概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: The Practical Effects of the GVL on Scaling in Ruby
- 原文公開日: 2020/05/11
- 著者: Nate Berkopec
- サイト: Speedshop -- フロントエンド、バックエンド、環境を含めたフルスタックのRailsパフォーマンスコンサルタントです。
画像は元記事からの引用ですが、著作権を確認しきれないものはリンクにとどめました。
コンカレンシーとパラレリズムの説明がとても丁寧なのが嬉しいポイントです😋。
Rubyのスケール時にGVLの特性を効果的に活用する(翻訳)
GVLは多くのRubyistを混乱させています。私がこれまで出会ったRubyistのほとんどが、はっきり口に出さないまでもGVLは何らかの点でよくないと感じており、GVLがどこかでコンカレンシーやパラレリズムに関連していると考えています。
VMロックはJavaScriptの有名なV8仮想マシンにもあるのでしょうか?CPythonにも「グローバルな」VMロックはあるのでしょうか?どれも世界にその名を知られた動的言語のビッグスリーですね。VMロックは動的言語ではきわめて普通に用いられています。
CRubyのグローバルなVMロックを理解することは、Rubyアプリケーションのスケーリングを考えるうえで重要です。GVLがCRubyから完全に消えることはまずありえませんが、GVLの振る舞いはRubyアプリを効率よくスケールする方法に影響します。
GVLとは何かを知り、現在のGVLが「グローバル」である理由を知ることで、以下のような疑問の解答を得られるようになります。
- Sidekiqのコンカレンシーをどう設定すべきか
- Pumaのスレッド数はいくつにすべきか
- UnicornやResqueやDelayed.jobからPumaやSidekiqに乗り換えるべきか
- イベントドリブンのコンカレンシーモデル(Nodeなど)のメリットとは
- グローバルロックが存在しない言語VM(ErlangのBEAMやJavaのJVMなど)のメリットとは
- RubyのコンカレンシーがRuby 3でどのように変わるのか
本記事ではこれらの疑問を含めて解説いたします。
⚓ロックの対象は「言語の仮想マシン」だ
「ちょっと待った。それってGILじゃなかったの?GVLってそもそも何よ?」
GILはGlobal Interpreter Lockの略で、かつてRuby 1.9でKoichi SasadaがYARV(Yet Another Ruby VM)を導入したときに、Rubyから取り除かれた「何か」です。YARVによってCRubyの内部構造が変わり、インタプリタではなくRuby仮想マシン上にロックが存在するようになりました。したがって、この10年の正しい用語はGVLであり、GILではありません。
InstructionSequenceクラスを用いることでインストラクションシーケンスとやりとりできます。Rubyではあらゆるものがオブジェクトです!
インタプリタと仮想マシンの違いはどこにあるのでしょう?
