- Ruby / Rails関連
週刊Railsウォッチ(20200824前編)「Active Jobスタイルガイド」は有用、SiderがGitLabに対応、eager loading時のselectを修正ほか
こんにちは、hachi8833です。先週Gmailがコケてたみたいですね。
https://twitter.com/lukestateson/status/1296314411334983680
(今日は忙しかったのでGoogleが潰れていたのを知らなかった)
— Haruhiko Okumura (@h_okumura) August 20, 2020
- 各記事冒頭には⚓でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
- 「つっつきボイス」はRailsウォッチ公開前ドラフトを(鍋のように)社内有志でつっついたときの会話の再構成です👄
今週もエントリ数は抑え気味にしました。
⚓Rails: 先週の改修(Rails公式ニュースより)
以下のコミットリストのChangelogを中心に見繕いました。いつもより少ないところに夏を感じます。
- コミットリスト: Comparing master@{2020-08-15}...@{2020-08-20} · rails/rails
- 6.1.0マイルストーン: 6.1.0 Milestone -- 27件
⚓rails db:structure:{dump,load}をrails db:schema:{dump,load}に統合
RailsのA May of WTFにも書いたとおり。
このプルリクに実装したdeprecationの修正方法はよくわからない。
このプルリクの前は、config.active_record.schema_formatの値にかかわらずrails db:schema:{dump,load}はdump/load db/schema.rbを出力し、rails db:structure:{dump,load}はdump/load db/structure.sqlを出力していた)
このプルリクをマージすると、...:schema:と...structure:のどちらのコマンドもconfig.active_record.schema_formatに従って...:schema:...コマンドを実行するようになる。
なおdb:test:load_schemaは本当に必要なのか、あるいはdb:test:loadに組み入れられるだろうか。
同PRより大意
つっつきボイス:「config.active_record.schema_formatが効いてなかったようですね」「前からdb:structureとdb:schemaの2とおりがあったけど、やってることは同じだったので片方に統合したのか」
Railsガイドの更新を見るほうがわかりやすそうです↓。
# guides/source/active_record_multiple_databases.md#L139
$ bin/rails -T
rails db:create # Creates the database from DATABASE_URL or config/database.yml for the ...
rails db:create:animals # Create animals database for current environment
rails db:create:primary # Create primary database for current environment
rails db:drop # Drops the database from DATABASE_URL or config/database.yml for the cu...
rails db:drop:animals # Drop animals database for current environment
rails db:drop:primary # Drop primary database for current environment
rails db:migrate # Migrate the database (options: VERSION=x, VERBOSE=false, SCOPE=blog)
rails db:migrate:animals # Migrate animals database for current environment
rails db:migrate:primary # Migrate primary database for current environment
rails db:migrate:status # Display status of migrations
rails db:migrate:status:animals # Display status of migrations for animals database
rails db:migrate:status:primary # Display status of migrations for primary database
rails db:rollback # Rolls the schema back to the previous version (specify steps w/ STEP=n)
rails db:rollback:animals # Rollback animals database for current environment (specify steps w/ STEP=n)
rails db:rollback:primary # Rollback primary database for current environment (specify steps w/ STEP=n)
-rails db:schema:dump # Creates a db/schema.rb file that is portable against any DB supported ...
-rails db:schema:dump:animals # Creates a db/schema.rb file that is portable against any DB supported ...
+rails db:schema:dump # Creates a database schema file (either db/schema.rb or db/structure.sql ...
+rails db:schema:dump:animals # Creates a database schema file (either db/schema.rb or db/structure.sql ...
rails db:schema:dump:primary # Creates a db/schema.rb file that is portable against any DB supported ...
-rails db:schema:load # Loads a schema.rb file into the database
-rails db:schema:load:animals # Loads a schema.rb file into the animals database
-rails db:schema:load:primary # Loads a schema.rb file into the primary database
-rails db:structure:dump # Dumps the database structure to db/structure.sql. Specify another file ...
