Ruby: mallocでマルチスレッドプログラムのメモリが倍増する理由(翻訳)
要約
メモリ断片化は測定や診断が困難ですが、驚くほど簡単に修正できることもあります。マルチスレッドのCRubyプログラム(mallocのスレッド単位メモリアリーナ)におけるメモリ断片化の原因を追ってみましょう。本記事のボリュームは3343語、20分程度です。
単純な設定変更だけで問題を完全に解決できることはめったにありません。
私の顧客のSidekiqプロセスが大量のメモリを消費していたことがありました(1プロセスあたり1 GB程度)。開始当初の各プロセスは300MB程度でしたが、時間の経過とともにじわじわと肥大化してほぼギガバイトレベルにまで達したところで落ち着き始めました。
私は顧客にMALLOC_ARENA_MAXというたった1つの環境変数の変更を依頼しました。「2に設定してください」と。
プロセス再起動後、「じわじわ肥大化」現象はピタリと止みました。プロセスのメモリ使用量は以前の半分程度(512 MBぐらい)に落ち着いたのです。

「うっそぴょーん」
実際はそんな単純な話ではありません。
フリーランチは存在しませんが、ほぼ無料(10円ランチ程度)だったと言えなくもないぐらいでした。
ここまで読んでこの「魔法の」環境変数をアプリ環境にコピペして回る前に、「この方法にはいくつもの欠点がある」ということを知っておいてください。この方法で解決される問題のことで今のあなたが困っているとも限りません。銀の弾丸はないのです。
Rubyがメモリ使用量の少ない言語であることは、意外に知られていません。しかしRailsアプリの多くは1プロセスあたりのメモリ使用量が1 GBに達する問題に悩まされています。これはJavaレベルに匹敵しつつあります。Rubyのバックグラウンドジョブプロセッサとして有名なSidekiqのプロセスも、同程度かそれより巨大になることがあります。理由はいろいろありますが、特に、断片化の診断とデバッグが極端に難しいこともそのひとつです。
