概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: The Limits of Copy-on-write: How Ruby Allocates Memory
- 公開日: 2017/08/28
- 著者: Brandur
- サイト: https://brandur.org/
Rubyのメモリ割り当て方法とcopy-on-writeの限界(翻訳)
Unicorn(またはPumaやEinhorn)を実行していると、誰しもある奇妙な現象に気がつくでしょう。マスタからforkした(複数の)ワーカープロセスのメモリ使用量は開始当初は低いにもかかわらず、しばらくすると親と同じぐらいにまでメモリ量が増加します。大規模な本番インストールだと各ワーカーのサイズが100MB以上まで増加することもあり、やがてメモリはサーバーでもっとも制約の厳しいリソースになってしまい、しかもCPUはアイドル状態のままです。
現代的なOSの仮想メモリ管理システムは、まさにこの状況を防止するために設計されたcopy-on-write機能を提供します。プロセスの仮想メモリは4kページごとにセグメント化されます。プロセスがforkした当初の子プロセスは、すべてのページを親プロセスと共有します。子プロセスがページの変更を開始した場合にのみ、カーネルはその呼び出しをインターセプトし、ページをコピーして新しいプロセスに再度割り当てます。
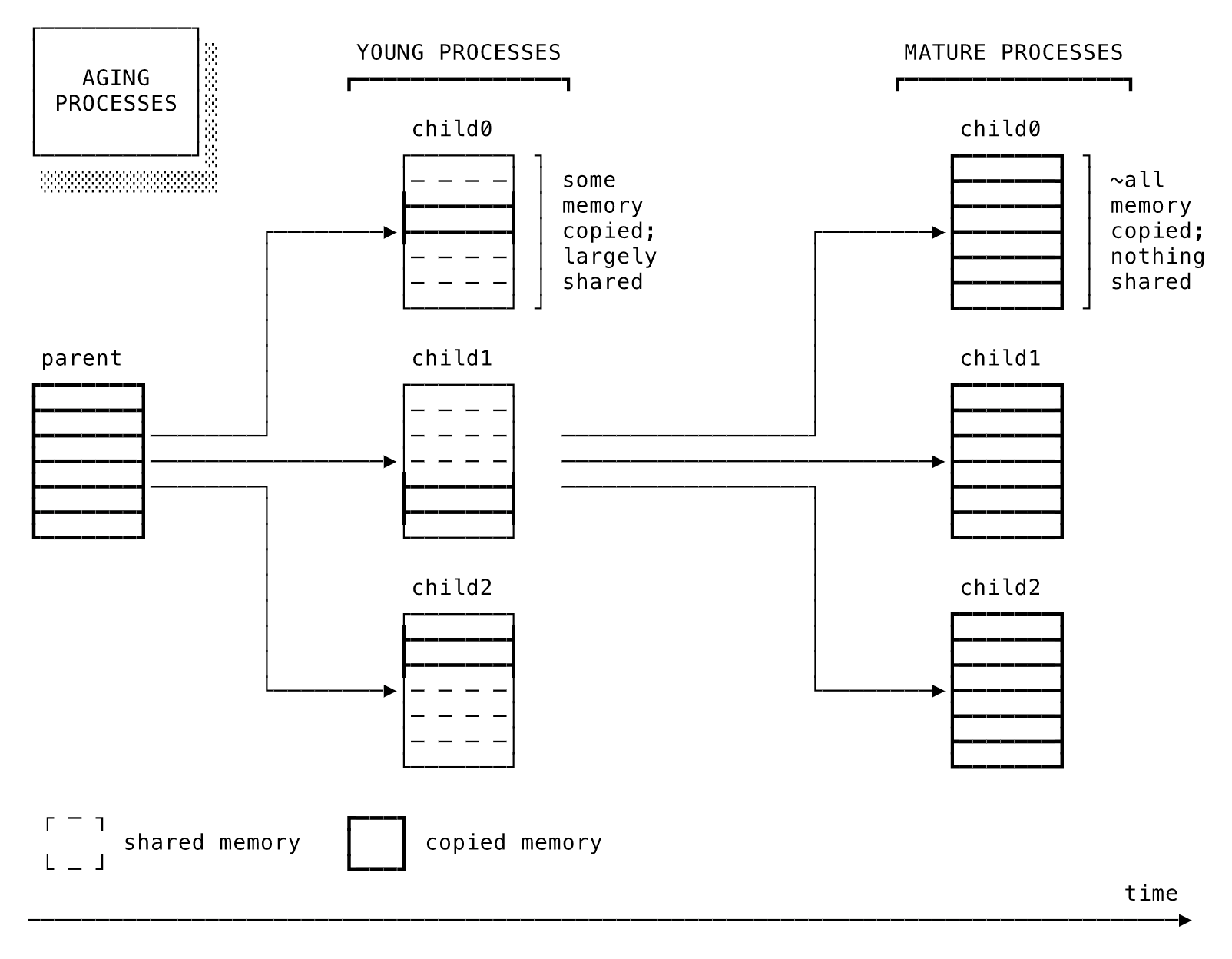
子プロセスが時間とともに共有メモリ中心からコピー中心に移行する様子
だとすると、なぜUnicornのワーカーはもっと多くのメモリを共有しないのでしょうか。多くのソフトウェアが持つ(サイズを増減可能な)静的オブジェクトのコレクションは、一度だけ初期化された後、プログラムのライフタイム終了までメモリ上で変更されないままワーカー全体で共有され続ける筆頭候補になりえます。形式的にはそのとおりなのですが、実際には何も再利用されません。その理由を理解するには、Rubyのメモリ割り当て動作を詳しく調べる必要があります。
スラブとスロット
