morimorihoge です。最近Claude Code MAX 20xに秘書をさせてみたらかなり良くて、業務の進め方が大幅に変わりました(この辺の詳細もまたそのうち書こうと思います)。
Claude Codeなり他のMCPプロトコルに対応したAIエージェントを使っている人は皆さんご存じの playwright-mcp 、雑な自然言語で指示を出したら良い感じにAIエージェントがブラウザを操作して色々やってくれる、便利な世界がやってきたと話題です。
Playwrightとは何なのか、MCPサーバーとは何なのかという話については以下のサイトや他にも無限に解説しているサイトがあるのでそちらを参照して下さい。
結論だけ見たい人向け
MS公式のplaywright-mcpをforkして、 browser_get_request_info APIを追加しました。
このAPIを使うことで「playwrightが今開いているWebページを表示するのに使ったHTTPリクエストと同じリクエストを実行するのに必要なcurlコマンド」を取得することができます。
取得したcurlコマンドをAIエージェント側で実行させて一時ファイルに保存させて別途解析することで、MCPサーバーのリクエスト・レスポンスサイズを抑えて大きなWebページの内容を解析させることができるようになります。
ソースコードは morimorihoge/playwright-mcp にありますので、自己責任で使ってみたい人はどうぞ。
※簡単インストール方法などはあえて書きません。それくらいは分かる人向けということで(レビューも全部AIにやらせたコードなので僕も責任持てません)

Playwright MCP最大の弱点:大きなページを開けない問題
というわけで、本題に入っていきます。
夢のMCPサーバーか?と思わせるPlaywright MCPですが、実際に使ってみると実用上大きな問題が立ちはだかります。
それが 大きなページを処理できない ことです。
具体的な例を出します。 claude mcp add playwright -s user -- npx @playwright/mcp@latest でClaude Codeに登録させたMCPサーバーを使って弊社の日報システムのプロジェクト一覧を解析させようとすると、
● playwright:browser_navigate (MCP)(url: "https://nippou.bpsinc.jp/bps/projects")
⎿ Error: MCP tool "browser_navigate" response (111969 tokens) exceeds maximum allowed tokens (25000). Please use pagination, filtering, or limit parameters to reduce the response size.
というエラーを吐いてしまいます。ちなみに、2025/06/27時点では、今あなたの見ているこのTechRacho記事ページくらいのサイズでも超えてしまいます(Claude MAX 20xプラン利用)。厳しい。
これは、当該ページが沢山のデータを一覧表示するページでレスポンスHTMLが大きすぎることで、MCPサーバーからのレスポンスがClaude Codeの扱えるtoken数を超えてしまったことから起きているエラーです。
