RubyにマージされたZJITの概要を理解する(翻訳)
RubyKaigi 2025におけるMaximeのプレゼンテーションと、Matzさんによる承認(#21221)を経て、とうとうZJITがRubyにマージされました。バンザイ!
本記事では、開発のきわめて初期段階にあるこのプロジェクトの高レベルな概要をお伝えいたします。
ZJITは、Rubyのリファレンス実装であるYARVに組み込まれた、Rubyの新しいJIT(just-in-time)コンパイラであり、YJITと同じコンパイラグループによって開発されました。私たち(Maxime Chevalier-Boisvert、Takashi Kokubun、Alan Wu、Max Bernstein、Aiden Fox Ivey)は今年初めからZJITの開発に取り組んでいます。
ZJITは、以下のようにさまざまな点でYJITと異なっています。
- YARVバイトコードを低レベル中間表現(LIR)に直接コンパイルするのではなく、静的単一代入(SSA)ベースの高レベル中間表現(HIR)を利用する
-
一度に1つの基本ブロックをコンパイルするのではなく、一度に1つのメソッド全体をコンパイルする
-
型プロファイリングにlazy basic block versioning (LBBV)を使うのではなく、プロファイルされたインタプリタからの型情報履歴を読み取る
-
YARVをLIRに下げる形で最適化を行うのではなく、HIR上で動作する高レベルなモジュラーオプティマイザを備えている
YJITとの主な違いは、チームがあえて「伝統的な教科書のコンパイラ」に近づけることを意図しているという点です。これは、Rubyコミュニティが貢献しやすくするためです。
ここには興味深いトレードオフがいくつかあります。
YJITのアーキテクチャでは、プロシージャ間で型ベースの特殊化が行いやすかったのですが、ZJITのアーキテクチャでは、一度にオプティマイザに渡せるコード量を増やせます。
それではZJITのアーキテクチャについて説明しましょう。
🔗 ZJITの現在のアーキテクチャ
大まかな流れでは、ZJITはYARVバイトコードを受け取り、そこから中間表現(IR)をビルドし、いくつかの最適化を行ってから、最終的なマシンコードを出力します。簡略化すると以下の図のようになります。
図1: Rubyコードがコンパイラを通過する様子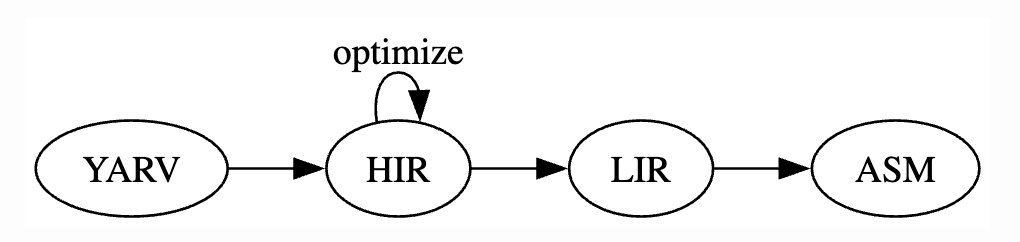
以下のRubyプログラムをサンプルとして使い、コンパイラのパイプラインに渡してみましょう。
# add.rb
def add(left, right)
left + right
end
p add(1, 2)
p add(3, 4)
最初にYARVの概要を押さえておきましょう。
🔗 YARV
Ruby VM(仮想マシン)は、次の2つの関数をYARVバイトコードにコンパイルします。
1つ目はトップレベル関数のISEQ(インストラクションシーケンス)ですが、簡潔にするため...で省略します。
2つ目はadd関数のISEQです。
ここでは多くの処理が行われていますが、重要なのは、YARVがローカル変数を使うスタックマシンであるという点です。ほとんどのインストラクションは、入力をスタックからポップして受け取り、結果をスタックにプッシュします。
たとえば、add関数のgetlocal_WC_0(オフセット: 0000と0002)インストラクションを見てみましょう。
- オフセット
0000のgetlocal_WC_0は、スロット0(第3カラム)メモリ領域にあるleftローカル変数を読み込んでスタックにプッシュする処理に特化しています。 - 同様に、オフセット
0002のgetlocal_WC_0は、スロット1メモリ領域にあるrightローカル変数について同じ処理を行います。 - 次にオフセット
0004で特殊な+ハンドラを呼び出します。このハンドラはスタックに積まれている2つの引数を読み取って、足し算の結果をスタックにプッシュします。
$ ruby --dump=insns add.rb
...