まずはオブジェクト割り当ての概要をざっと押さえておきましょう。RubyがOSにリクエストするメモリはチャンクに分かれており、内部ではヒープページと呼ばれます。(Rubyの)ヒープページは、OSから渡される4kページ(以後「OSページ」と呼ぶことにします)とは同じではないため、ヒープページという名前は少々不運かもしれませんが、1つのヒープページは仮想メモリ上で多数のOSページにマッピングされます。Rubyは、(OSページが複数の場合も含め)OSページを専有することで、OSページを最大限利用できるようにヒープページのサイズを増減します(通常、4kのOSページ4つが16kのヒープページ1つに等しくなります)。
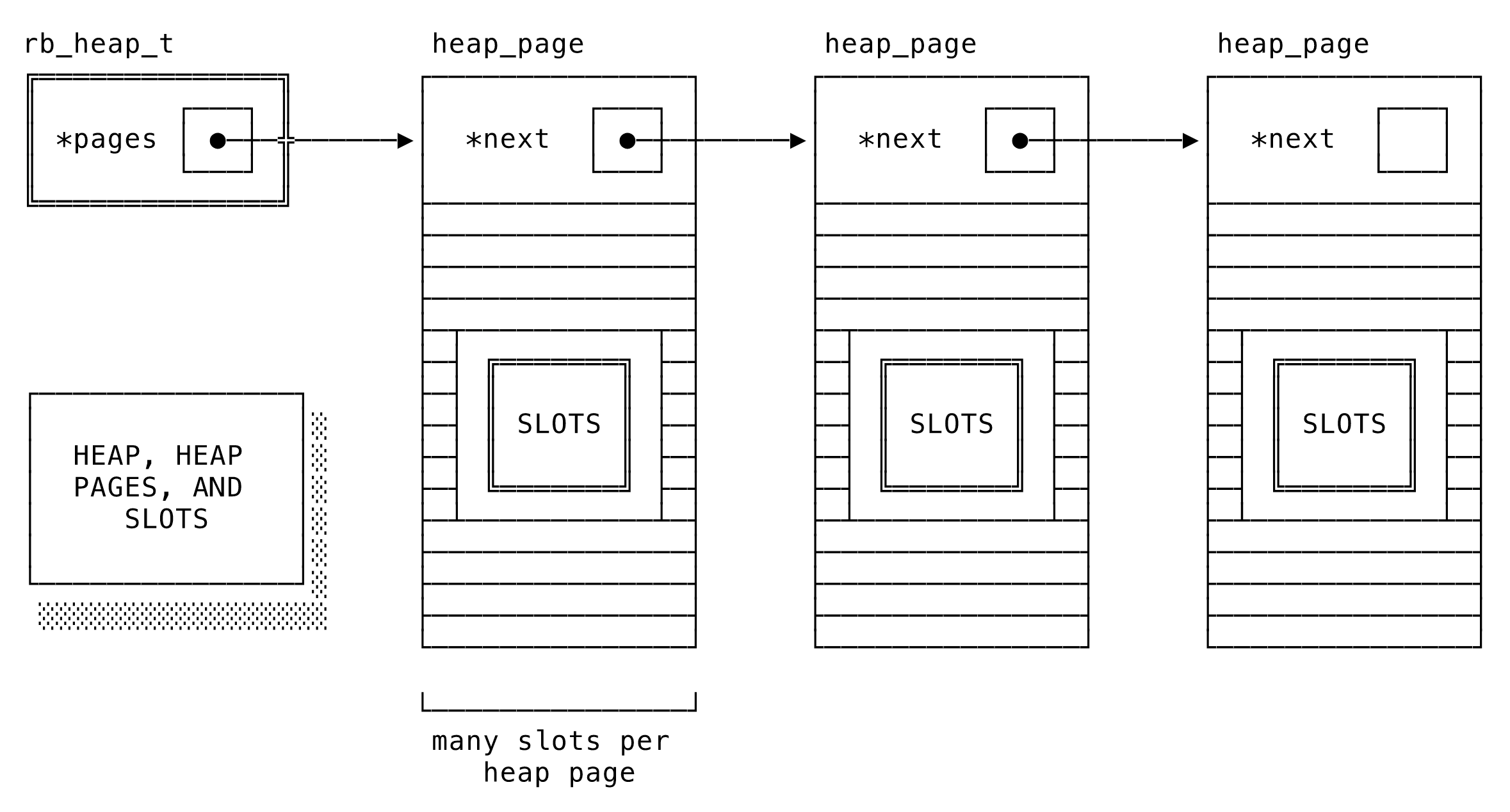
1つの(Ruby)ヒープ、そのヒープページ、各ページごとのスロット
1つのヒープページは「ヒープ(複数形はheaps)」と呼ばれることもあれば、「スラブ(slab)」や「アリーナ(arena)」と呼ばれることがあるのをご存知かもしれません。私としては曖昧さの少ない後者の2つが好みなのですが、Rubyのあらゆるソースで使われている呼び名に合わせて、以後1つのチャンクを「ヒープページ」、ヒープページが複数集まったコレクション1つを単に「ヒープ」と呼ぶことにします。
1つのヒープページは、1つのヘッダと多数の「スロット」でできています。各スロットにはRVALUEが1つずつあり、これはメモリ上のRubyオブジェクトです(詳しくは後述)。1つのヒープは1つのページを指し、そこから多数のヒープページが互いを指して、コレクション全体に繰り返される結合リスト(linked list)を1つ形成します。
ヒープを利用する
Rubyのヒープは、ruby_setup(eval.c)から呼び出されるInit_heap(gc.c)によって初期化されます。ruby_setupは1つのRubyプロセスへの主要なエントリポイントです。ruby_setupはこのヒープに沿ってスタックとVMも初期化します。
void
Init_heap(void)
{
heap_add_pages(objspace, heap_eden,
gc_params.heap_init_slots / HEAP_PAGE_OBJ_LIMIT);
...
}
Init_heapは、スロットのターゲット数を元に初期のページ数を決定します。デフォルト値は10,000ですが、設定や環境変数で調整可能です。
#define GC_HEAP_INIT_SLOTS 10000
