Railsスケーリング(4): Active Recordコネクションプールの適切な設定を理解する(翻訳)
本記事は、「Railsをスケーリングする」シリーズのパート4です。
🔗 データベースのコネクションプールとは
Railsアプリケーションは、データベースとやりとりする必要が生じると、「コネクション(connection)」を確立します。コネクションとは、アプリケーションとデータベースサーバー間の専用通信チャネルです。
Railsが新しいリクエストを1件受信すると、以下のような操作が実行されます。
- コネクションを作成する
- データベース操作を実行する
- コネクションをクローズする
以後、リクエストを受信するたびに上の処理を繰り返します。
データベースコネクションの作成は、コストのかかる操作です。作成のたびに、コネクションの確立、認証、通信チャネルのセットアップを行うための時間がかかります。つまり、リクエストが到着するたびにコネクション設定に時間を取られてしまうことになります。
事前に確立済みのコネクションをどこかに保存しておいて、新しいリクエストを受信したら、そのプール(pool)に保存したコネクションを取得する方がよさそうです。これなら、リクエストを受信するたびにコネクションを作成したりクローズしたりする必要がなくなるので、処理を短縮できます。
改善後の新しい処理は以下のような感じになります。
- コネクションを作成する
- データベース操作を実行する
- コネクションをプールに保存する
この場合、新しいリクエストを受信したときの操作は以下のようになります。
- プールからコネクションを取得する
- データベース操作を実行する
- コネクションをプールに戻す
データベースコネクションをこのようにプールに保存する手法は、再利用可能なデータベースコネクションのセットを保持する形でパフォーマンスを最適化する手法のひとつです。
🔗 Active Recordにおけるコネクションプールの実装
Active Recordは、データベースコネクションプールをWebプロセスやバックグラウンドプロセスごとに管理します。プロセスごとに独自のコネクションプールを持つので、マルチプロセス(PumaプロセスやSidekiqプロセスなど)で実行されるRailsアプリケーションでは、独立したコネクションプールが複数存在することになります。このプールは、同じプロセス内のスレッド間で共有されるさまざまなデータベースコネクションをまとめたものです。
プーリングはプロセスレベルで行われることにご注意ください。あるプロセスのスレッドは、別のプロセスのコネクションを取得できません。
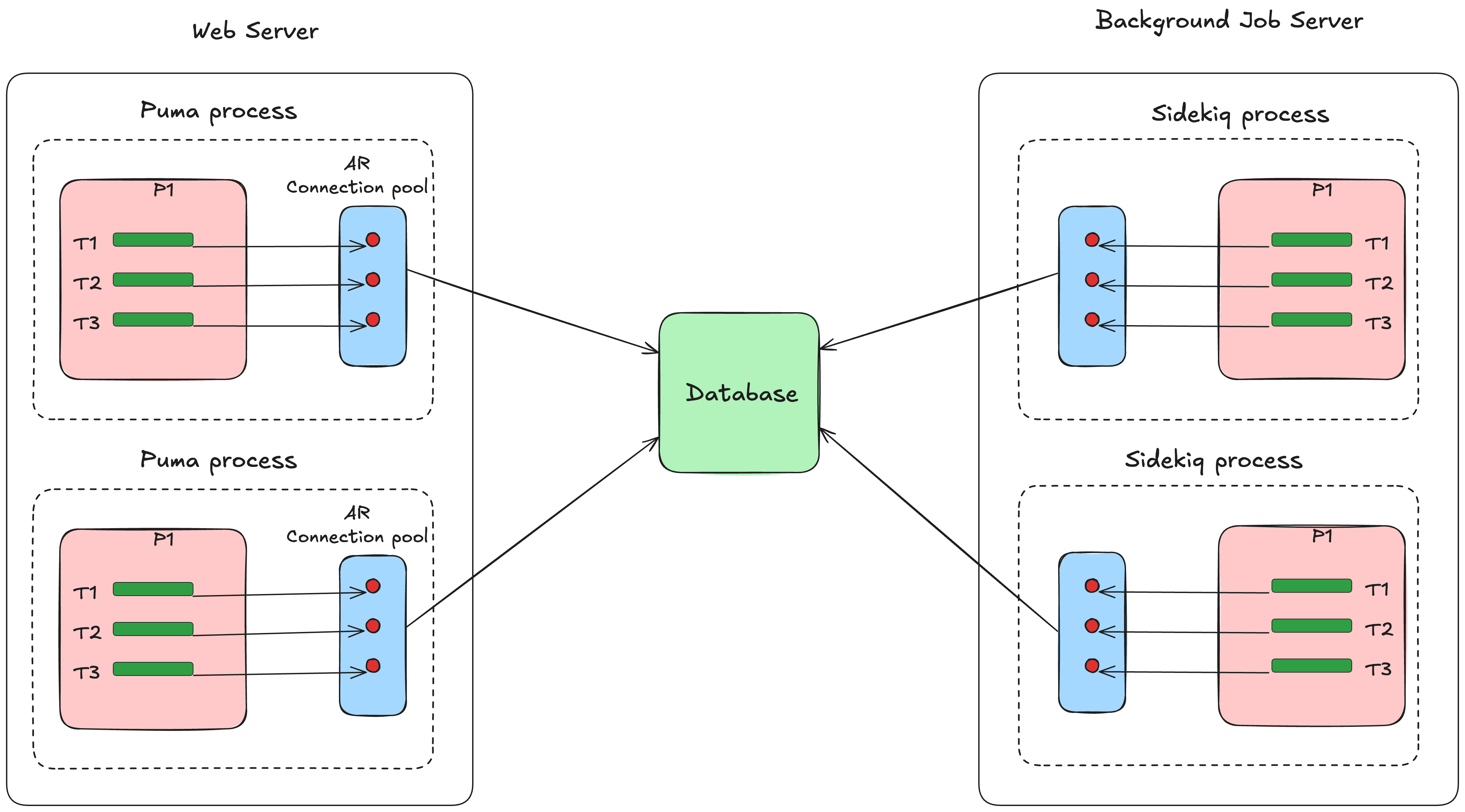
