🔗 ChatGPTのしくみとAI理論の根源に迫る:(1/16)実は語を1個ずつ後ろに追加しているだけ(翻訳)
ChatGPTが、(表面的にはですが)まるで人間が書いたかのような自然な文章を自動生成できていることは、実に驚くべきことであり、従来の想像を超えています。しかし、ChatGPTはどうやってそんな凄いことを行っているのでしょうか?そして、なぜうまくいくのでしょうか?
本記事では、ChatGPTの内部で行われていることを大まかに説明し、ChatGPTが意味のある文章を生成できる理由を探ってみたいと思います。
最初に断っておきますが、本記事において私は、ChatGPTの中で「何が起こっているのか」という全体像を描くことに専念するようにしています。テクニカルな詳しい内容にも多少言及はしますが、深入りはしません(なお、本記事で私が述べる内容の本質的な部分は、ChatGPTのみならず、現時点における他のさまざまなLLM(Large Language Model: 大規模言語モデル)についても通用します)。
最初に説明しておくと、ChatGPTが基本的にやろうとしているのは、要するに、あるテキストの前半の「筋の通った続き(reasonable continuation)」を生み出す形でテキストの後半を埋めていく作業です。「筋の通った」というのは、「何十億ものWebページでいろんな人間が書いてきた膨大なテキストを調べた結果、多くの人間は普通なら続きをこう書くだろうと予想されるもの」という意味です1。
たとえば、「AIの最も優れた点は、〜する能力である(The best thing about AI is its ability to.)」という文章があるとします。これまで人間が書いてきた何十億ページもの文章(Webやデジタル化された書籍など)をスキャンして、この文章の前半部分のありとあらゆる事例を探索し、次にどんな語(word)がどんな割合で出現するかを観察するところを想像してみてください。
ChatGPTがやっているのは、テキストを厳密に一字一句そのまま探索するのではなく、「意味さえ一致すればよい」という(ある意味で少し高度な)探索を行っている点を除けば、実質的にはそれと変わらないのです。
しかし、最終的には以下のような、その前半部分の右で次に来る可能性のある語のランク付けリストが得られます。そしてそのリストには、さらに「確率(probability)」という味付けも加えられています。

驚くべきことに、ChatGPTが何らかの文章を生成するときにやっていることは、本質的に「テキストの前半がこうなっているなら、その続きにどんな語が来るのがふさわしいか」、つまり1語1語、「ここまでこう来たら、次はどう来るか」という問いを発しながら、次の語を追加している、たったそれだけの作業でしかないのです。
原注
厳密には、これから説明するように、追加するのは語ではなく、「トークン(token)」という、語よりも小さな単位なのですが、トークンが語の一部分となる場合もあるので2、トークンを使った場合でも「新しい語を作る」ことが可能になるのです。
しかし不思議なことに、この方法で確かにうまくいくのです。
「次にどんな語が来る可能性が高いか」というリストは、1語ずつ進むたびに変わります。しかし問題は、そうやって1語進むたびに手に入るリストの中から、どの語を選んで文の前半に追加すればよいか、です。
普通に考えれば、「ランクが最も高い語」(つまり確率が最も高い語)を毎回選ぶのが当然と思うかもしれません。しかし、まさにこの部分に、ちょっとした謎のオマジナイが入り込んでくるのです。
どういうわけか(そのうち科学的に解明されるかもしれませんが)、常にランクが最も高い語ばかりを選んで文章を生成すると、でき上がった文章がこれっぽっちも「創造性」を感じられない、極めて「平板な」、面白くも何ともないものになってしまうのです(ひどいときは同じ文や語をひたすら棒のように繰り返すことさえあります)。
しかし、時おりランクの低い語を(ランダムに)選ぶ戦略に変更すると、不思議なことに文章の「面白み」がぐんと増してくるのです。
ChatGPTの生成ステップという根幹部分にランダムネスが関わっているということは、たとえまったく同じものを入力しても、入力のたびに異なる文章が生成される可能性が高いということになります。そして、ChatGPTにある「温度(temperature)」というパラメータは、ランクが低い語をどのぐらいの頻度で使うかを決定するのに使われる、オマジナイ(=理由は分からないのになぜか効く手法)の一種です。
そして、まともな文章を生成するには、この「温度」を0.8に設定するのが最適であることがわかっています。
原注
ここでご注意いただきたいのは、この背後で何かすごい「理論」が使われているのではなく、「そうやると、どういうわけかうまくいく」程度のものに過ぎないということです。たとえば、ChatGPTで「温度」という概念が使われているのは、たまたま統計物理学でおなじみの指数分布が使われているからに過ぎず、「物理学的な」関連性はありません(少なくとも私たちが知る限りでは)。
原注
先に進む前にここでお断りしておきますが、私は、本記事での説明のためにChatGPTの完全版システムを使うつもりはほとんどありません。GPT-2は、(訳注: スペックは劣るものの)標準的なデスクトップコンピュータで実行できるほど規模が小さいという優れた特徴があります。
そのため,本記事の原文に掲載されている図版をクリックすると、皆さんのコンピュータでもすぐに実行して試せるWolfram言語コードが自動的にクリップボードにコピーされるようになっています。どうぞ原文記事を開いてお試しください。
たとえば、前述した確率の表は、以下のようにして手に入ります。
まず、基礎となる「言語モデル」のニューラルネットを取得する必要があります:

後ほどこのニューラルネットの内部を観察し、その仕組みについて詳しくお話しますが、とりあえず今は、この「ネットモデル」をブラックボックスと見なして、中身の振る舞いを考えずに先ほどのテキスト例に適用し、言語モデルが予測する「次にどんな語が来るか」という確率ランキングの上位5つを言語モデルに教えてもらえばよいのです。

以下は、その結果を書式の整った「データセット」にしたものです。
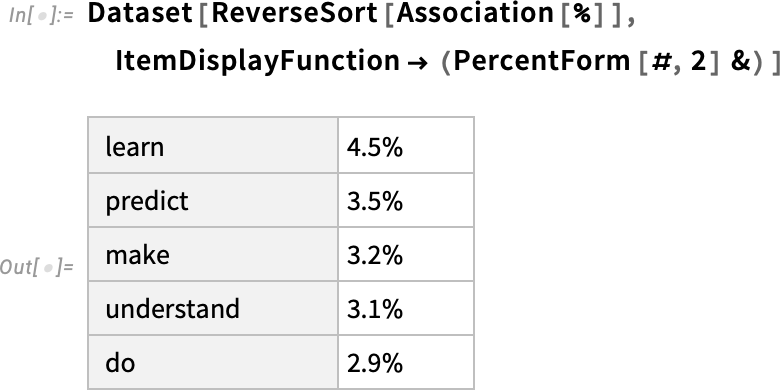
文の前半に対して、このような「モデルの適用」を1語ずつ繰り返し、その都度最も確率の高い語だけ(このコード内では、確率は「モデルだけで決定される」という前提です)を文に追加していくと、前半の文に対して以下のように1語ずつ追加されていきます。

この調子で続けると、文はどうなるでしょうか?
「温度ゼロ」すなわちランダムネスがゼロの場合、出力結果は以下のように同じお題目の繰り返しだらけになってしまい、意味不明です。
AIの最も良い点は、経験から学べる能力です。単に経験から学ぶだけではなく、あなたの身の回りの世界から学んでいるのです。AIはその非常に良い例です。AIを使って生活を改善する非常に良い例です。AIを使って生活を改善する非常に良い例です。AIを使って生活を改善する非常に良い例です。AIを使って生活を改善する...