この問題は、速度の低下や、Rubyプロセスの不気味なメモリ肥大化という形で顕在化します。そしてよくメモリリークと間違えられます。しかしメモリリークは直線的に増加しますが、断片化によるメモリの肥大化は対数的に増加します。
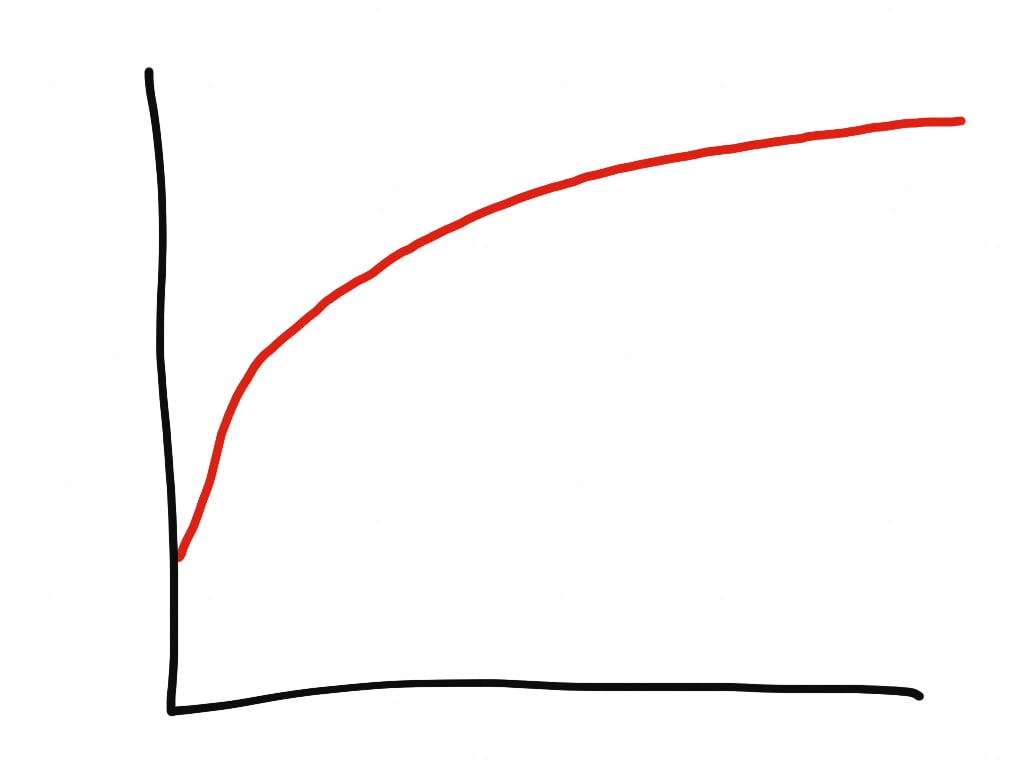
Rubyメモリは対数的に肥大化するのが典型的
普通、Rubyプログラムのメモリリークの原因はC拡張のバグによるものです。たとえば、markdownパーサーで呼び出しのたびに10 KBずつリークすると、markdownパーサーの呼び出し頻度は一定になる傾向があるので、メモリ使用量は直線的に青天井で増加し続けます。
メモリ断片化は対数的なメモリ肥大化の原因になります。肥大化は長い曲線を描いて、見えないどこかの上限値に向かいます。メモリ断片化はあらゆるRubyプロセスである程度発生します。これはRubyのメモリ管理方法による、避けがたい結果です。
特に、Rubyではオブジェクトをメモリ内で移動できません。もし移動したら、Rubyオブジェクトへのポインタを持つC言語拡張が残らず破損するかもしれません。オブジェクトをメモリ内で移動できないのだとしたら、断片化は避けられません。これはRubyに限らず、多くのCプログラムで共通の問題です。
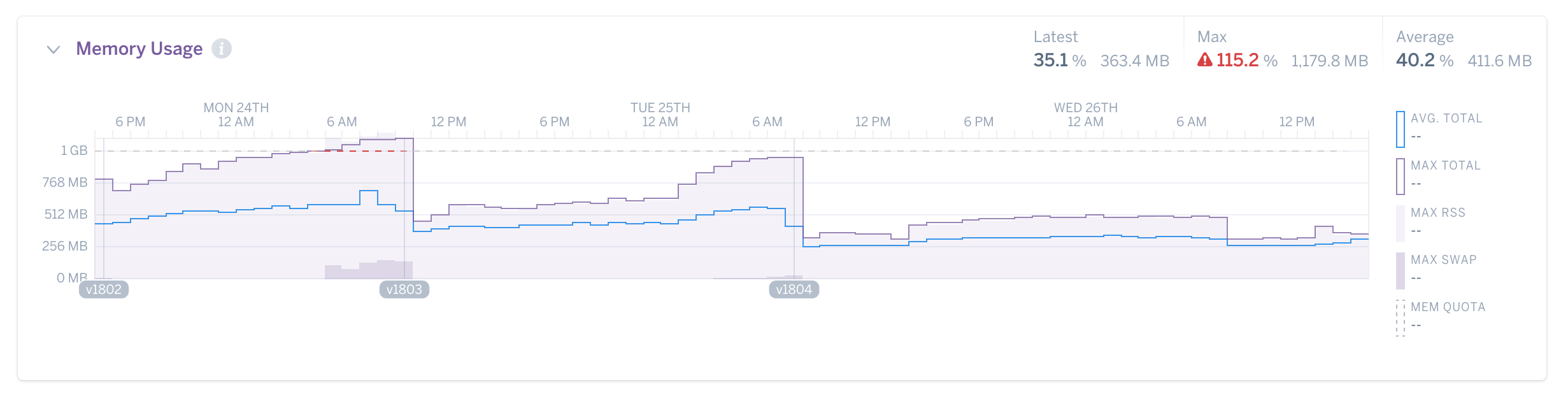
顧客の実際のグラフより: 断片化はこのような経過をたどります。MALLOC_ARENA_MAXを2にすると激減していることにご注目ください。
しかしRubyプログラムのメモリ使用量は、断片化によって通常の「倍」に、場合によっては4倍以上に達することすらあるのです!
