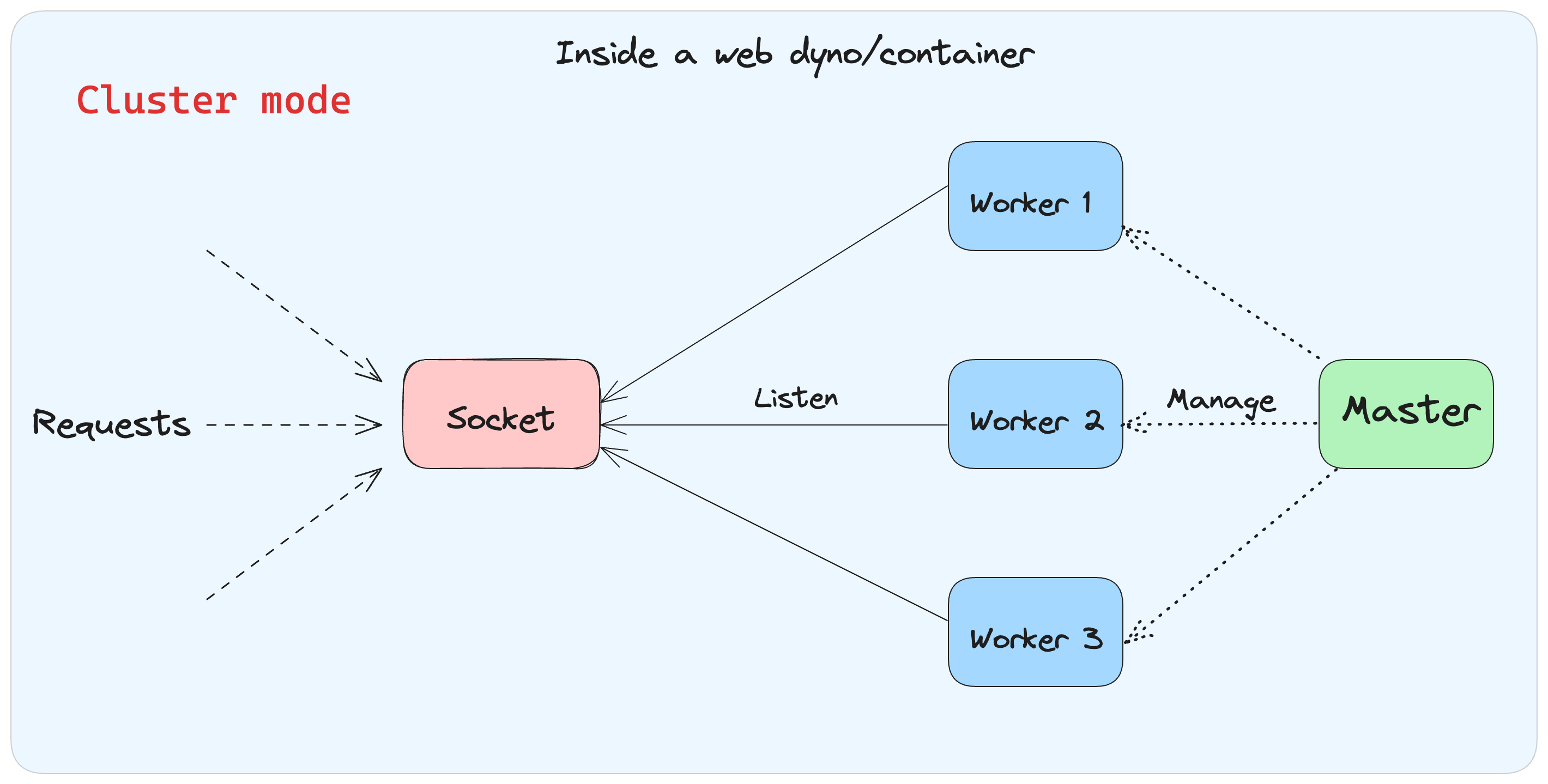
🔗 新規RailsアプリのデフォルトのPuma設定
Rails 8以降のアプリケーションを新規作成したときにconfig/puma.rbに保存されるデフォルトのPuma設定には、以下のコードが含まれます。
Rails 8のPuma設定は、従来バージョンのPuma設定と異なります。本記事ではRails 8のPuma設定について説明している点にご注意ください。
threads_count = ENV.fetch("RAILS_MAX_THREADS", 3)
threads threads_count, threads_count
rails_env = ENV.fetch("RAILS_ENV", "development")
environment rails_env
case rails_env
when "production"
workers_count = Integer(ENV.fetch("WEB_CONCURRENCY", 1))
workers workers_count if workers_count > 1
preload_app!