設定に応じて、1ページあたりのスロット数が大まかに算出されます(gc.c)。ターゲットサイズは16k(2*14または1 << 14)から始まり、そこからmallocの予約(bookkeeping)1分の数バイトを引き、ヘッダー用の数バイトも引いてから、RVALUE構造体の既知のサイズで割ります。
/* default tiny heap size: 16KB */
#define HEAP_PAGE_ALIGN_LOG 14
enum {
HEAP_PAGE_ALIGN = (1UL << HEAP_PAGE_ALIGN_LOG),
REQUIRED_SIZE_BY_MALLOC = (sizeof(size_t) * 5),
HEAP_PAGE_SIZE = (HEAP_PAGE_ALIGN - REQUIRED_SIZE_BY_MALLOC),
HEAP_PAGE_OBJ_LIMIT = (unsigned int)(
(HEAP_PAGE_SIZE - sizeof(struct heap_page_header))/sizeof(struct RVALUE)
),
}
64ビットシステムの場合、RVALUEは40バイトを占めます。デフォルトのRubyが最初に408スロット2ごとに24ページを割り当てていることを示すために、一部の計算を省略します。メモリがもっと必要になるとヒープは増大します。
RVALUE: メモリスロット上のオブジェクト
1つのヒープページ内にあるスロット1つにつきRVALUEが1つあり、メモリ上のRubyオブジェクトを表現します。定義は以下のとおりです(gc.cより)。
typedef struct RVALUE {
union {
struct RBasic basic;
struct RObject object;
struct RClass klass;
struct RFloat flonum;
struct RString string;
struct RArray array;
struct RRegexp regexp;
struct RHash hash;
struct RData data;
struct RTypedData typeddata;
struct RStruct rstruct;
struct RBignum bignum;
struct RFile file;
struct RNode node;
struct RMatch match;
struct RRational rational;
struct RComplex complex;
} as;
...