スレッドでコネクションが必要になると、スレッドはプールからコネクションをチェックアウト(=借り出し)し、データベース操作を実行したら、コネクションをプールに返却します。
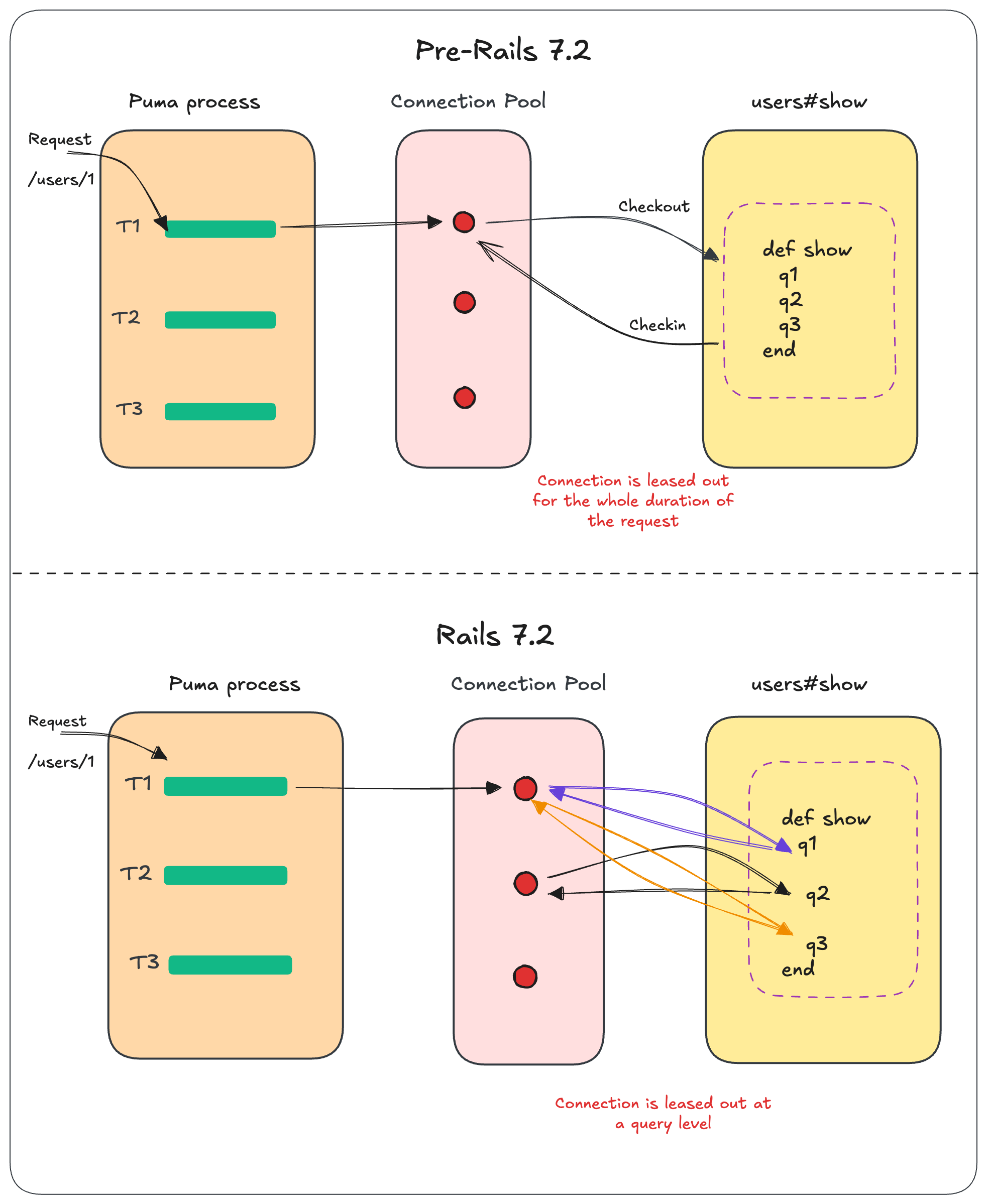
これはクエリレベルで実行されるので、コネクションは個別のクエリごとにリースされ、利用後にプールに返却されます。
Rails 7.2より前のコネクションは、Webリクエストの場合はWebリクエストが完了するまでリースされ続け、バックグラウンドジョブの場合はジョブが完了するまでリースされ続けます。しかしこの方法は、I/O処理に多くの時間がかかるアプリケーションでは問題でした。スレッドはI/O処理の間ずっとコネクションを占有するため、同時に実行できるクエリ数が制限されていました。
コネクションのリースがリクエスト単位からクエリ単位に変わったことに伴い、クエリキャッシュが効くようにするため、クエリキャッシュをコネクションプールが所有する形に変更されました(#50938)。
これは、クエリキャッシュがプール内のすべてのコネクションで共有されるようになったことを意味します。従来は、コネクションごとに独自のクエリキャッシュを持っていましたが、リクエスト全体を通じて同じコネクションを使うことになるため問題ありませんでした。
しかし現在はクエリごとにコネクションがリースされるため、プール内のすべてのコネクションでクエリキャッシュを共有する必要があります。
🔗 コネクションプール設定のオプション
Active Recordのコネクションプールの振る舞いは、database.ymlファイル内のさまざまな設定オプションでカスタマイズできます。
pool- プールで保持するコネクションの最大数を設定します。デフォルトは
RAILS_MAX_THREADSですが、それ以外の値も設定できます。RAILS_MAX_THREADSに設定すると小さな問題が生じますが、これについては後述します。 checkout timeout- コネクション取得を待っているスレッドがタイムアウトするまでの時間を指定します(デフォルトは
5秒)。すべてのスレッドが利用中のときに待機時間がこの値を超えると、ActiveRecord::ConnectionTimeoutError例外が発生します。 idle timeout- コネクションがプールから削除されるまでアイドリング可能な時間を指定します(デフォルトは
300秒)。これにより、未使用のコネクションからリソースを回収しやすくなります。 reaping frequency- デッドコネクションやアイドルコネクションを回収するReaperプロセス(後述)を実行する頻度を指定します(デフォルトは
60秒)。
🔗 コネクションプールのReaperとは
