- Ruby / Rails関連
週刊Railsウォッチ(20200706前編)Railsでのマルチテナンシー実装戦略を比較、Railsでサブクエリを使う、URI.parserが非推奨化ほか
こんにちは、hachi8833です。RubyKaigiのチケット代返金処理が始まったそうです。
We've just submitted the refunds of all registrations to our payment provider. We plan to cancel all registrations from our end once we become sure the refunds are completed successfully. We thank you for patience. #rubykaigi
— RubyKaigi (@rubykaigi) July 1, 2020
つっつきボイス:「RubyKaigiチケット代返金は参加者向けのお知らせということでしょうね」「チケットの返金始まったんですね!こないだDoorkeeperから届いたメールにRubyKaigiにようこそみたいなことが書いてあってもう返金無理かと思ってましたけど」「あ、紛らわしいメールが飛んで失礼しましたというのが2通目のツイートです↓」「なるほど😆」「完全に理解しました😆」
We're aware that you may have received a welcome email from our ticketing provider, Doorkeeper. Perhaps it was sent because we left your tickets active while it has been refunded. Please disregard, and again, we plan to cancel all tickets soon. Sorry for confusion. #rubykaigi
— RubyKaigi (@rubykaigi) July 1, 2020
- 各記事冒頭には⚓でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
- 「つっつきボイス」はRailsウォッチ公開前ドラフトを(鍋のように)社内有志でつっついたときの会話の再構成です👄
⚓Rails: 先週の改修(Rails公式ニュースより)
以下のコミットリストのChangelogを中心に見繕いました。先週のコミット数は珍しく少なめですね。
⚓URI.parserが非推奨化
今後はRubyのURI::DEFAULT_PARSERを使うようにとのことです。よく見るとShopifyのプルリクでした。
# actionview/lib/action_view/helpers/url_helper.rb#L542
def current_page?(options, check_parameters: false)
unless request
raise "You cannot use helpers that need to determine the current " \
"page unless your view context provides a Request object " \
"in a #request method"
end
return false unless request.get? || request.head?
check_parameters ||= options.is_a?(Hash) && options.delete(:check_parameters)
- url_string = URI.parser.unescape(url_for(options)).force_encoding(Encoding::BINARY)
+ url_string = URI::DEFAULT_PARSER.unescape(url_for(options)).force_encoding(Encoding::BINARY)
# We ignore any extra parameters in the request_uri if the
# submitted URL doesn't have any either. This lets the function
# work with things like ?order=asc
# the behaviour can be disabled with check_parameters: true
request_uri = url_string.index("?") || check_parameters ? request.fullpath : request.path
- request_uri = URI.parser.unescape(request_uri).force_encoding(Encoding::BINARY)
+ request_uri = URI::DEFAULT_PARSER.unescape(request_uri).force_encoding(Encoding::BINARY)
if url_string.start_with?("/") && url_string != "/"
url_string.chomp!("/")
request_uri.chomp!("/")
end
if %r{^\w+://}.match?(url_string)
url_string == "#{request.protocol}#{request.host_with_port}#{request_uri}"
else
url_string == request_uri
end
end
つっつきボイス:「URI.parserが非推奨化?」「やべ、最近どっかで使っちゃったかも😅」「非推奨になったURI.parserはRailsのActive Supportの機能で、URI::DEFAULT_PARSERはRuby自身の機能だそうです」「なるほど〜」
これまでRegexpの重複を調べてきて、
URI::Parserにはものすごい量の重複があることに気がついた。もう少し追ってみたところ、Active Supportが不要な場合であっても第2のパーサーをインスタンス化していたのが原因だった。
DEFAULT_PARSERは12年も前に追加されていたこともわかった。
URI.parserの有用性にも疑問があるが、Railsで使われている場所はほんのひと握りなので、完全に削除できるだろう。ドキュメントはないが:nodoc:も付いてないので、これがpublic APIかどうかはわからない。
@rafaelfranca
同PRより大意
- Rails API:
URI.parser - Ruby API: class
URI::Generic(Ruby 2.7.0 リファレンスマニュアル)
「オリジナルのURI.parserは使ったことないので、使いたいニーズがどのぐらいあるのかはわかりませんけど」「上のコミットメッセージには、ほぼないだろうとありますね」「とは言えゼロではないでしょうから非推奨化して消さないとですね」「ワイ、こないだ書いたコードを見直さないと...使ってなかったよかった〜😂」「😆」
「プルリクコメントにこんなの書いてありました↓」「なるほど、Ruby 1.8と1.9の頃の話だったのね」
URI.parserは、URI::ParserがまだなかったRuby 1.8とRuby 1.9との間の互換性のためにに導入されたらしい。URI.unescapeは既に5d773f8, 2f326b7, 197a995で非推奨化されている。URI.parserの非推奨化に一票。
URI.parserの振る舞いに関するドキュメントはないが、APIドキュメントには載っているのでpublic APIということになる。
同PRコメントより
⚓Ruby 1.8の頃
「まあ1.8を知るエンジニアも随分減ったかもしれませんけど」「どんな時代...?」「ほら、ハッシュの順序が維持されてなかった時代ですよ↓」「1.8やってました〜」「Ruby Enterprise Editionとかあった時代」「REEってありましたね」「2.0になってレビューで古い書き方にツッコまれまくったのを覚えてます」
参考: 要素の追加順序を保持するHashクラス (#1273692) | Ruby 1.9.0 リリース | スラド
Re: (スコア:0) by Anonymous Coward Hashが順序を保持。についてもう少し知りたい。キーの順序を保持?連想配列の実装が二分木になったとか、そういう話ですか?