} RVALUE;
ここは私にとって、Rubyが任意の型を任意の変数に代入できるという神秘のベールが最初に剥がされる場所です。上から、RVALUEとは単にRubyがメモリ上に保持している、取り得るすべての型の巨大なリストにすぎないことが直ちにわかります。すべての型が同じメモリを共有できるようにCの共用体(union)で圧縮されています。共用体には一度に1つずつしか設定できませんが、その共用体全体のサイズは、最大でもリストの個別の型の最大サイズにしかなりません。
スロットを具体的に理解するため、そこに保持される可能性のある型の1つを見てみることにしましょう。以下は典型的なRubyの文字列です(ruby.hより)。
struct RString {
struct RBasic basic;
union {
struct {
long len;
char *ptr;
union {
long capa;
VALUE shared;
} aux;
} heap;
char ary[RSTRING_EMBED_LEN_MAX + 1];
} as;
};
RString構造体を眺めてみると、いくつか興味深い点が浮かび上がってきます。
RBasicを含む。これはメモリ上にあるすべてのRuby型を区別しやすくするための共通の構造体です。-
ary[RSTRING_EMBED_LEN_MAX + 1]を含む共用体は、文字列の内容がOSヒープに保存されるのに対し、短い文字列はRString値にインラインで含まれることがわかります。全体の値は、メモリ割り当ての追加なしにスロットに収まります。 -
ある文字列は別の文字列を参照することがあり(上の
VALUE sharedの部分)、割り当てられたメモリを共有します。
VALUE: ポインタ兼スカラー
RVALUEはRuby標準のさまざまな型を保持しますが、すべての型を保持するわけではありません。Ruby C拡張のコードを読んだことがあれば、VALUEというよく似た名前に見覚えがあるでしょう。これは一般にRubyのあらゆる値の受け渡しに使われる型です。VALUEの実装はRVALUEよりややシンプルであり、単なるポインタです(ruby.hより)。
typedef uintptr_t VALUE;
ここでRubyの実装が賢くなります(残念だと思う人もいるかもしれませんが)。VALUEは多くの場合RVALUEへのポインタですが、定数との比較やさまざまなビットシフトを駆使して、ポインタのサイズに収まる、ある種のスカラー型を保持することもあります。
true、false、nilについては簡単です。これらはruby.hに値として事前定義されています。
enum ruby_special_consts {
RUBY_Qfalse = 0x00, /* ...0000 0000 */
RUBY_Qtrue = 0x14, /* ...0001 0100 */
RUBY_Qnil = 0x08, /* ...0000 1000 */
...
}
いわゆるfixnum(ごく大ざっぱに言うと64ビットに収まる数値)はもう少し複雑です。fixnumはVALUEを1ビット左にシフトして保存し、最下位にフラグを1つ設定します。
enum ruby_special_consts {
RUBY_FIXNUM_FLAG = 0x01, /* ...xxxx xxx1 */
...
