概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: Speeding up Ruby with Shared Strings | Tenderlovemaking
- 原文公開日: 2018/02/12
- 著者: Aaron Patterson
- サイト: http://tenderlovemaking.com/
Ruby内部の文字列を共有してスピードアップする(翻訳)
メモリを削減し、かつスピードもアップするようなパッチを書き上げられることはそう多くはありません。いつもならメモリとスピードのトレードオフでにらめっこするところですが、今回はうまいことに1つのパッチで両方を実現できました。そこで本記事では、Rubyに投げた#14460チケットについて書きたいと思います。このパッチは「起動後の」Railsアプリのメモリ使用量を4%削減し、requireを約35%高速化します。
実はこのパッチを書いていたときはメモリ使用量の削減を狙っていたのですが、やってみるとメモリ使用量の削減と同時に実行速度も向上しました。なので本当はタイトルを「Rubyのメモリ使用量の削減」とでもしたかったところですが、既に同じタイトルで記事を書いていたのでした。
文字列の共有による最適化
前回の記事でも触れたように、Rubyのオブジェクトは40バイトに制限されています。しかし文字列は40バイトよりずっと長くなることがあります。文字列はどんなふうに格納されているのでしょうか?文字列を表す構造体をご覧いただければ、そこにchar *があるのがわかります。
struct RString {
struct RBasic basic;
union {
struct {
long len;
char *ptr;
union {
long capa;
VALUE shared;
} aux;
} heap;
char ary[RSTRING_EMBED_LEN_MAX + 1];
} as;
};
文字列構造体のptrフィールドは1バイトの配列を指しており、そこが私たちの文字列になります。つまり、文字列の実際のメモリ使用量はオブジェクトで約40バイトの他に、文字列の長さ分増えます。この配置を図示すると次のような感じになります。

この場合、実際のメモリ割り当てはRStringオブジェクトと「hello world」char配列の2つになります。RStringオブジェクトの方はGC(ガベージコレクション)で割り当てられた40バイトのRubyオブジェクトであり、char配列の方はシステムのmalloc実装によって割り当てられたものです。
ちょっとメモ: 別な最適化手法として「埋め込み」も行われています。横道に逸れない程度にご説明すると、「埋め込み」は「十分小さな」文字列を単にRString構造体内部に直接保存することを指します。これについては別記事でご説明してもよいのですが、本記事では常に2種類の異なるメモリ割り当てが存在するということにしておきます。
このchar配列で文字列の途中を指すことによって部分文字列を表現します。たとえば、Rubyオブジェクトが2つあって、1つは「hello world」文字列を表し、もう1つは「world」文字列を表すとすると、これらを1つのchar配列バッファだけに割り当てます。
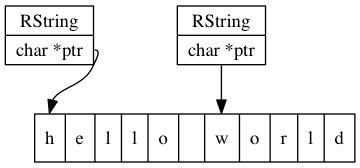
この例の割り当ては3つしかありません。うち2つはRuby文字列オブジェクト用にGCから割り当てられ、1つはchar配列用にmallocで割り当てられます。ObjectSpaceモジュールを使ってスライス後のオブジェクトのメモリサイズを調べると、この最適化を実際に観察できます。
>> require 'objspace'
=> true
>> str = "x" * 9000; nil
=> nil
>> ObjectSpace.memsize_of str
=> 9041
>> substr = str[30, str.length - 30]; nil
=> nil
>> str.length
=> 9000
>> substr.length
=> 8970
>> ObjectSpace.memsize_of substr
=> 40
上の例では、最初に9000文字の文字列が割り当てられます。続けて文字列のメモリサイズを測定すると、文字用の9000文字の他に、Rubyオブジェクトのオーバーヘッド分を含め、メモリサイズの合計は9041文字になっています。次に元の文字列から最初の30文字を部分文字列としてスライスします。元の文字列は9000文字なので、予想どおり部分文字列は8970文字となりました。この部分文字列のサイズを調べてみると、わずか40バイトしかありません。この理由は、新しい文字列でのメモリ割り当ては、新しいRubyオブジェクト分しか必要とせず、新しいオブジェクトは(上の図のように)元の文字列の文字バッファの途中を指しているだけだからです。
この最適化が使えるのは文字列だけではありません。次のように配列でも使えます。
>> list = ["x"] * 9000; nil
=> nil
>> ObjectSpace.memsize_of(list)
=> 72040
>> list2 = list[30, list.length - 30]; nil
=> nil