when "development"
worker_timeout 3600
end
Rails 8の新規Railsアプリケーションでは、環境変数のRAILS_MAX_THREADSとWEB_CONCURRENCYは設定されません。つまり、この設定によってthreads_countはデフォルト値の3に、workers_countはデフォルト値の1に設定されます。
次に、上の設定コードの2行目を見てみましょう。
threads threads_count, threads_count
threadsメソッドには2つの引数が渡されています。
第1引数のthreads_countのデフォルト値は3なので、実際には以下の引数で呼び出していることになります。
threads(3, 3)
Pumaのthreadsは、minとmaxという2つの引数を受け取ります。これらは、Pumaの個別のプロセスがリクエストを処理するときに使われる最小スレッド数と最大スレッド数をそれぞれあらわしています。この場合、Pumaはスレッドプールで3つのスレッドを初期化します。
次に、上記コードのうち以下の行を見てみましょう。
workers workers_count if workers_count > 1
この場合workers_countの値は1になるので、Pumaはシングルモードで起動します(前述のようにPumaのワーカーは基本的にはプロセスであり、バックグラウンドジョブのワーカーではありません)。
これまで見たように、環境変数RAILS_MAX_THREADSやWEB_CONCURRENCYを指定しない場合、Pumaは単一プロセスを起動し、そのプロセス内に3つのスレッドを持つようになります。言い換えれば、Railsが起動されると、同時に3つのリクエストを処理可能になります。
この「シングルプロセス、3スレッド」は、Railsをdevelopmentモードやproductionモードで起動した場合のPumaのデフォルト値です。
🔗 WebアプリケーションとCPU使用量の関係
Webアプリケーション内のコードは、以下のような感じで処理を進めます。
- 何らかのデータ操作を行う
- データベース呼び出しをいくつか行う
- さらに追加の計算を行う
- 何らかのネットワーク呼び出しを行う
- さらに追加の計算を行う
図で表すと以下のような感じになります。
3スレッド、1プロセス、2コア
CPUが行う作業には、ビューのレンダリング、文字列操作、あらゆる種類のビジネスロジック処理などが含まれます。要するに、Rubyコードの実行に関連するような処理は、すべてCPUの作業とみなされます。それ以外の作業(データベース呼び出しやネットワーク呼び出しなど)はすべて、CPUがアイドル状態になります。
CPUがいつ動作し、いつアイドル状態になっているかを別の視点から図示すると以下のようになります。
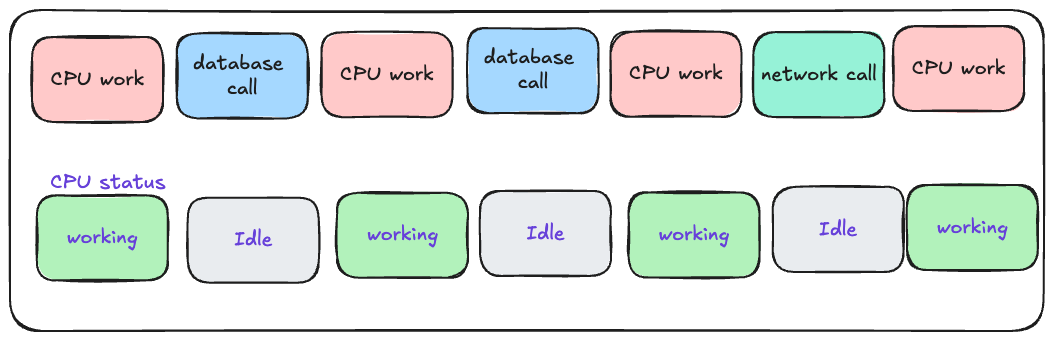
プログラムがCPUを使っている場合、コードのその部分は「CPUバウンド(CPU bound)」と呼ばれ、プログラムがCPUを使っていない場合、コードのその部分は「I/Oバウンド(I/O bound)」と呼ばれます。
🔗 CPUバウンドとI/Oバウンド
CPUバウンドの実際の意味を理解しましょう。以下のコードを見てください。
10.times do
Net::HTTP.get(URI.parse("https://bigbinary.com"))
end
上のコードは、BigBinaryのWebサイトに10回連続でアクセスしています。ネットワーク接続を確立するには時間がかかるため、上のコードを実行するとどうしても時間がかかります。
仮に上のコードを実行するのに10秒かかるとしましょう。このコードをもっと速くしたいと思って、サーバー用に購入するCPUをもっと高機能なものにしたとしたら、このコードは速くなるでしょうか?
いいえ。このコードはI/Oバウンドであり、CPUバウンドではないので、CPUをいくら高機能にしても実行は速くなりません。この場合CPUは速度の上限となるファクターとはならないのです。
CPUが高速になれば高速になるプログラムは、CPUバウンドです。
IO操作が高速になれば高速になるプログラムは、I/Oバウンドです。
以下は、I/Oバウンドな操作の例です。
- データベース呼び出し: テーブルの読み取り、新規テーブル作成など
- ネットワーク呼び出し: Webサイトのデータ読み取り、メール送信など
- ファイルシステム操作: ファイルシステム上のファイル読み取りなど
先ほどの図で、CPUがアイドル状態になる場合があることがわかりました。このアイドル状態は「I/Oバウンド」という用語に該当することがわかったので、図を以下のように更新してみましょう。
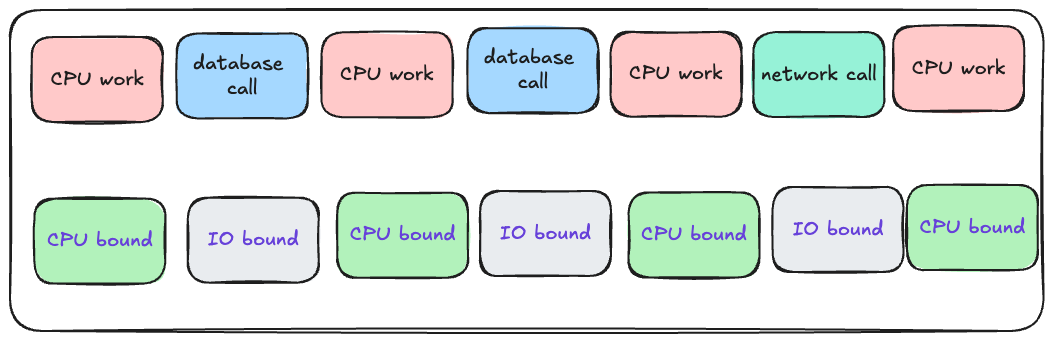
プログラムがI/Oバウンドの状態では、CPUは何も行いません。貴重なCPUサイクルを無駄にせずにCPUを使い切るには、何をすればよいでしょうか?
