注意このコードは実験的機能を使用しており、一部ブラウザ(Firefox、Safari)では動作しません。
🔗目次
- まえがき
- 解決したい問題
- 完成品
- 環境紹介
- VB-Audio Virtual Cableって?
- VOICEVOX-COREって?
- Colab内で環境構築
- まずはバックエンドから書いてみよう
- フロントエンドを書こう
- 参考記事
- クレジット
🔗まえがき
皆様こんにちは、BPSの協力会社として横浜を拠点に活動しております、株式会社ECNのFuseです。
突然ですが、みなさんは通話、してますか?夏休みも本番になり、遠方の友達とDiscordなどのオンライン通話で会話する機会も多いと思います。
ですが…
↑目次に戻る
解決したい問題
私は私の声が嫌いです。
自分で聞いてても嫌になってしまうほどのローテンションボイスです。
今回はこれをしゃべった声を音声合成ソフトに代弁させる形で何とかしたいと思います。
ですが私のロースペPCでは大きな遅延が発生してしまいます。
なので今回音声合成部分はデータサイエンスや機械学習に使われる
- 環境構築が不要
- GPU に料金なしでアクセス
- 簡単に共有
の3点が特徴の"Google Colaboratory"の上で動かしていこうと思います。
参考: Colaboratory へようこそ - Colaboratory
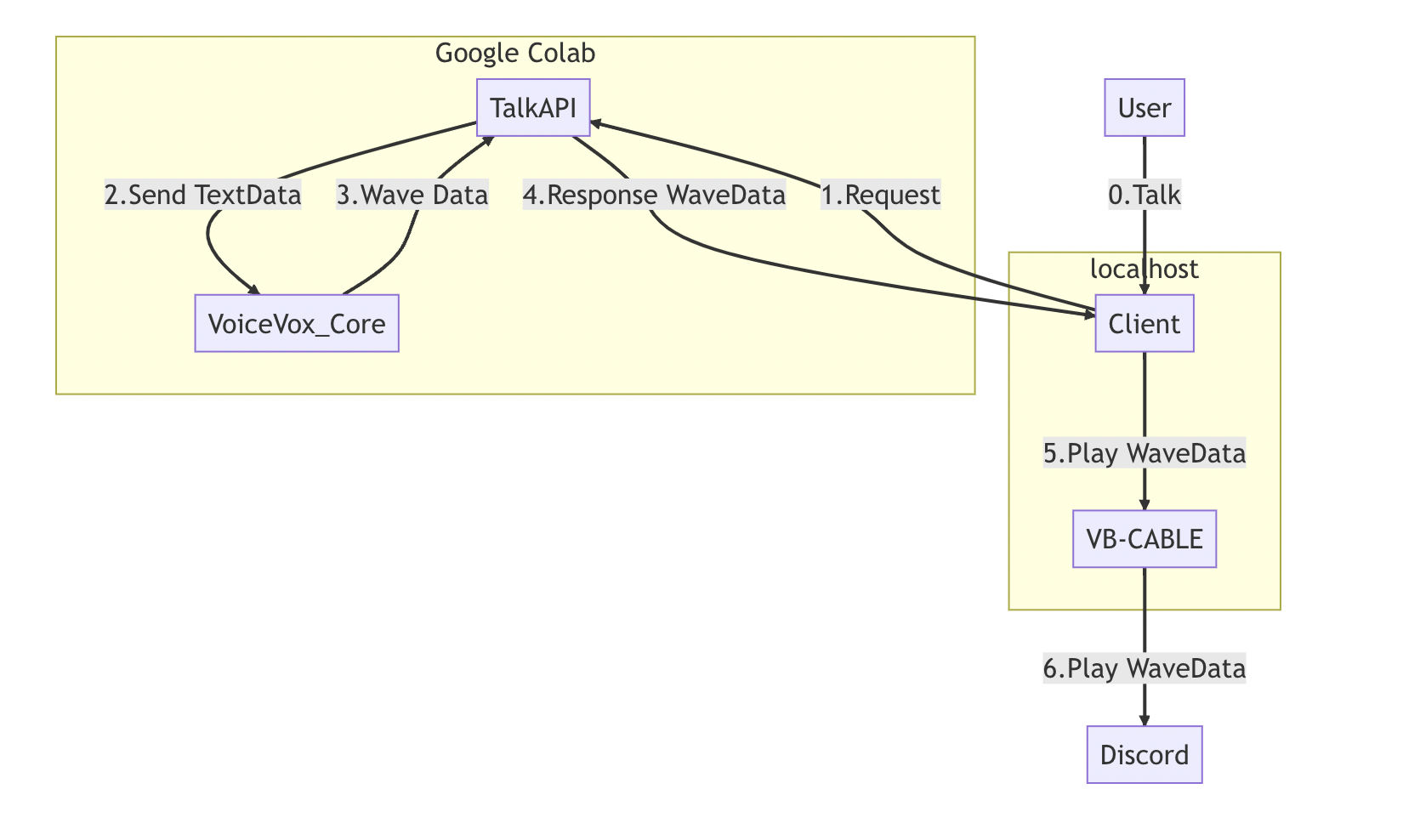
🔗完成品
イメージ図
動作動画
↑目次に戻る
🔗環境紹介
| フロントエンド | バージョン |
|---|---|
| Node.js | v16.18.0 |
| TypeScript | 4.9.5 |
| npm | 8.19.2 |
| yarn | 1.22.19 |
| react | 18.2.0 |
| バックエンド | バージョン |
|---|---|
| go | 1.20 |
| github.com/sh1ma/voicevoxcore.go | v0.0.5 |
| voicevox-core | 0.14.4 |
| その他ソフトウェア | バージョン |
|---|---|
| VB-Audio Virtual Cable | 1.0.3.5 |
🔗VB-Audio Virtual Cableって?
今回は私の声を流すことなく合成音声だけがDiscordに流れる必要があります。ですがデフォルトのマイクとスピーカーでは私の声だけが流れてしまいます。
これではいけないということで専用の仮想デバイスが必要です。
VB-CABLE Virtual Audio Deviceはそんな悩みを解決してくれるソフトウェアで、出力デバイス「Cable Input」に流した音声をそのまま入力デバイス「Cable OutPut」に流してくれます。
これを使えば、合成した音声だけをDiscordに流せますね。
🔗VOICEVOX-COREって?