Rubyプログラマーはメモリを意識することに慣れていません。特にmallocレベルではなかなか意識できません。Ruby言語全体が、抽象的なメモリをプログラマーが意識しないで済むように設計されているのですから、もちろんそれ自体は別に問題ありません。しかしRubyはメモリ安全性を保証できるにもかかわらず、完全なメモリ抽象化を提供できていません。メモリを完全に無視するわけにはいかないのです。というのも、Rubyプログラマーはコンピュータ上のメモリの動作についてそれほど経験を積んでいないので、いざ問題が発生すると、どこからデバッグを始めたらよいのか皆目見当がつかなくなることも多く、Rubyのような動的インタプリタ言語の本質的な機能だから仕方がないと諦めることもあります。
さらに厄介なのは、メモリが4つの異なる層によって抽象化され、Rubyistから見えなくなっていることです。第1層はRubyの仮想マシン(VM)そのものです。VMは独自の内部構造やメモリトラッキング機能を備えています(これはObjectSpaceと呼ばれることもあります)。第2層はアロケータです。この振る舞いは、用いる特定の実装によって大きく異なります。第3層はOSです。ここでは実際の物理メモリアドレスを仮想メモリアドレスに抽象化します。この抽象化はカーネルごとに大きく異なっています。たとえばMachの抽象化はLinuxとかなり異なります。最後の第4層は実際のハードウェアそのものです。ここでは、アクセスの多いデータが、頻繁にアクセスしやすい「ホット」な場所からなるべく移動しないようにするためにさまざまな戦略を用います。ときには、translation lookaside buffer(TLB)のような特殊なCPU部品まで関わっていることがあります。

「お姫様が4つの敷布団(メモリ抽象化)をめくると、何とその下が断片化し始めているではありませんか」
これらによって、Rubyistがメモリ断片化問題に対処することが非常に困難になっています。この問題は、仮想マシンやアロケータのレベルで一般的に発生しますが、ここはRubyistの95%にとって馴染みのない部分でもあります。
断片化には避けようのないものもありますが、Rubyプロセスのメモリ使用量が倍増するほど悪化する原因でもあります。今起きているのが避けられない断片化ではなく、メモリ使用量が倍増する断片化かどうかをどうやって知ればよいでしょうか。なお私は、PumaやPassenger Enterprise上で動作するWebアプリや、SidekiqやSucker PunchなどのマルチスレッドジョブプロセッサのマルチスレッドRubyアプリに影響するメモリ断片化の原因について論文を1本書いたことがあります。
glibc malloc内のスレッド単位メモリアリーナ
この問題は、いずれも標準glibcの「スレッド単位メモリアリーナ(per-thread memory arena)」と呼ばれるmalloc実装の特定の機能に集約されます。
理由を理解いただくためには、CRubyのガベージコレクション(GC)が驚くほど高速に実行される様子について説明する必要があります。
すべてのオブジェクトは、ObjectSpace内にエントリを1つ持ちます。ObjectSpaceは、プロセス内で動作しているあらゆるRubyオブジェクトのエントリを保持する巨大なリストです。リストの項目はRVALUEの形を取ります。RVALUEはオブジェクトの基本データの一部を保持する40バイトのC言語struct(構造体)です。構造体の正確な中身は、どのクラスのオブジェクトかによって変わります。たとえば、"hello"のような非常に短いStringの場合、文字データを実際に含むビットはRVALUE内に直接埋め込まれます。しかしRVALUEは40バイトしかないので、文字列が23バイト以上になると、RVALUEは、そのオブジェクトデータが実際に配置されるメモリの場所(つまりRVALUEの外)を参照する生のポインタだけを保持します。