ここまではスレッドが1つの場合だけを見てきましたが、プロセス内のスレッド数は増やすことが可能です。スレッドを増やすことで、あるスレッドがCPUバウンドな処理を実行している間に、CPUが別のスレッドに切り替えてI/Oバウンドな操作を実行できるようになり、CPUを効率よく利用可能になります。スレッド同士を切り替えるしくみについては、本記事の後半で詳しく説明します。
🔗 コンカレンシーとパラレリズム
コンカレンシー(concurrency: 並行実行)とパラレリズム(parallelism: 並列実行)は意味が似通っていて、日常生活ではどちらを使っても問題ありません。しかしコンピュータエンジニアリングにおいては、コンカレントな処理とパラレルな処理は違います。
ある社員が、100通のメールと100通のツイートに返信しなければならないとします。この社員は、「1通のメールに返信する」「1件のツイートに返信する」をひたすら交互に繰り返す形で仕事をすることが可能です。
この社員の仕事ぶりを監視している上司から見ると、残りメール数と残りツイート数は、どちらも100件、99件、98件...と順調に減っているように見えるでしょう。
この上司は、社員が仕事を「パラレルに」進めていると思い込むかもしれませんが、その解釈は正しくありません。この社員の進め方は「コンカレント」であると解釈するのが技術的に適切です。
あるシステムが処理を「パラレル」に実行していると言えるためには、複数の操作を「同時に(simultaneously)」に実行していなければなりません。この社員の場合、どの瞬間を見ても、メールに返信しているか、ツイートに返信しているかのどちらか1つしか行っていません。
言い方を変えれば、コンカレンシーとは同時に複数の作業をまかなうことであり、パラレリズムは複数の処理を文字通り「同時に」実行することです。
どっちがどっちだかわからなくなったときは、「コンカレンシーという用語には"con"(俗語で"詐欺"を表す)という語がある」と覚えておくとよいでしょう。コンカレンシーはconman(詐欺師)なので、一見処理をパラレルに行っているように見せかけているが、実際は複数の処理をコンカレントに(素早く交互に切り替えて)実行しているに過ぎない」と覚えるのです。
🔗 RubyのGVLを理解する
RubyのGVL(Global VM Lock)は、複数のスレッドがRubyのコードを同時に実行しないようにするためのメカニズムです。
GVLは、片側1車線の橋についている交通整理用の信号機のように振る舞います。複数の自動車(スレッド)が同時に橋を渡ろうとしても、信号機(GVL)が通すのは一度に1台の自動車だけです。信号機は、その自動車が橋を無事に渡り終えた場合にのみ、次の自動車の通行を許可します。