-rails db:structure:dump:animals # Dumps the animals database structure to sdb/structure.sql. Specify another ...
-rails db:structure:dump:primary # Dumps the primary database structure to db/structure.sql. Specify another ...
-rails db:structure:load # Recreates the databases from the structure.sql file
-rails db:structure:load:animals # Recreates the animals database from the structure.sql file
-rails db:structure:load:primary # Recreates the primary database from the structure.sql file
+rails db:schema:load # Loads a database schema file (either db/schema.rb or db/structure.sql ...
+rails db:schema:load:animals # Loads a database schema file (either db/schema.rb or db/structure.sql ...
+rails db:schema:load:primary # Loads a database schema file (either db/schema.rb or db/structure.sql ...
「統合されてとりあえずdeprecationになった段階だから、従来の書き方もしばらくは使えるということで」
⚓eager loadingでselectの値を無視しないよう修正
# Changelogより
post = Post.select("UPPER(title) AS title").first
post.title # => "WELCOME TO THE WEBLOG"
post.body # => ActiveModel::MissingAttributeError
# Rails 6.0 (ignore the `select` values)
post = Post.select("UPPER(title) AS title").eager_load(:comments).first
post.title # => "Welcome to the weblog"
post.body # => "Such a lovely day"
# Rails 6.1 (respect the `select` values)
post = Post.select("UPPER(title) AS title").eager_load(:comments).first
post.title # => "WELCOME TO THE WEBLOG"
post.body # => ActiveModel::MissingAttributeError
つっつきボイス:「あ〜、selectで絞り込んだあとで別テーブルをeager_loadすると、selectして更新したSELECT句が無効になってたのか」 「selectしなかったのと同じになっちゃってたんですね」「Post.eager_loadとほぼ同義というか」「これはたしかによくない」
関連: #35210
パフォーマンス上の理由で、使わないカラムの数をselectで減らすことがときどきある。
たとえばGET /posts/1(postの詳細)では(ほぼ)すべてのカラムを使うが、GET /posts(postのリスト)ではすべてのカラムを使うとは限らない(idとtitleはリストビューに使うがbodyは使わない場合など)。
ある関連付けがeager loadingされると、selectのカラム数削減が期待どおりに動かず、selectのカラム読み込みのほかにeager loadingでモデルの全カラムも読み込む。この動作は通常のロードやプリロードと異なる。つまり通常のロードやプリロードをeager loadingする(あるいはその逆)のは安全ではない。
このプルリクでは、「selectのカラムも読み込むほかに、eager loadingで常にモデルの全カラムも読み込む」という振る舞いを、他と同様にselectしたカラムを尊重するよう修正する。
同PRより大意
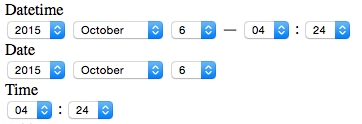
⚓datetime_select APIドキュメントのデフォルト値を修正
# actionview/lib/action_view/helpers/date_helper.rb#L
# * <tt>:date_separator</tt> - Specifies a string to separate the date fields. Default is "" (i.e. nothing).
- # * <tt>:time_separator</tt> - Specifies a string to separate the time fields. Default is "" (i.e. nothing).
- # * <tt>:datetime_separator</tt>- Specifies a string to separate the date and time fields. Default is "" (i.e. nothing).
+ # * <tt>:time_separator</tt> - Specifies a string to separate the time fields. Default is " : ".
+ # * <tt>:datetime_separator</tt>- Specifies a string to separate the date and time fields. Default is " — ".