仮想マシンは「CPUの中にあるCPU」のようなものです。仮想マシンは、シンプルなインストラクションを受け取るコンピュータプログラムであるのが普通で、インストラクションは内部のステートの一部を操作します。チューリングマシンをソフトウェアで実装すれば、それは一種の仮想マシンになります。マシンと呼ばずに仮想マシンと呼ぶ理由は、(CPUのようなハードウェア上ではなく)ソフトウェア上で実装されているからです。
Ruby 1.9以前は、独立した仮想マシンのステップは実際には存在せず、インタプリタだけがありました。Rubyプログラムを実行すると、実行を進めるときには実際に1行ずつ「解釈(interpret)」していました。現在は、コードを1回だけ解釈して一連のVMインストラクションに変換し、それからインストラクションを実行しています。この方が、Rubyコードを「解釈」するより常に高速です。
チューリングマシンをソフトウェアで実装したものは、一種の仮想マシンです。
Wikimedia Commons by RosarioVanTuple

Ruby仮想マシンが理解するのは、シンプルなインストラクションのセットです。インストラクションはユーザーの書いたRubyコードからインタプリタによって生成され、続いて仮想マシンのインストラクションがRuby VMに送り込まれます。
実際に動くところを見てみましょう。最初は、やったことがない人向けに-eオプションを付けてRubyをコマンドラインで実行します。
$ ruby -e "puts 1 + 1"
2
図へのリンク: スタック上の2つの1を足すVM
このシンプルなプログラムに--dump=insnsを追加するとインストラクションを表示できます。
$ ruby --dump=insns -e "puts 1 + 1"
== disasm: #<ISeq:<main>@-e:1 (1,0)-(1,10)> (catch: FALSE)
0000 putself ( 1)[Li]
0001 putobject_INT2FIX_1_
0002 putobject_INT2FIX_1_
0003 opt_plus <callinfo!mid:+, argc:1, ARGS_SIMPLE>, <callcache>
0006 opt_send_without_block <callinfo!mid:puts, argc:1, FCALL|ARGS_SIMPLE>, <callcache>
0009 leave
RubyのVMは「スタックベース」です。上で生成されたインストラクションを見れば動きがわかります。スタックにintegerの1を2回追加し、続いてplusを呼びます。plusが呼ばれたときのスタック上にはintegerが2つありますが、これらが2という結果に置き換えられ、スタック上には2が置かれます。
さて、このRuby VMがスレッディングやコンカレンシーやパラレリズムとどう関係するのでしょうか?
⚓コンカレンシーとパラレリズム
![]()
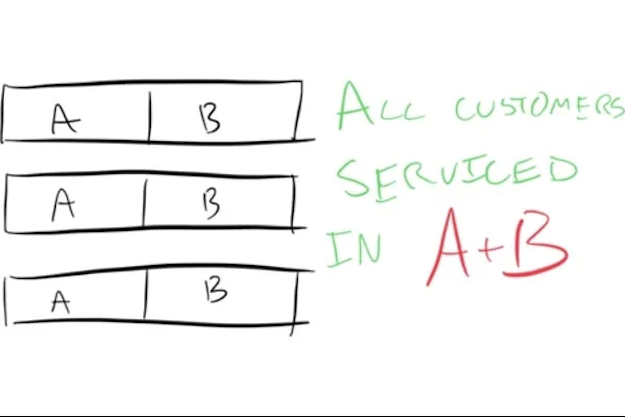
コンカレンシー(concurrency)とパラレリズム(paralellism)の違いについては一応ご存知の方もいるかと思います。ここではスーパーマーケットで考えてみましょう。スーパーのレジの前は行列があり、レジ係の人たちが行列からひとりずつ客を呼んで会計します。
会計を行うレジ係ひとりひとりの作業は「パラレル」になります。作業のためにレジ係同士が声を掛け合う必要はありませんし、あるレジ係がやっている作業は、他のレジ係の作業に何の影響も与えません。このレジ係たちは「100%パラレル」で作業しています。
![]()
さて、レジ係はその気になれば複数のお客を「コンカレントに」さばくこともできます。レジ係は行列からお客を数人まとめてレジに呼び、ある瞬間はお客A、次の瞬間は別のお客B、といった具合に次々に切り替えます。このレジ係は「コンカレント」に作業しています。
もう少し具体的な例を見てみましょう。「3人のレジ係がパラレルに作業する場合」と「ひとりのレジ係がコンカレントに作業する場合」を比べてみます。レジ係がしなければならない作業は「商品のスキャン」と、それに続く「袋詰め」の2つです。スキャンに要する時間と袋詰めに要する時間は、どのお客の場合にもきっかり同じだと仮定します。