Aaron PattersonによるObjectSpaceのビジュアル表示。
ピクセル1個が1つのRVALUEを表す。新しいのが緑、古いのが赤。
詳しくはheapfragを参照。
複数のRVALUEがObjectSpace内で編成されて16 KBの「ページ」になります。1つのページには約408個のRVALUEが含まれます。
この個数は、どのRubyプロセスについてもGC::INTERNAL_CONSTANTS定数で確認できます。
GC::INTERNAL_CONSTANTS
=> {
:RVALUE_SIZE=>40,
:HEAP_PAGE_OBJ_LIMIT=>408,
# ...
}
長い文字列を作成すると(たとえば1000文字のHTTPレスポンス)、次のようになります
ObjectSpaceリストにRVALUEを1つ追加します。ObjectSpaceの空きスロットが不足すると、malloc(16384)を呼び出してリストをヒープページ1つ分増やします。malloc(1000)を呼び出して、メモリ上1の1000バイトを指すアドレスを1つ受け取ります。
このmalloc呼び出しにご注目ください。私たちが行おうとしているのは、特定サイズのメモリ領域を(場所は問わずに)求めているだけです。実際には、mallocの隣接については定義されていないのです。つまり、メモリ上で実際に配置される場所については何の保証もないということになります。ということは、断片化(根本的にはメモリの場所の問題です)とは、Ruby VMから見ればアロケータの問題だということです2。
Ruby自体のObjectSpaceの断片化はある意味で測定可能です。GCモジュールのメソッドGC.statは、現在のメモリやGCのステートに関する情報を豊富に提供してくれます。情報がやや多い上にドキュメントも不十分ですが、次のようなハッシュを出力します。
GC.stat
=> {
:count=>12,
:heap_allocated_pages=>91,
:heap_sorted_length=>91,
# ... 他にも多数のキー ...
}
このハッシュの中でご注目いただきたいのは、GC.stat[:heap_live_slots]とGC.stat[:heap_eden_pages]の2つのキーです。
:heap_live_slotsは、生きている(=解放とマーキングされていない)RVALUE構造体が現在専有しているObjectSpace内のスロット数を表します。これはおおよそ「現在生きているRubyオブジェクト」の個数とみなせます。
:heap_eden_pagesは、生きているスロットを1つ以上含んでいるObjectSpaceページの個数を表します。生きているスロットを1つ以上含むObjectSpaceページは、「edenページ」と呼ばれます。生きているスロットを1つも含まないObjectSpaceページは「tombページ」と呼ばれます。tombページはOSに返却される可能性があるので、両者の違いはGC側にとって重要です。また、GCが新しいオブジェクトを最初に置くのはedenページであり、edenページに空きがない場合に初めてtombページに置きます。これによって断片化を軽減しています。

edenのヒープ
生きているスロット数を全edenページ内のスロット数で割ると、ObjectSpaceで現在発生している断片化の度合いを求められます。私が新しいirbプロセスで取得した例をご覧ください。
5.times { GC.start }
GC.stat[:heap_live_slots] # 24508
GC.stat[:heap_eden_pages] # 83
GC::INTERNAL_CONSTANTS[:HEAP_PAGE_OBJ_LIMIT] # 408
# live_slots / (eden_pages * slots_per_page)
# 24508 / (83 * 408) = 72.3%
私のedenページスロットのうち28%は現在空いています。空きスロットの割合が多いということは、ObjectSpaceのRVALUEが本来よりずっと多くのヒープページにばらまかれているということになります(もし見ることができればですが)。これは内部メモリの断片化の一種です。
Ruby VMの内部断片化を知るもうひとつの測定値はGC.stat[:heap_sorted_length]です。このキーは1つのヒープの「長さ」を表します。ObjectSpaceが3つあり、私が真ん中の2番目をfreeしたとすると、残るヒープページは2つだけになります。しかしヒープページはメモリ内を移動できないので、そのヒープの「長さ」(本質的にはそのヒープページのインデックスの最大値)は3のまま変わりません。