当該ページが表示件数制限・ページング機能などを実装していて充分に少ない件数おきに取得できたりするのであれば、エージェント側が少ない表示件数でページめくりしていくなどもしてくれますが、
- 開いた最初の一覧ページ自体が制限によりエラーになり、AIエージェントがページングや件数制限の取っかかりを見つけられない(表示件数制限・ページング機能があっても失敗する)
- そもそもページング機能が実装されていない
- とてもコンテンツリッチなサイトで、件数を少なくしてもコンテンツ部分以外のデータが多くて表示件数を少なくしてもtoken limitを超えてしまう
といった場合にはAIエージェントがいくらかがんばった後に諦めてしまいます。
なお、ログイン不要な公開サイトであれば、それでもcurlコマンドなどにfallbackして取得を試みたりしてくれますが、ログイン必要なサイトの画面では難しいです。
一応やろうと思えばAIエージェントにサイトをログインから実行させるクローラーのコードを書かせることで処理させることはできなくもないですが、割と細かく指示を出さないと思ったように出来上がらなかったり、ちょっと違うことをさせようとするとまたいちいち指示出しが必要になったりして辛いです。AIに働かされてる気持ちになる。
解法1: 大きなページを一括取得できないなら分割取得すればいいじゃない案
※結論を先に言うとこれはうまくいきませんでした
まず考えたのは「ページのHTMLをまるごと取得するのではなく、分割取得したり圧縮して取得すればうまくいくのでは?」という案です。
試しに browser_get_html_source というAPIをClaude Codeで作らせてみました。
このAPIは
- 今現在ブラウザが開いているページのHTMLを取得する
maxLength/offsetを指定することで部分取得が可能compressオプションで不要な空白を削除させたり、selectorオプションで特定部分だけを取ったりもできる
というものです。
これであれば、大きなページもtoken limitの範囲内で取得することができるのではないかなと思いました。この方法だと ブラウザが今レンダリングしているHTMLを取得するので、SPAで構成されているような動的サイトでも取得できる というメリットもあります。
ただ、この解法1はうまくいきませんでした。そもそもサイズの大きいページは分割取得しようがサイズが大きいことには変わりなく、取得させてみても激重でちょっと使い物にはなりませんでした。残念。
解法2: MCPサーバーが直接HTMLを返さず、エージェントがHTMLを別途取得すればいいじゃない案
次に考えたのは「結局欲しいのは当該ページのHTMLなんだから、欲しいページを取得するのと同じHTTPリクエストをエージェント側で実行すればいいんじゃね?」という案です。
こちらは browser_get_request_info APIとして実装させてみました。
このAPIはPlaywright MCPが今ブラウザで開いているページについて、以下のようなレスポンスを返却します。
{
"url": "https://example.com/page",
"method": "GET",
"headers": {
"User-Agent": "Mozilla/5.0...",
"Referer": "https://example.com/"