お客さんが3人来ました。スキャンにA秒がかかり、袋詰めにB秒を要するとしましょう。レジ係たちが作業をパラレルに進めれば、(A + B)秒で3人のお客さんをさばけることになります。
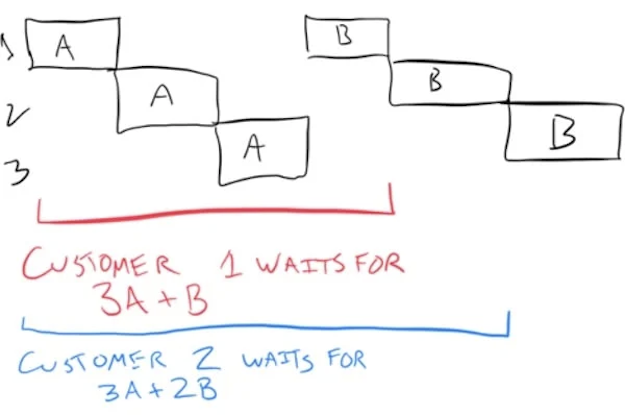
(3A + B)秒になります。お客Aが自分が買った商品を袋詰めしてもらうには、他のお客全員分のスキャンが終わるまで待たなければなりません。次のお客Bをさばくのにかかるトータル時間は(3A + 2B)秒になり、最後のお客Cをさばくにはトータルで(3A + 3B)秒かかります。
これで、ひとりのレジ係がコンカレントに作業するのと、3人のレジ係がパラレルに作業するのとでは、前者の方がトータルの作業時間がどれだけ長くなるかがわかります。
まとめ: コンカレンシーはそれはそれで興味深いものですが、システムをスピードアップして負荷増加に対応できるのはパラレリズムです。
2つの操作をコンカレントに実行するということは、それらの操作の開始時刻と終了時刻がどこかで重なるということです。たとえば私とあなたが向かい合って契約書にサインするとしましょう。ペンは1本しかありません。サインすべき場所に私がサインしたらペンを相手に渡し、今度は相手がサインします。相手はサインし終わったらペンを私に返し、そして私がイニシャルを記入します。この契約作業全体が「コンカレント」に行われていると言えなくもありませんが、しかし決してパラレルになることはありません。ペンは1本しかないので、一度に1人しか契約書にサインできません。
操作をパラレルに実行するということは、それらの操作を「完全に同時に」行うということです。契約書の例でいうと、パラレルな契約作業では2本のペンを使います(たぶん実際には契約書も2通ないとじたばたすることになるでしょう)。
⚓コンピュータ上のコンカレンシーとパラレリズム
モダンなオペレーティングシステム(OS)上のプログラムは、プロセス(process)とスレッド(thread)の組み合わせで動作します。プロセスには少なくとも1つのスレッドがあり、多い場合は数千のスレッドができることもあります。
先ほどのスーパーの例を拡張して説明すると、プロセスは1人のレジ係が使う「レジカウンター」に似ています。レジカウンターにはレジやバーコードスキャナーといった道具やリソースが揃っていますが、レジカウンター自身は「何もしません」。ひとつのプロセスには、メモリアロケーション(ヒープ)や(ソケットやファイルなどの)ファイルディスクリプタなどのさまざまなコンピュータリソースが含まれています。
実際にコードを実行するのはスレッドです。プロセスごとに1つ以上のスレッドが存在します。スーパーの例で言うと、スレッドはレジ係に似ています。スレッドにも若干の情報が含まれており、たとえばRailsアプリケーションでローカル変数を2つ追加すると、スレッドには2つの変数に関する情報が置かれ(スレッドローカルストレージ)、現在実行中の行も置かれます(スタック)。
図へのリンク: MEME: Pentium
「ここ西暦何年よ?」
「あいつに聞いてみようぜ」
「すいませ〜ん、今使ってるCPUのコア数っていくつですか〜?」
「ワイのPentium 3はな...」
「1999年じゃん」
1990年代にRubyが生まれたときは、どのプロセスにもスレッドが1つしかありませんでした。この部分の変更は2000年代前半から始まり、Ruby 1.9では言語VMを書き直す必要が生じました(YARV)。このときできたのが、今の私たちが知っているGVLです。
⚓GVLが実際に行っていること
前述したように、RubyのVMはRubyの(インタプリタが生成した)仮想マシンインストラクションをCPUインストラクションに実際に変換します。
図へのリンク: 「そちらのVMロックについていま一度お尋ねしたいんだが」
Ruby VMは内部のスレッド安全性を意図していません。2つのスレッドがRuby VMに同時にアクセスしようとしたら実にマズいことになるでしょう。これはスーパーのレジカウンターにあるレジで精算するときと少し似ています。2人のレジ係が同じPOS端末を操作しようとしたら、お互いの作業が邪魔されて台無しになるので、一方の精算が終わるまで待つことになるでしょう。
つまり、複数のスレッドがRubyのVMに同時にアクセスするのは安全ではありませんので、代わりにVMにグローバルロックをかけて一度に1つのスレッドだけがパラレルにアクセスできるようにしているわけです。