>> ObjectSpace.memsize_of(list2)
=> 40
実際、関数型プログラミングではデータ構造がイミュータブルなので、この最適化が非常に有効です。イミュータブルでない(=変更可能な)言語では、元の文字列が変更される場合についても取り扱わなければならなくなりますが、データ構造がイミュータブルな言語ならここが大きく最適化されます。
文字列共有による最適化の限界
文字列共有による最適化にも限界というものがあります。この最適化を利用するには、常に文字列の端まで進めなければなりません。言い換えると、文字列の(端にかからない)途中の部分を取り出す最適化はできないのです。先のサンプル文字列で、先頭から15文字、末尾から15文字を除いた真ん中の部分を取り出して、メモリサイズを観察してみましょう。
>> str = "x" * 9000; nil
=> nil
>> str.length
=> 9000
>> substr = str[15, str.length - 30]; nil
=> nil
>> substr.length
=> 8970
>> ObjectSpace.memsize_of(substr)
=> 9011
最初の例と比べると、上の例では部分文字列のメモリサイズがずっと大きくなってしまいました。これはRubyが部分文字列を保存するためのバッファを作成しなければならなかったためです。教訓「文字列をスライスするときは、常に左から右へ行うこと」。
ここで1つ興味深い点について考えてみたいと思います。次のプログラムの末尾にあるsubstrのメモリサイズはいくつになるでしょうか?このプログラムは実際にどれだけのメモリを消費するでしょうか?このstrオブジェクトはまだ「生きている」のでしょうか?生きているとしたらどうやって見つければよいでしょうか?
require 'objspace'
str = "x" * 9000
substr = str[30, str.length - 30]
str = nil
GC.start
# substrのメモリサイズはいくつになるでしょう?
# このプログラムの実際のメモリ消費量はどのぐらいでしょう?
# `str`はGC後も生きているでしょうか?
# ヒント: `ObjectSpace.dump_all`で調べましょう
# (試す場合は`--disable-gems`を付けて実行するのがおすすめです)
ここまでご説明した最適化は、Cの文字列に対してもRubyの場合とまったく同じ方法で機能します。この最適化を、Rubyのメモリ使用量削減とrequireの高速化に用います。
メモリ使用量削減とrequireの高速化
requireの高速化手法の説明が終わりましたので、この問題を見てみることにしましょう。その後で、文字列共有の最適化を適用して実際にrequireのパフォーマンスを改善します。
Rubyでは、プログラムでファイルがrequireされるたびにファイルが既にrequire済みかどうかをチェックしなければなりません。グローバル変数$LOADED_FEATURESには、それまでにrequireされたすべてのファイルリストが保存されます。もちろん、このリストを上から下まで愚直に探索していたら、リストが大きくなるほど速度がガタ落ちになってしまうので、Rubyでは$LOADED_FEATURESリストのエントリ探索のためのハッシュを保持しています。このハッシュはloaded_features_indexと呼ばれ、仮想マシンのこの構造体に保存されます。
このハッシュのキーは、特定のファイルをrequireするときにrequireに渡される文字列です。ハッシュの値は、実際にrequireされたファイルの$LOADED_FEATURES配列のインデックスです。すなわち、たとえばシステムに/a/b/c.rbというファイルがあるとすると、ハッシュのキーは以下になります。
- "/a/b/c.rb"
- "a/b/c.rb"
- "b/c.rb"
- "c.rb"
- "/a/b/c"
- "a/b/c"
- "b/c"
- "c"
読み込みパスをうまく工夫すると、上のどの文字列でも/a/b/c.rbの読み込みに使える可能性が生じるので、インデックスにはこれらをすべて保持しておく必要があります。たとえば、ruby -I / -e"require 'a/b/c'"やruby -I /a -e"require 'b/c'"'などを実行すると、いずれも同じファイルを指します。
loaded_features_indexハッシュはfeatures_index_add関数でビルドされます。この関数の一部をちょっと覗いてみましょう。
static void
features_index_add(VALUE feature, VALUE offset)
{
VALUE short_feature;
const char *feature_str, *feature_end, *ext, *p;
feature_str = StringValuePtr(feature);
feature_end = feature_str + RSTRING_LEN(feature);
for (ext = feature_end; ext > feature_str; ext--)
if (*ext == '.' || *ext == '/')
break;
if (*ext != '.')