GC.stat[:heap_eden_pages]をGC.stat[:heap_sorted_length]で割ると、ObjectSpaceページレベルの内部断片化の測定値を得られます。この割合が低いと、ObjectSpaceリストのあちこちにヒープページ大の穴が開いていることになります。

断片化してるけどとってもおいしそうなヒープ
これらの測定値も興味深いのですが、ほとんどのメモリ断片化(およびアロケーション)はObjectSpaceの中では起きていないのです。断片化が発生するのは、1個のRVALUEに収まりきれないオブジェクトに空き(メモリ)を割り当てるときです。Aaron PattersonとSam Saffronによる実験結果によると、ほとんどがこれに該当することが判明しました。典型的なRailsアプリのメモリ使用量の50%〜80%は、たかが数バイトより大きなオブジェクトに空きメモリを割り当てるmalloc呼び出しによって占められています。
Well this sucks. Looks like only 15% of the heap in a basic Rails app is managed by the GC. 85% is just mallocs pic.twitter.com/sPbtAq4g8j
— Aaron Patterson (@tenderlove) June 28, 2017
Aaronの言う「managed by the GC」は、実際には「ObjectSpaceリストの内部で」のことです。
それでは「スレッド単位メモリアリーナ」の話題に移りましょう。
スレッド単位メモリアリーナはglibc 2.10(現在はarena.cにある)で導入された最適化であり、メモリアクセス時のスレッド間競合を軽減するよう設計されました。
アロケータの素朴な基本設計では、メインアリーナの1つのメモリチャンクを要求できるのは一度に1つのスレッドに限定されます。これによってメモリの同じチャンクを誤って2つのスレッドが取得することがないようにできます。そのような状況が発生すると、かなりやな感じのマルチスレッドバグの原因になります。しかしスレッドを多数持つプログラムではロックの奪い合いが多数発生して速度が低下することがあります。すべてのスレッドからのすべてのメモリアクセスはこのロックを必ず経由するので、ここがボトルネックになることがおわかりいただけるかと思います。
パフォーマンスへの影響が大きいため、アロケータの設計ではこのロック機構を撤廃するために多大な努力がなされました。ロックを行わないアロケータすらいくつか開発されたほどです。
スレッド単位メモリアリーナの実装は、次の処理におけるロックの奪い合いを軽減します(Siddhesh Poyarekarの記事を言い換えたものです)。
- あるスレッドで
mallocを呼び出します。このスレッドは、前回アクセスしたメモリアリーナ(他のアリーナが作成されていない場合はメインのアリーナ)のロック取得を試みます。 - そのアリーナを利用できない場合は、次のメモリアリーナのロック取得を試みます(メモリアリーナが他にもある場合)
- 利用できるアリーナがない場合は、アリーナを1つ作成してそれを使う。この新しいアリーナは、連結リストの最後のアリーナにリンクされる。
メインアリーナは基本的にこのような形でアリーナやヒープの連結リストで拡張されます。アリーナの個数はmallopt、特にM_ARENA_MAX(ドキュメントはこちらの「environment variables」セクション)で制限されます。デフォルトでは、作成可能なスレッド単位メモリアリーナの個数の上限は、利用可能なコア数の8倍までです。Ruby Webアプリの多くはコアあたりおよそ5スレッドを実行し、Sidekiqクラスタの場合はこれよりずっと多くのスレッドを実行します。Rubyアプリが作成する可能性のあるスレッド単位メモリアリーナの個数は、実際にはこれよりはるかに多くなるということを示します。
これがマルチスレッドRubyアプリにおいて正確にはどのような役割を果たすのかを見てみましょう。
- Sidekiqプロセスをデフォルトの25スレッドで実行しています。
- Sidekiqが新しい5つのジョブの実行を開始します。このジョブは、外部のクレジットカード処理システムとやりとりするためのものであり、HTTPSでPOSTリクエストを1つ送信し、3秒以内にレスポンスを1つ受け取ります。
- 各ジョブ(Rubyland内で個別のスレッドを実行しています)がHTTPリクエストを送信し、
IOモジュールを用いてレスポンスを待ちます。一般に、CRubyにおけるほぼすべてのIOはGVM(global VM lock)を解放します。つまり、これらのスレッドは並列(parallel)に動作しており、メインのメモリアリーナロックを奪い合う間柄なので、新しいメモリアリーナがいくつも作成されます。