}
#define RB_INT2FIX(i) (((VALUE)(i))<<1 | RUBY_FIXNUM_FLAG)
flonum(浮動小数点など)やシンボルの保存にも類似の手法が使われています。VALUEの型の識別が必要になると、Rubyはポインタの値をフラグのリストと比較します。このリストは、スタックに紐付けられた型を知っています。どのフラグともマッチしない場合は、ヒープに進みます(ruby.hより)。
static inline VALUE
rb_class_of(VALUE obj)
{
if (RB_IMMEDIATE_P(obj)) {
if (RB_FIXNUM_P(obj)) return rb_cInteger;
if (RB_FLONUM_P(obj)) return rb_cFloat;
if (obj == RUBY_Qtrue) return rb_cTrueClass;
if (RB_STATIC_SYM_P(obj)) return rb_cSymbol;
}
else if (!RB_TEST(obj)) {
if (obj == RUBY_Qnil) return rb_cNilClass;
if (obj == RUBY_Qfalse) return rb_cFalseClass;
}
return RBASIC(obj)->klass;
}
値の特定のいくつかの型をスタック上に保持しておくことで、ヒープ上のスロットを専有せずに済むというメリットが生じ、速度面でも有利です。flonumがRubyに追加されたのは比較的最近であり、flonumの作者は単純な浮動小数点の計算が2倍程度まで高速化すると見積もりました。
衝突の回避
VALUEのスキームは賢くできていますが、あるスカラー値がポインタと衝突しないことをどうやって保証しているのでしょうか。ここで賢さがさらにパワーアップします。RVALUEのサイズが40バイトになっている経緯を思い出しましょう。アラインされたmallocとサイズの組み合わせは、RubyがVALUEに保存する必要のあるRVALUEのアドレスが必ず40で割り切れることを示しています。
2進数では、40で割り切れる数値の最下位3ビットは必ずゼロになります(...xxxx x000)。スタックに紐付けられる型(fixnum、flonum、シンボルなど)をRubyが識別するのに使われるあらゆるフラグは、この3つのビットのいずれかに関連するので、こうした型とRVALUEポインタは確実に住み分けられます。
ポインタに別の情報を含めるのはRubyに限りません。この手法を用いた値は、より一般には「タグ付きポインタ(tagged pointer)」と呼ばれます。
オブジェクトを割り当てる
ヒープについての基礎をいくつか押さえたので、Unicornの賢いプロセスが親プロセスと何も共有しない理由にもう少し迫ってみましょう(鋭い人はもうお気づきかもしれません)。ここから先は、Rubyがあるオブジェクト(ここでは文字列)を初期化する方法を辿ってみたいと思います。
str_new0から始めます(string.cより)。
static VALUE
str_new0(VALUE klass, const char *ptr, long len, int termlen)
{
VALUE str;
...
str = str_alloc(klass);
if (!STR_EMBEDDABLE_P(len, termlen)) {
RSTRING(str)->as.heap.aux.capa = len;
RSTRING(str)->as.heap.ptr = ALLOC_N(char, (size_t)len + termlen);
STR_SET_NOEMBED(str);
}
if (ptr) {
memcpy(RSTRING_PTR(str), ptr, len);
}
...
return str;
}
先ほどRStringを調べたときの推測と似て、Rubyは新しい値が十分短い場合はスロットに埋め込みます。そうでない場合はALLOC_Nを使ってOSのヒープに文字列用の新しいスペースを割り当て、内部のポインタがそのスロット(as.heap.ptr)を指して参照できるようにします。
スロットを初期化する
いくつかの間接参照の層を経て、str_allocがgc.cのnewobj_ofを呼び出します。
static inline VALUE
newobj_of(VALUE klass, VALUE flags, VALUE v1, VALUE v2, VALUE v3, int wb_protected)
{
rb_objspace_t *objspace = &rb_objspace;
VALUE obj;
...
if (!(during_gc ||
ruby_gc_stressful ||
gc_event_hook_available_p(objspace)) &&
(obj = heap_get_freeobj_head(objspace, heap_eden)) != Qfalse) {
return newobj_init(klass, flags, v1, v2, v3, wb_protected, objspace, obj);
}
...
}
Rubyは、スロットに空きのあるヒープを問い合わせるのにheap_get_freeobj_headを使います(gc.c)。
static inline VALUE
heap_get_freeobj_head(rb_objspace_t *objspace, rb_heap_t *heap)
{
RVALUE *p = heap->freelist;
if (LIKELY(p != NULL)) {
heap->freelist = p->as.free.next;
}
return (VALUE)p;
}
Rubyには、スレッドがいくつあっても一度に1つだけが実行されるようにするためのグローバルなロック(GIL)があるので、次のRVALUEをヒープの空きリストから安全に外して次の空きスロットを指し直すことができます。これ以上細かいロックは不要です。
空きスロットを獲得した後は、newobj_initがいくつか一般的な初期化を行ってからstr_new0に処理を戻して文字列固有の設定を行います(実際の文字列のコピーなど)。
eden、tomb、空きリスト
Rubyが空きスロットをheap_edenに問い合わせることを既にお気づきの方もいるかもしれません。edenという名前は聖書の「エデンの園」から命名された3ヒープのことで、Rubyはそこに生きているオブジェクトがあることを知っています。Rubyは2つのヒープをトラックしていますが、そのうちの1つです。
そしてもう1つが「tomb」です。実行後に、生きているオブジェクトがヒープページに残っていないことをガベージコレクタが検出すると、そのページはedenからtombに移動します。Rubyがある時点で新しいヒープページの割り当てが必要になると、OSにメモリ追加を要求する前に、tombから呼び戻すことが優先されます。逆に、tombのヒープページが長時間死んだままの場合、RubyはページをOSに返却します(実際にはそれほど頻繁には発生せず、一瞬で終わります)。
ここまで、Rubyが新しいページを割り当てる方法について簡単に説明しました。OSによって新しいメモリが割り当てられると、Rubyは新しいページをスキャンしていくつか初期化を行います(gc.cより)。
static struct heap_page *
heap_page_allocate(rb_objspace_t *objspace)
{
RVALUE *start, *end, *p;
...