== disasm: #<ISeq:add@add.rb:2 (2,0)-(4,3)>
local table (size: 2, argc: 2 [opts: 0, rest: -1, post: 0, block: -1, kw: -1@-1, kwrest: -1])
[ 2] left@0<Arg>[ 1] right@1<Arg>
0000 getlocal_WC_0 left@0 ( 3)[LiCa]
0002 getlocal_WC_0 right@1
0004 opt_plus <calldata!mid:+, argc:1, ARGS_SIMPLE>[CcCr]
0006 leave
$
このopt_plusというオペコードは、汎用的なメソッドの探索と呼び出し操作を行います。ここには、VMのインストラクションハンドラにインライン化されたさまざまな高速パスもありますが、2つの小さな整数値(fixnum)を加算する一般的なケースを、汎用的なsendにフォールバックするコードも備わっています。
static VALUE
vm_opt_plus(VALUE recv, VALUE obj)
{
// fixnum + fixnum用の高速パス
if (FIXNUM_2_P(recv, obj) &&
BASIC_OP_UNREDEFINED_P(BOP_PLUS, INTEGER_REDEFINED_OP_FLAG)) {
return rb_fix_plus_fix(recv, obj);
}
// ... それ以外の場合(float + floatなど)
// ... Integer#+が再定義された場合のフォールバックコード
}
opt_plusの処理で重要なのは、引数の型をチェックするだけでは不十分だということです。このオペコードハンドラには、Integer#+が再定義されていないことを確認するための"bopチェック"1も含まれています(Integer#+が再定義されている場合は一般的な演算にフォールバックして、再定義された新しいメソッドがVMで呼び出されるようにしなければなりません)。
このバイトコード関数がインタプリタ内で一定の回数実行されると(この回数は設定で変更可能)、ZJITは一部のオペコードを、それらのプロファイルを考慮したバージョンに変更します(例: opt_plusがzjit_opt_plusに書き換えられる)。この変更バージョンでは、スタック上にあるオペコードの入力値を、ZJITが把握している特別な場所に記録します。
そこからバイトコード関数が一定の回数実行されると(この回数も設定で変更可能)、ZJITはバイトコード関数をコンパイルします。
次は、opt_plusが、コンパイラのパイプラインの最初の部分であるHIRでどのように変わるかを見てみましょう。なお、以後の手順を自分で実行してみるときは、Rubyをビルドするときに--enable-zjitを指定しておく必要があります(詳しくはZJITのドキュメントを参照)。
🔗 HIR(高レベル中間表現)
簡潔な形式にエンコードされたバイトコードでは、ジャンプ命令はオフセットを指定することであり、一部の制御フローは暗黙的に実行されるものもありますが、ほとんどのデータフローは明示的にスタックを介して行われます。
それと対照的に、HIRは、ノードとエッジを持つグラフに近いものになっています。ジャンプにはジャンプ先へのポインタがありますが、スタックは存在しません。データを使うインストラクションは、そのデータを作成するインストラクションを直接指すポインタを持ちます。
あらゆる関数には基本ブロックのリストがあり、あらゆる基本ブロックにはインストラクションのリストがあります。そしてあらゆるインストラクションは、IDを指定することでアドレッシング可能であり(IDを表すInsnIdはv12のような値になります)、型を持ち(InsnIdで決まる)、オペコードを持ちます(場合によってはオペランドをいくつか持つこともあります)。
私の言いたいことを伝えるために、バイトコードから直接構築したHIRのテキスト表現を以下に示しておきます(実行時に--zjitを指定してZJITを有効にしておくこと)。
$ ruby --zjit --zjit-dump-hir-init add.rb
HIR:
fn add:
bb0(v0:BasicObject, v1:BasicObject):
v4:BasicObject = SendWithoutBlock v0, :+, v1
Return v4
$
HIRのテキスト表現は一見するとバイトコードに似ているように思えるかもしれませんが、単に「どちらもテキストだからそう見える」に過ぎません。HIRのグラフ的な性質をより正確に表すと、以下の図のようになります。
図2: 矢印は、データを利用する側から、利用されるデータを指しています。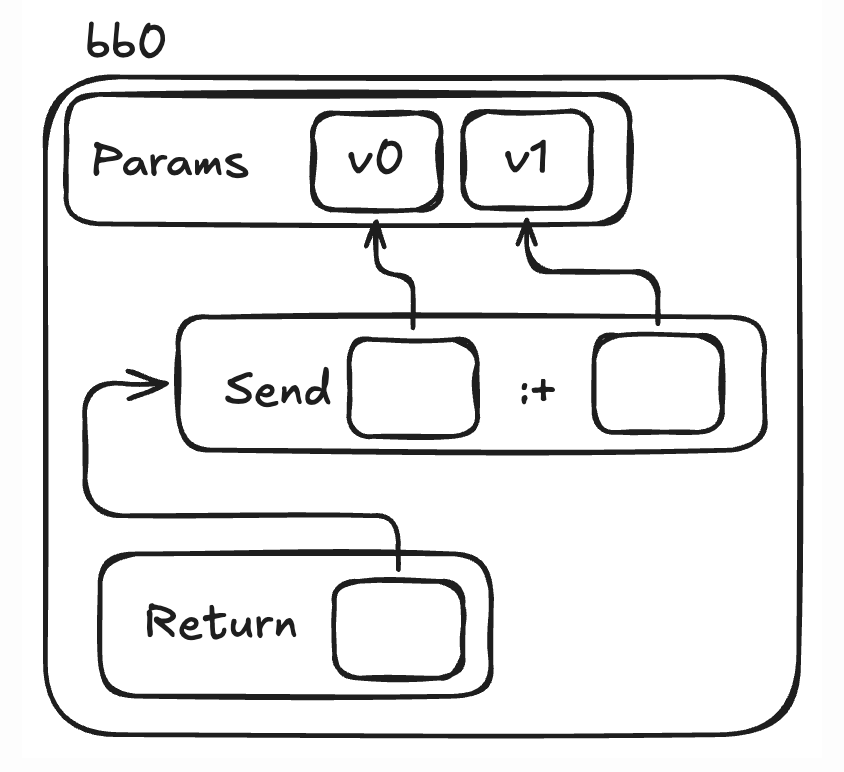
Sendは出力データを生成します。
この出力データは、それを生成したインストラクション名で参照されています。
これが、ReturnインストラクションがSendを指している理由です。