ext = NULL;
/* これで`ext`は、`feature`の末尾にある%r{^\.[^./]*$}にマッチする
文字列だけを指す(文字列がない場合はNULLになる) */
この関数はパラメータとしてfeatureとoffsetを1つずつ受け取ります。featureは、requireされたファイルのフルネーム(拡張子などすべてを含む)です。offsetは、読み込まれたfeatureのリストのインデックスで、この文字列はそこにあります。この関数の冒頭では、文字列を末尾から先頭に向かってスキャンし、ピリオド.かスラッシュ/があるかどうかを調べます。.があればそのファイルには拡張子があることが認識され(Rubyでは拡張子のないファイルでもrequireできることにご注意!)、/があれば拡張子がないと仮定します。
while (1) {
long beg;
p--;
while (p >= feature_str && *p != '/')
p--;
if (p < feature_str)
break;
/* *p == '/'の場合: `feature`で'/'が見つかるたびにここを通る */
beg = p + 1 - feature_str;
short_feature = rb_str_subseq(feature, beg, feature_end - p - 1);
features_index_add_single(short_feature, offset);
if (ext) {
short_feature = rb_str_subseq(feature, beg, ext - p - 1);
features_index_add_single(short_feature, offset);
}
}
続いて、文字列を末尾から先頭に向かってスキャンし、/があるかどうかを調べます。/が見つかるたびに、rb_str_subseqを用いて部分文字列を取り出し、features_index_add_singleを呼び出してその部分文字列を登録します。rb_str_subseqは、先ほどRubyで行ったのと同じ方法で部分文字列を取得し、同じ最適化を適用します。
if (ext)条件は拡張子のあるファイルを扱いますが、問題はまさにここから始まるのです。この条件はfeatureの部分文字列を受け取りますが、文字列の端まで進むわけではありません。ファイルの拡張子は除外しなければならないのです。つまり、ここでは背後の文字列がコピーされます。そういったわけで、rb_str_subseqへの2回の呼び出しによってメモリ割り当てが合計3回発生します。うち2つはRubyオブジェクト(この関数はRubyオブジェクトを返します)で、「拡張子のない部分文字列」の場合は文字列をコピーするためのmallocが1回発生します。
この関数はfeatures_index_add_singleを呼ぶことで部分文字列をインデックスに追加します。features_index_add_single関数から一箇所抜粋したいと思います。
features_index = get_loaded_features_index_raw();
st_lookup(features_index, (st_data_t)short_feature_cstr, (st_data_t *)&this_feature_index);
if (NIL_P(this_feature_index)) {
st_insert(features_index, (st_data_t)ruby_strdup(short_feature_cstr), (st_data_t)offset);
}
このコードはインデックス内の文字列を探索し、文字列がインデックスに見当たらない場合はインデックスに文字列を追加します。呼び出し元では新しいRuby文字列にメモリが割り当てられますが、この文字列がGCされる可能性があるため、この関数でruby_strdupを呼び出して文字列をコピーし、ハッシュのキーとします。ここで重要なのは、このハッシュのキーはRubyオブジェクトではなく、Rubyオブジェクトから来たchar *ポインタである点です(先ほどのchar *フィールドです)。
