- Ruby / Rails関連
[Rails5] Active Support Core Extensionsのマルチバイト系メソッド: String#mb_charsとis_utf8?
こんにちは、hachi8833です。ActiveSupport探訪シリーズ、今回はかわいらしいIntegerクラスに続いてStringのマルチバイト系メソッドにお邪魔します。
短いコードは他のメソッドにガンガン委譲していることの多いActive Supportですが、今回はどうでしょうか。
条件
- Railsバージョン: 5.0.2(5-0-stable)
- Rubyバージョン: 2.4.0
active_support/core_ext/string/multibyte.rb
- multibyte.rbのコードはこれまた簡素です。
require 'active_support/multibyte'
class String
def mb_chars
ActiveSupport::Multibyte.proxy_class.new(self)
end
def is_utf8?
case encoding
when Encoding::UTF_8
valid_encoding?
when Encoding::ASCII_8BIT, Encoding::US_ASCII
dup.force_encoding(Encoding::UTF_8).valid_encoding?
else
false
end
end
end
String#mb_chars- 文字列系メソッド用のマルチバイトセーフなプロキシ
String#is_utf8?- UTF-8かどうかを論理値で返す
String#mb_charsの方はこれだけでは不足なので、コメントをざっと訳してみます。
String#mb_charsのコメント訳
マルチバイトプロキシ
String#mb_charsは、文字列系メソッドで使えるマルチバイトセーフなプロキシです。
String#mb_charsを呼び出すとActiveSupport::Multibyte::Charsクラス(訳注: 以下単にCharsクラス)を返します。このクラスには元の文字列がカプセル化されて保存されます。Stringクラスのメソッドのうち、Unicodeに対応しているものはすべてこのプロキシクラス上で定義されます。Stringクラスの特定のメソッドがこのプロキシクラスに応答しない場合、カプセル化された文字列にメソッドが転送されます。
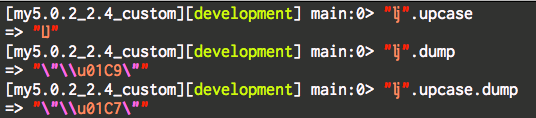
"lj".upcase # => "lj"
"lj".mb_chars.upcase.to_s # => "LJ"
メソッドチェーン
Charsプロキシ上の、通常なら文字列を返すすべてのメソッドはCharsオブジェクトを返すようになります。これにより、それらのどのメソッドから返った結果もほかのメソッドにチェインできるようになります。
name.mb_chars.reverse.length # => 12
相互変換と設定
このCharsオブジェクトは、できる限りStringオブジェクトと相互変換可能になっています。これにより、StringとCharsの間でのソートや比較が期待どおり動作します。
!のついた破壊的メソッドを使うと、内部の文字列表現はCharsオブジェクトに変換されます。相互変換の問題は#to_sを呼び出すことで簡単に解決できます。
Charsプロキシに定義されているメソッドについて、詳しくはActiveSupport::Multibyte::Charsをご覧ください。デフォルトのMultibyteクラスの動作を変更する方法については、ActiveSupport::Multibyteをご覧ください。
String#mb_charsを動かしてみる
というわけで、コードは簡潔でもやはり読み取りは一筋縄ではいきませんでした。
Rails 5.0.2 + Ruby 2.4で"lj".upcaseを実行してみると、あれ?#mb_charsしなくても大文字に変換できました。少なくともString#upcaseはマルチバイトに対応しています。
multibyte.rbの履歴を見てみると、2015年から特に動きがありません。履歴は2008年から始まっていて、Ruby 1.9での対応がそもそものきっかけだったようです。
Ruby 2.4では#mb_charsが不要なこともある
そこで思い出したのが、ActiveSupport探訪シリーズの以前の記事「ActiveSupport::Inflectorの便利な活用形メソッド群」や「週刊Railsウォッチ(20161117)」でも取り上げた、Ruby 2.4での非ASCII文字の大文字小文字変換の拡張です。
Ruby 2.3(Railsは5.0.1)でもう一度やってみると、今度は上のサンプルのとおり#mb_charsを介することで大文字に変換できました。

ということで、少なくとも以下の4つのメソッドについてはRuby 2.4を使っていれば#mb_charsなしでUnicode仕様に沿った大文字小文字変換に対応できます。
その他の#decomposeといったメソッドをマルチバイトセーフに扱うには、ActiveSupport::Multibyte::Charsに記載されているように#mb_charsを介して使います。
'é'.length # => 2
'é'.mb_chars.decompose.to_s.length # => 3
Ruby 2.4のString#casecmpはUnicode仕様に非対応
String#casecmpは大文字小文字の違いを除外した文字列比較メソッドですが、#10085によるとRuby 2.4ではまだUnicode仕様に対応していない([A-Za-z]のみ対応)とのことなので、ActiveSupportのActiveSupport::Multibyte::Unicode#normalizeで正規化する必要があります。
"lj".casecmp(ActiveSupport::Multibyte::Unicode.normalize "lj") #=> 0
"lj".casecmp(ActiveSupport::Multibyte::Unicode.normalize "LJ") #=> 0

String#mb_charsだけでは#casecmpに対応できません。
"lj".mb_chars.to_s.casecmp("LJ".mb_chars.to_s) #=> 1
"lj".mb_chars.upcase.to_s.casecmp("LJ".mb_chars.to_s) #=> 0

ActiveSupport::Multibyte::Charsクラスについて追いきれなかったので、次回再挑戦いたします。
追伸
つい先ごろ「「ユニコード」で予期せぬ目に遭った話」という記事が話題になりました。String#mb_charsからは外れますが、同記事で言及されていた以下の文字について私も少しだけ確認してみました。
「西」 (WEST U+897F) ⇔「⻄」(CJK RADICAL WEST TWO U+2EC4)
2つの文字はほぼそっくりですが、前者は普通の文字、後者は漢字の「部首」であり、意味論(semantics)的に異なるものとして扱われます。この2つの文字は現在のUnicodeの定義上#normalizeで均すことができませんし、同じに扱われてはいけない文字です。
ActiveSupport::Multibyte::Unicode.normalize("西").dump #=> "\"\\u897F\""
ActiveSupport::Multibyte::Unicode.normalize("⻄").dump #=> "\"\\u2EC4\""

現実にこうした部首文字が混入してしまった場合のことを考えると、なかなか頭の痛い問題です。