つっつきボイス:「datetime_selectかぁ〜、あれで表示したセレクトボックスって使いにくいんですよね😆」「それそれ😆」「生成されるAPIドキュメントの記述が違ってたそうです↑」
# 正しい記述
datetime_separator: " — "
time_separator: " : "
date_separator: ""
参考: 4 日付時刻フォームヘルパーを使う -- Action View フォームヘルパー - Railsガイド
参考: datetime_select -- ActionView::Helpers::DateHelper
こんな感じで表示されますね↓(1つ目がdatetime_select)。
ruby on rails - Materialize plugin breaks date and datetime selectors - Stack Overflowより
⚓Linkヘッダーをスタイルシートやスクリプトごとに自動追加するようになった
Shopifyからのプルリクです。
つっつきボイス:「HTTPヘッダーの話みたい」「何か具体例が欲しいです...」「preloadのLink要素ってカンマ区切りで書けるんだ、あんまり自分で書いたことなかったから知らなかったけど」「この辺が差分っぽい↓」
# actionview/lib/action_view/helpers/asset_tag_helper.rb#L486
+ def send_preload_links_header(preload_links)
+ if respond_to?(:request) && request
+ request.send_early_hints("Link" => preload_links.join("\n"))
+ end
+
+ if respond_to?(:response) && response
+ response.headers["Link"] = [response.headers["Link"].presence, *preload_links].compact.join(",")
+ end
+ end
「リクエストの場合はrequestヘッダーに入れて返して、レスポンスの場合はresponseヘッダーに入れて返してる感じ」「MDN見ると、こういう感じにLinkヘッダーでリンクを複数返せるのね↓」「これ見てちょっとわかった気がしてきたかも」
# developer.mozilla.orgより
Link: <https://one.example.com>; rel="preconnect", <https://two.example.com>; rel="preconnect", <https://three.example.com>; rel="preconnect"
「テストコードもresponseヘッダーにリンクが付いたかどうかをチェックしてる↓」
# actionview/test/template/asset_tag_helper_test.rb#L513
+ def test_should_set_preload_links
+ stylesheet_link_tag("http://example.com/style.css")
+ javascript_include_tag("http://example.com/all.js")
+ expected = "<http://example.com/style.css>; rel=preload; as=style,<http://example.com/all.js>; rel=preload; as=script"
+ assert_equal expected, @response.headers["Link"]
+ end
preloadのelementは
LinkヘッダーでシリアライズしてHTMLのbodyがパースされる前にブラウザでプリロードできる。
これはドキュメント末尾に含まれるスクリプトでは特に便利。
実装:
この機能はEarly Hintsに乗っかっているが、原理的にはどちらも同じ機能なので、Early Hintsでは単にLinkヘッダーがどんなふうになりそうかを事前にブラウザに通知している。
シリアライゼーションにおいては、Linkヘッダーを複数送ることも、1つのヘッダーにカンマ区切りで複数の値を入れることもできる。後者は少々コンパクトになるので、自分は後者にした。
同PRより大意
⚓APIドキュメントのデフォルトインデックス名を修正
- PR: Fix generated default index names in API doc [ci skip] by mikong · Pull Request #40065 · rails/rails
つっつきボイス:「これはAPIドキュメントの自動生成の内容が違ってたということね」「実際のものに合わせたと」
# activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb#L
- # CREATE INDEX suppliers_name_index ON suppliers(name)
+ # CREATE INDEX index_suppliers_on_name ON suppliers(name)
...
- # CREATE INDEX IF NOT EXISTS suppliers_name_index ON suppliers(name)
+ # CREATE INDEX IF NOT EXISTS index_suppliers_on_name ON suppliers(name)
...
- # CREATE UNIQUE INDEX accounts_branch_id_party_id_index ON accounts(branch_id, party_id)
+ # CREATE UNIQUE INDEX index_accounts_on_branch_id_and_party_id ON accounts(branch_id, party_id)
...