VOICEVOX-COREは文字通りVOICEVOXという音声合成ソフトのコア部分。通常のVOICEVOXより軽量なだけでなくサービスやソフトウェアにも組み超える優れもの。といってもやっぱりキャラクターごとに利用規約が違うので、規約をよく読んだうえで使っていきましょう。
↑目次に戻る
🔗Colab内で行う環境構築
必要なあれこれを理解したら、Colab上で音声合成APIサーバを立てるために必要な準備を整えていきます。
Golangを使うために必要な準備
Go言語のコードをビルドするためには、Go言語のバイナリが必要です。以下のコードをコードセルに貼り付け動かしましょう。
# 最新バージョンのgolangを入手して解凍する
!wget https://go.dev/dl/go1.20.5.linux-amd64.tar.gz #シェルコマンドを使うときは先頭に"!"
!sudo tar -C /usr/local -xzf go1.20.5.linux-amd64.tar.gz
!rm -rf go1.20.5.linux-amd64.tar.gz
# パスを通す
import os
%env PATH=/usr/local/go/bin:{os.environ['PATH']}
# 念のためバージョンを確認
!go version
また、%envでPATHを触るときは慎重に行いましょう。go以外のコマンドがすべて使えなくなったりします。(1敗)
VOICEVOX-COREを使うために必要な準備
Goの導入が終わったら次はVOICEVOX-COREを導入します。こちらのコードをコードセルに張り付け実行します。
!sudo apt update
# ダウンローダを入手
!curl -sSfL https://github.com/VOICEVOX/voicevox_core/releases/latest/download/download-linux-x64 -o download
!chmod +x download
# 忘れずにGPU版に
!sudo ./download --device=cuda
import os
# ライブラリのパスを通しておく
%env LD_LIBRARY_PATH=/content/voicevox_core:{os.environ['LD_LIBRARY_PATH']}
その後、バイナリをビルドするときのために以下のコードでシンボリックリンクを作成しましょう。
!ln -s /content/voicevox_core/libvoicevox_core.so /usr/local/lib
!ln -s /content/voicevox_core/libonnxruntime.so.1.13.1 /usr/local/lib
!ln -s /content/voicevox_core/voicevox_core.h /usr/local/include
Goのプロジェクトを作成しよう
後はいつものようにgo.modを初期化し必要なパッケージをインポートすれば準備完了です。お疲れ様でした!