(ここでは、opt_plusインストラクションが再び:+への汎用的なメソッド呼び出しに変換されていることも分かります。これは(前述したように)、実際には多くのopt_何ちゃらインストラクション(opt_plusなど)が内部的にopt_send_without_blockとして扱われており、型に関する最適化はコンパイラパイプラインの後半で行われるためです)
このHIRの例を詳しく見てみましょう。
v4:BasicObject = SendWithoutBlock v0, :+, v1はインストラクションですv4は、インストラクションIDと出力データ名を兼用しています- 出力の型は
BasicObject(またはそのサブクラス)です - これは送信操作です(具体的には
opt_send_without_block) v0は自分自身です:+はメソッド名です- オペランドは
v0とv1です
次に、HIR は最適化パイプラインを通過します。
いくつかの最適化が行われると、HIRの外観は大きく変わります。型に依存しない汎用的な送信操作がなくなり、代わりに型に特化したコードに変換されています。
$ ruby --zjit --zjit-dump-hir add.rb
HIR:
fn add:
bb0(v0:BasicObject, v1:BasicObject):
PatchPoint BOPRedefined(INTEGER_REDEFINED_OP_FLAG, BOP_PLUS)
v7:Fixnum = GuardType v0, Fixnum
v8:Fixnum = GuardType v1, Fixnum
v9:Fixnum = FixnumAdd v7, v8
Return v9
$
オプティマイザが挿入したGuardTypeインストラクションは、オペランドがFixnum型かどうかを実行時にその都度チェックします。オペランドがFixnum型でない場合、生成されたコードはフォールバックとしてインタプリタにジャンプします。このようにして、Fixnum型に特化したコードであるFixnumAddだけを生成すれば済むようになります。
しかし、ここで話しているGuardTypeやFixnumAddは、まだかなり象徴的かつ高レベルです。そこで、次はコンパイラパイプラインのLIRを詳しく見てみましょう。
🔗 LIR(低レベル中間表現)
LIRはマルチプラットフォームなアセンブラとして設計されており、ここで提供されている高度な機能は、レジスタアロケータ(register allocator)だけです。
HIRをLIRに変換するときは、もっぱら高レベルな操作をアセンブリ言語風に変換することに注力しています。この作業を容易にするため、LIRの仮想レジスタを必要なだけいくつでもアロケーションしています。それをレジスタアロケータが、物理レジスタやスタック位置に対応付けているのです。
以下はadd関数のLIRです。
$ ruby --zjit --zjit-dump-lir add.rb
LIR:
fn add:
Assembler
000 Label() -> None
001 FrameSetup() -> None
002 LiveReg(A64Reg { num_bits: 64, reg_no: 0 }) -> Out64(0)
003 LiveReg(A64Reg { num_bits: 64, reg_no: 1 }) -> Out64(1)
# 1つ目のGuardType
004 Test(Out64(0), 1_u64) -> None
005 Jz() target=SideExit(FrameState { iseq: 0x1049ca480, insn_idx: 4, pc: 0x6000002b2520, stack: [InsnId(0), InsnId(1)], locals: [InsnId(0), InsnId(1)] }) -> None
# 2つ目のGuardType
006 Test(Out64(1), 1_u64) -> None
007 Jz() target=SideExit(FrameState { iseq: 0x1049ca480, insn_idx: 4, pc: 0x6000002b2520, stack: [InsnId(0), InsnId(1)], locals: [InsnId(0), InsnId(1)] }) -> None
# FixnumAdd: 値がFixnumを超える場合はSideExitする
008 Sub(Out64(0), 1_i64) -> Out64(2)
009 Add(Out64(2), Out64(1)) -> Out64(3)
010 Jo() target=SideExit(FrameState { iseq: 0x1049ca480, insn_idx: 4, pc: 0x6000002b2520, stack: [InsnId(0), InsnId(1)], locals: [InsnId(0), InsnId(1)] }) -> None
011 Add(A64Reg { num_bits: 64, reg_no: 19 }, 38_u64) -> Out64(4)