- # add_index(:accounts, [:branch_id, :party_id, :surname], order: {branch_id: :desc, party_id: :asc})
+ # add_index(:accounts, [:branch_id, :party_id, :surname], name: 'by_branch_desc_party', order: {branch_id: :desc, party_id: :asc})
ActiveRecord::ConnectionAdapters::SchemaStatements#add_indexのAPIドキュメントで、生成されたSQL文のデフォルトインデックス名が正しくない例があった。
その他:
デフォルトのインデックス名は以下のフォーマットになっている。
index_<TABLE>_on_<COL1>_and_<COL2>
add_indexのAPIドキュメントには既にこれが反映されている。このプルリクは、フォーマットに準じてないSQL文が残っていたのを単に修正したのみ。なおデフォルトのインデックス名は以下の環境のRailsアプリで検証した。
Rails 6.0.3.2
Ruby 2.5.5
PostgreSQL 11.5例の中には、
add_indexでnameオプションを指定したことでデフォルトインデックス名のフォーマットがないものもある。とりわけ、このプルリクで修正した「ソート順でインデックスを作成する(昇順(デフォルト)または降順)」セクションの最後のSQL文では、インデックス名がby_branch_desc_partyとなっており、これはnameオプションが渡されたことを示しているが、Rubyコードを見てみるとnameオプションは渡されていない。
add_index(:accounts, [:branch_id, :party_id, :surname], order: {branch_id: :desc, party_id: :asc})
このSQL文を修正して、デフォルトインデックス名が
index_accounts_on_branch_id_and_party_id_and_surnameになるようにした。今回は行わなかったが、add_indexコードを更新してnameオプションにby_branch_desc_partyを渡す別修正も考えられる。その場合、SQL文で同じインデックス名が使われる。別修正の方がよければ知らせて欲しい。
同PRより大意
⚓Rails
⚓Active Jobスタイルガイド(Ruby Weeklyより)

つっつきボイス:「これってスタイルガイドなんですか?」「どちらかというとActive JobでSidekiqを使うときのノウハウ集といった趣かも」「Active Jobを使うときはこう書こうというスタイルガイドでいいと思います」

「Active JobではRails内部のGlobalIDを使うという話はたしかにある」「前に話題にしたGlobalIDですね(ウォッチ20181203)」
参考: 10 GlobalID -- Active Job の基礎 - Railsガイド
「1個のジョブキューに重いバッチと軽いバッチを混ぜて入れると、なるべくすぐ終わって欲しい軽いバッチが日次バッチみたいな重いヤツに止められてしまうの、あるある」
# 同記事より
# bad - no queue specified
class SomeJob < ApplicationJob
def perform
# ...
end
end
# bad - the wrong queue specified
class SomeJob < ApplicationJob
queue_as :hgh_prioriti # nonexistent queue specified
def perform
# ...
end
end
# good
class SomeJob < ApplicationJob
queue_as :high_priority
def perform
# ...
end
end
「ジョブは冪等かつリトライ可能に書く、みたいな定番のノウハウもあるし」
「ジョブの中にはなるべくビジネスロジックは書かないこと、ごもっとも」「せ、せやな😆」「現実にはビジネスロジックをジョブに書くのは割とありがちなんですけど、そうするとジョブの形でしか呼び出せなくなるから分けましょうと」
「ジョブからジョブを呼び出すかどうかの話、なるほど」「これはダメそうですけど、やりたくなるときってあるのかな...」「普通にあると思いますよ: たとえばメールのジョブでメール送信部分だけをマイクロなジョブにして、ちょうどここでやっているようにdeliver_laterするとか↓」「あ〜なるほどそういうことですか」
# 同記事より
# good - error kernel pattern
# bad - additional jobs are spawned
class SomeJob < ApplicationJob
def perform