データベースコネクションは、データベースの再起動やネットワーク問題などが原因で「切断」されることがあります。Active Recordは、これを処理するためにReaperを提供しています。
Reaperは定期的にプール内のコネクションをチェックして、デッドコネクションや、長時間チェックアウトされたままのアイドリングコネクションを削除します。
Reaperは、データベースコネクションにおけるガベージコレクタのようなものです。Reaperは、上述のidle_timeout設定を用いてアイドリングコネクションを削除するまでの最大アイドリング時間を決定し、コネクションが最後に利用された時刻に基づいてアイドリング時間をトラッキングします。
もう1つのreaping_frequency設定オプションは、デッドコネクションやアイドルコネクションを回収するReaperプロセスを実行する頻度を指定します。デフォルトは60秒です。つまり、Reaperは1分おきに起動してメンテナンスタスクを実行します。
アプリケーションが受信するトラフィックが急上昇しがちな場合は、このreaping_frequencyやidle_timeoutの値を小さめに設定してみましょう。これにより、Reaperの実行頻度が増えてアイドリングコネクションが削除されやすくなり、コネクションプールの健全性や応答性を維持しやすくなります。
🔗 アイドリングコネクションが良くない理由
データベースのアイドリングコネクションによってデータベースのパフォーマンスが著しく悪化する理由は、相互に絡み合っています。
メモリ消費量: データベースコネクションは、アイドリング状態であってもメモリアロケーションを保持し続けます。データベースは、セッション状態、バッファ、ユーザーコンテキスト、トランザクションワークスペース用にコネクションのメモリを確保しなければなりません。
このメモリは、コネクションが何も仕事をしていなくてもアロケーションされたままになります。たとえば1コネクションあたり10MBのメモリを消費するとすると、アイドリングコネクションが100個になれば、本来ならアクティブなクエリやキャッシュなどの生産的な作業に使えたはずのデータベース用メモリが1GBも無駄に消費されてしまうことになります。
CPUオーバーヘッド: アイドリング(idle)は何もしていない状態を指しますが、その間もデータベースはコネクションごとに定期的なメンテナンス作業(死活チェックによるコネクションの健全性監視やプロセステーブルの管理など)を実行し続けなければなりません。
ここで重要な問題は、アイドリングコネクション数が増えたときのオーバーヘッドは非線形に増加することです。アイドリングコネクションが増えるに連れて、データベースが消費するコネクション管理用のCPU時間の増加ペースも上がり、本来のクエリ処理用のCPU時間が圧迫されてしまいます。
幸い、これについてはReaperが処理してくれます。
