とある案件で、Grover を使って生成したPDFの内容をテストするRSpecがローカル環境でのみ失敗してしまうということがありました。

テストコードは以下のような感じです。
pdf = PDF::Reader.new(io)
contents = pdf.pages.first.runs.map(&:text)
expect(contents).to include '〜を見る'
PDF内の文字列を pdf-reader で抽出し、「〜を見る」という文字列が含まれているかどうかをテストしています。
ローカルでは失敗するのですが、なぜかCI環境では問題なく通ります。
原因を調べる
まず、PDFに文字列が出力されていないのでは?と考え、生成されたPDFをプレビューツールで開いてみたのですが、ちゃんと「見」の文字が確認できました。
次に、pdf-readerでうまく文字列を抽出できてない可能性を疑い、runs.map(&:text) で抽出した文字列を VSCodeにコピペしてみたのですが、やはり、「見」の文字はちゃんと含まれていました。
しかし、Ctrl+Fで「見」を検索してみたところ、なぜかヒットしません。
そこで「見」らしき文字を以下のように文字コードに変換してみたところ、康熙部首であることがわかりました。

康熙部首(こうきぶしゅ)とは
康熙部首とはUnicodeの U+2F00 〜 U+2FDF に割り当てられていて、部首を表すために使用される文字です。(漢字ではない)
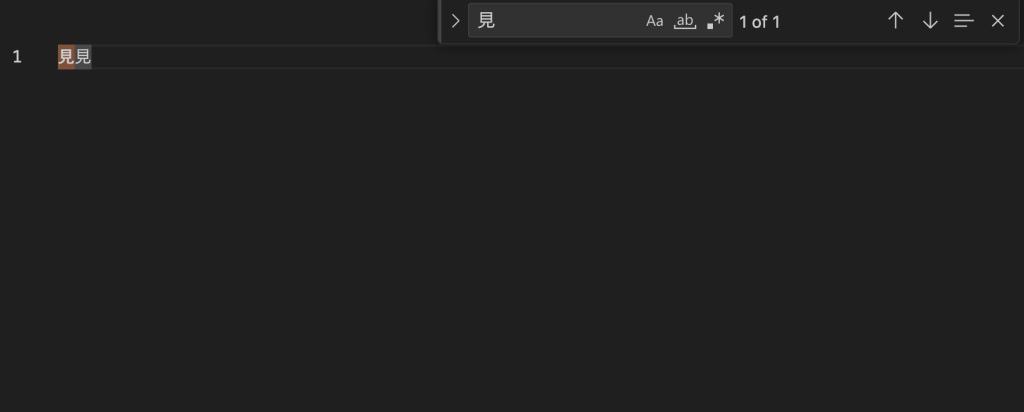
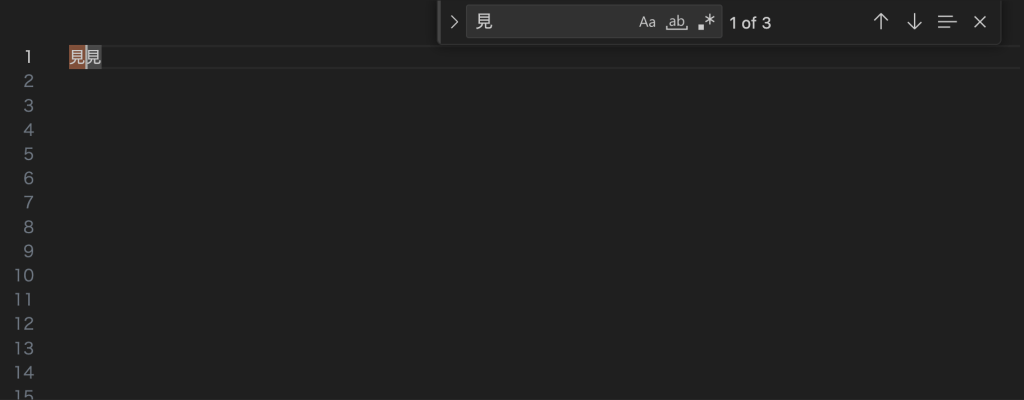
2つの文字を横に並べて比較してみると、VSCodeのフォント設定によって見た目が微妙に違ったり、全く見分けがつかなかったりします。(左が漢字で、右が康熙部首)
Macでデフォルトのmonospaceを指定している場合:
Hiragino Kaku Gothic ProNの場合:
康熙部首に化けてしまう原因
原因をネットで調べてみたところ、詳しく解説されているスライドが見つかりました。
参考: PDFのコピペが文字化けするのはなぜか?~CID/GIDと原ノ味フォント~ | PPT
用語:
- GID/CID
- フォント内の一つ一つの文字に振られたID。通常、PDF に文字を埋め込む際は、文字コードを CID/GID へ変換したものをPDF内に記述するようになっている。
- CMap
- 文字コードをGID/CIDに変換するためのテーブル。フォントによっては文字コードとCID/GIDの関係がn:1になっていることがある。
- ToUnicode CMap
- GID/CIDをUnicodeに変換するためのテーブル。CMapを逆変換して作られる。PDFビュアー上で文字列を検索したり、クリップボードにコピーしたりする際に必要。PDF作成時にPDF内部に埋め込まれる。
このスライドによるとどうやら、ToUnicode CMapを作る際、 n:1 の関係になっている文字については、最初に見つかった若い文字コード( 0x2F92 < 0x898B )を採用するため、康熙部首に化けてしてしまうということのようです。
テストがローカルでのみ失敗していた原因
CI環境ではテストが通るのにローカルでは失敗していた原因としては、帳票のフォントに指定されている IPA P ゴシックのフォントをローカル環境にインストールし忘れていて、別のフォントが使われていたからでした。(IPA P ゴシックは康熙部首に化けないフォント)
以上、PDF周りのテストで文字列の比較がうまくいかない場合は康熙部首を疑ってみた方がいいかもしれないという話でした。