メモリ割り当てを数えてみましょう。ここまではRubyオブジェクト2つ(1つはファイル拡張子あり、もう1つはファイル拡張子なし)、共有されない部分文字列用のmallocが1つ、そして文字列をハッシュにコピーするとmallocがさらに2つ増えます。つまり、メモリ割り当てはfeatures_index_add内のwhileループを繰り返すたびに5回(Rubyオブジェクト2つとmallocが3つ)ずつ行われます。
このような状況は図で説明するのがよいでしょう。以下の図はメモリ割り当てと互いの関係を示したものです。
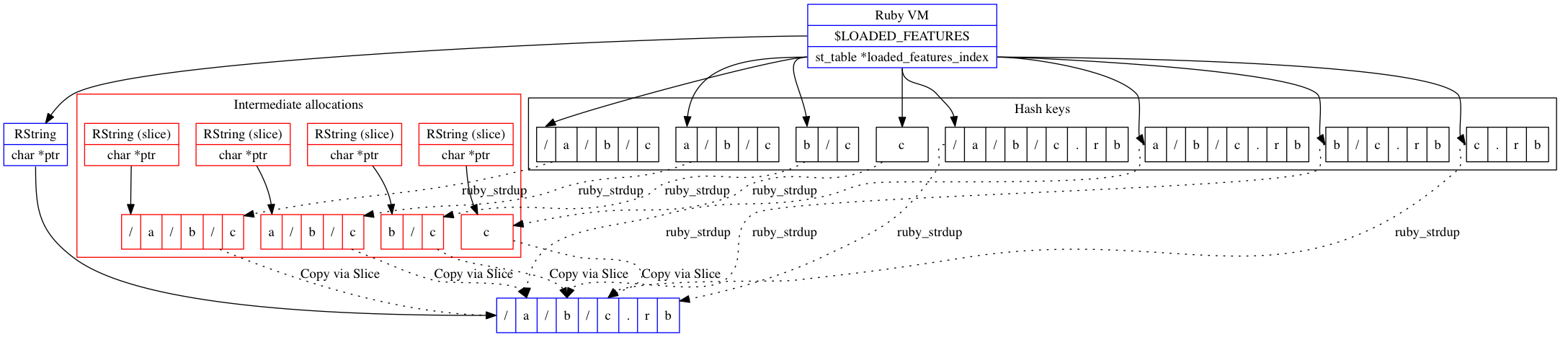
この図では、/a/b/c.rbパスをインデックスに追加してハッシュエントリが8つ生成されたときのメモリ内の配置の様子が示されています。
青いノードは、インデックスにパスを追加する呼び出しを行う前から「生きている」メモリ割り当てを、赤いノードはインデックス追加途中の一時メモリ割り当て(ある時点で解放される)を、黒いノードは、インデックスにパスを追加中に割り当てられたがインデックスへのパス追加完了後も「生きている」メモリ割り当てをそれぞれ表します。実線矢印は実際の参照を表します。点線は関係を示しますが実際には参照ではありません(ある文字列が別の場所からruby_strdupされたときなど)。
この図には多数のノードがあってかなり込み入っていますが、これをすっきりクリーンアップしましょう!
文字列共有の最適化を適用する
最適化の様子をわかりやすく示すため、CコードをRubyコードに移植しました。
$features_index = {}
def features_index_add(feature, index)
ext = feature.index('.')
p = ext ? ext : feature.length
loop do
p -= 1
while p > 0 && feature[p] != '/'
p -= 1
end
break if p == 0
short_feature = feature[p + 1, feature.length - p - 1] # 新しいRubyオブジェクト
features_index_add_single(short_feature, index)
if ext # ファイル拡張子がある場合は切り出す
short_feature = feature[p + 1, ext - p - 1] # 新しいRubyオブジェクト + malloc
features_index_add_single(short_feature, index)
end
end
end
def features_index_add_single(str, index)
return if $features_index.key?(str)
$features_index[str.dup] = index # malloc
end
features_index_add "/a/b/c.rb", 1
既に説明したとおり、文字列共有の最適化は、共有されている文字列の端を部分文字列が含んでいる場合にしか効きません。つまり部分文字列は、元の文字列の左側からしか取り出せません。
最初に行える変更は、文字列を「拡張子あり」「拡張子なし」の2つの場合に分けることです。「拡張子なし」の場合、if文は文字列を末尾までスキャンしないので、常に新しい文字列を割り当てます。拡張子を含まない新しい文字列を作成するようにすれば、mallocの場合を1つ除外できます。
$features_index = {}
def features_index_add(feature, index)
no_ext_feature = nil
p = feature.length
ext = feature.index('.')