Re: (スコア:0) by Anonymous Coward キーが常時ソートされた状態で保持されるという意味ではなく、each(など)で列挙すると追加した順序で出てくるという意味です。
srad.jpより
参考: Ruby Enterpriseエディションが終わる。Phusionは、Passengerに注力。 -- 2012年の記事です
⚓可能な場合はLoadError#original_messageを使うようになった
こちらもShopifyのプルリクです。
LoadError#messageはRuby 2.8/3.0でDidYouMeanによって拡張されていて、$LOAD_PATHにあるものをかなりいい感じに使って訂正サジェスチョンを表示してくれる。
このおかげで、特に$LOAD_PATHの量が多い場合にメッセージへのアクセスがかなり拡張可能になる。
NameError#messageでは既に同じ問題を扱っているので、それと同じアプローチを取ることにした。
同PRより大意
つっつきボイス:「DidYouMeanをsafe_constantizeでも効かせるようにしたということですね」
# activesupport/lib/active_support/inflector/methods.rb#L329
def safe_constantize(camel_cased_word)
constantize(camel_cased_word)
rescue NameError => e
raise if e.name && !(camel_cased_word.to_s.split("::").include?(e.name.to_s) ||
e.name.to_s == camel_cased_word.to_s)
rescue ArgumentError => e
raise unless /not missing constant #{const_regexp(camel_cased_word)}!$/.match?(e.message)
rescue LoadError => e
- raise unless /Unable to autoload constant #{const_regexp(camel_cased_word)}/.match?(e.message)
+ message = e.respond_to?(:original_message) ? e.original_message : e.message
+ raise unless /Unable to autoload constant #{const_regexp(camel_cased_word)}/.match?(message)
end
「DidYouMeanって何でしたっけ?」「ほら、『本当はこれじゃないの?』みたいなエラーメッセージですよ」「『それはタイポでは?』的なヤツ」「あ〜あれですか!何気に助かるんですよね」「『どうしてわかった?』みたいに図星だったりしますよね」「いや〜今回もどれだけ助けられたことか😂」「Rubyに後ろから見られてるような気持ちになります😆」
「Rubyはこういうところがプログラマーに優しいですよね」「いちいちAPIドキュメントをひっくり返したりしなくてもわかりますし」「そういう部分がMatzが言うところの『楽しくプログラミングできる』というヤツなのかなと思いますね」「jnchitoさんが『Rubyの書き味』を引用してたのもそのあたりかも」「他の言語だとスタックトレース追ったりしないといけなくなったりしますし」「DidYouMeanでツッコまれたら取りあえず言われたとおりに変えて試すという投機的実行ができるのはいいですよね」
後で掘り起こしました↓。
ほんまそれ。> 書き味
「プログラミングをしているとき、簡潔で楽しいという感覚がRubyにはあると言われるんです。僕はその感覚を「書き味」と言っているんですが、それじゃないかと思います。その「書き味」は言い換えると、書いているときにストレスが少ないとも言えます」https://t.co/CAUs1yPi8e
— Junichi Ito (伊藤淳一) (@jnchito) May 8, 2020
⚓Marshal.load(legacy_record.dump)がMySQLで動くための後方互換性
実際にはMarshalの互換性をRailsバージョン間で維持すると明言したことは一度もないので、これまでもそれ用の型を直接削除したことがある(f1a0fa9や#29666など)が、直接削除するとキャッシュのローテーションが難しくなる。
未使用の定数を新しいバージョンで維持すれば、少なくとも1つのバージョンが続く間はキャッシュのローテーションはやりやすくなる。
同PRより大意
