
- Logidze 1.2.0の要件
- PostgreSQL >=9.6
- Ruby ~> 2.5
- Rails >= 5.0(Rails 4.2では0.12.0以下を使うこと)
Rails: Logidze gemでActive Record背後のPostgreSQL DB更新をトラッキング(翻訳)
はじめに
Logidzeは、Active Recordの変更をトラッキングするRubyライブラリです。背後のPostgreSQLデータベースでレコードが更新されるたびにLogidzeが新旧ステートの差分を保存し、レコードの履歴で任意の時点にタイムトラベルできるようにします。Logidzeはこの5年間のRailsエコシステム内のモデル監査系gemとしては最速を誇り、このたびバージョン1.0になったことでさらに使いやすくなりました。
さて問題です。「ジョージア国のレモネード(#73)1」「Rails」「タイムトラベル」の共通点といえば何でしょうか?それがLogidze gemです。私が2016年に作ったこのライブラリは、最初のメジャーバージョンアップを迎えてめでたく大人の仲間入りを果たしました。本記事では、Logidzeの主要な機能を紹介するほか、Logidzeの完全な利用例として、弊社顧客向けの成熟した商用プロダクトで私たちが行った作業も紹介します。準備はよろしいですか?
Rails開発者にとってのLogidze導入は、gemをインストールしてジェネレータをいくつか実行し、以下のようにモデルに1行追加するだけで終わる、いたってシンプルな作業です。
class Post < ApplicationRecord
has_logidze
end
post = Post.find(id)
yesterday_post = post.at(time: 1.day.ago)
Logidzeは以下のたった2つのアイデアで構成されています。
- 変更のトラッキングにデータベーストリガーを利用: 混乱しがちでメンテの困難なActive Recordのコールバックも、速いとは言えないRubyやRailsのコードも使わず、高速かつ堅牢な昔ながらのPostgreSQLトリガーをシンプルに用いています。MySQLは「まだ」サポートされていませんが、ちゃんとしたプルリクがひとつ投げられれば可能です。
- changelogはレコードデータのすぐ隣に保存(PostgreSQLの
log_dataJSONBカラム)
このアプローチを PaperTrailやAuditedといったその他の著名な監査系gemと比較したときの速度については、私が2016年にLogidzeをリリースしたときの過去記事をご覧ください。
私はかれこれ5年ほどLogidzeの開発を続けてきましたが、最近になってやっと巨大なRailsコードベース内で正しくドッグフーディングする機会に恵まれ、おかげで荒削りな部分を見つけて削ぎ落とすことができました。変更点についてはこの先をぜひ読み進めてください。
目次
🔗 Logidze 1.0: 構成からスキーマまで
最新リリースの大きな変更点は、デフォルトのRails wayである「schema.rbへのデータベーススキーマ保存」のサポートです。従来のLogidzeはSQL形式のstructure.sqlスキーマでしか動きませんでした。プレーンSQL形式のスキーマファイルが必要になったことのない方や、プレーンSQL形式のスキーマファイルを見たことのない方は、2種類のスキーマ形式について余すことなく解説されているAppSignalの良記事『Pros and Cons of Using structure.sql in Your Ruby on Rails Application』をご覧ください
変更点の完全なリストについては1.0.0リリースノートをご覧ください。
これまで私は常々、schema.rbではなく structure.sqlを選ぶのは「必要悪」だと考えていました。たしかにSQLをマージしたときのコンフリクトを解決するのはつらい作業ですし、schema.rbの方がずっと簡潔なのですが、schema.rbでは「トリガー」「シーケンス」「ストアドプロシージャ」「チェック制約(Rails 6.1でのみ追加)」といったPostgreSQLの一部の機能がサポートされていません。トリガーがなければ、高速なモデルトラッキングもLogidzeも存在しようがありません(昔はそうだったのですが)。
私がF(x)という「本物のgem」を発見したことで、世界が変わりました。このライブラリはRails専用で、SQLの関数やトリガーを別ファイル(.sql)内で宣言できるようにし、それらをRubyマイグレーションおよびschema.rbに「読み込む」APIを提供します。素晴らしいと思いませんか?

