こんにちは、hachi8833です。
これは一体どういうことなのでしょうか。
CSS Text Module Level 3の改行周りの仕様
何はともあれ、仕様を参照してみます。以下の仕様は2016-09-28のドラフトです。
When white-space is pre, pre-wrap, or pre-line, segment breaks are not collapsible and are instead transformed into a preserved line feed (U+000A).
For other values of white-space, segment breaks are collapsible, and are either transformed into a space (U+0020) or removed depending on the context before and after the break:
・If the character immediately before or immediately after the segment break is the zero-width space character (U+200B), then the break is removed, leaving behind the zero-width space.
・Otherwise, if the East Asian Width property [UAX11] of both the character before and after the line feed is F, W, or H (not A), and neither side is Hangul, then the segment break is removed.
・Otherwise, the segment break is converted to a space (U+0020).
4.1.2. Segment Break Transformation Rules(Editor’s Draft, 28 September 2016)
なお、現時点で「Last Call Drafts」となっている仕様は2013-10-10となっていますが、この部分の記述は同じです。
大意
white-space: pre(=連続スペースを1つにせず改行をそのまま表示)、white-space: pre-wrap(=連続スペースを1つにしないがワードラップは行う)、white-space: pre-line(=連続スペースを1つにしてワードラップも行うが改行はそのまま表示)のいずれかを指定すると、segment break(いわゆる改行記号: CRLF、CR、LF)は消えずに1つのLFに変換される。
white-spaceがそれ以外の値の場合segment breakは消え、スペース1つに変換されるか、以下のような前後の状況に応じて削除される。
- segment breakの直前や直後に「ゼロ幅のスペース文字」があると、segment breakは削除され、「ゼロ幅のスペース文字」は削除されない。
- 改行文字の直前や直後にある文字の
East Asian WidthプロパティがF、W、Hのいずれかであり、Aでなく、ハングルでもない場合は、segment breakを削除する。 - それ以外の場合はsegment breakをスペース1つに変換する。
参考: East Asian Width
値についてはEast Asian Widthに以下のようにあります。「全角/半角」という単純な区別だけではない点に注意が必要です。
F(Full): Unicode Standardで全角と定義されている文字です。H(Half): Unicode Standardで半角と定義されている文字です。W(Wide): 全角と半角の2種類ある文字のうち「全角」に分類される文字です。これの対がNa(Narrow)になります。A(Ambiguous):文字コードだけでは幅が全角か半角かを決められない文字です(日本語の文字セットから持ち込まれたギリシャ文字・キリル文字・数学記号など)
「改行を削除してもスペースは削除しない」はず
該当部分は箇条書きの2番目の項目にありました。ざっくり言うと、改行文字の前後がいわゆる漢字などの全角文字であれば改行は削除しますが、そのときに改行をスペースに置き換えるとは書かれていません。

あ、仕様のすぐ下にあった。「念のため言っておくが、現状のブラウザはこのルールに従ってない(IEは場合によっては改行を置き換えているが)」と。
現状黙認ということなのでしょうか。
実際のブラウザの動作
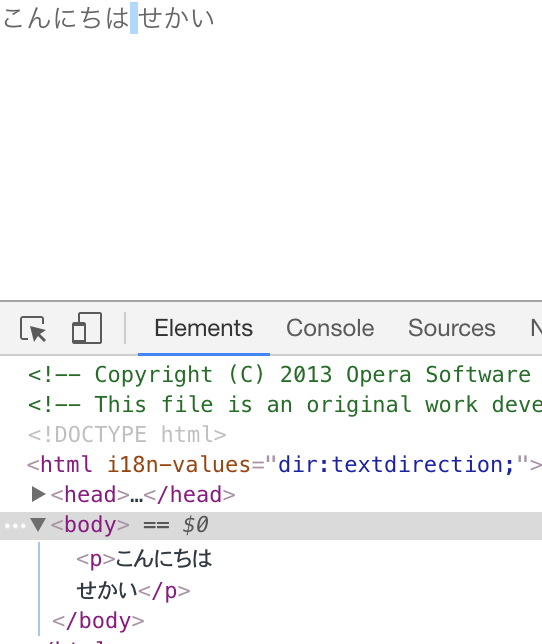
手元のいくつかのブラウザで確認してみました。babaさんの言うとおり、仕様と異なる動作になっています。
Chrome
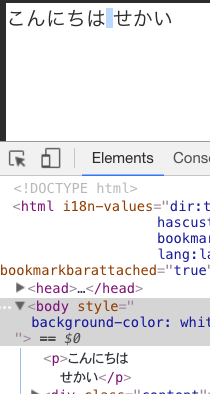
Firefox
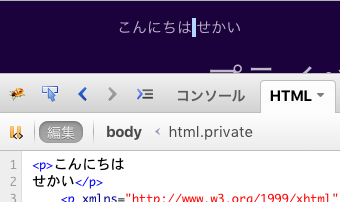
Opera
まとめ
自分の覚えている限りでは、ブラウザは昔からこのように日本語であるなしを問わず改行をスペースに置き換えていました。もともと英語での動作がそのようになっているので、皆そういうものだと認識していたように思います。かつ、HTMLを書く上でこうした無駄な改行を含めるのは本当はよろしくありません。
何より、今からこの仕様を実装すると相当な混乱が巻き起こる可能性も考えられます。おそらくそうした理由で大きな問題にならずに済んでいるのでしょう。
「ブラウザで実装されてないという現状は認識しておる」という注釈があることからして、この問題について少々フィードバックしたぐらいでは修正されなさそうです。

これか。レ、レスが付いてない...(´;ω;`)
ともあれ、W3Cで規定されている仕様であっても、すべてのブラウザでそれらが正しく実装されている保証があるわけではないという事実を改めて痛感する話でした。
追記: East Asian Width
仕様を読んでいて、East Asian Widthという項目をわざわざ設けて全角と半角をF/H/W/Na/Aなどという苦しい分類をしているところにW3Cで規格を策定している側の苦労が偲ばれました。
ここからはあくまで私の想像ですが、Unicodeの制定で日本語の文字コード体系から全角英数字やギリシャ文字やキリル文字などが独自に持ち込まれてしまい、今さら重複を取り除くわけにも行かず、こうやってしのいだのではないでしょうか。Unicodeに持ち込まれる文字セットの重複や不備が常にみっちり精査されているとは限らず、少々いい加減なコード体系でも追加を申請すると割と通ってしまうらしいとどこかで読んだような気がします。このあたりはまた別の記事で調べることにしましょう。