🔗 Webとバックグラウンドプロセスで使われる最大コネクション数は?
既に学んだように、コネクションプールはプロセス単位で管理されます。Railsプロセスごとに独自のプールを持ちます。
- Webプロセス(Puma)の場合
個別のPumaプロセスは互いに独立したプロセスであり、それぞれのプロセスが独自のコネクションプールを持ちます。プロセス内では、個別のスレッドが1個のコネクションをチェックアウトできます。
すなわち、プロセスごとに必要なコネクションの最大数はPumaのmax_threads設定と等しくなります。
- バックグラウンドプロセス(Sidekiq)の場合
Sidekiqは、独自のコネクションプールを持つ別プロセスとして実行されます。スレッド数はSidekiqのconcurrency設定によって決定されるため、必要なコネクションの最大数はそのconcurrency値と等しくなります。
注: Sidekiq swarmで複数のSidekiqプロセスを実行している場合は、その点も考慮すること。
ここから、典型的なRailsアプリケーションで潜在的に必要となるコネクションの合計数を以下のように算出できます。
- Webコネクション数 = Webのdyno数 ✕ Pumaプロセス数 ✕
max_thread値 -
バックグラウンドコネクション数 = ワーカーのdyno数 ✕ Sidekiqプロセス数 ✕ プロセスあたりのスレッド数
-
最大コネクション数 = Webコネクション数 + バックグラウンドコネクション数
ここでご注目いただきたいのは、データベースでこれほど多くの同時接続数をサポートする必要があるという点です。
注意: プリブートが有効になっている場合は、上で求めた最大コネクション数の倍の値が必要です。これは、リリースフェイズでは新しいdynoと古いdynoが同時に実行される期間が短時間生じるためです。
Rails 7で導入されたload_asyncを使うと、データベースクエリをバックグラウンドスレッドで非同期的に実行できます。load_asyncを使う場合は、必要な最大コネクション数の算出方法が少し変わります。
まずはload_asyncのしくみを理解しておきましょう。
🔗 load_asyncのしくみ
Railsのload_asyncを使うと、複数のデータベースクエリをバックグラウンドのスレッドで非同期実行可能になります。遅延読み込みされるActive Recordクエリと異なり、load_asyncのクエリは常にバックグラウンドスレッド内で即時実行され、結果が必要になった時点でメインスレッドに合流します。
非同期エグゼキュータはconfig.active_record.async_query_executorで設定できます。
以下の3通りの設定が可能です。
- 1.