if ext
p = ext
no_ext_feature = feature[0, ext] # 新しいRubyオブジェクト + malloc
end
loop do
p -= 1
while p > 0 && feature[p] != '/'
p -= 1
end
break if p == 0
short_feature = feature[p + 1, feature.length - p - 1] # 新しいRubyオブジェクト
features_index_add_single(short_feature, index)
if ext
len = no_ext_feature.length
short_feature = no_ext_feature[p + 1, len - p - 1] # 新しいRubyオブジェクト
features_index_add_single(short_feature, index)
end
end
end
def features_index_add_single(str, index)
return if $features_index.key?(str)
$features_index[str.dup] = index # malloc
end
features_index_add "/a/b/c.rb", 1
この変更によって、関数は新しい文字列を割り当てる代わりに、常にどちらの文字列も末尾までスキャンします。「左からスキャンを開始できる」文字列が2つになったので、ループ内で新しい部分文字列のmallocを回避できました。この「拡張子を含まない」新しい文字列を割り当てる変更についてはこちらでご覧いただけます。
以下の図は、スライスを1つ取り出してから文字列を共有した後のメモリ内の配置と関係を示したものです。
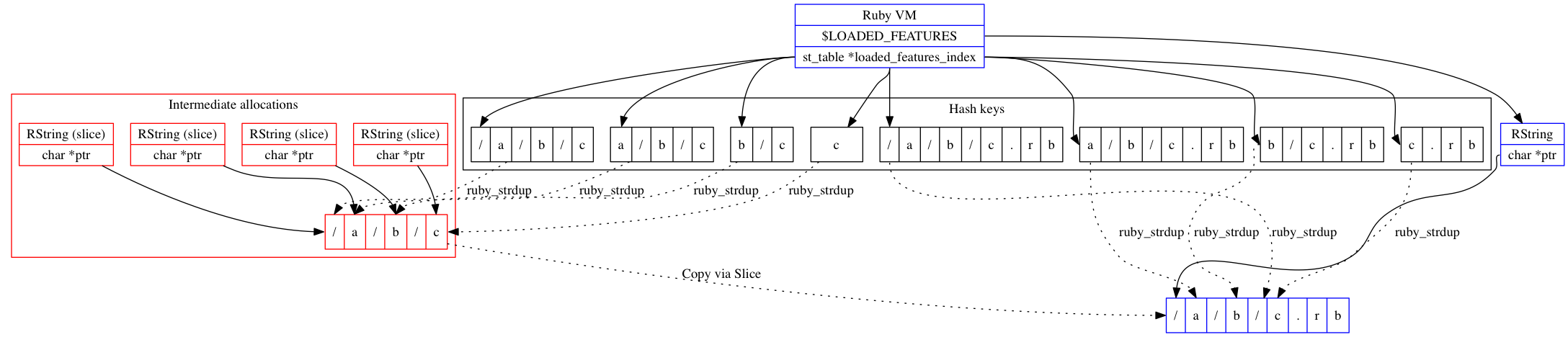
この図から、「拡張子なし」の部分文字列を最初に割り当ててからスライスを取り出すことによって文字列バッファを排除できたことがわかります。
このパッチでは他にも2つの最適化を適用しています。残念ながらこれはC言語固有の手法なのでRubyで説明するのは簡単ではありません。
Rubyオブジェクトのメモリ割り当てを排除する
既存のコードでは文字列のスライスにRubyを使っているので、新しいRubyオブジェクトが1つ割り当てられます。文字列が2つになったことで常に左側から文字列を取れるようになりました。つまり、Cのポインタを用いて部分文字列を「作成」できるようになったのです。文字列をスライスするのにRuby APIに頼らず、Cのポインタで部分文字列の開始地点をシンプルに指しています。インデックスを管理するハッシュテーブルではCの文字列をキーに使っているので、Rubyオブジェクトを引き回す代わりに、単に文字列へのポインタを渡しています。
- short_feature = rb_str_subseq(feature, beg, feature_end - p - 1);
- features_index_add_single(short_feature, offset);
+ features_index_add_single(feature_str + beg, offset);
if (ext) {
- short_feature = rb_str_subseq(feature, beg, ext - p - 1);
- features_index_add_single(short_feature, offset);
+ features_index_add_single(feature_no_ext_str + beg, offset);
}
}
- features_index_add_single(feature, offset);
+ features_index_add_single(feature_str, offset);
if (ext) {
- short_feature = rb_str_subseq(feature, 0, ext - feature_str);
- features_index_add_single(short_feature, offset);
+ features_index_add_single(feature_no_ext_str, offset);