for (p = start; p != end; p++) {
heap_page_add_freeobj(objspace, page, (VALUE)p);
}
page->free_slots = limit;
return page;
}
Rubyはそのページの開始スロットから末尾のスロットまでのメモリオフセットを算出し、一方の端から他方の端まで進みながらスロットごとにheap_page_add_freeobjを呼び出します(gc.cより)。
static inline void
heap_page_add_freeobj(rb_objspace_t *objspace, struct heap_page *page, VALUE obj)
{
RVALUE *p = (RVALUE *)obj;
p->as.free.flags = 0;
p->as.free.next = page->freelist;
page->freelist = p;
...
}
このヒープ自身は、空いていることがわかっているスロットへの空きリストポインタを1つトラックしますが、そこからRVALUE自身のfree.nextをたどると新しい空きスロットが見つかります。既知の空きスロットはすべて、heap_page_add_freeobjが構成した長大な連結リストで互いに連鎖しています。
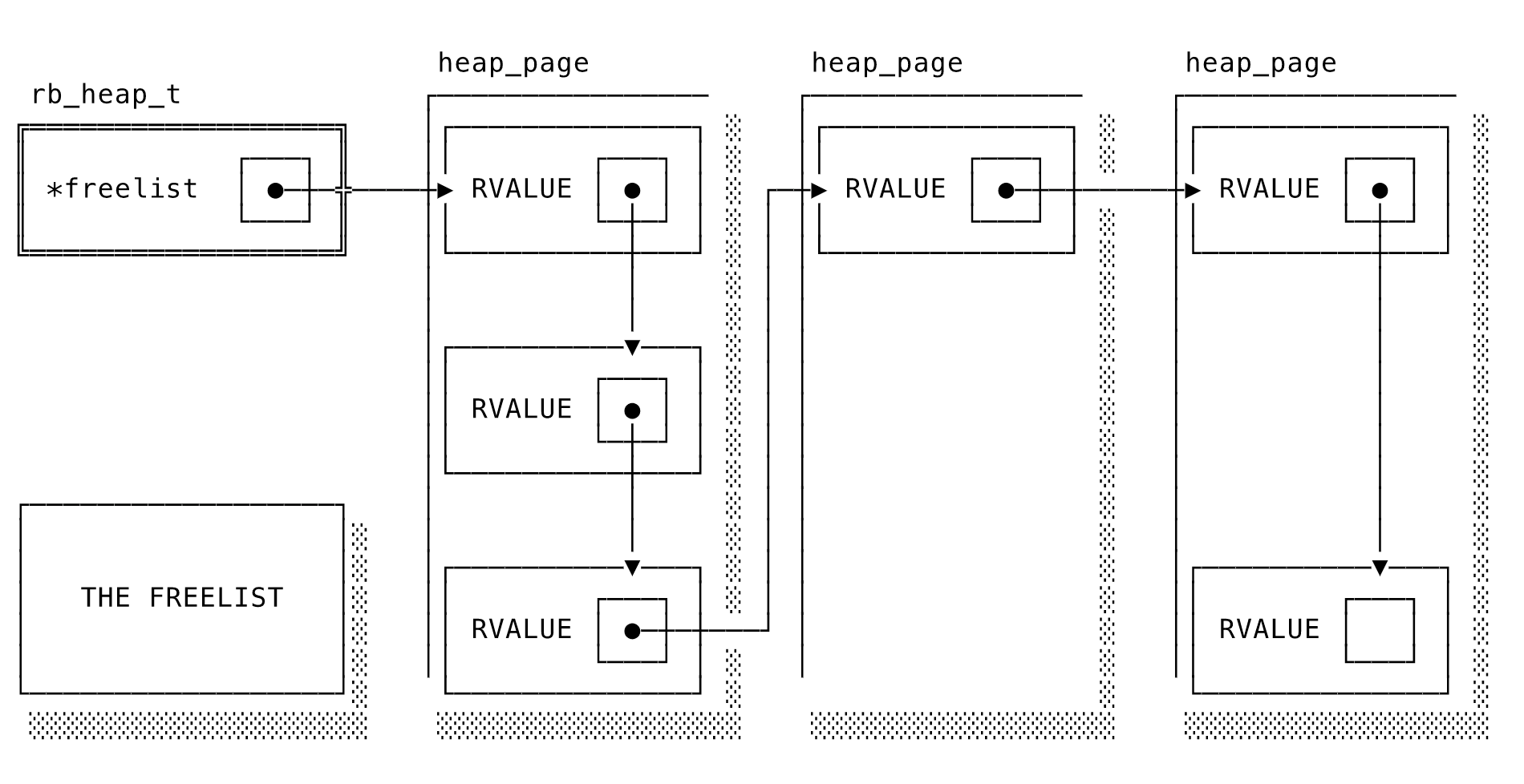
あるヒープにおける、空いている
RVALUEを指す空きリストポインタと、連結リストの連鎖
heap_page_add_freeobjが呼ばれてページを初期化します。これはオブジェクトが開放されたときにもガベージコレクタによって呼び出されます。このようにしてスロットが空きリストに戻され、再利用できるようになります。
肥大化したワーカーの事例についての結論