なお、schema.rbをPostgreSQLのenum互換にできるactiverecord-postgres_enumや、同じくPostgreSQLのVIEW(データベースビュー)互換にできるScenicといったgemもあります。
そういうわけでLogidzeにF(x)を統合することを決め、その結果主要な問題を解決できました。Logidzeがschema.rbとstructure.sqlのどちらもカバーできるようになったのです!
既にプロジェクトでfx gemがインストールされていれば、LogidzeがF(x)を用いて関数やトリガーを自動生成してくれます。どうぞお試しください。
Logidze ❤️ F(x)
🔗 実際のActive Recordタイムトラベル
そろそろ業務に即した話に移りましょう。コードを書くのが好きだからというだけではなく、生きていくためにも。
問題点
この数か月、私と同僚でRetail Ziplineという小売業向けコミュニケーションプラットフォームの顧客向けの主要機能の強化や新機能の構築、全体のパフォーマンス向上、開発エクスペリエンス向上について同社のコア技術チームを支援してきました。
私の人生にLogidzeが再び舞い戻ってきたのは、同プラットフォームで重要な機能のひとつである「アンケート(survey)」機能でした。
簡潔にまとめると、アンケート機能では以下を行えます。
- 管理者は、さまざまな種類(単一回答、複数選択回答、yes/no、記述式など)のアンケートを作成する
- ユーザーは回答を送信する
- 管理者はレポートを生成して履歴データを分析する
アンケートのデータモデル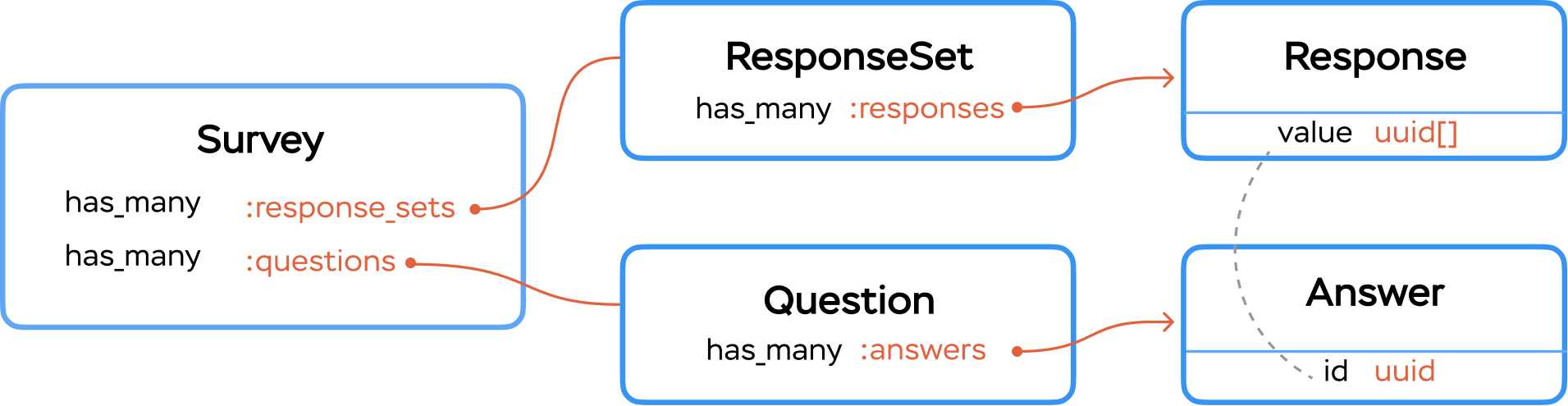
ユーザーが複数選択回答を送信すると、Responseのレコードを作成し、選択した回答のIDを含む#valueフィールド(背後のPostgreSQLはarray型)を設定します。後でこの回答を表示するには、以下のようなコードを使います。
# 近似的コード
module Surveys
class Response < ApplicationRecord
def display_value
# {answer.id => answer.value}形式のハッシュをビルド
id_to_val = question.answers.index_by(&:id).transform_values!(&:value)
# IDごとに値を抽出して文字列を形成する
value.map(&id_to_val).compact!.join(", ")
end
end
end
どこが問題かおわかりでしょうか?