つっつきボイス:「なるほど、Railsのリリースバージョン間でのMarshal.loadを問題にしているということか!」「RubyのMarshalはバージョン間での互換性は保たれないものですけど、Railsでのバージョン間互換性と言われるとたしかにと思いますね」「キャッシュローテーションはたしかにMarshalでやる方が軽そう🎈」
# activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb#L847
+ # MysqlStringエイリアスでMashal.load(File.read("legacy_record.dump"))が効くようにする
+ # TODO: Rails 6.1がリリースされたらこの定数エイリアスを削除する
+ MysqlString = Type::String # :nodoc:
+
- Ruby API: module
Marshal(Ruby 2.7.0 リファレンスマニュアル)
「まあ自分はそもそもMarshalの互換性は当てにしませんけどね: 一般にバージョンが変わってもロードを維持しないといけないものならMarshalではなくJSONとかを使うべきだと思いますし」「たしかに」「MarshalはRubyのバージョンが変われば互換性が失われるものだから、そういうのを永続化的に使いたくはないですね」
⚓番外: tags_textのキャッシュ化を取り消し
- commit: Revert "Cache tags_text to avoid computing tags each time when logging" · rails/rails@c3913e5
つっつきボイス:「このタグはログで使うヤツみたいですね」「元のコミット↓ではメモ化||=でキャッシュしてたのを、その後のコミットで取り消したのね」
# activesupport/lib/active_support/tagged_logging.rb#L56
def tags_text
- tags = current_tags
- if tags.one?
- "[#{tags[0]}] "
- elsif tags.any?
- tags.collect { |tag| "[#{tag}] " }.join
+ @tags_text ||= begin
+ tags = current_tags
+ if tags.one?
+ "[#{tags[0]}] "
+ elsif tags.any?
+ tags.collect { |tag| "[#{tag}] " }.join
+ end
end
end
このコミットは05060ddを取り消す。
タグはファイバーごとにあるので、インスタンス変数内ではキャッシュされない。
同コミットより大意
⚓Rails
⚓提案: ハッシュ記法のショートハンド(Ruby on Rails Discussionsより)
以下のように最近のJavaScript的に書きたいという提案です。肯定否定さまざまな意見が出ています。
{topics, users, very_longly_named_objects}
# ↓
{
topics: topics,
users: users,
very_longly_named_objects: very_longly_named_objects,
even_more_very_longly_named_objects: even_more_very_longly_named_objects,
}
つっつきボイス:「このスレが割と盛り上がってるので」「あ〜、JS風のこの書き方が欲しいというのワカル!」「ローカル変数名とキー名を一致するように書くことはよくあるので、だったらこう書けるといいよねと」「特にeven_more_very_longly_named_objectsみたいに長大になるとエディタで改行して見づらくなりますし」「そうそう!」「Rubyには入れられなくても、Active Supportあたりに追加できないかな?」「ローカル変数名を取得できるならやれそうな気もしますね」「欲しい人が多いのもわかります」
後でRubyの#15236(rejected)↓を見てみました。Matzの講評を抜粋してみます。
(別のスレより)この構文についてはほとんど肯定的な気持ちになれない。理由はset構文や昔のRuby 1.8のハッシュスタイルっぽく見えるため。将来ES6の構文が普及したらこの変更を入れるチャンスはあるだろう。
JavaScriptをまったく使っていないコンサバなシニアとしては、この構文についてまだネガティブな気持ちがある。現在のRuby構文ではほぼ不可能なデストラクチャリング(代入の左側)なら最も相性がよさそう。
