Rubyのメモリ管理方法2: Ruby 3.1の文字列の可変幅アロケーション(翻訳)
本記事は第1回の続編です。今回はRubyのメモリ管理における可変幅アロケーション(Variable Width Allocation: VWA)の仕組みと、可変幅アロケーションがRubyのメモリパフォーマンスをどのように改善するかについて深く見ていくことにします。可変幅アロケーションについて説明する前に、巨大オブジェクトがどのようにヒープに割り当てられるかを理解しましょう。
ヒープ上の巨大オブジェクト
ご存知の通り、スロットのサイズは40バイトで、その中で実際のコンテンツが格納されるのは24バイトのみです。残り16バイトは、フラグの保存や他のRVALUEへのポインタの保存に使われます。それでは、12バイトの文字列と37バイトの文字列をそれぞれアロケーションする必要のある例を見てみましょう。
12バイトの文字列は24バイトに収まるので、以下のように同一スロット内に文字列をまるごと格納できます。
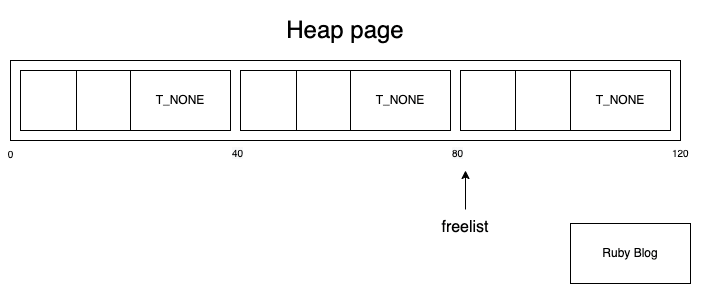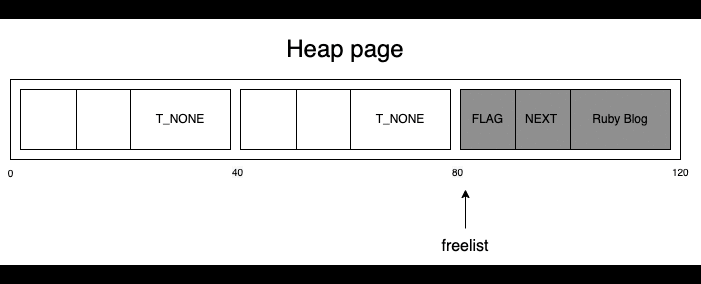
37バイトの文字列は24バイトに収まらないので、Rubyはmallocシステムコールを呼び出して、Rubyヒープの外でシステムヒープからメモリ領域を確保し、37バイトの文字列を格納します。
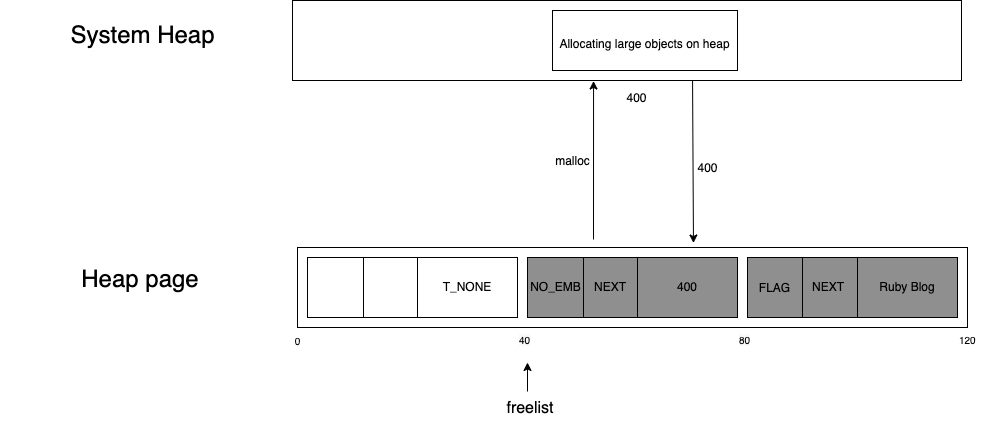
次に、システムヒープのアドレスをスロットに保存してフラグの値をNO_EMBEDに設定します。このフラグは、コンテンツがスロット内に埋め込まれておらず、代わりにコンテンツへのポインタを保存していることを表します。
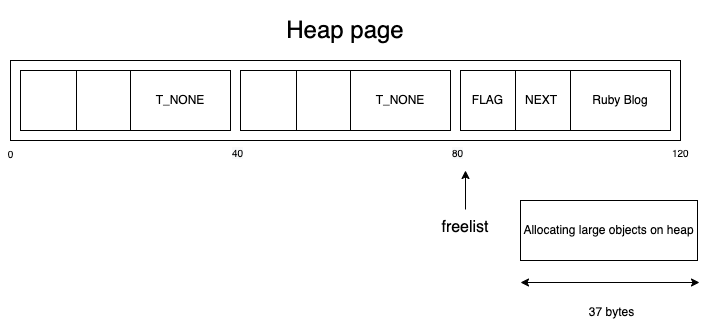
アロケーション後は以下のようになります。
Rubyヒープのボトルネック
- コンテンツをRubyヒープ以外の場所に保存すると、キャッシュの局所性が落ちる
- Rubyは巨大オブジェクトのアロケーション時に
mallocを呼び出すが、これはコストが極めて高く、パフォーマンス上のオーバーヘッドを生じる
これらを詳しく見ていくことにしましょう。
キャッシュ
キャッシュの局所性が落ちる原因について説明します。CPUにはL1、L2、L3という3つのレベルのキャッシュがあります。
- L1: CPUコア自身にあり、L2やL3よりも高速だが、サイズはわずか32KB程度と非常に小さい
- L2: L3よりも高速で、サイズは512KB程度
- L3: 3つの中で最も低速だが、サイズは32MB程度とずっと大きい
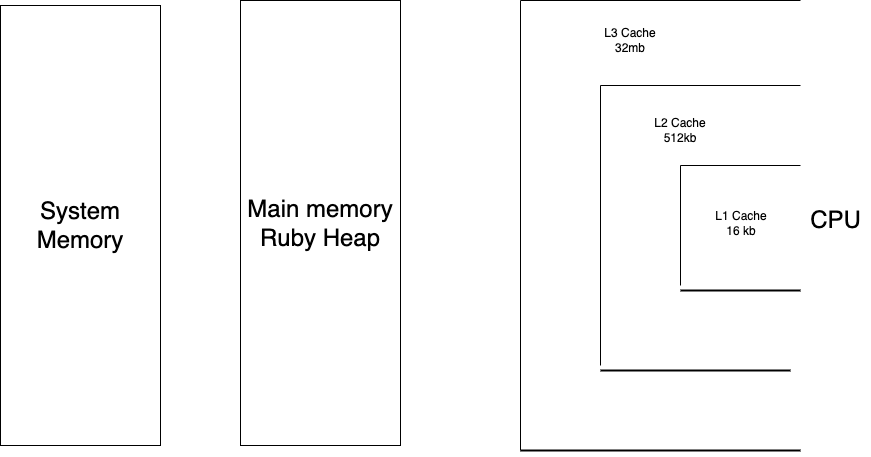
メインメモリからフェッチしたデータは、これらのキャッシュにも保存されます。つまり、上述の37バイト文字列の場合は、フェッチを2回行わなければならなくなります。つまり、コンテンツをフェッチするには、1回目はメインメモリからのフェッチ、2回目はメインメモリからシステムメモリへのフェッチが必要となります。この場合、フェッチするコンテンツのサイズは40バイト(RVALUE)+37バイト(コンテンツ)で計77バイトになります。
malloc
mallocによるシステムメモリの確保は、無料というわけにはいきません。必ずパフォーマンス上のオーバーヘッドを伴うため、mallocの呼び出し回数は最小限に抑える必要があります。mallocでメモリを確保するときには、メタデータ保存用のヘッダー領域も必要とするため、結果としてメモリ使用量が増加します。
そこで、上述のボトルネック解消のために導入されたのが可変幅アロケーション(VWA)です。