!go mod init talkapi
!go get github.com/sh1ma/voicevoxcore.go
🔗まずはバックエンドから書いてみよう
サーバを作ろう
今回は標準パッケージ"net/http"をメインに使った簡易的なものを書いていきます。
以下のコードをコードセルに書き込み、main.goを生成します。
//main.go
%%file main.go
package main
import (
"encoding/json"
"fmt"
"github.com/sh1ma/voicevoxcore.go"
"net/http"
)
type ReqBody struct { //リクエスト用構造体
Text string
}
func Initialize() (c *voicevoxcorego.VoicevoxCore) { //コアの生成と初期化を行う関数
core := voicevoxcorego.New()
initializeOptions := voicevoxcorego.NewVoicevoxInitializeOptions(0, 0, false, "/content/voicevox_core/open_jtalk_dic_utf_8-1.11")
core.Initialize(initializeOptions)
core.LoadModel(8) //8番は春日部つむぎのモデル
return core //初期化したコアを返す
}
func main() {
core := Initialize()
ttsOptions := voicevoxcorego.NewVoicevoxTtsOptions(false, true)
Synth := func(w http.ResponseWriter, req *http.Request) { //音声を返すための関数
w.Header().Add("Access-Control-Allow-Headers", "*")
w.Header().Add("Access-Control-Allow-Origin", "*")
w.Header().Add("Access-Control-Allow-Methods", "POST,OPTIONS")
if req.Method == "OPTIONS" {
w.WriteHeader(http.StatusOK)
return
}
len := req.ContentLength
body := make([]byte, len) // Content-Length と同じサイズの byte 配列を用意
req.Body.Read(body)
var param ReqBody
err := json.Unmarshal(body, ¶m) //Jsonを構造体に
if err != nil { //パースに失敗したら
fmt.Printf("Error:%s\n", err.Error())
w.WriteHeader(http.StatusInternalServerError) //500番エラー
fmt.Fprint(w, "Data Invalid.\n")
return
}
fmt.Printf("%+v\n", param)
fmt.Printf("Target Text=>:%s\n", param.Text)
wav, err := core.Tts(param.Text, 8, ttsOptions)
if err != nil {
fmt.Printf("Error:%s\n", err.Error())
w.WriteHeader(http.StatusInternalServerError)
fmt.Fprint(w, "Server Error.\n") //500番エラー
return
}
w.WriteHeader(http.StatusOK) //200番
w.Write(wav)
}
CORS := func(w http.ResponseWriter, req *http.Request) {
w.Header().Add("Access-Control-Allow-Headers", "*")
w.Header().Add("Access-Control-Allow-Origin", "*")
w.Header().Add("Access-Control-Allow-Methods", "POST,OPTIONS")
if req.Method == "OPTIONS" {
w.WriteHeader(http.StatusOK)
return
}
}
http.HandleFunc("/synthaudio", Synth)
http.HandleFunc("/", CORS)
if err := http.ListenAndServe(":1114", nil); err != nil {
fmt.Printf(("Error:%e"), err)
}
}
一つ注意点として、8080番はColab側で既に使用されており、ポートを開けようとするとエラーになります。
その後、コードをビルドし、
!go build
実行すれば、サーバ側のコードは完成です!
!nohup ./talkapi > server.log 2>&1 &
試しに音声を取得してみましょう。
!curl -X POST -H "Content-Type: application/json" -d '{"text":"これはテスト音声です"}' "localhost:1114/synthaudio">result.wav
見事音声の合成に成功しました!
サービスを外部に公開しよう
…ですが今の状態では内部からの音声合成はできても肝心の外部からの音声合成ができません。
なので今回はngrokなる代物を使い、URLを発行します。
参考: ngrok
参考: pyngrok · PyPI
まずはngrokとそのラッパーライブラリであるpyngrokをインストール。
!pip install pyngrok
そしたらサーバを起動するコードセルを次のように書き換えます。
#二重起動を防ぐ
!pkill talkapi
!pkill ngrok
# トンネル開通
from pyngrok import ngrok
public_url = ngrok.connect(1114)
# URL出力
print(public_url)
# サーバ起動
!nohup ./talkapi > server.log 2>&1 &
するとhttps://****-**-***-***-**.ngrok.ioみたいなURLが発行されるので、さっきと同じようにそのURLにcurlすれば音声が生成されるはずです!