もちろんRubyユーザーの多くがRailsとJavaScriptを同時に使っていることは認識しているので、皆さんの意見はオープンに受け止めます。
同issueより大意
「そういえばコメントにI’m greenly jealous of JavaScriptという言い方があったんですけど、greenってたしか英語圏だと嫉妬に通じる色なんですよ」「へぇ〜」「日本語の『真っ赤な嘘』的に色の名前に含みがあるというか」
参考: ブルーは憂鬱、グリーンは嫉妬…色にまつわる英語表現(活かす!イングリッシュ Vol.12)|すぐに役立つ英会話・英語レッスン|現地情報誌ライトハウス
greenは、他にも人間を形容すると「青二才」のようなニュアンスも含むことがありますね(たぶん「初々しい」と表裏一体な感じで)。
⚓Railsでサブクエリを使う(Ruby Weeklyより)
つっつきボイス:「PostgreSQLが前提のようです」「またぽすぐれか〜😅」
「このselect('avg(salary)').to_sqlみたいな書き方は自分もやったことある↓ to_sqlすれば普通にサブクエリにできるので」「ふむふむ」
# 同記事より
avg_sql = Employee.select('avg(salary)').to_sql
Employee.select(
'*',
"(#{avg_sql}) avg_salary",
"salary - (#{avg_sql}) avg_difference"
)
「なるほど、FROMでサブクエリしたい場合↓」
# 同記事より
from_sql =
PerformanceReview.select(:reviewer_id, 'avg(score) avg_score').group(
:reviewer_id
).to_sql
PerformanceReview.select('avg(avg_score) reviewer_avg').from(
"(#{from_sql}) as reviewer_avgs"
).take.reviewer_avg
「そしてHAVINGでサブクエリしたい場合↓」
# 同記事より
avg_sql = PerformanceReview.select('avg(score)').to_sql
Employee.joins(:employee_reviews).select(
'employees.*',
'avg(score) avg_score',
"(#{avg_sql}) company_avg"
).group('employees.id').having("avg(score) < 0.75 * (#{avg_sql})")
「サブクエリを使う方が適切なケースは普通にありますね」「もしかすると、コンセンサスの取れる形で生SQLを書けるインターフェイスがActive Recordに公式に入ればそれで解決するのかなという気がしてきた」「そうかも」「言い換えるとArelで頑張るには限界があるということで」「あ〜」「上みたいな書き方をやっていくと今度はWITH句も使いたくなるだろうし😆」「今ならMySQLでもPostgreSQLでもWITH使えますよね」
- PostgreSQLドキュメント: 7.8. WITH問い合わせ(共通テーブル式)
参考: MySQL8.0の新機能、共通テーブル式(WITH句、再帰CTE)の使い方! - bitA Tech Blog
記事見出しより:
- RailsのActive Recordを使うということは
- Railsにおけるサブクエリとは
- 私たちのデータの概要
WHEREにサブクエリを書くWHERE NOT EXISTS
SELECTにサブクエリを書くFROMにサブクエリを書くHAVINGにサブクエリを書く- まとめ
⚓Railsでのマルチテナンシー実装戦略を比較
つっつきボイス:「Railsで複数のテナントの扱いをどう実装するかという戦略の話なのかな」「中身読まないうちに推測すると、rowレベルは複数顧客のデータを同じテーブルに入れるし、dbレベルはデータベースを顧客ごとに分けるというヤツで、スキーマレベルは顧客ごとに別のテーブルを作るんでしょう、きっと」「たぶんそれっぽいこと書いてる気がします」「マルチテナンシーで思いつくのが取りあえずその3つなので😆」「スキーマレベルはcreate schemaとcreate tableって書いてるのでそうだと思います」
- row(行)レベル
- スキーマレベル
- dbレベル
「記事にこんな感じで表が載っています↓」
同記事より
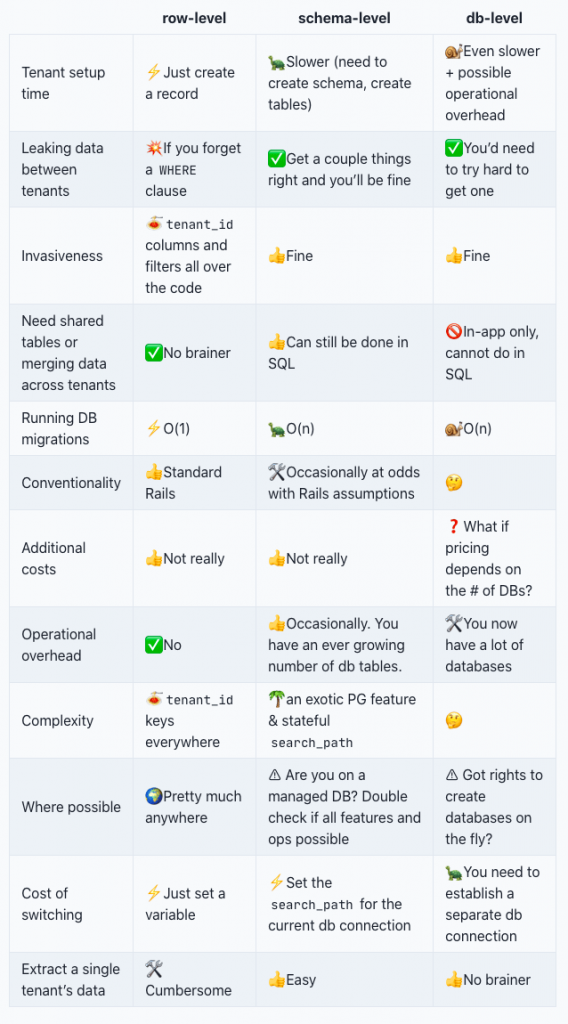