動的言語のVMがスレッドセーフでないのは珍しくも何ともありません。上述のCPythonやV8はその最も典型的な例です。Javaはおそらく、スレッドセーフなVMを持つ準動的な言語のベストな例と言えるでしょう。JVM上で構築されている言語がたくさんある理由がこれです。スレッドセーフなVMを自力で書くのはものすごくつらい作業です。
図へのリンク: ロックが常に発生し、しかも「実装の腕前」と「誰が実装したか」以外に
違いがないことに気づいたときのオレの気持ち
GVLがこれほど普及しているのには、もっともな理由があります。
- 速い。内部でロック/アンロックを繰り返す必要がないのでシングルスレッドのパフォーマンスが向上する。
- C拡張などの拡張を統合しやすい
- 大量にロックをかけるVMより、ロックをかけないVMの方が作りやすい
Rubyでは各プロセスが独自のグローバルVMロックを持つので、「プロセス規模のVMロック」と呼ぶ方がもう少し正確かもしれません。この「グローバル」という語は、グローバル変数がグローバルなのと同じ感覚です。
Rubyではどのプロセスもスレッドを1つしか持たないので、グローバルVMロックを好きなだけ長く維持できます。そしてRubyコードを実際に実行するには1つのスレッドがRuby VMにアクセスする必要があるので、Rubyコードをいつでも実行できるのは事実上1つのスレッドだけです。
GVLは、言ってみればゴールディングの小説『蝿の王(Lord of the Flies)』に登場するホラ貝のようなものかもしれません。少年たちは、ホラ貝を持っているときだけ発言権を獲得できます(つまりここではRubyコードを実行できる)。GVLが他のスレッドによってロックされていたら、残りのスレッドたちはGVLが解放されて自分たちがGVLを取得できるようになるまで待つしかありません。
⚓アムダールの法則: Sidekiqのプロセス1個がDelayedJobやResqueの倍も効率が高い理由
ユーザーの書くRubyプログラムで行われる作業の多くは、Ruby VMにアクセスする必要がありません。最も重要なのは、データベース呼び出しやネットワーク呼び出しなどの「I/O待ち」です。これらの操作はCで実行されますが、このときスレッドはそのI/Oから戻るまで明示的にGVLを解放します。I/Oから戻ると、スレッドはプログラムの指示を続行するために、GVLを再び獲得しようと試みます。
そしてこの部分が現実のパフォーマンスに甚大な影響を及ぼします。
Rubyで処理しなければならない衛星画像データがひとかたまりあるとしましょう。これを処理するためにSatelliteDataProcessorJobというSidekiqジョブを書き、各ジョブはすべての衛星画像データを小分けにした部分を処理するとします。
class SatelliteDataProcessorJob
include Sidekiq::Worker
def perform(some_satellite_data)
process(some_satellite_data)
touch_external_service(some_satellite_data)
add_data_to_database(some_satellite_data)
end
end
上のprocessメソッドが100% Rubyで書かれていて、C拡張や外部サービスを呼び出さないとします。さらに、touch_external_serviceメソッドやadd_data_to_databaseメソッドのI/O効率が100%で、処理時間のほとんどがネットワーク待ちで終わるとしましょう。
最初は簡単な問題からいきましょう。各SatelliteDataProcessorJobの実行に1秒を要し、キューに100件のジョブがあり、Sidekiqのプロセスは1個、スレッドがその中に1個あるとします。このとき、ジョブがすべて完了するのに何秒かかるでしょうか?CPUやメモリのリソースは無限だとします。
答え: 100秒
プロセスが2個の場合は50秒、そしてプロセスが4個の場合は25秒...という具合に逓減します。これが「パラレリズム」です。
さて、今度はSidekiqプロセス1個にスレッドが10個あるとします。ジョブがすべて完了するのに何秒かかるでしょうか?