可変幅アロケーション
このプロジェクトの主な目的は、Ruby全体のパフォーマンス改善です。従って、コンテンツをRVALUEの直後に直接配置することでキャッシュの局所性を高めるとともに、ヒープ内で動的サイズのスロットをアロケーションすることで、高価なmallocシステムコールの呼び出しを回避できるようになります。
可変幅アロケーションの仕組みを説明します。
ご存知の通り、Rubyのヒープは複数のページに分割され、各ページはサイズが40バイト固定のスロットに分割されます。
可変幅アロケーションでは、40バイト固定でないサイズによって構成されるヒープページが導入され、、これに対応するためにサイズプール(Size Pool)と呼ばれる構造が導入されました。サイズプールは、特定サイズのスロットを持つヒープページのコレクションです。このスロットサイズは、RVALUEのサイズ * 2の累乗なので、サイズは40バイト,、80バイト、160バイト、320バイト...のようになります。
スロットサイズが異なるヒープページを持つサイズプールを以下に図示します。

ソースコードによれば、先ほどと同じ37バイト文字列(つまりRVALUE 40バイト+コンテンツ37バイト=77バイト)のアロケーションが必要になったとき、サイズプールのインデックスは以下の公式で計算されます。
slot_count = ceil ( total_size / sizeOf(R_VALUE) ) = ceil ( 77 / 40)
slot_count = 2
pool_index = ceil (log slot_count ) = ceil (log 2) = 1 // 対数の底は2
pool_indexが1になったことで、次にスロットサイズが80バイトのページのヒープを持つインデックス1のプールに進みます。つまり、80バイトのスロットで77バイトをアロケーションすると3バイトが使われずに余ることになります。しかしベンチマークによれば、、この余りはトータルのメモリ使用量やランタイムのパフォーマンスにほとんど影響しないことがベンチマークで示されています。
以上が可変幅アロケーションの仕組みです。
現時点の可変幅アロケーションの利用はClass型とString型に限定されています。アロケーション時にサイズが既知の文字列で、かつサイズが十分小さいものについては埋め込み文字列としてアロケーションされます。サイズが確定していない文字列やサイズが大きすぎる文字列については、従来の「40バイトのスロットをアロケーションしてmallocヒープにコンテンツを保存する」方式にフォールバックします。
さらに、スロットに埋め込まれた文字列が実行中に増加してスロットに入り切らなくなった場合は、文字列がmallocヒープに移動します。つまり、スロット内にある空きメモリの一部は無駄になるということです。たとえば、文字列が可変幅アロケーションによって当初160バイトのスロットにアロケーションされ、実行中にサイズが200バイトに増加したとすると、コンテンツはmallocヒープに移動し、40バイトは引き続き古いスロット内の160バイトに残されたままなので、古いスロット内の120バイトは無駄になります。
いくつかのベンチマークについては以下のissueに結果が掲載されています。ここでは可変幅アロケーションがRubyのメモリパフォーマンスを向上させる様子が示されています。
- issue: Feature #18045: Variable Width Allocation Phase II - Ruby master - Ruby Issue Tracking System
詳しくは以下のプルリクをどうぞ。
概要
原著者の許諾を得て翻訳・公開いたします。