ここで問題なのは「回答がイミュータブルではない」ことです。アンケート作者は回答の削除も変更も可能になっています。実際のユーザーは、古い回答を捨てて新しく作るよりも、作成済みの回答を完全に変更することを好みます。つまり「ID=1」「値="非常に重要"」という回答があるとすると、やがて値が"まったく重要でない"にすぐ変わってしまう可能性があります。これは問題です。
このため、履歴データがまったく信用できません。今表示されている回答の意味が当時も同じだったかどうかがわからなくなってしまいます。
私が今から何をしようとしているかは、もうおわかりですね。
ソリューション
私たちはこの問題解決のために、さまざまなアプローチを検討しました。
最も素朴で単刀直入な方法は「IDではなくナマの値を保存する」ことです。しかしこの方法はデータの整合性が損なわれるので、ほぼ一瞬で却下されました。もう少し手を加えた「IDと一緒にナマの値も保存する」方法もうまくいきませんでした。アンケートには多言語の訳文を持たせることができるので、回答をカレントユーザーのロケールで表示する必要がありました。この方法だとすべての訳文を保存する必要があり、ストレージのオーバーヘッドががかなり大きくなります。
さらに別の方法は「イミュータビリティ」を復活させることです。回答が更新されるたびに同じ#reference_idを持つレコードを作成し、古い方を論理削除する(レコードを削除せずにデータベース内で非表示にする)というものです。このアプローチでは、基本的にAnswerモデルをスナップショットベースで実装することになります。このソリューションの擬似コードは以下のような感じになります。
# app/models/surveys/answer.rb
module Surveys
class Answer < ApplicationRecord
#paranoia gemを利用した
acts_as_paranoid
before_create :assign_reference_id
after_create :discard_previous_version
private
def assign_reference_id
# 一意のid生成にはNanoid gemを使うのが個人的に好み
self.reference_id ||= Nanoid.generate(size: 6)
end
def discard_previous_version
self.class
.where(reference_id: reference_id)
.where.not(id: id)
.update_all(deleted_at: Time.current) # 削除フラグは付くがDBには残る!
end
end
end
# app/controllers/surveys/answers_controller.rb
module Surveys
class AnswersController < ApplicationController
# updateは古い回答を更新せず新規回答を作成すべき
def update
answer = Answer.find(params[:id])
# 重複には古いreference_idが含まれる
new_answer = answer.dup
new_answer.assign_attributes(answer_params)
new_answer.save!
redirect_to new_answer
end
end
end
これは完全にまっとうなソリューションですが、欠点もあります。Answerで変更されるのはテキスト値だけではなく、パラメータ集計などに用いるユーティリティフィールドもいくつかあり、実はこれらの方が頻繁に更新されます。テキスト値の更新とは対象的に、ユーティリティフィールドの更新はビジネスロジック上まったく問題ありません。これはつまり、モデル内で論理削除のためのチェックが増加し、同一の回答がコンカレントに更新されると競合する可能性があります(データベースロックで修正可能ですが)。これ以外にもエッジケースが潜んでいることは確かなので、より強固なバージョントラッキング手段が必要でした。