答え: 「場合による」。JRubyかTruffleRubyを使っていれば10秒で終わります。各スレッドが他のスレッドに対して完全にパラレルになるからです。
しかしMRIには例のGVLが住んでいます。スレッドを追加するとコンカレンシーは増加するでしょうか?

ジーン・アムダールが1967年に関心を寄せていたのは、まさしくこの問題だったのです。アムダールの提案は現在アムダールの法則と呼ばれていますが、これは負荷を固定してリソースを増やしたときにタスクの実行速度がどのように向上するかを理論的に考察したものです。
アムダールは、パラレリズムの追加による速度向上は、パラレルに実行される時間の比率に関連していることを突き止めました。どこかで聞いたような話ですね。
アムダールの法則は1 / (1 - p + p/s)というシンプルなものです。pはタスクがパラレルに実行される割合(パーセンテージ)、sはタスクのうちリソースを増やした部分(パラレルになる部分)によって得られる高速化の係数です。
つまり、先ほどの例でSatelliteDataProcessorJobの半分はGVLに束縛され、残りの半分はI/Oに束縛されているとしましょう。この場合はI/Oを待つことは可能で、かつスレッドが10個なので、pは0.5、sは10になります。アムダールの法則は、このときのSidekiqプロセスが、シングルスレッドのResqueやDelayedJobのプロセスと比較して1.81倍も高速にジョブを完了することを示します。
Rubyのバックグラウンドジョブの多くは、I/O待ちに少なくとも処理時間の半分を費やしています。Sidekiqなら、そうしたジョブのリソース消費は半分以下で済む可能性もあります。Sidekiqプロセス1個は、シングルスレッドプロセス2個に相当する作業を行えるからです。
すなわちGVLがあっても、アプリケーションにスレッドを追加すれば、プロセスあたりのスループットが向上し、ひいてはメモリ消費も低減されるのです。
⚓スレッド、Puma、GVL由来のレイテンシ
これで「SidekiqやPumaで必要なスレッド数はいくつか」という疑問に答えられます。すなわち「スレッドが非GVL実行にどのぐらい時間を要するか」つまり「自分のプログラムはI/O待ちにどのぐらいの時間を使っているか」がわかればよいのです。I/Oに要する時間の割合が非常に高い場合(75%以上)の負荷はスレッドが16個以上あればたいてい改善されますが、通常の負荷ならスレッドが3〜5個もあれば改善できます。
ただしスレッドプールの設定を「大きくしすぎる」こともできてしまいます。PumaやSidekiqのスレッド設定を5以上にすると、処理のパラレル化が不十分な場合にGVLが競合してサービスのレイテンシが増加する可能性があります。
すべての作業単位を処理するのに要するトータル時間は変わりませんが、各作業単位でのレイテンシが増加します。
再びスーパーで考えましょう。レジ係が待ち行列から16人のお客を呼んでコンカレントに作業するとしましょう。お客ごとに品物をひとつずつスキャンしてから、次のお客のカートのスキャンに進みます。このときお客が精算に要する時間は(A + B)秒ではなく、16(A + B)になります。
一部の人はこの遅延追加を「コンテキストスイッチ」のコストだと思いこんでいますが、個別の作業単位で発生するレイテンシは「コンテキストスイッチのコストを増やさずに」増加します。
いずれにしろ、モダンなコンピュータやOSにおけるコンテキストスイッチのコストは、典型的なWebアプリにおけるリクエストやバックグラウンドで要する処理時間に比べればたかが知れています。レスポンス時間が数百ミリ秒も増えたりしません。ただしGVLが飽和すれば別ですが。
CRubyのプロセスにスレッドを追加すればレイテンシが増加するのに、それでもスレッド追加が有用な理由は何でしょうか?