しかし、1語進むたびに最も確率の高い「トップランキング」の語ばかりを選ぶのをやめて、代わりに適度に「トップでない語」もランダムに選ぶようにするとどうなるでしょうか?
この場合も、同じように文が後ろに伸びていきます(以下のランダムネスは、温度0.8に相当)。

すると、生成するたびに語の選択方法がランダムに変わるので、以下の5つの例文のように文の後半部分も生成をやり直すたびに違ってくることになります。

語を追加する最初のステップの時点でも、語の候補は1個ではなく、以下のグラフに示すように(learn、predictからcatchまで)たくさんあります(温度0.8の場合)。
しかし、このグラフでご注目いただきたいのは、グラフの左から右に進むに連れて、語の確率が急速に低下していることの方です。
原注
はい、以下は対数グラフになっているので、グラフ上では右肩下がりの直線に見えていても、実際には「べき乗」の逆数として右に進むほど急速に低下していることにご注意ください。言語に関連する統計は、このような対数グラフ的な特徴を示すことがよくあります。

では、この調子で文の後半に語を追加し続けていくと、どうなるでしょうか?
以下の例文はランダムさを加えたおかげで、先ほどの確率トップの語ばかり選んだ場合(つまり温度ゼロ)よりはマシな英文になりましたが、贔屓目に見ても、自然な英文としてはまだ少々違和感が残っています。
AIの最も良い点は、パニックになることも無視することもせずに、私たちの身の回りの世界を見通して腑に落ちるようにすることです。これはAIが「仕事をしている」またはAIが「いつも通りのことをしている」と知られています。実際、実行するステップ数を無限にしたり、他のシステムと統合可能なマシンを開発したり、本物のマシンであるひとつのシステムを制御したりすることは、AIの最も基本的なプロセスです。人間とマシンのやりとりを別にすると、AIは創造性の大きな位置をも占めていました。

原注
上の例文は、最もシンプルなGPT-2モデル(2019年製)で生成したものです。より新しくて大規模なGPT-3モデルで生成した例文は、上の例文よりずっと自然になります。
以下は、現時点で最大のGPT-3モデルに、GPT-2のときと同じ「プロンプト(prompt)」を指定して生成した、確率トップの語ばかり選んだ場合(つまり温度ゼロ)の例文です。
AIの最も良い点は、処理を自動化して決定を素早く精密に下せる能力です。AIは、データ入力といったありふれたタスクの自動化にも、顧客の振る舞いの予測や巨大データセットの分析といった複雑な決定を下すのにも使えます。AIカスタマーサービスの改善にも、顧客からの問い合わせに迅速かつ正確にお答えすることも可能です。AIは病気を正確に診断したり、新薬発見プロセスの自動化にも使えます。

そして以下は、GPT-3モデルで「温度0.8」を指定した、ランダムネスありの場合の生成文です。
AIの最も良い点は、時間とともに学習と発達を繰り返すことで、その能力を継続的に改善してタスクをさらに効率よくこなせるようになることです。AIはありふれたタスクを自動化することで人間がより重要なタスクに専念できるようにします。AIは、人間では気づくことが不可能な洞察を提供することで決定を下す助けにもなります。

お便り発掘
この記事をおすすめしました "ChatGPTのしくみとAI理論の根源に迫る:(1/16)実は語を1個ずつ後ろに追加しているだけ(翻訳)" via @techfeedapp #techfeed https://t.co/LWJ2PsAKuW
— にゃんだーすわん (@tadsan) July 23, 2025
概要
原文サイトのCreative Commons BY-NC-SA 4.0を継承する形で翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。原文が長大なので、章ごとに16分割して公開します。
スタイルについては、かっこ書きを注釈にする、図をblockquoteにするなどフォーマットを適宜改善し、文面に適宜強調も加えています。
元記事は、2023年2月の公開時点における、ChatGPTを題材とした生成AIの基本概念について解説したものです。実際の商用AIでは有害コンテンツのフィルタなどさまざまな制御も加えられているため、そうした商用の生成AIが確率をベースとしつつ、確率以外の制御も加わっていることを知っておいてください。
コモンズ証 - 表示 - 非営利 - 継承 4.0 国際 - Creative Commons