↑目次に戻る
🔗フロントエンドを書こう
次にフロントエンド部分を書いていきます。使用する技術には最近使用する機会の多いReactを選択しました。
参考: React
🔗 AudioContextをケーブルにつなごう
まずはAudioContextを生成し録音を完成するボタンを作るのですが、デフォルトではAudioContextの出力先はデフォルトのスピーカー。これをどうにかしてCABLE-INPUTに繋ぎ変えてやらねばなりません。今回は実験的な機能であるAudioContext.setSinkId()を使っていきます。
// tsx:RecButton.tsx
import { useState } from "react";
interface ExAudioContext extends AudioContext {
setSinkId(id: string):Promise<undefined>;//型情報に関数がないので拡張する
}
interface Props{
setResult:(arg0:string)=>void//文字起こし結果をセットする関数
}
export default function RecButton(prop:Props) {
// eslint-disable-next-line @typescript-eslint/ban-ts-comment
// @ts-ignore
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
const [recording,setRecording]=useState<boolean>(false);//現在録音中か
const =useState<ExAudioContext|null>(null)//AudioContext
const [recog,setRecog]=useState<SpeechRecognition|null>(null)//SpeechRecognition
const setDevice=async ()=>{
const devices = await navigator.mediaDevices.enumerateDevices();//デバイス一覧を取得
const ads = devices.filter(device => device.kind === 'audiooutput'&&device.label.includes("CABLE"));//音声出力かつ名前にCABLEと入っているものだけ
const ac=new AudioContext() as ExAudioContext;//ExAudioContextとして生成
ac.setSinkId(ads[0].deviceId)//出力先セット
setAudio(ac)
return ac;
}
// TODO:SpeechRecognitionの生成と初期化を行う関数
const recStart=async ()=>{
setRecording(true)
if(!audio){
await setDevice()
}
recog?.start();
console.log("Start")
}
const recEnd=()=>{
setRecording(false)
recog?.abort()
}
return <div className="RecButton"style={{background:recording?"#f00":"#444",color:recording?"fff":"f00"}} onClick={recording?recEnd:recStart}>●</div>
}
AudioContext.setSinkId()は存在こそしているものの、実験的な関数ゆえかなぜか型情報に存在しません。なのでAudioContextを継承した新しい型を作ってそっちで定義します。
//App.css(一部抜粋)
.RecButton{
width:10vw;
height:10vw;
line-Height:10vw;
border-Radius:2.5vw;
margin-left:auto;
margin-right:auto;
margin-top: 32px;
}
スタイルシート側はこんな感じになっています。margin-leftとmargin-rightを共にautoにし、要素を中央に寄せています。
🔗 音声を文字起こししよう
いったん後回しにしていた文字起こし部分を満を持して完成させます。以下のようにRecButton.texを完成させていきましょう。
// tsx:RecButton.tsx(完成)
import { useState } from "react";
interface ExAudioContext extends AudioContext {
setSinkId(id: string):Promise<undefined>; //型情報に関数がないので拡張する
}
interface Props{
setResult:(arg0:string)=>void //文字起こし結果をセットする関数
}
export default function RecButton(prop:Props) {
// eslint-disable-next-line @typescript-eslint/ban-ts-comment
// @ts-ignore
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
const [recording,setRecording]=useState<boolean>(false); //現在録音中か
const =useState<ExAudioContext|null>(null)//AudioContext
const [recog,setRecog]=useState<SpeechRecognition|null>(null)//SpeechRecognition
const setDevice=async ()=>{
const devices = await navigator.mediaDevices.enumerateDevices(); //デバイス一覧を取得
const ads = devices.filter(device => device.kind === 'audiooutput'&&device.label.includes("CABLE")); //音声出力かつ名前にCABLEと入っているものだけ
const ac=new AudioContext() as ExAudioContext; //ExAudioContextとして生成
ac.setSinkId(ads[0].deviceId)//出力先セット
setAudio(ac)
return ac;
}
const initRecog=(ac:ExAudioContext)=>{
const nrecog=new SpeechRecognition() //生成
nrecog.lang = 'ja'; //日本語