Rubyプロセスにスレッドを追加することは、プロセスを追加するトータルコストに比べて少ないメモリ使用量で、CPU利用率を改善するのに有用です。プロセスを1個追加するたびにメモリを512MB消費しますが、スレッドを1個追加する場合のメモリ使用量の増加はおそらく64MBに届かないでしょう。スレッドを1個ではなく2個追加すれば、最初のスレッドがGVLとI/Oリッスンを解放したときに2つ目のスレッドが新しい作業を引き受けられるので、スループットとサーバー利用率が増大します。
GitLabはWebサーバーをUnicorn(シングルスレッドモデル)からPuma(マルチスレッドモデル)に切り替え、メモリ使用量を30%も削減しました(#7455のコメント)。ホストのメモリが制限されているのであれば、この方法でメモリサイズが同じままでスループットを30%向上できるわけです。スゴいじゃありませんか。
⚓今後はどうなるか
ここ10年「Rubyにはまともなコンカレンシーがない」という理由でRubyはもう死んでいるという外野からの声を目にします。
ここまで説明したように、Rubyにはコンカレンシーがあると思います。まず、Rubyにはプロセスベースのコンカレンシーがあります。プロセスを増やせばGVLも増やせます。メモリが十分あればの話ですが、これについては何の問題もなくやれます。
メモリが足りなくなったら、SidekiqやPumaを使うとよいでしょう。どちらもアプリにスレッドセーフなコンテナを提供し、プリエンプティブなスレッドでやれるようになります。
Rubyのプロセスベースのコンカレンシー(実際はGVLがそれを強要しているわけですが)が十分スケールすることが立証されました。昨今はクラウドプロバイダのメモリも随分安くなっているので、コストも他のモデルと比べてさほどではありません。「アクタースタイル」のアプローチや「Ealang Processスタイル」のアプローチでは、一日の終りに行うデプロイ作業が実際にどう変わるかを批判的に考えてみましょう。CPUごとのメモリ使用量は減るでしょうが、多くのWebアプリケーションが大規模なデプロイ作業で既に直面している問題はCPUのボトルネックであり、メモリではありません。
⚓Ractorについて
- Ractorドキュメント: ruby/ractor.ja.md at ractor · ko1/ruby
YARVの作者であるKoichi Sasadaは、Ruby 3向けの新たなコンカレンシー抽象化としてRactorを提案しています。Ractorの提案はアクター(Actor)コンカレンシーモデルを元にしています(RubyのActorだからRactorというわけです)。アクターは複数のオブジェクトを収める箱であり、各アクターは自分が所有しているオブジェクトにしかアクセスできませんが、他のアクターにオブジェクトを送信したり他のアクターからオブジェクトを受け取ったりすることはできます。Koichi Sasadaによるコード例を以下に示します。
r = Ractor.current
rs = (1..10).map{|i|
r = Ractor.new r, i do |r, i|
r.send Ractor.recv + "r#{i}"
end
}
r.send "r0"
p Ractor.recv #=> "r0r10r9r8r7r6r5r4r3r2r1"
(現時点の実装には含まれていませんが)最終的には各Ractorが独自のVMロックを取得するようになります。つまり上のコード例はパラレルに実行されるようになるということです。
Ractorでパラレル実行が可能になる理由は、ミュータブル(=改変可能)なステートを共有しないからです。Ractorではイミュータブル(=不変)なオブジェクトしか共有できません。すなわち、1つのRactorの中ではVMロックが不要になるということです。