Rubyの機能のうち、メモリ管理(ガベージコレクションなど)などはスレッド安全ではありません。そのため、GVLによって一度に1つのスレッドだけがRubyコードを実行するようにし、データの破損を防いでいるのです。
あるスレッドが「GVLをつかむ」と、そのスレッドだけがVM構造を排他的に変更可能になります。
重要なのは、RubyにGVLが存在している目的は、あくまでRubyの動作やRubyの内部VMのステート管理を保護するためであり、アプリケーションコードを保護するためではありません。
繰り返しますが、GVLが存在するからといって、スレッド安全でないコードを書いてよいわけではなく、コード内におけるスレッド関連の問題をRubyが自動的に面倒を見てくれるわけでもありません。
Rubyは、コンカレントなコードを管理するためのMutexライブラリやconcurrent-ruby gemなどのツールも提供しています。たとえば、以下のコードは(出典)はスレッド安全ではありませんが、GVLはこのコードを競合状態から保護しません。
from = 100_000_000
to = 0
50.times.map do
Thread.new do
while from > 0
from -= 1
to += 1
end
end
end.map(&:join)
puts "to = #{to}"
このコードはfromをカウントダウンしてtoをカウントアップするだけなので、値は常に100,000,000になりそうに思えますが、コードを何度か実行してみると結果は期待通りになりません。
その理由は、同じ変数(fromとto)を複数のスレッドが同時に変更しようとしており、同期処理がまったく行われていないためです。これは競合状態(race condition)と呼ばれます。
to += 1とfrom -= 1という処理は、CPUレベルではアトミック(atomic: 分割不可)ではなく、以下の3つの処理として記述可能です。
- 現在の
to変数の値を読み出す - その値に1を足す
- 結果を
to変数に書き込む
この競合状態は、以下のようにMutexライブラリを使って書き直すことで修正できます。
from = 100_000_000
to = 0
lock = Mutex.new
50.times.map do
Thread.new do
while from > 0
lock.synchronize do
if from > 0
from -= 1
to += 1
end
end
end
end
end.map(&:join)
puts "to = #{to}"
なお、JRubyやTruffleRubyなどのRuby実装にはGVLがないことも知っておくとよいでしょう。
🔗 必要なプロセス数はGVLで決まる