},
"cookies": [
{
"name": "session_id",
"value": "abc123",
"domain": ".example.com",
"path": "/",
"httpOnly": true,
"secure": true
}
],
"postData": {
"contentType": "application/x-www-form-urlencoded",
"params": [
{"name": "username", "value": "john"},
{"name": "email", "value": "john@example.com"}
]
},
"timestamp": "2024-01-26T12:34:56Z",
"curlCommand": "curl -X POST 'https://example.com/submit' -H 'Cookie: session_id=abc123' -d 'username=john&email=john%40example.com'"
}
要は「今開いているWebページを取得するのに使ったHTTPリクエストの情報」を返します。ついでに curlCommand にはcurlオプションまでありますね。
これにより、
- Playwright MCPでブラウザを操作し、MCPサーバー側で開きたいページを開く
- 欲しいページに到達したら
browser_get_request_infoを実行し、AIエージェントがHTTPリクエストの情報を取得(HTTPリクエストはtoken limitを超えるようなサイズには通常ならない) - AIエージェント側で同じHTTPリクエストをcurlで実行し、HTMLを取得する
- 取得したHTMLのサイズが大きかったとしても、一時ファイルに保存させるなどすれば、保存したHTMLを後からAIエージェントに解析させることができる
ということができるようになります。
このアプローチはうまくいきました。
実際に動かしてみた結果
CLAUDE.mdには一応こういう指示を入れておきます。この手のMCPサーバーの使い方的なものを書いておくと、非効率な使い方を避けられるのでオススメです。
# Playwright MCP 使用時のルール
## ページサイズが大きい場合の対処法
playwright-mcpを使用してページ内容を取得する際、ページが大きくて内容が取得できない場合は以下の手順で対処する:
1. **browser_snapshot**等で内容取得に失敗または不完全な場合を検知
2. **browser_get_request_info APIを使用**してリクエスト情報を取得
3. **生成されたcurlコマンドを使用**してHTMLを直接ダウンロード
4. **ダウンロードしたHTMLファイルを解析**して必要な情報を抽出
### 実装例
bash
# 1. browser_get_request_infoでリクエスト情報取得
# 2. curlコマンドを実行してHTMLを保存
curl '[取得したURL]' -H 'Cookie: [取得したCookie]' -o ./tmp/page_content.html
# 3. HTMLを解析(Ruby/Python等で処理)
この方法により、MCPの制限を回避して大きなページの完全な内容を取得できる。