nrecog.continuous = true;
nrecog.onresult = async (event: SpeechRecognitionEvent) => { //結果が出たら
const current = event.resultIndex;
const transcript = event.results[current][0].transcript;
if (transcript.length > 1&&ac!=null) { //空白でないかつAudioContextが存在
prop.setResult(transcript) //結果をセット
const url_synth = "https://****-**-***-***-**.ngrok.io/synthaudio"; //さっきngrokからもらったURL
fetch(url_synth, {method: 'post', headers: {"accept": "audio/wav"},body:'{"text":"'+transcript+'"}'})
.then((synth_resp)=>synth_resp.arrayBuffer()) //バイナリ取り出し
.then((ab)=>ac.decodeAudioData(ab)) //デコード
.then((buffer)=>{
const source=ac.createBufferSource()
source.connect(ac.destination)
source.buffer=buffer
source.start() //再生
})
}
}
nrecog.onerror = (e:SpeechRecognitionErrorEvent) => { //エラーが起きたら
if (e.error === 'no-speech') { //タイムアウトなら
nrecog.start(); //もう一回
}
};
nrecog.onend = () => { //終わったら
if(recording)nrecog.start(); //録音中ならもう一回
}
nrecog.start() //開始
setRecog(nrecog) //セット
}
const recStart=async ()=>{
setRecording(true)
if(!audio){
await setDevice()
.then(audio=>initRecog(audio)) //作った関数を追加
}
recog?.start();
console.log("Start")
}
const recEnd=()=>{
setRecording(false)
recog?.abort()
}
return <div className="RecButton"style={{background:recording?"#f00":"#444",color:recording?"fff":"f00"}} onClick={recording?recEnd:recStart}>●</div>
}
これで録音ボタンは完成です。
また、HeaderにContent-Typeとか余計なものは追加しないようにしましょう。
私はCORSに引っ掛かり8時間ぐらいはまりました。
🔗 文字起こしした結果を表示する枠を作ろう
次に自分の声がどう認識されたかを確認できる表示枠を作っていきましょう。
// RecogResult.tsx
import {useEffect} from 'react'
interface Props{
result:string //文字起こしの結果
}
export default function RecogResult(props:Props) {
useEffect(()=>{
console.log("Result=>"+props.result)
},[props.result])
return(
<div className="RecogResult" style={{fontSize:"calc(50vw/"+props.result.length+")"}}>
{props.result}
</div>
)
}
特に変わったところはありませんが、強いて挙げるならばfontSizeをCalcを使って動的に変動させ、文字が必ず1行に収まるように作りました。
// App.css(一部抜粋)
.RecogResult{
background-color: #fff;
border: solid 3px #000;
width:60%;
border-radius: 32px;
height: 50vh;
line-height: 45vh;
margin-left:auto;
margin-right:auto;
margin-top: 32px;
}
スタイルシート側はこんな感じ、line-heightとheightを調節する事で、文字を上下中央に持ってきています。
🔗 組み立てよう
あとは組み立てて、ステートとそれをセットするための関数をそれぞれに渡してあげればきれいに動作するはずです!
//App.tsx
import './App.css'
import {useState} from 'react'
import RecButton from './Components/RecButton'
import RecogResult from './Components/RecogResult'
function App() {
const [resultstr,setResult]=useState<string>("下のボタンで録画を開始します") //文字起こし結果を管理するステート
return (
<>
<div style={{width:"100vw",height:"100vh",border:"solid 2px #000",padding:"0",margin:"0"}}>{/*なんとなく枠をつけてみる*/}
<h1>VOICEVOX VoiceChanger</h1>
<RecogResult result={resultstr}/>{/*ステートを渡す*/}
<RecButton setResult={setResult}></RecButton>{/*セット用の関数を渡す*/}
</div>
</>
)
}
export default App
背景もおしゃれなアクアマリン色(?)にしてみました。
//App.css(一部抜粋)
body {
margin: 0 auto;
padding: 0;
text-align: center;
background-color: aquamarine;
color:#000000;
}
VOICEVOX式簡易ボイスチェンジャー、これにて完成です!
🔗参考記事
🔗クレジット
利用音声
![]()
株式会社ECNはPHP、JavaScriptを中心にお客様のご要望に合わせたwebサービス、システム開発を承っております。
ビジネスの最初から最後までをサポートを行い
お客様のイメージに合わせたWebサービス、システム開発、デザインを行います。
注釈