productionアプリをAWS EC2のt2.mediumマシンにデプロイすることを考えてみましょう。以下の図によると、このマシンには2つのvCPU(仮想CPU)があることがわかります。
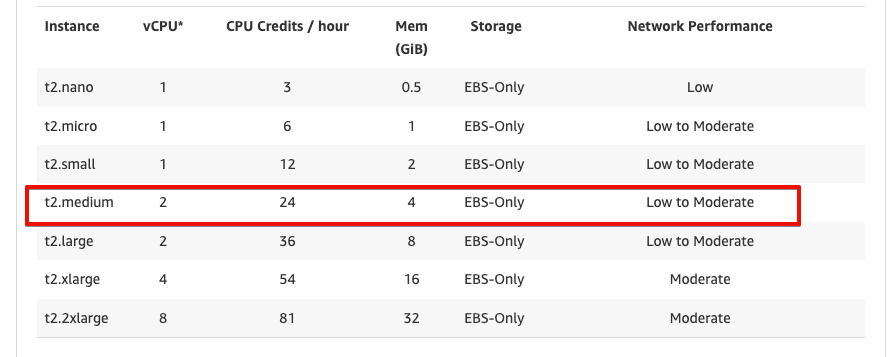
CPUとvCPUの違いについては立ち入らないことにして、AWSのマシンが2コアであると仮定して話を進めることにしましょう。つまり、コードのデプロイ先には2コアのマシンがあり、productionで動いているプロセスは1個だけという状態です。しかし心配いりません。スレッドは3つあるので、2つのコアで3つのスレッドを共有できます。
このとき、以下のような実行状態が可能そうに思えます。
3スレッド、1プロセス、2コア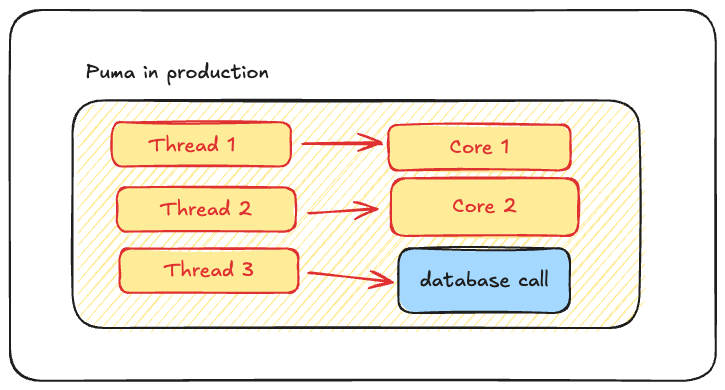
しかしこのような状態は不可能です。Rubyではこのような状態になることが許されていません。
現状では、GVL(Global VM Lock)によってスレッド1とスレッド2が同一のプロセスに属しているため、このような状態は取れません。
GVLは、単一のRubyプロセス内では同時に1つのスレッドだけがCPUバウンドのコードを実行できるようにします。ここで重要なのは、このロックはCPUバウンドのコードだけを対象にし、かつ同一のプロセスのみを対象としていることです。
シングルプロセス、マルチコア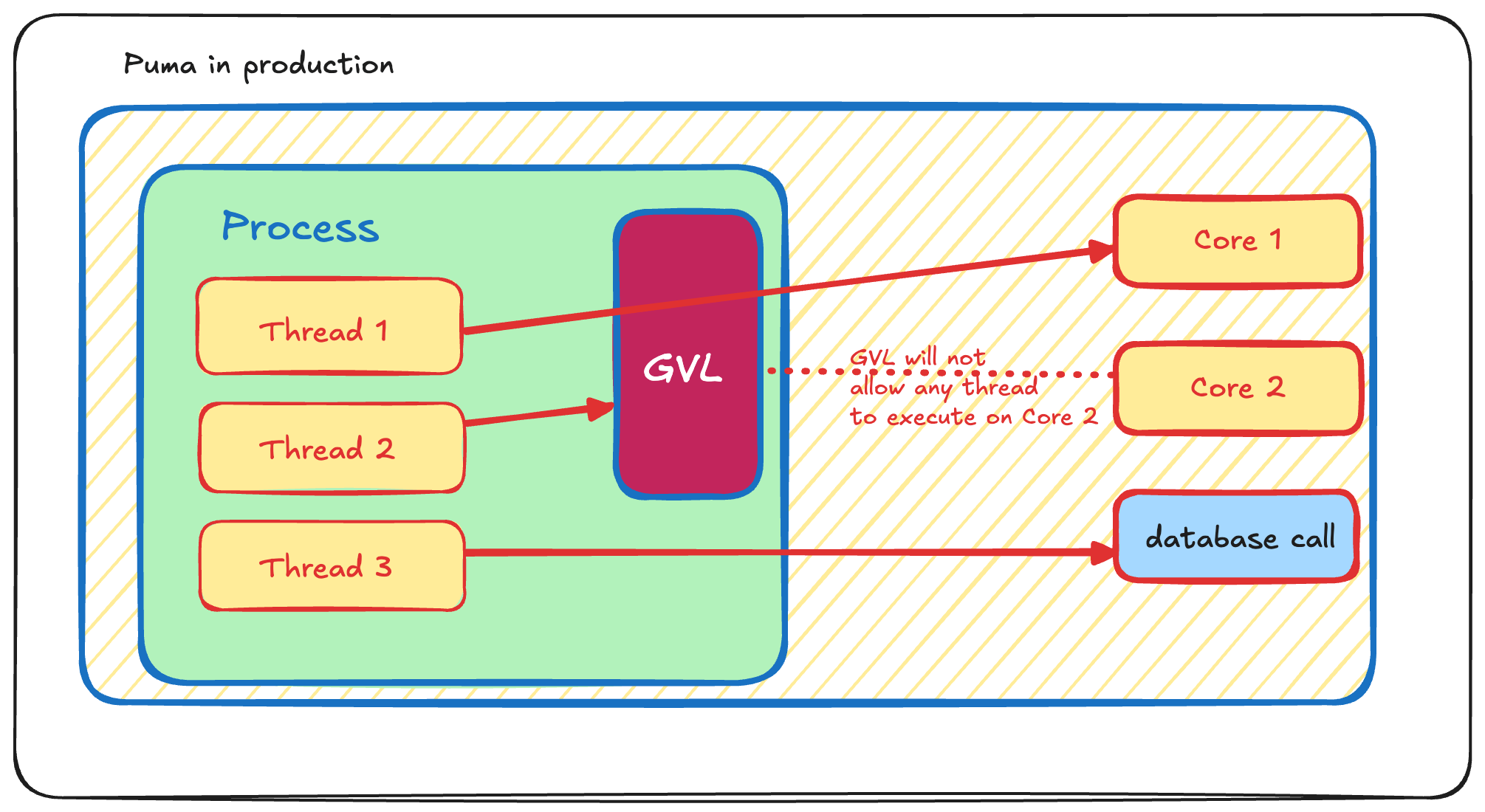
上の場合、3つのスレッドはDB操作であればパラレルに実行できます。
しかしCPU操作については、同一プロセス内の2つのスレッドはパラレル実行できません。
図では、スレッド1がコア1を利用しています。このとき、コア2は空いていて利用可能ですが、スレッド2はこのコア2を利用したくてもGVLに阻まれてしまいます。
GVLが何をしているのかをおさらいしてみましょう。GVLは、CPUバウンドのコードについてはCPUにアクセスできるスレッドが1つだけになるように制限します。
この空いているコア2をどうやったら活用できるかという疑問が生じます。
- GVLはプロセスレベルで適用される。
- 同一プロセス内にある複数のスレッドは、CPU操作をパラレルに実行することは許されない。
ならば、解決方法はプロセス数を増やすことです。
Pumaプロセスを2つ実行するには、以下のようにWEB_CONCURRENCY環境変数に2を渡してPumaを再起動する必要があります。
WEB_CONCURRENCY=2 bundle exec rails s
これでプロセス数が2になり、コア1とコア2を同時に利用可能になりました。
マルチプロセス、マルチコア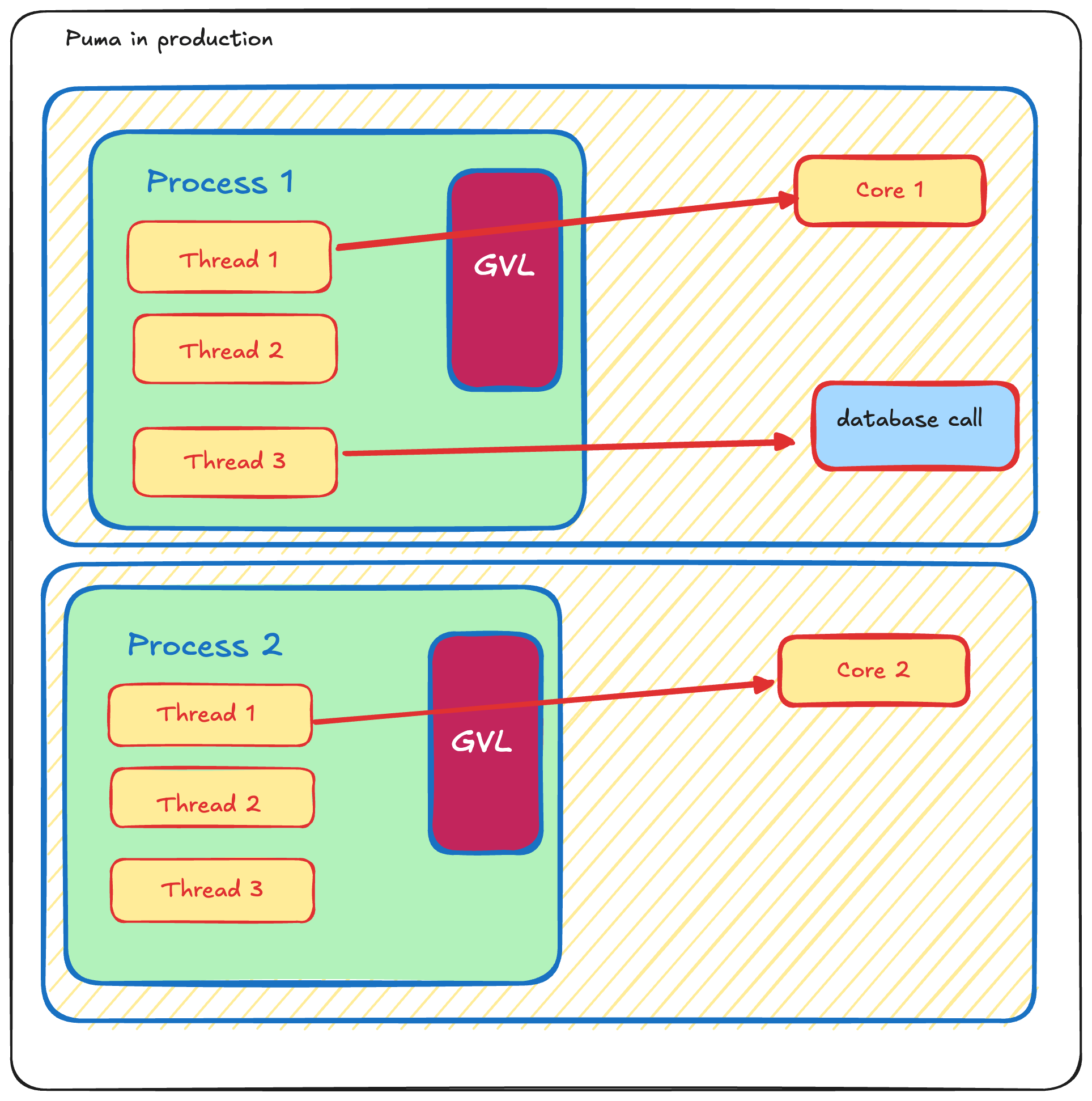
マシンにコアが5つある場合、プロセスも5つ必要なのでしょうか?