Koichi SasadaによるRactorのプロポーザルは現在公開されています。ほぼほぼ日本語で書かれているのと、先ほどの「各Ractorが独自のVMロックを取得する」が未実装という状態ではありますが。Ractorは本質的に1プロセス内でのGVLを増やせるので、各Ractorの中には引き続きロックが存在することになりますが、もはやGVLは「グローバル」ではなくなります。
⚓まとめ
私のつぶやきを読んでいただいた皆さまに感謝申し上げます。皆さまに知っていただく必要のあるリストを以下にメモしました。
- 皆さんがRubyでメモリのボトルネックに遭遇した場合は、スレッドを追加してGVLを飽和させる必要があります。それによって「少ないメモリ使用量でCPUをより効率よく動かせる」ようになります。
- そのときのGVLは、RubyのI/Oでパラレリズムに制限がかかっているので、まずマルチスレッドのバックグランドジョブプロセッサに切り替え、それから続いてマルチスレッドWebサーバーに切り替えてください。その場合、Webサーバーで用いるスレッドプールのサイズよりもずっと大きなスレッドプールのサイズをバックグラウンドジョブに割り当てることになるでしょう。
- おそらくRuby 3では、RactorでVMを増やせるようになることでGVLがグローバルでなくなるでしょう。アプリケーション・サーバーやバックグラウンドジョブプロセッサでこのメリットを得るためにはバックエンドの変更が必要になると思われますが、実際にはコードを全面的に変更する必要はありませんし、スレッド安全性を気にする必要もなくなるでしょう(やったね😋)。
- プロセスベースのコンカレンシーは非常によくスケールします。他のコンカレンシーモデルより数ミリ秒余分に時間を食うかもしれませんが、典型的なRailsアプリではコンカレンシー切り替えのコストは一般に問題になりません。その代わりCPUの飽和の重要性が増します。現代のコンピューティング環境で最も不足しがちなリソースはCPUです。
⚓お知らせ: もっと速いWebサイトが欲しい方へ
私はNate Berkopecと申します(@nateberkopec)。フルスタック開発者の視点から、主にフロントエンドやRubyバックエンドのWebパフォーマンスに関する記事を書いています。この記事を気に入っていただいた方や次の記事が読みたくなった方は、元記事末尾のSubscribeボタンをクリックしてください。週一ぐらいのペースでささやかな直送メールをお届けします(スパムメールは送りませんのでご心配なく)。
⚓お知らせ: 書籍『The Complete Guide to Rails Performance』
私の近著もぜひご覧ください!『The Complete Guide to Rails Performance』はRuby on Railsアプリケーションを高速化し、スケーラブルかつメンテナンスしやすくするツールを手にするためのフルスタックコースです。361ページのPDFの他に、プライベートSlackと15分の動画コンテンツも付属します。

おたより発掘
読みました📝
Nateさんの記事の翻訳。この記事でGVLの概念を初めて知ったプロセス&スレッド初心者にも分かりやすい、とても丁寧な記事でした。Rubyのスケール時にGVLの特性を効果的に活用する(翻訳) https://t.co/Hmr9KnISFZ
— Misaki Shioi (しおい) (@coe401_) June 1, 2020
一箇所だけ「YARVは笹田くんの博士論文で(学部)卒論ではない」
Link: Rubyのスケール時にGVLの特性を効果的に活用する(翻訳)|TechRacho(テックラッチョ): https://t.co/g6cgAt0IsF— Yukihiro Matz (@yukihiro_matz) May 28, 2020
訂正いたしました(2020/05/29)🙇。