SomeMailer.some_notification.deliver_later
OtherJob.perform_later
end
end
# good - no additional jobs
# bad - if `OtherJob` fails, `SomeMailer` will be re-executed on retry as well
class SomeJob < ApplicationJob
def perform
SomeMailer.some_notification.deliver_now
OtherJob.perform_now
end
end
「ジョブからジョブを呼ぶときはこれとこれを気をつけろとか書いてますね」「ジョブが発行したジョブのエラーをトラップするかどうかとか、ジョブが発行したジョブのエラーを追いかけたときになぜそのジョブが起動したのかが追いかけづらくなるとか、いろいろハマりどころがあるんですよ」「たしかに」
「ジョブからジョブ呼び出しは、やってはダメというよりは、やるなら気をつけろという感じだと思います」「ジョブはジョブ単位で管理できるようにしておかないと後で面倒なことになりますし」
「たくさんのジョブを1個にまとめる話↓」
# 同記事より
# acceptable
def perform
batch = Sidekiq::Batch.new
batch.description = 'Send weekly reminders'
batch.jobs do
User.find_each do |user|
WeeklyReminderJob.perform_later(user)
end
end
end
「Kernel.sleepは使うなとありますね」「ジョブの中でKernel.sleepを使うのは割とアンチなパターンです」「なるほど」「それをやると、ワーカーを握ったままsleepしたときに、ワーカー数を使い尽くした時点でジョブキューが詰まっちゃいます」「あ〜そういうことですか」
参考: Kernel.#sleep (Ruby 2.7.0 リファレンスマニュアル)
「APIの秒間呼び出し数がlimit exceededになったときとかの対応って割と面倒なんですよ: ジョブを登録し直すにしても大変なのでsleep書いちゃうこともありますけど」「あ〜わかります」「あと30秒待たないと再開できないとか」「それそれ」「そのときにジョブがワーカーを解放するように書く方がお行儀がいいのはたしかなんですけど、それも大変なので、痛し痒し感がある 」
「sleepを書くべきでないのはわかるんですけど、書かざるを得ないときってありますよね」「わかります、それ」「そのためにはジョブキューが詰まらないようにするのが大事で、さっきのジョブを分ける話ともつながってくるところもあると思います」
「他にもone process per coreとか、Redisのメモリあふれに気をつけようとか、いろいろわかりみがある」
「ジョブの引数を増やしすぎるなとありますね」「う、今の案件でこれやっちゃってたかも...😅」「😆」「Active Jobのジョブに渡した引数って、たしかActive Job内の変数として持ってたような覚えがあるんですけど、そういうのもあって引数をいっぱい渡すのはあんまりよくないですね」「なるほど」
「以下みたいなuser_statusとかuser_infoみたいな引数↓って、ジョブを投入したときとジョブが実行されるときで状態が変わる可能性があるんですよ」「あ〜そうか!」
# 同記事より
# bad
SomeJob.perform_later(user_name, user_status, user_url, user_info: huge_json)
# good
SomeJob.perform_later(user, user_url)
「こういう情報は引数で渡すよりも実行時にチェックする方がより安全でしょうね」「ジョブ単体の中で取れる情報はジョブで取った方がいいと」「ジョブ投入時のスレッドとジョブ実行時のスレッドで状態を共有しようと思ったら1回シリアライズしないといけないですし、そういうところは注意が必要ですね」「よし、後で直そう😆」「😆」
「これはこの間も話題になったジャストの時刻にバッチを起動するのを避けるヤツ」「開始時刻を少しずつ前後にずらしたりできるという話もありましたね」
「Sidekiqの有料機能を使うとこんなことができるという話」「APIアクセス頻度を制限する機能なんてのもあるんですね」「あると便利な機能😋」
参考: Ent Rate Limiting · mperham/sidekiq Wiki
「Active Jobはジョブエンジンを限定しないつくりなんですけど、それがゆえにキューを細かく管理する機能があまりないので、こんなふうにSidekiqの高度な機能を使えるといいですよね: まあそうするしかないとも言えますけど」
「こういうスタイルガイドあると助かるかも😋」「なかなかいいドキュメント👍」「Creative CommonsのBYなので翻訳できそう」
⚓SiderがGitLabに対応開始