そのとおりです。この場合、すべてのコアを活用するにはプロセスが5つ必要です。
つまり、コアを最大限に活用するには、経験則としてWEB_CONCURRENCY環境変数には利用可能なプロセス数、つまりそのマシンで利用可能なコア数を設定する必要があります。
🔗 スレッドの切り替え
今度は、マルチスレッド環境でスレッドがどのように切り替わるかを見ていきましょう。ここではスレッド数を2に設定している点にご注意ください。
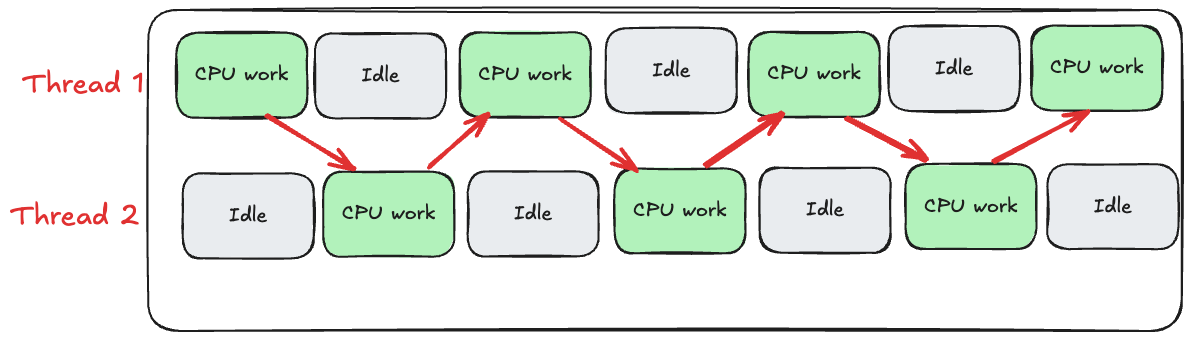
図に示したように、スレッドがアイドル状態になると、CPUはスレッド1とスレッド2を切り替えます。これなら先ほどのシングルスレッドの場合と異なり、CPUサイクルが無駄にならないので望ましい振る舞いです。しかし実際のスレッド切り替えは、図に示したものよりもずっと複雑です。
Rubyは、複数のスレッドを「OSレベル」と「Rubyレベル」という2つのレベルで管理します。Rubyで作成したときのスレッドは「ネイティブスレッド」と呼ばれます。これは、OSで認識され、OSで管理される本物のスレッドであるという意味です。
あらゆるOSには「スケジューラ」と呼ばれるコンポーネントがあります。Linuxの場合はCFS(Completely Fair Scheduler)と呼ばれます。このスケジューラは、どのスレッドにどの程度の時間CPUを利用させるかを決定します。
しかしRubyは、GVL(Global VM Lock)を介して独自の制御レイヤを追加します。
Rubyのスレッドは、GVLをつかんでいる場合に限ってCPUバウンドのコードを実行可能になります。また、Ruby VMは、1つのスレッドがGVLを保持可能な期間を最大100msまでに制限します。スレッドのGVL保持期間が100msを超えると、CPUバウンドのコード実行を待機している別スレッドが存在する場合、そのスレッドは強制的にCPUを別スレッドに解放させられます。これにより、Rubyのスレッドがリソーススタベーションに陥らないようにしています。
スレッドが実行しているコードがCPUバウンドの場合、以下のいずれかが発生するまでは実行を継続します。
- スレッドがCPUバウンドの処理を完了させる。
- スレッドがI/O操作を実行する(この場合自動的にGVLを解放する)
- 100msの上限に達する
あるスレッドが実行開始すると、Ruby VMはバックグラウンドタイマースレッドをVMレベルで利用します。このタイマースレッドは、現在のRubyスレッドが何ms実行されたかを10msごとにチェックします。