CRubyでいくつものスレッドが実行されていて、かつI/Oを行っていない場合、2つのRubyスレッドが同時にRubyコードを実行しようとしてもGVMによって阻止されるため、メインのメモリアリーナを奪い合うことは不可能に近くなってしまいます。従って、スレッド単位メモリアリーナは、マルチスレッドかつI/Oを実行するCRubyアプリにしか効きません。
これがどのようにしてメモリ断片化につながるのでしょうか。
メモリ断片化は、本質的には(数学の)ビンパッキング問題(bin packing problem)です。変な形のピースをいくつもの容器(bin)に振り分けて、隙間を最小にするにはどうしたらよいでしょうか。次の理由から、ビンパッキング問題によってアロケータの難易度が非常に高まります。a)Rubyではメモリ上の場所を決して移動できない(場所をいったん割り当てると、オブジェクトやデータは解放されるまでそこにとどまる)。b)スレッド単位メモリアリーナは、本質的には容器を大量に作成しますが、これらを結合したりまとめたりすることができません。ビンパッキング問題は既にNP困難であり、この制約があるために最適解を得るのがさらに難しくなってしまいます。

ビンパッキングもきっと楽しい
時間とともにRSS(Resident Set Size)の値を巨大にするスレッド単位メモリアリーナは、glibc malloc trackerの既知の問題の一部です。実際、MallocInternals wikiには以下の指摘があります。
スレッド衝突の圧力が増加するとともに、圧力を逃がすために
mmap経由で追加アリーナが作成される。このアリーナの最大個数はシステムのCPU個数の8倍までに制限されている(ただし特に指定のない場合: 詳しくはmalloptを参照)ため、多数のスレッドがあるアプリでは引き続きある程度の競合が発生するが、トレードオフとして断片化は減少する。
ここがポイントです。利用可能なメモリアリーナの個数を減らすと、断片化を軽減できるのです。この方法には明確なトレードオフが存在します。アリーナを減らせばメモリ使用量を減らせますが、その代わりロックの競合が増加してプログラムの実行速度が落ちる可能性があります。
HerokuはCedar-14スタックを作成したときに、スレッド単位メモリアリーナにおけるこの副作用を発見しました。Cedar-14スタックでは、glibcのバージョンが2.19にアップグレードされています。
Herokuの顧客から報告された、アプリを新しいスタックにアップグレードするとアプリのメモリ使用量が増加する問題があります。これについてHerokuのTerrenceTerence HoneLeeがテストを行い、いくつか興味深い結果を得ています。
ちなみに本当の正解は Terence Lee
— Keiko Oda (@keiko713) December 29, 2017
| 設定 | メモリ使用量 |
|---|---|
| Base (unlimited arenas) | 1.73倍 |
| Base (before arenas introduced) | 1倍 |
| MALLOC_ARENA_MAX=1 | 0.86 |
| MALLOC_ARENA_MAX=2 | 0.87 |
基本的に、メモリアリーナのデフォルトの振る舞いはlibc 2.19で実行時間が10%削減されましたが、メモリ使用量は75%も増加したのです!メモリアリーナの最大数を2まで減らすと、スピードアップは得られない代わりに、旧Ceder-10スタックと比較して10%(デフォルトのメモリアリーナの振る舞いと比較すればほぼ2倍!)もメモリ使用量が削減されたのです。
| 設定 | レスポンス時間 |
|---|---|
| Base (unlimited arenas) | 0.9倍 |
| Base (before arenas introduced) | 1倍 |
| MALLOC_ARENA_MAX=1 | 1.15倍 |
| MALLOC_ARENA_MAX=2 | 1.03倍 |
ほとんどすべてのRubyアプリにとって、メモリ使用量を75%増やすのと引き換えに10%スピードアップするというのは、割に合わないトレードオフです。しかし、次にもう少し現実的な結果をご覧いただくことにします。
プログラムのレプリケーション
私はデモ用のアプリを作成しました。これはランダムなデータを生成してそのレスポンスをデータベースに書き込むSidekiqジョブです。
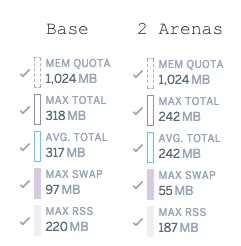
MALLOC_ARENA_MAXを2に変更すると、24時間後のメモリ使用量は15%低下しました。
ここで私は、この効果が現実の負荷によって大きく拡大されることに気づきました。つまり、この断片化の原因となるアロケーションパターンについて私もまだわかっていない点があるということです。拙著『Complete Guide to Rails Performance』のSlackチャンネルで、本番環境でMALLOC_ARENA_MAX=2を設定するとメモリ使用量を2〜3倍も節約できることを示すメモリのグラフをたくさん目にしました。