つっつきボイス:「今日出たニュースです」「何と、SiderがついにGitLab対応ですか!」「そうなんですよ、以前自動レビューツールのときにSiderも取り上げましたね(ウォッチ20190304)」「BPSはGitLabがメインなので、GitLabで使えて欲しいですよね」
sider.reviewより

「以前問い合わせたときはGitLab対応の予定がないとのことだったので使わなかったけど、やっとか〜」「ちょっとお高いかな💵」「10ユーザー単位か、う〜む」「自動レビューはあるとありがたいんですけどね」
以下は昨年のツイートです。
“株式会社ビットジャーニー - Querlyは「8割くらい修正しない」程度のバランスでいい。” https://t.co/55GQ6GleIS
— 個人未開発さん (@kimihito_) December 5, 2019
⚓後置のif
後置ifは「用量・用法を守って正しくお使いください」な機能なので、「Rubocopに怒られたから」という理由で機械的に変更するとダメな気がします。むしろRubocopの設定を変えたいところ。
【Ruby】乱用厳禁!?後置ifで書くとかえって読みづらくなるケース https://t.co/egu0XOH7Q8 #Qiita
— Junichi Ito (伊藤淳一) (@jnchito) August 19, 2020
つっつきボイス:「後置のifってたしかに横に長くなるとわかりにくくなる傾向はありますよね」「個人的には三項演算子より後置ifの方が割と好きですけど」「自分もそんなにキライじゃないかな〜」「最終的には人間が読んだときに読みやすいかどうかですし」
「デフォルトのRuboCopは一行で書けるときは後置のif推奨なのね」
参考: Style/GuardClause -- Style :: RuboCop Docs
つっつき後にふと思い出したのですが、以前、例のGoby言語に後置のifがない理由を@st0012さんに尋ねたところ、以下のようなよくない書き方ができてしまうから入れなかったとのことでした。
foo do
# すごく長い処理
end if bar?
⚓その他Rails
つっつきボイス:「AppSignalの記事なんですけど、割と基本的な内容かなと」「『まずRubyをきちんと学んでからRailsをやろう』、ごもっとも」
「一般によく言われているノウハウや注意点をまとめた感じの記事ですね: あとは、こういう記事を読んで欲しい人に読んでもらったときにどこまでわかってもらえるかでしょうね」「いろんな罠が説明されてますけど、読んだ人が罠を踏まなくなるかどうかはまた別というか」
「ところで記事の見出しにbread & butterってあるんですけど、ここでは『メシのタネ』みたいなニュアンスですね」「朝食メニューじゃないのか🌭」
前編は以上です。
バックナンバー(2020年度第3四半期)
週刊Railsウォッチ(20200818後編)ruby_jardデバッガがスゴい、RubyオンラインマニュアルにEdit機能が追加、Ruby 2.7のBundlerを消す方法ほか
- 20200817前編 お盆も続くRails改修、Rails 6.1にManyモナドが入る?rails-auth gemでクライアント認証ほか
- 20200811山の日短縮版 RSpec Queueでパラレルテスト、カロリーメイトとRubyのコラボ、Rubyのcoercionほか
- 20200804後編 「RubyKaigi Takeout 2020」9月オンライン開催、メールバリデータtruemail、Gitのmasterが変更可能にほか
- 20200803前編 書籍『パーフェクトRuby on Rails』増補改訂版、マルチDBで抽象クラスをscaffold生成、GitLabがPumaに乗り換えほか
- 20200721後編 『パーフェクトRuby on Rails』増補改訂版発売間近、scan_left gemでレイジーなinjectほか
- 20200720前編 10月開催「Kaigi on Rails」CFP募集中、enumにデフォルト値設定機能、RailsでBitemporal Data Modelほか
- 20200714後編 ruby-warning gemでワーニングを手軽に抑制、rubocop -aの振る舞いが変わる、書籍『MySQL徹底入門 第4版』ほか
- 20200713前編 rspec-openapiでスキーマ自動生成、Rails Architect Conf動画、
where()ハッシュキーに比較演算子条件を書ける機能ほか - 20200707後編 Rubyで無名structリテラル提案、書籍『AWS認定ソリューションアーキテクト』、21世紀のC言語ほか
- 20200706前編 Railsでのマルチテナンシー実装戦略を比較、Railsでサブクエリを使う、URI.parserが非推奨化ほか
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやはてブやRSSやruby-jp SlackやRedditなど)です。