スレッドの実行時間がスレッドクォンタム(=スレッドを実行可能な最大時間、デフォルトは100ms)を超えると、Ruby VMはアクティブなスレッドからGVLを取り上げて、キューで待機している次のスレッドに渡します。
スレッドが(自発的または強制的に)GVLを解放すると、そのスレッドはキューの最後尾に移動します。
デフォルトのスレッドクォンタムは100msですが、Ruby 3.3からはRUBY_THREAD_TIMESLICE環境変数で設定可能になりました(詳しくは#20861の議論を参照)。
この環境変数を使うことで、スレッドのスケジューリング動作を微調整できます。クォンタムが小さいほどスレッドの切り替え頻度が上がり、クォンタムが大きいほど切り替え頻度が下がります。
スレッドが2つある場合の振る舞いを見てみましょう。
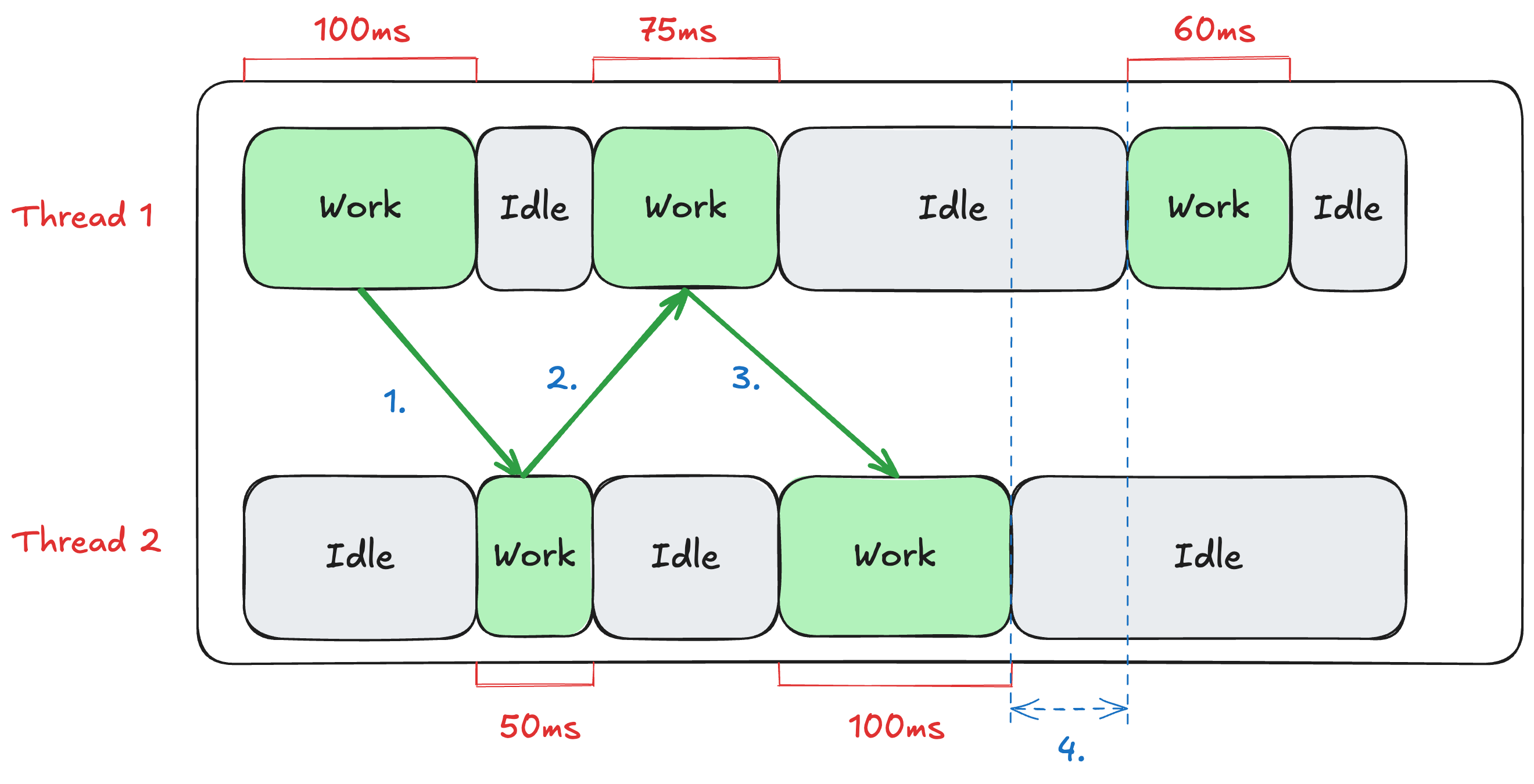
- スレッド1はクォンタム100msを超え、スレッド2にGVLを譲る
- スレッド2はCPUを50ms利用したタイミングで自発的にGVLをスレッド1に譲ってI/Oを実行する
- スレッド1はCPUを75ms利用したタイミングで自発的にGVLをスレッド2に譲ってI/Oを実行する
- スレッド1もスレッド2もI/Oを実行しているのでGVLを必要としなくなる
スレッド2がCPUにアクセスできる時間を増やせば、今よりもずっと速くなる可能性があります。CPUが処理するスレッド数を減らせば、スレッドの順番待ちが減り、スレッドがCPUを即座に利用可能になります。
しかし値のバランスには注意が必要です。CPUがアイドル状態になれば無駄なコストになりますし、CPUが極端にビジーな状態ではリクエストの処理時間が余計にかかることになります。
🔗 GVLの影響を可視化する
Rubyのマルチスレッドがパフォーマンスにどう影響するかをより深く理解するために、簡単なテストを行ってみましょう。このテストには以下の2つのメソッドがあります。
cpu_intensiveメソッドは、ネストされたループ内で純粋な算術演算を実行し、CPUに大きく依存する負荷を作成します。mixed_workloadメソッドは、CPUを集中的に利用する操作とI/O操作(ここではスリープ状態でシミュレーション)を組み合わせます。I/O操作中はGVLが解放され、他のスレッドが作業を実行できるようになります。
このコードはGistで参照できます。
cpu_intensiveメソッドを実行すると、以下の出力が生成されます。
Running demonstrations with GVL tracing...