nil(デフォルト) - 非同期クエリは無効になり、
load_asyncはクエリを同期実行します。 - 2.
:global_thread_pool - データベースの全コネクションをシングルスレッドのプールで扱います。
- 3.
:multi_thread_pool - データベースコネクションごとに独立したスレッドプールを利用します。
Railsにはglobal_executor_concurrencyという設定もあり、1プロセスあたりで実行可能な非同期のコンカレントクエリ件数を制御します(デフォルト: 4)。
つまり、load_asyncを利用すると、1プロセスあたりの最大コネクション数は以下のように算出できます。
- 1プロセスあたりの最大コネクション数 = プロセスレベルのコンカレント実行数 +
global_executor_concurrency+ 1
このプロセスレベルのコンカレント実行数は、Pumaプロセスではmax_threadsの値が、Sidekiqプロセスではsidekiq_concurrencyの値が該当します。
+ 1はメインの制御スレッド用です。
状況によっては、一時的に追加のコネクションが必要となることもあります(例: クラス読み込み時のモデルイントロスペクション)。
なお、Judoscaleの中の人が作成した以下のサービスを使うと、アプリケーションで必要な最大コネクション数を手軽に算出できます。
🔗 データベースのプールサイズを設定する
database.ymlファイルには以下の行があります。
pool: <%%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
1個のスレッドは、データベースコネクションを2つ以上必要としないことがわかっているので、1つのプールで必要なコネクション数は、スレッドの総数と等しくなります。つまり上の設定はこのままでよさそうです。
しかし、この設定ではload_asyncを使うかどうかが考慮されていません。load_asyncを使うのであれば、1プロセスあたりで必要な最大コネクション数はRAILS_MAX_THREADS + global_executor_concurrency + 1となります。
適切なプールサイズを得るためにこんなに事細かく調べる必要はあるのでしょうか?実はもっと手軽な方法があります。
ホスティングサービスのプロバイダは、ほとんどの場合最大コネクション数の情報を提供しているので、プロバイダのデータベースプランでサポートされている最大コネクション数をプールに設定すればよいのです。