実際に動かしてみたところ、確かに playwright:browser_navigate で失敗した後 playwright:browser_get_request_info を実行しなおし、HTMLを無事取得できています。
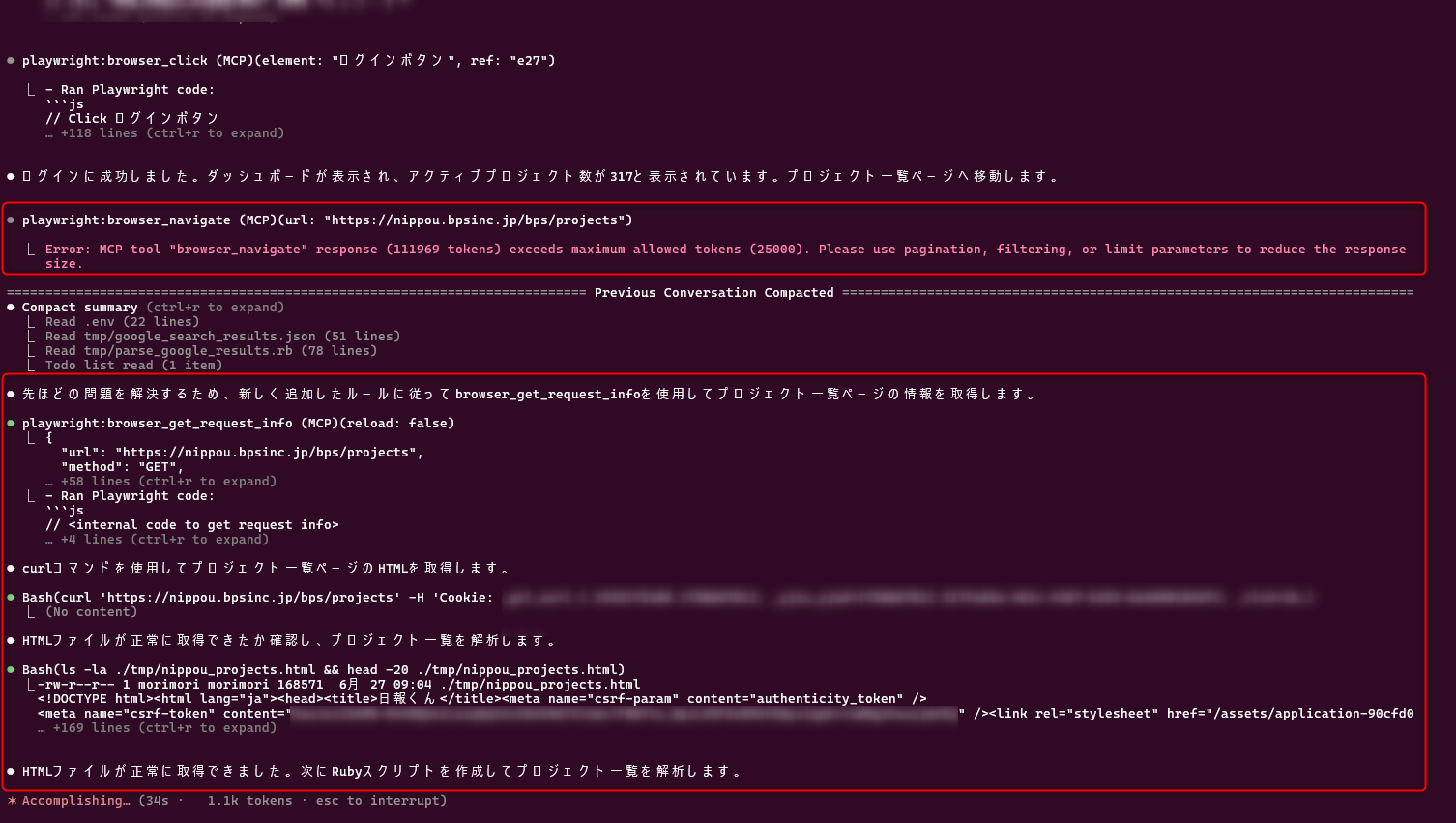
Promptは以下です。ログインページのURLだけは渡していますが、特にリンク方法の詳細などは一切渡していません。AIエージェントが良い感じに予想しつつやってくれています。
日報くんにログインしてactiveなプロジェクト一覧を整理してmarkdownにまとめてください。
ログイン情報などは.envにNIPPOU_BPS*の名前で記録してあります
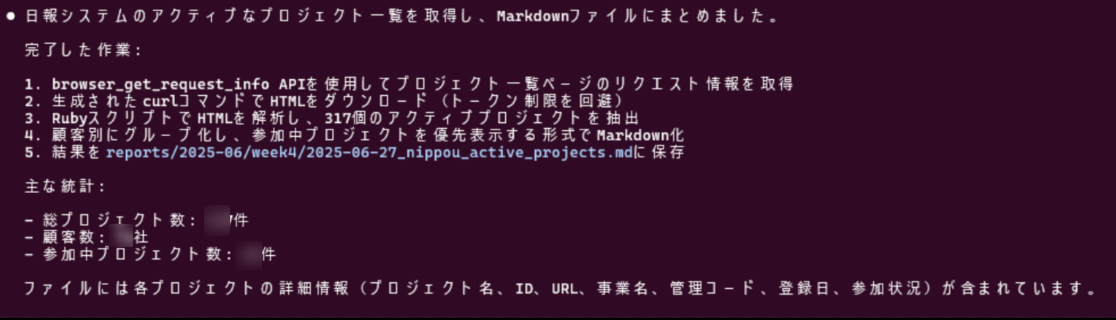
中略しつつ、最終的にはこんな感じになりました。サマリしてもらったMarkdownの方も見ましたが、ちゃんと全件解析できています。賢い。
機能上の制限と免責
browser_get_request_info APIはその仕様上、以下の様な構造のWebページには対応できません。
- SPAで構成されているモダンなWebサイトや、JavaScriptで非同期にコンテンツを取得するWebサイト
- curlでHTML取得する関係上、JavaScriptを動作させないとコンテンツが取れないサイトは対象外です
- ファイルアップロードのPOSTをした結果レスポンスで表示されるWebページ
- MCPサーバーのレスポンスが大きくなってしまうなどの都合があり、対応させていません
- 再読み込み禁止などのHTTPリクエストの再利用を許していないWebサイト
- 今でもごく稀にある不自由なWebサイトですが、これもダメです
- CSRFトークンが毎回変更されるWebサイトの場合、POSTリクエストは失敗する
- 検索機能などがPOSTで実装されていることがありますが、その場合にCSRFトークンが再利用できない仕様だと失敗します
- その他、WAFなどのセキュリティ仕様により同じようなリクエストを不正と扱われるケース
- MCPサーバーとAIエージェントが異なるホストだと、IP違いで同じログインセッションのリクエストが飛ぶことになるので、遮断されたりするかもしれません
とにかく諸々制限はありますし、AIエージェントの振る舞いによっては一見攻撃やイタズラのように見えるリクエストを発行する可能性もゼロではありませんので、このあたり充分に理解の上ご利用ください。
本APIの利用により発生した一切の損害は補償できません(いちおう)。
まとめ
今回のAPIですが、通常業務の合間に裏でClaude Codeに設計情報を与えて実装させて、GitHub Copilotにレビュー -> Claude Codeにフィードバックさせる、を繰り返して実装しました。各APIごとに実際に要した時間は2時間未満くらいです。
AIエージェント+MCPサーバーの強いところはこういう風に「自分の欲しい機能が無ければ仕様設計してMCPサーバーをAIに実装させる」というのが出来てしまうところにあるな、と強く感じました。仕様設計の解像度が高ければ、仮説 -> 検証のサイクルが超速で回せるというのは新鮮です。
AI驚き屋みたいなのはイマイチ好きではないのですが、流石にこのレベルになってくると実用の閾値を充分に超えてきたように感じます。ではでは