Rubyは精巧なメモリ管理戦略を備えていますが、これらのコードを読んでみると、何かがOSのcopy-on-writeとうまく噛み合っていないことにお気づきかもしれません。Rubyは拡張可能なヒープページをメモリに割り当て、そこにオブジェクトを保存し、可能になったらスロットをガベージコレクションします。空きスロットは注意深くトラックされているのでランタイムは効率よく空きスロットを見つけられます。しかし、これほど洗練されているにもかかわらず、生きているスロットの位置はヒープページ内やヒープページ間でまったく変わらないのです。
オブジェクトの割り当てと解放が常に発生する実際のプログラムでは、すぐに、生きているオブジェクトと死んだオブジェクトが混じり合った状態になってしまいます。ここで思い出されるのがUnicornです。親プロセスが自分自身をセットアップしてからfork可能な状態になるまでの間、親プロセスのメモリはちょうど、利用可能なヒープページ全体に渡って生きているオブジェクトが断片化している典型的なRubyプロセスと似た状態になっています。
ワーカーは、自身のメモリ全体を親プロセスと共有した状態から開始します。残念なことに、子が最初にスロットを1つでも初期化またはGCすると、OSは呼び出しをインターセプトして背後のOSページをコピーします。まもなく、プログラムに割り当てられているあらゆるページでこれが発生し、子ワーカーは親から完全に分岐してしまったメモリのコピーで実行されます。
copy-on-writeは強力な機能ですが、Rubyプロセスのforkにはあまり向いていません。
copy-on-writeへの対策
Rubyチームはcopy-on-writeに精通しており、ある時期に最適化を進めてきました。たとえば、Ruby 2.0ではヒープの「bitmap」が導入されました。Rubyでは「マークアンドスイープ」方式のガベージコレクタが使われており、これはオブジェクト領域全体をスキャンして生きているオブジェクトを見つけるとマーキングし、死んでいるものをすべて片付ける(sweep)というものです。従来のマーキングは1つのページ内の各スロットに直接フラグを設定するのに使われていましたが、これによってあらゆるforkでGCが実行され、マーキングが渡されるとOSページが常に親プロセスからコピーされていました。