Benchmarking all scenarios:
Starting demo with 1 threads doing CPU-bound work
Time elapsed: 7.4921 seconds
Starting demo with 3 threads doing CPU-bound work
Time elapsed: 7.8146 seconds
Starting demo with 1 threads doing Mixed I/O and CPU work
Time elapsed: 8.0332 seconds
Starting demo with 3 threads doing Mixed I/O and CPU work
Time elapsed: 7.5651 seconds
この出力から、CPUバウンドの処理はシングルスレッドの方がパフォーマンスが優れていることがわかります。理由がわかりますか?
上記のスクリプトで生成されたトレース結果をgvl-tracing gemで視覚化してみましょう。


この結果から、CPU バウンドの処理でスレッドが1つしかなければ、GVLを待機しないことがわかります。
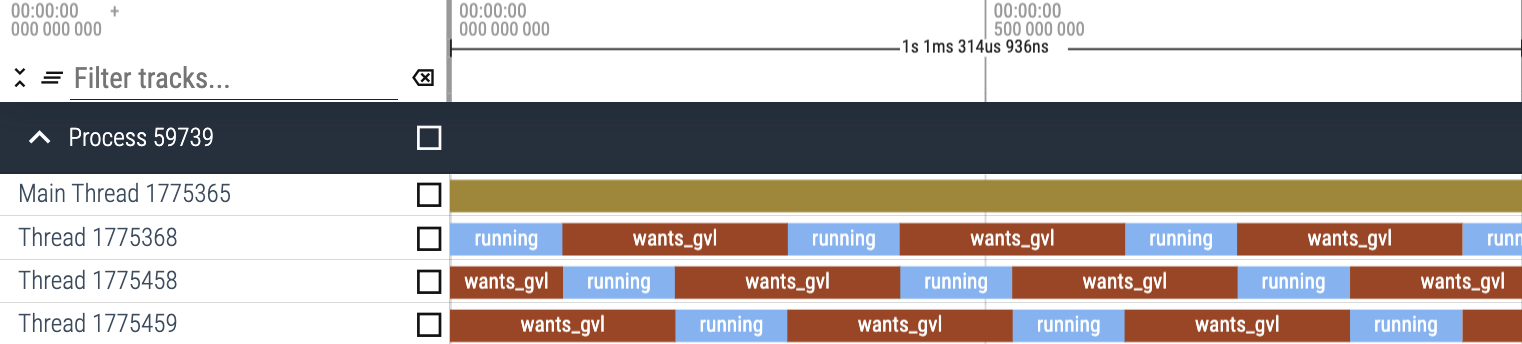
この結果から、CPU バウンドの処理でスレッドが3つある場合は、各スレッドがGVLを何度も待機していることがわかります。
次に、シングルスレッド環境とマルチスレッド環境で、mixed_workloadの結果を見てみましょう。
mixed_workloadでは、マルチスレッド環境の方がパフォーマンスが向上しました。これは、sleep呼び出し(I/Oのシミュレーション)中にGVLが解放され、他のスレッドがそのGVLを取得できるためです。スレッドはI/O操作中にCPUを効果的に共有できるため、全体的なスループットが向上します。

上でわかるように、mixed_workloadではスレッドが1つであればGVLを待機する必要はありません。スレッドの待機は発生しますが、待機するのはI/Oの完了のみであり、GVLを待機することはありません。

以上から、mixed_workloadでスレッドを3つにすると、GVL待機が発生することがわかります。
🔗 スレッド数を大きく増やせない理由
前のセクションでは、スレッド数を増やすとCPU使用率が向上すると説明しました。では、スレッド数を大きく増やすわけにいかない理由はおわかりでしょうか?図解で説明します。
パフォーマンスを向上させようと思って、前述のコードスニペットのスレッド数を今度は20に増やして、gvlトレースの結果を確認してみましょう。

上の図からわかるように、GVLの競合が大量に発生します。多数のスレッドがGVLをつかもうとして待機しています。
つまりPumaでスレッド数を増やしすぎると、これと同じことが起きるのです。ご存知の通り、リクエストはスレッドごとに処理されるので、GVLの奪い合いが大量に発生すると多数のリクエストが待ちぼうけ状態となり、レイテンシが増加するというわけです。
🔗 次回予告
次回は、max_threadsの理想的な値を探り当てる方法を、アプリケーションの負荷に基づいて、理論と経験の両面から見ていく予定です。
本記事でわかりにくい点がありましたら、LinkedIn、Twitter、BigBinaryサイトまでお問い合わせください。私たちは、Railsアプリケーションをスケールさせる方法を誰もが理解できるよう、わかりやすく書くことを目指しています。
概要
元サイトの許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。