たとえば、Herokuの"Standard-0"データベースを使っている場合、そこでサポートされている最大コネクション数は120なので、その値をプールに設定すればよいのです。
pool: 120
この方法でよい理由は、データベースコネクションがプールで遅延初期化されるためです。アプリケーションは必要以上のデータベースコネクションを作成しないので、ここでは保守的に考える必要はありません。
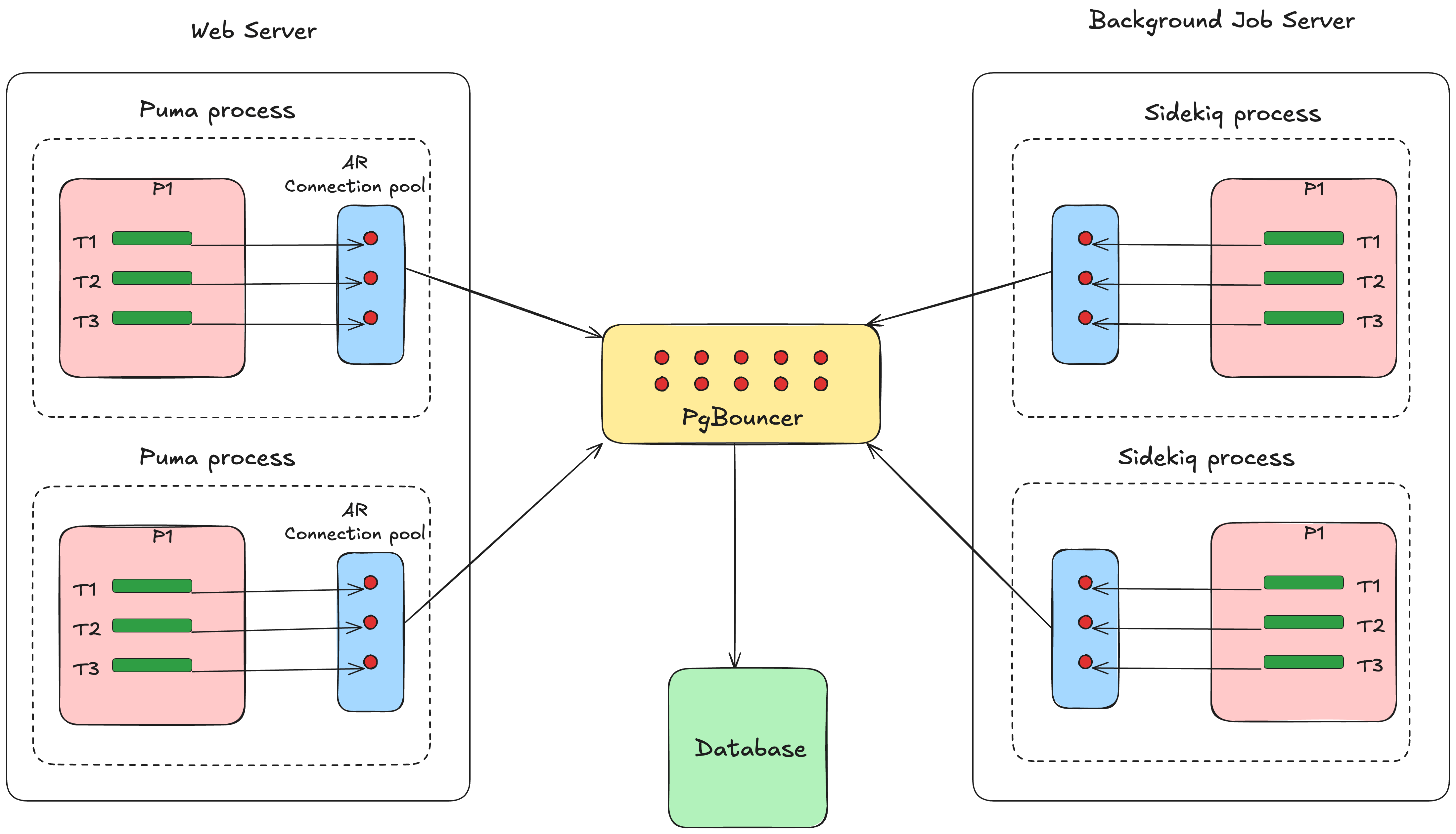
唯一注意すべきは、最大コネクション数がデータベースプランの上限を超えないようにすることです。超える場合は、PgBouncerという別のソリューションが使えます。
🔗 PgBouncer

PgBouncerはPostgreSQL用の軽量なコネクションプーラーであり、アプリケーションとPostgreSQLデータベースの間に位置して、データベースコネクションのプールを管理します。
PgBouncerもActive Recordもコネクションプール機能を提供していますが、両者の動作レベルも利用目的も異なっています。
Active RecordのコネクションプールはRubyの単一プロセス内で動作し、そのプロセス内のスレッドを対象にコネクションを管理します。
PgBouncerは外部のコネクションプーラーであり、アプリケーションとPostgreSQLデータベースの間に位置して、アプリケーションの全プロセスを対象にコネクションを管理します。
🔗 ActiveRecord::ConnectionTimeoutErrorは恐ろしい
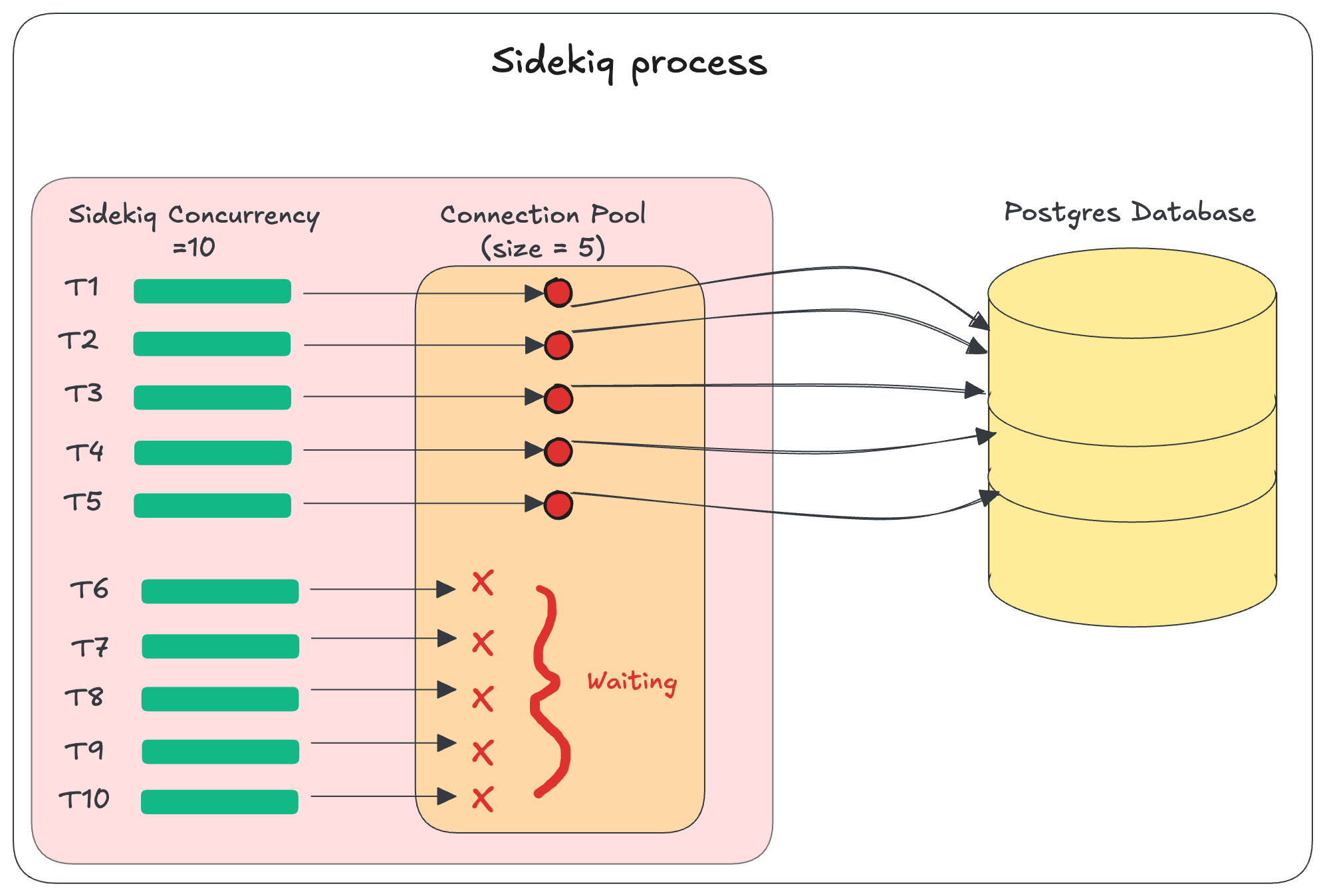
このエラーは、スレッドがコネクションを取得するために待機する秒数がcheckout_timeoutを超えたときに発生します。これは、poolサイズの設定値がコンカレンシー数を下回っているときによく発生します。
たとえば、Sidekiqのコンカレンシー数が10で、プールサイズが5になっているとします。コネクションを要求するスレッドの数が5つを超えると、スレッドはコネクションを待機するしかなくなります。
これを解決するには、前述のようにpoolに十分大きな値を設定すれば、ほとんどの場合エラーが解消するはずです。
poolの値を正しく設定しても、ActiveRecord::ConnectionTimeoutErrorエラーが引き続き発生して困ってしまうことがあります。この問題が発生するシナリオをいくつか検討してみましょう。
🔗 カスタムコードが新しいスレッドを立ち上げてコネクションを占有している場合
class SomeService
def process