Ruby 2.0の変更によって、これらのマーキングフラグがヒープレベルの「bitmap」に移動しました。これは、そのヒープのスロットをマッピングする単一ビットの巨大なシーケンスです。GCがあるforkでこれを渡すと、bitmapで必要なOSページだけがコピーされ、共有期間がより長いメモリをさらに多く利用できるようになりました。
今後の「圧縮」機能
今後導入される変更はさらに期待できます。Aaron Patterson氏はある時期にRuby GCの圧縮の実装について話していて、GitHub本番で導入した結果ある程度の成功を収めたとのことです。具体的には、ワーカーがforkする前に呼び出されるGC.compactという名前のメソッドであるようです。
# ワーカーが親からforkするときに常に呼び出される
before_fork do
GC.compact
end
初期化の一環としてオブジェクトの大量作成を終了できた親プロセスは、まだ生きているオブジェクトを、より長期間安定しそうなページの最小セット上のスロットに移動します。forkしたワーカーは、より長期間親プロセスとメモリを共有できるようになります。
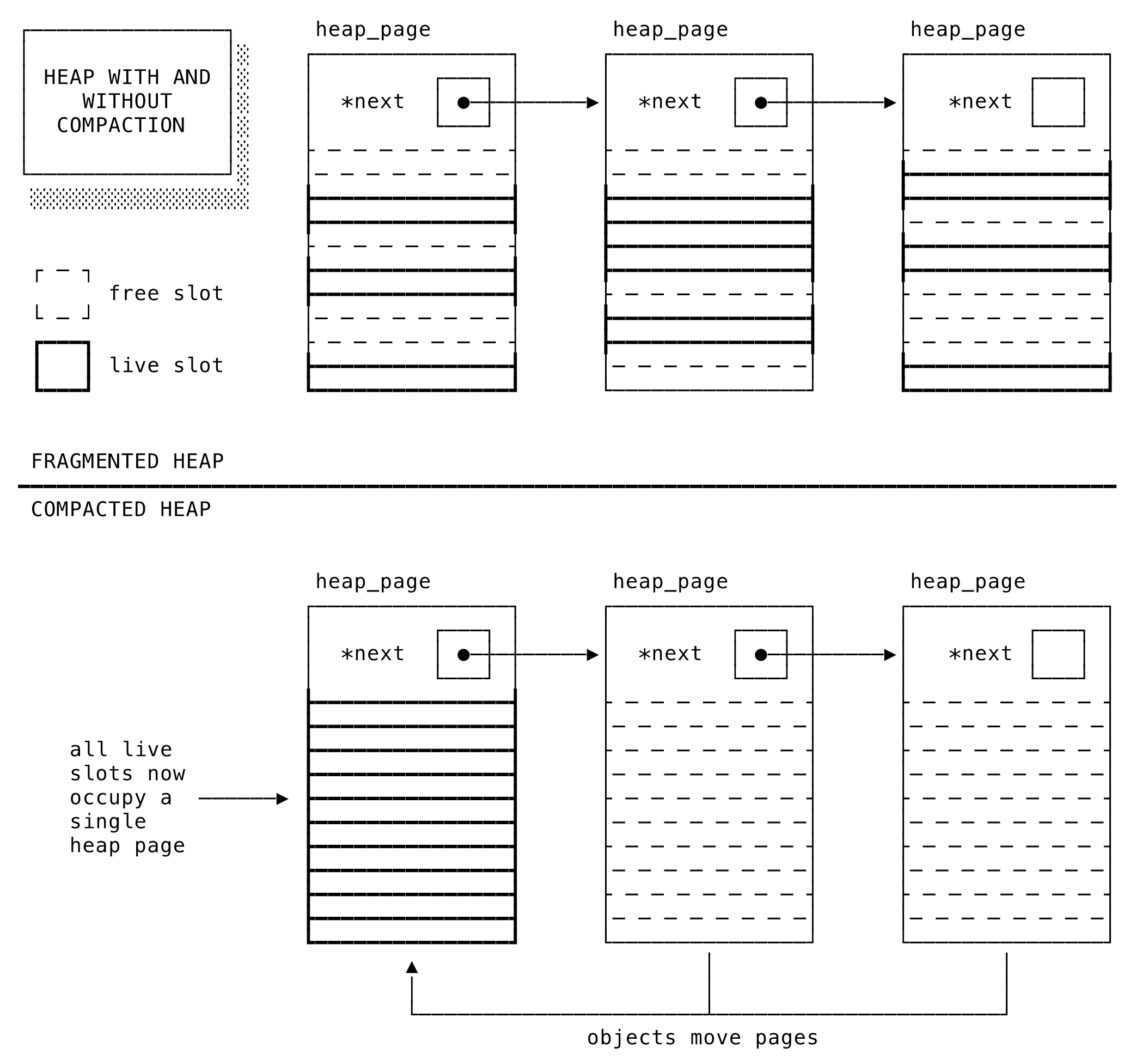
GC圧縮前後の断片化したヒープ
これは、GitHubやHeroku、または私たちがStripeでやっているような巨大なRubyインストールを実行しているすべての人にとって実に期待できる成果です。メモリを大量に使うインスタンスをデプロイしても、メモリは多くの場合、実行可能なワーカー数という限定されたリソースに収まります。GC圧縮は各ワーカーで必要なメモリのかなりの部分を削減する能力を持ちます。メモリ削減によってboxごとに実行できるワーカー数が増加し、boxの総数も削減できます。注意点もほとんどなく、多数のワーカーを実行するコストが直ちに削減されます。
本記事へのコメントや議論はHacker Newsまでどうぞ。
もし誤りがありましたら、プルリク送信をご検討ください。