ここでLogidzeの登場です!以下は実装のサンプルコードです。
module Surveys
class Question < ApplicationRecord
has_many :answers
# 削除済みも含めてすべての回答をLogidzeデータと一緒に読み込む
# 特定の関連付けを追加する(デフォルトでは無視する)
has_many :answers_with_deleted, -> { with_deleted.with_log_data },
class_name: "Surveys::Answer",
inverse_of: :question
# ...
end
class Response < ApplicationRecord
# Adds .with_log_data scope
has_logidze
def display_value
# 論理削除された回答を扱うためにwith_deleted_answersスコープを追加した
# これで、必要な回答だけをHash#sliceで返せるようになる
# ActiveSupport:Enumerable#index_byについては以下を参照
# https://api.rubyonrails.org/classes/Enumerable.html#method-i-index_by
answers = question.with_deleted_answers.index_by(&:id).slice(*value).values
# 上によって、各回答で使われた全テキスト値を持つハッシュが
# IDでグループ化されていい感じに取れるようになる
answers.map do |answer|
# ログを追加する前にレスポンスが作成されたら現在のステートにフォールバック
answer = answer.at(time: created_at) || answer
answer.value
end.join(", ")
end
end
end
以上でおしまいです!これ以外の変更は一切不要です。コードにほんの数行を追加するだけでできます(もちろんLogidzeマイグレーションの実行もお忘れなく)。
なお、Logidze gemとApartment gem(データベースマルチテナンシー)を仲良くさせる作業も多少行い、その結果LogidzeドキュメントのTroubleshootingに新しいセクションを追加しました。
かくして、Logidzeを用いた実装はRetail Ziplineチームからゴーサインを頂戴し、めでたくproduction環境にリリースされました。
🔗 過去、現在、そして未来もまた
このgemを使い始めてから4年を経て、ようやくこのgemに依存したproduction向け機能をリリースできました。
自分で作ったgemをそれまで真面目に使わなかった理由ですか?AnyCableのときと異なり、Logidzeはオープンソースの実験として作ったものではなく、私自身が文字どおり「悪い火星人」になるためのテスト課題だったからです(私たちが自らを"evil"と呼ぶ意味がこれでおわかりでしょう🙂)
Logidzeは、主にバグレポートやフィーチャーリクエストによって進化を遂げてきました。バージョン1.0になったことで安定性を獲得し、隅々まで仕上がりました。Logidzeが独自の設計で完成したのです。
今後についてですか?
今回のリリース作業では、PostgreSQLに関連するコードやテストの改善にかなり力を入れました。Logidzeは実際には70%がPL/pgSQL、30%がRubyとRailsでできています。バージョン2.0への最初のステップは、Railsへの依存を完全に消し去る作業であることは明らかです(Ruby != Railsですよ)。
それが終われば、さらに「LogidzeをPostgreSQLライブラリ化する(extensionやヘルパーなど)」作業に進めるようになります。SQLをRubyから切り離すことに加えて、差分計算も以下のようにデータベースに移動してみたいと思います。
SELECT posts.*,
logidze_diff_from(
'2020-10-09 12:43:49.487157+00'::timestamp,
posts.log_data
) as logidze_diff
FROM posts
また、ログデータにクエリを書けるヘルパー関数もいくつか追加できます。よくあるユースケースのひとつとして、特定の時点に特定のフィールドに特定の値を持っていたレコードをすべて取得することが考えられます。
SELECT posts.*
FROM posts
WHERE logidze_log_exists(
posts.log_data,
'moderation_status',
'suspicious'
)
最近のPostgreSQLではバージョン12でSQL/JSON Path Languageが追加されました。これは単に以下のシンタックスシュガーです。
SELECT posts.*
FROM posts
WHERE jsonb_path_exists(
posts.log_data,
'$.h[*].c ? (@.moderation_status == "suspicious")'
)
責務をアプリケーションコードからデータベースに移動するなんて、まるで道路を逆走するような話に思えるかもしれませんが、そんなことはありません。私見では、製品の機能をデータベースレベルで実装するのはよくないと思いますが、ある種の数値計算やユーティリティーコードをデータベースに移動するのは間違いなくOKです👌。
ここまでお読みいただいた皆さんに感謝いたします。モデルトラッキングとPostgreSQLトリガーを(皆さんの責任のもとで)お楽しみください。本記事で解説したような課題に直面している方は、どうぞお気軽にEvil Martiansのフォームにてご相談ください。お客様の製品に私たちが力添えする方法を検討いたします。
概要
原著者の許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。また、元記事で同サイト別記事へのリンク切れを含む文は原著者の了解を得て削除しました。
なおLogidzeの最新バージョンは1.2.0です。