threads = []
5.times do |index|
threads << Thread.new do
ActiveRecord::Base.connection.execute("select pg_sleep(5);")
end
end
threads.each(&:join)
end
end
上では5つのスレッドが起動されています。これらのスレッドも、プロセスに割り当てられている同じプールからコネクションを取得していることに注意してください。
🔗 Active Storageのプロキシモード
アプリケーションで新しいスレッドが起動していなくても、Rails自身がスレッドを追加することがあります。Active Storageのプロキシモードなどがそうです。
Active Storageのプロキシコントローラ(1、2)はレスポンスをストリームとして生成しますが、この処理は専用のスレッドを必要とします。
つまり、Active Storageファイルを2つのプロキシコントローラのどちらかで配信すると、実際にはRailsで2つのスレッドが使われることになります(1つはメインのリクエスト処理用、もう1つはストリーム処理用)。どちらのスレッドも別々のデータベースコネクションをActive Recordのコネクションプールから取得する必要があります。
🔗 Rack-timeout gem

rack-timeoutは、Railsアプリケーションで長時間実行されているリクエストを自動終了するのによく用いられます。これは低速なリクエストによってサーバーリソースが占有されるのを防ぐのに有用ですが、いくつか問題を引き起こすこともあります。
rack-timeoutでは、設定されたタイムアウト値を超えたリクエストを終了させるためにRubyのThread#raise APIを用いています。タイムアウトが発生すると、rack-timeoutがRack::Timeout::RequestTimeoutExceptionを別スレッドでraiseします。
スレッドでデータベース操作を実行中にこの例外が発生すると、データベースコネクションが適切にクリーンアップできなくなる可能性があります。
🔗 ActiveRecord::ConnectionTimeoutErrorsをトラッキングする
アプリケーションでActiveRecord::ConnectionTimeoutError例外が頻発する場合は、コネクションプールの情報をエラー監視サービスにログ出力することで追加のコンテキストを得られます。これは、エラー発生時にどのスレッドがコネクションをつかんでいたかを特定するのに有用です。