問題を修正する
この問題の主な解決方法は2つあります。3つ目は将来可能になるかもしれない解決方法です。
修正1: メモリアリーナを削減する
比較的わかりやすい方法として、利用可能なメモリアリーナの最大個数を減らす方法が考えられます。これはMALLOC_ARENA_MAX環境変数で変更できます。前述のとおり、この変更を行うとアロケータのロック競合が増加し、アプリ全体のパフォーマンスに悪影響を及ぼします。
本記事で一般的な設定を推奨するのは無理です。しかしほとんどのRubyアプリではアリーナ数2〜4が適切であるように思えます。MALLOC_ARENA_MAXを1にすると、パフォーマンスに深刻な悪影響が生じ、しかもメモリ使用量はほとんど改善されません(1%〜2%止まり)。(この方法を使うのであれば)これらの設定を実験し、自分のアプリに適したトレードオフの落とし所が見つかるまで、メモリ使用量低下とパフォーマンス低下の両方について結果を測定してください。
修正2: jemallocを使う
This is CodeTriage's Sidekiq worker memory use with and without jemalloc. I'm really starting to wonder how much of Ruby's memory problems are just caused by the allocator. pic.twitter.com/FD0fVbJCLt
— Nate Berkopec (@nateberkopec) December 1, 2017
もうひとつの解決方法として、単にアロケータを変更する手も考えられます。jemallocもスレッド単位アリーナを実装していますが、mallocで起きる断片化を回避する設計になっているようです。
上のツィートは、私がCodeTriageのバックグラウンドジョブプロセスからjemallocを削除したときのグラフです。ご覧のとおり、かなり劇的な効果を示しています。mallocでMALLOC_ARENA_MAX=2を指定した場合についても実験してみましたが、こちらのメモリ使用量はjemallocのほぼ4倍にとどまりました。Rubyでjemallocに変更可能なら、ぜひ変更しましょう。mallocよりずっと少ないメモリで、mallocと同等かそれ以上のパフォーマンスを得られるようです。
本記事はjemallocの記事ではありませんが、jemallocをRubyで使うときに押さえておきたい点を以下に示します。
- Herokuならこのbuildpackでjemallocを使えます。
jemalloc4.xはRubyで使ってはいけません。LinuxのTransparent Huge Pages(THP)との相性が悪く、表示されるメモリ節約量が目減りしてしまいます。使うならjemalloc3.6にしましょう。なお、5.0でRubyのパフォーマンスがどう変わるかは不明です。- Rubyを
jemalloc付きでコンパイルする必要はありません(一応可能ですが)。LD_PRELOADを使えば動的に読み込めます。
修正3: GCのコンパクション
一般的には、メモリ上の場所を移動できれば断片化を削減できます。CRubyでは、C拡張からRubyのメモリをじかに参照する生ポインタが使われる可能性があるため、この手が使えません。メモリ上の場所を移動すれば、segfaultするか読み出すデータがおかしくなる可能性があります。
Aaron Pattersonはここ最近、GCをコンパクションすべくがんばっています(以下の動画)。期待が持てますが、おそらく登場は先の話になるでしょう(訳注: その後Ruby 2.7でGCコンパクションが導入されました)。
まとめ
マルチスレッドRubyプログラムでは、mallocの「スレッド単位メモリアリーナ」で引き起こされる断片化が原因で、実際に必要なメモリ量の2〜4倍ものメモリを消費することがあります。これを修正するには、MALLOC_ARENA_MAX環境変数を設定して最大アリーナ数を減らすか、アロケータをjemallocなどに切り替えることでパフォーマンスを改善します。
これによって多くのメモリを節約でき、ペナルティも大きくありませんので、本番でRubyとPumaまたはSidekiqを使うときは常にjemallocを使うことをおすすめしたいと思います。
効果が最も著しいのはCRubyですが、JVMとJRubyでは問題が起きる可能性もあります。
概要
原著者の許諾を得て翻訳・公開いたします。
「スレッド単位メモリアリーナ」(per-thread memory arena)は定訳が見当たらないため仮訳を当てています。
楽しい画像はすべて英語記事からの引用です。