012 Mov(A64Reg { num_bits: 64, reg_no: 19 }, Out64(4)) -> None
013 Mov(Mem64[Reg(20) + 16], A64Reg { num_bits: 64, reg_no: 19 }) -> None
014 FrameTeardown() -> None
015 CRet(Out64(3)) -> None
$
上から、LIRで行われていることはHIRよりもずっと具体的であることがわかります。たとえば以下のような低レベルの詳細を確認できます。
FrameSetupやFrameTeardown(ネイティブのベースポインタ操作に対応)-
Test(1ビットのテスト用インストラクション) -
インタプリタに明示的にSideExitする条件ジャンプ(
JzやJoなど) -
単独の数値演算インストラクション(
SubやAddなど)
これ以外の関数におけるLIR出力では、高度なHIR構造がCランタイム(ヘルパー)関数呼び出しに変換されることもあります。
この例ではわかりにくいのですが、HIRとLIRのもう1つの大きな違いは、LIRは単一の大きな線形ブロックであることです。HIRと異なり、LIRには複数の基本ブロックというものが存在しません。
最後は、LIRの次であるアセンブリに進みましょう。
🔗 アセンブリ(ASM)
このアセンブリのリストはブログ記事には少々長すぎますが、GuardTypeやFixnumAddの有用性を示す興味深い部分をここで紹介いたします。
$ ruby --zjit --zjit-dump-disasm add.rb
...
# Insn: v7 GuardType v0, Fixnum
0x6376b7ad400f: test dil, 1
0x6376b7ad4013: je 0x6376b7ad4000
# Insn: v8 GuardType v1, Fixnum
0x6376b7ad4019: test sil, 1
0x6376b7ad401d: je 0x6376b7ad4005
# Insn: v9 FixnumAdd v7, v8
0x6376b7ad4023: sub rdi, 1
0x6376b7ad4027: add rdi, rsi
0x6376b7ad402a: jo 0x6376b7ad400a
...
$
GuardTypeとFixnumAddのどちらの場合も、いくつかの非常に高速なマシンインストラクションだけで済んでいる(訳注: 低速な汎用インストラクションを必要としない)ことがわかります。これこそが型特化(type specialization)の価値です!
このアセンブリスニペットに表示されているのはx86インストラクションですが、ZJITはARMバックエンドにも対応しています。生成されるコードはARMの場合もこれと非常に近いものになっています。
🔗 今後の計画とまとめ
ZJITプロジェクトはまだまだ始まったばかりです。ZJITのソースコードを読んでローカルで実験してみることをおすすめしていますが、私たちはまだZJITをproduction環境で動かしていません(皆さんもまだproduction環境では動かさないでください)。行く手には困難が待ち受けていますが、わくわくする道のりでもあります!
そういうわけで、当面の間YJITのメンテナンスも継続します。Ruby 3.5ではYJITとZJITを両方同梱してリリースします。それと並行して、ZJITがYJIT並の機能とパフォーマンスを発揮できるまで改良する予定です。
現在は、JITで現実のコードを実行可能にする機能をいくつか実装中です。手始めに、SideExitを実装しています。現在は、GuardTypeが想定外の型に遭遇した場合は処理を中止(abort)していますが、理想的にはインタプリタに実際にジャンプ可能にする予定です。
SideExitが使えるようになれば、以下の2つの興味深いことが実現可能になります。
- Rubyのテストスイートを実行することで、正しさの基準として使えるようになる
- yjit-benchなどのproductionレベルのアプリケーションを実行することで、パフォーマンスの基準として使えるようになる
その次はプロファイリングに取り組むとともに、どんな最適化が最も影響が大きいかを調べる予定です。
本記事をお読みいただきありがとうございます!近いうちに、ZJITのさらに詳しい情報やドキュメントを公開する予定です。
関連記事
-
これは、Rubyでは(ほぼ?)あらゆるメソッドを再定義可能であるためです。bop(basic operation: 基本演算)である
Integer#+などの組み込みメソッドも再定義されている可能性があります。YARV VMの開発者は、小さな数値の加算(fixnums)などの一般的な演算のショートカットを組み込むとともに、非常に動的な振る舞いへのフォールバックもサポートしたいと考えています。 ↩
概要
CC BY-NC-SA 4.0 International Deedに基づいて翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。