文字列を指すポインタを使うことで、コードがシンプルになりました。feature_strは「ファイル拡張子あり」の文字列の先頭を指すポインタであり、feature_no_ext_strは「ファイル拡張子なし」の文字列の先頭を指すポインタです。begは、スライス対象の文字列の先頭から数えた文字数を表します。後は、それぞれのポインタの先頭にbegを足したものをfeatures_index_add_singleに渡すだけで済みます。
以下の図では、「add single」関数が背後のchar *ポインタに直接アクセスできるおかげで中間のRubyオブジェクトが不要になったことがわかります。
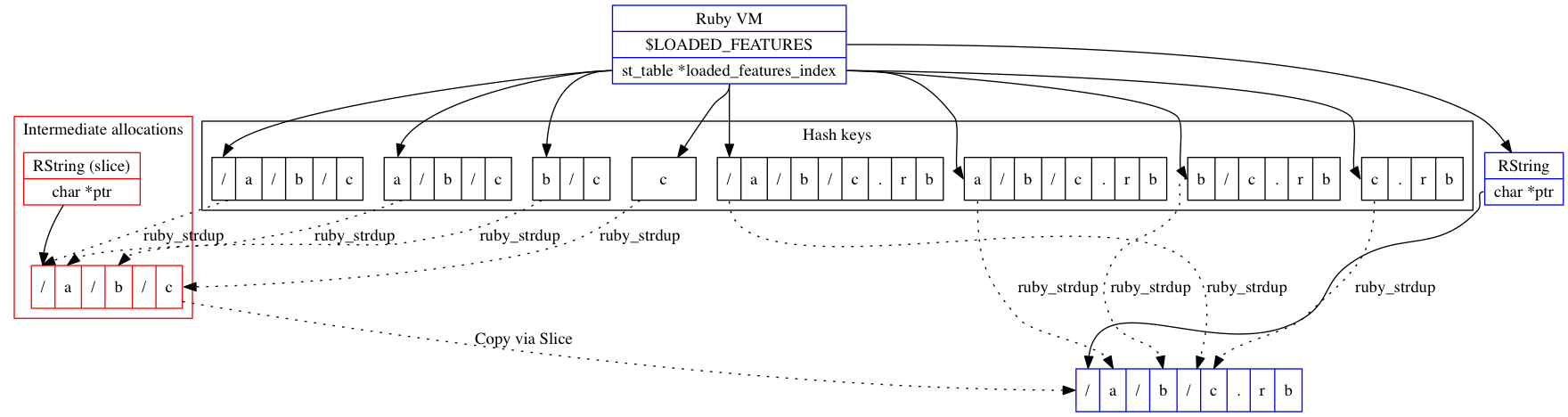
malloc呼び出しを排除する
最後にruby_strdup呼び出しを排除しましょう。既に述べたとおり、新しいRuby文字列の割り当てが発生する可能性があります。このRuby文字列はGCによって解放されるかもしれないので、ruby_strdupで文字列のコピーをインデックスのハッシュ内に取っておかなければなりませんでした。渡されるfeature文字列は$LOADED_FEATURESグローバル配列にも保存されるようになり、この配列はGCされないので、文字列のコピーが不要になりました。しかし、「拡張子なし」の方は新しい文字列を作成していたので、GCされる可能性がありました。これらの文字列がGCされないようにすれば、コピーは一切不要になります。
2つの文字列を「生かしておく」ために、仮想マシン上に配列を1つ追加しました(仮想マシンはプロセスの実行中ずっと生きています)。
vm->loaded_features = rb_ary_new();
vm->loaded_features_snapshot = rb_ary_tmp_new(0);
vm->loaded_features_index = st_init_strtable();
+ vm->loaded_features_index_pool = rb_ary_new();
続いて、割り当ての直後にrb_ary_pushを用いてこの新しい文字列を配列に追加しました。
+ short_feature_no_ext = rb_fstring(rb_str_freeze(rb_str_subseq(feature, 0, ext - feature_str)));
+ feature_no_ext_str = StringValuePtr(short_feature_no_ext);
+ rb_ary_push(get_loaded_features_index_pool_raw(), short_feature_no_ext);
これでインデックスのハッシュ内の文字列が生きたまますべて共有されるようになりました。つまり、GC発生時に文字列が解放されることなく、安全にruby_strdupを削除できるようになったのです。
if (NIL_P(this_feature_index)) {
- st_insert(features_index, (st_data_t)ruby_strdup(short_feature_cstr), (st_data_t)offset);
+ st_insert(features_index, (st_data_t)short_feature_cstr, (st_data_t)offset);
}
この変更後、Ruby文字列オブジェクト内に潜むchar配列をハッシュのキーが直接指すようになり、そのおかげでメモリコピーが完全に不要になりました。

この新しいアルゴリズムでは2つの割り当てが行われます。1つは元の文字列をコピーした「拡張子なし」用、1つはそれをラップするRStringオブジェクトです。「loaded features index pool」配列に保存された新規作成文字列はGCから保護され、文字列をコピーする必要なしに文字列の配列を直接指せるようになりました。
「loaded features」配列に追加されるどのファイルについても、割り当てにO(N)(Nは文字列内のスラッシュ数)が必要だったのを、文字列のスラッシュ数にかかわらず2つの割り当てだけで常にまかなえるように変更されました。
おしまい
文字列共有によって、Railsの起動プロセス中のシステムコールを76,000以上削減し、メモリのフットプリントを4%削減し、requireを35%高速化することに成功しました。来週は巨大なアプリで統計を取ってこの変更がどれだけうまくいっているかを見てみたいと思います。
お読みいただきありがとうございました!