config.before_notify do |notice|
if notice.error_class == "ActiveRecord::ConnectionTimeoutError"
notice.context = { connection_pool_info: detailed_connection_pool_info }
end
end
def detailed_connection_pool_info
connection_info = {}
ActiveRecord::Base.connection_pool.connections.each_with_index do |conn, index|
connection_info["connection_#{index + 1}"] = conn.owner ? conn.owner.inspect : "[UNUSED]"
end
connection_info["current_thread"] = Thread.current.inspect
connection_info
end
<スレッドオブジェクト>.inspectを実行すれば、スレッドの名前とid、ステータスが出力されます。たとえば、ハッシュ内のあるエントリが#<Thread:0x00006a42eca73ba0@puma srv tp 002 /app/.../gems/puma-6.2.2/lib/puma/thread_pool.rb:106 sleep_forever>であれば、Pumaスレッドがコネクションをつかんでいることになります。
🔗 Active Recordコネクションプールの統計情報を監視する
Active Recordコネクションプールの統計情報を監視するには、データをグラフ表示できるサービスプロバイダに定期的に統計情報を送信する必要があります。私たちの場合、統計情報を定期的に確認するためにrufus-scheduler gemを使っています。

データの収集や表示にはNewRelicを使っていますが、お好みのAPMサービスを使っても構いません。プールの統計情報は15秒おきに送信するように設定しています。データ送信用のgistは以下に置いてあります。
本記事でわかりにくい点がありましたら、LinkedIn、Twitter、BigBinaryサイトまでお問い合わせください。私たちは、Railsアプリケーションをスケールさせる方法を誰もが理解できるよう、わかりやすく書くことを目指しています。
概要
元サイトの許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。