「実際マルチテナンシーをどう実装するかって悩ましいんですよ: たとえばrowレベルにはrowレベルのつらさがありますし」「見えちゃいけないものが見えてしまうとか?」「それは実装がダメすぎ😆」「rowレベルで問題になりやすいのは、パフォーマンスが落ちる問題と、テーブルがバカでかくなったときにどうするかというスケーリングの問題: 1個のテーブルが極限までデカくなってしまうとまともにメンテできなくなる可能性もあるので」「なるほど」
「テナントをdbレベルで分けてあれば、あるデータベースで問題が起きても他のテナントが死なずに済むというメリットが得られます: たとえばテナントのほとんどは小規模だけど、一部のテナントはものすごく激しく使うような案件なら、dbレベルだと障害範囲を限定できるのがいいんですよ」「ふむふむ」「その代わりインフラをメンテナンスするコストが跳ね上がるのがしんどいですけど😭」
「スキーマレベルはまず使わないのが普通なので、これを検討することはほぼないかな」「自分の経験でもrowレベルかdbレベルのどっちかですね」「スキーマレベルでやっていてテナントが数千件とかになったら、テーブルが数千件できるということですよね...」「スキーマレベルはないわ〜」「/dtしてテーブルがどひゃ〜っと表示されたら死にたくなりそう」「イヤ〜😭」「表には『Extract a single tenant’s data = Easy』とか書いてあるけど、果たしてそうかな〜😅?」
「あとRails固有の問題なんですけど、rowレベルでやるとマイグレーションが激重になりがちなのが深刻なんですよ: 1個のテーブルに全テナントのデータが入るのでrails db migrateの遅さが半端なくなる」「あ〜、そうですよね」「dbレベルなら最悪でもテナントごとにマイグレーションを実行できるんですけどね」「rowレベルだと、stagingでは問題なかったのに本番でマイグレーションがなかなか終わらないということが起きがちなので、staging環境のデータベースには十分な量のダミーデータを入れておきたいですね」「たしかに!」「でないとコワすぎるので」
「エンタープライズなアプリのマルチテナンシー周りには気をつけたい」「やべマルチテナントやったことあるわ〜rowレベルだったわ〜😆」「😆」「まあ最近のMySQLやPostgreSQLはデータベースをロックしないでマイグレーションする手順も確立されているので、気をつければ大丈夫ですよ」「つまり気をつけないと死ぬってことですよね🤣」「🤣」
「ただ、どの方法を選ぼうとユーザー数やデータ量が増えれば気にしなければいけないのは一緒なので、この戦略を選びさえすれば楽になるというのはないと思ってます」「そうですよね」
⚓提案: schema.rb生成中にテーブル名やカラム名などをソートする機能(Ruby on Rails Discussionsより)
つっつきボイス:「なるほど、schema.rbの項目ソートか」「ただ既存のカラム名を無断でソートするのはやめて欲しい: データベース内部の物理配置に影響するので、勝手にソートされると意味が変わっちゃう」「あ、それもそうか!」
後で見ると、提案した方はfix-db-schema-conflicts gemの作者で、RubocopによるオートコレクトとぶつからないためにこのgemのソートロジックをRailsのスキーマ生成に入れませんか(カラムの並び順に依存するアプリ用に並び順を維持するオプションも付けて)という提案でした。structure.sqlは変更されないそうです。
「テーブル名のソートはいいと思います😋」「テーブル名なら全然構わない」「ところで今自分のRailsアプリ見るとテーブル名はアルファベット順になってますね」「あ、そうなんですか?」「外部キーのソートはRDBMSに依存しそうな気がする🤔」「結局はCREATE TABLE文の中に書かれているものの順序が、データベース内部のデータ構造に影響するかどうかがポイントでしょうね」
前編は以上です。
おたより発掘
一ヶ月前までRuby1.8, Rails2.3をがっつり触っていたのでURI.parseはちょっと懐かしかった☺️https://t.co/DFHk1CO1qd
— 山口 拓弥 (@yamat47) July 6, 2020
ハッシュ記法のショートハンドはついうっかりやりたくなる
週刊Railsウォッチ(20200706前編)Railsでのマルチテナンシー実装戦略を比較、Railsでサブクエリを使う、URI.parserが非推奨化ほか https://t.co/0ykP4biaDF
— 大野ぴーちゃん (@pi_cha_n) July 6, 2020
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやはてブやRSSやruby-jp SlackやRedditなど)です。

