概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: Ruby Next: Make all Rubies quack alike — Martian Chronicles, Evil Martians’ team blog
- 原文公開日: 2020/05/04
- 著者: Vladimir Dementyev -- Evil Martiansのリード開発者です。
- サイト: Evil Martians -- ニューヨークやロシアを中心に拠点を構えるRuby on Rails開発会社です。良質のブログ記事を多数公開し、多くのgemのスポンサーでもあります。
日本語タイトルは内容に即したものにしました。
Ruby NextトランスパイラでRubyの新機能を使おう(翻訳)
最近のRubyは、かつてない速度で進化を繰り返しています。最新のマイナーリリースであるRuby 2.7には、ナンバードパラメータやパターンマッチといった新しい構文が導入されています。しかしながら、production環境やオープンソースプロジェクトでのRubyバージョン切り替えは簡単な話ではありません。production Webサイトの開発者は、Rubyのアップグレード後にいろんな形で微妙に壊れる何千行ものレガシーコードの面倒を見てやらなければなりません。gemの作者であれば、JRubyやTruffleRubyなどの広く用いられているRubyの別実装についても古いバージョンのRubyをサポートしなければなりません。構文が変更されたときの対応も、すぐに行なってもらえるとは限りません。
本記事では、Ruby Nextという新しいツールをRuby開発者にご紹介します。Ruby Nextは上述の問題の解決はもちろん、Rubyコアチームのメンバーがエクスペリメンタル(実験的)な機能や提案を評価するときにも役立つことを意図しています。本記事では以下のトピックについても言及します。
⚓バックポートが重要である理由
クリスマスになったら必ずRubyを最新バージョンにアップグレードすることができない理由とは何でしょう?皆さまご存知のように、Matzは長い間Rubyの新しいメジャーリリースを12月25日にお披露目しています。その理由は、アップデート作業を休日にすべきではないという事実ももちろんありますが、開発チームに敬意を払うためでもあります。
ところで、私は自分を第一に「ライブラリ開発者」と考えたい人であり、「アプリケーション開発者」であることについては最後二の次です。私が何でもかんでもgem化したがるので、Evil Martiansのメンバーが長年そのことをネタにしているほどです。私がメンテしているgemは軽く数ダースを超えていて、いくつかはかなり評判を得ています。ともあれ、そのことが最初の問題につながりました。
つまり私は古いバージョンのRubyと互換性を保ったコードを書かなければならなくなったのです。
理由ですか?少なくともまだEOL(end of life)を迎えていないRubyバージョンをすべてサポートするのはよいことだからです。
Rubyメンテナンスカレンダーによると、本記事公開時点で「生きている」Rubyバージョンは2.5、2.6、2.7です。それより古いバージョンも利用できないわけではありませんが、できる限り早期にアップグレードすることが強く推奨されています。セキュリティ上の脆弱性が新たに見つかった場合、EOLを迎えたバージョンについては修正されないためです。
つまり、私のgemのユーザーにRubyのアップグレードを強要せずに、私のgemで2.7の機能をフルに利用するには、少なくとも2年待たなければならないのです。
もっと言えば、2年後に私がRubyを書いているかどうかもわかったものではありません。私は、この強烈なパターンマッチングを、今すぐ使いたいのです!
もし仮に、私がユーザーの都合などまったく無視してrequired_ruby_version = "~> 2.7"を指定した新しいgemをリリースしたら、どんなことになると思いますか?
そんなことをしたら、gemのユーザーの貴重な時間を吹っ飛ばしてしまうでしょう。RubyGems.orgの統計情報で、古いバージョンのRubyで動かなくなったgemの割合を見てみましょう。
RubyGems.orgでのバージョン非互換(2020/04/04時点)
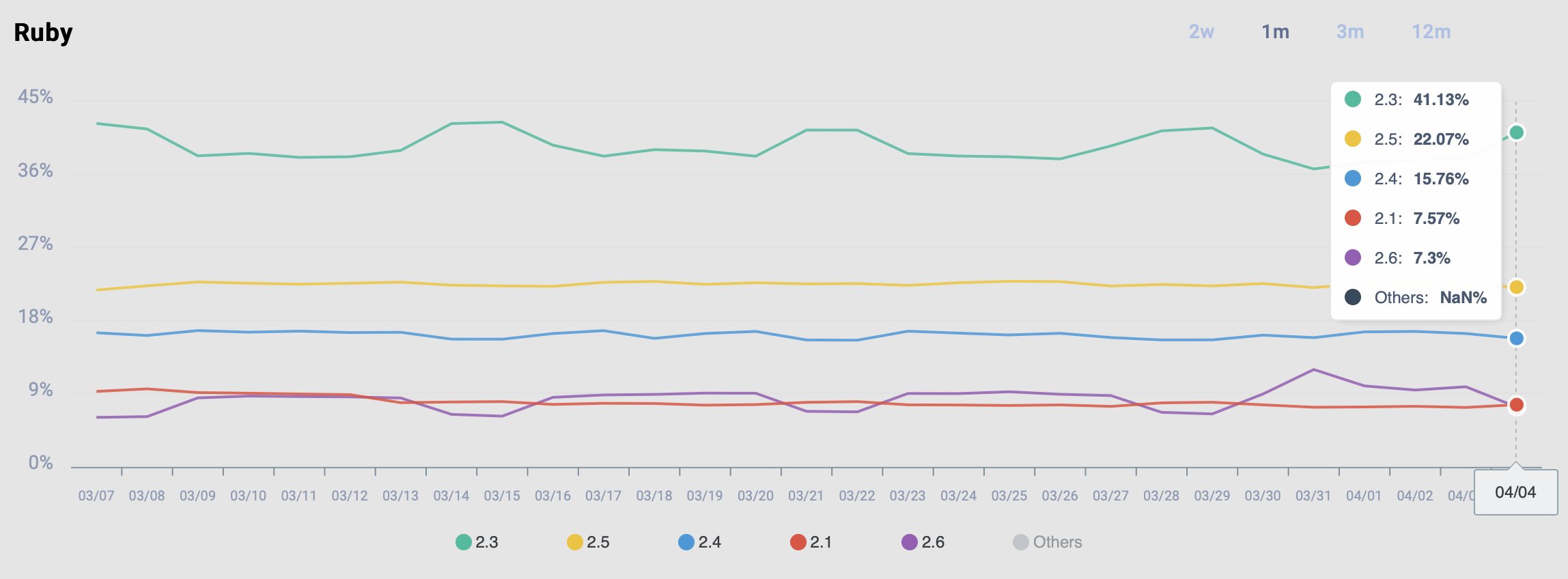
当然ながら現時点のグラフには2.7は見当たりません。ご注意いただきたいのは、このデータがある意味で「テクニカルすぎる」点です。つまりこの統計情報にはRubyアプリケーションや開発者からの情報だけではなく、(macOSやLinuxの)システムにプリインストールされているRuby(たいてい数バージョン古いものが使われています)のような無関係な情報源も含まれているのです。
Rubyコミュニティの現状をよりリアルに示す情報は、JetBrainsの毎年恒例のアンケートです。こちらは2019年度のデータですが、今もそう大きくは変わっていないと思います。
最もよく使われているのはどのバージョンのRubyでしょうか?
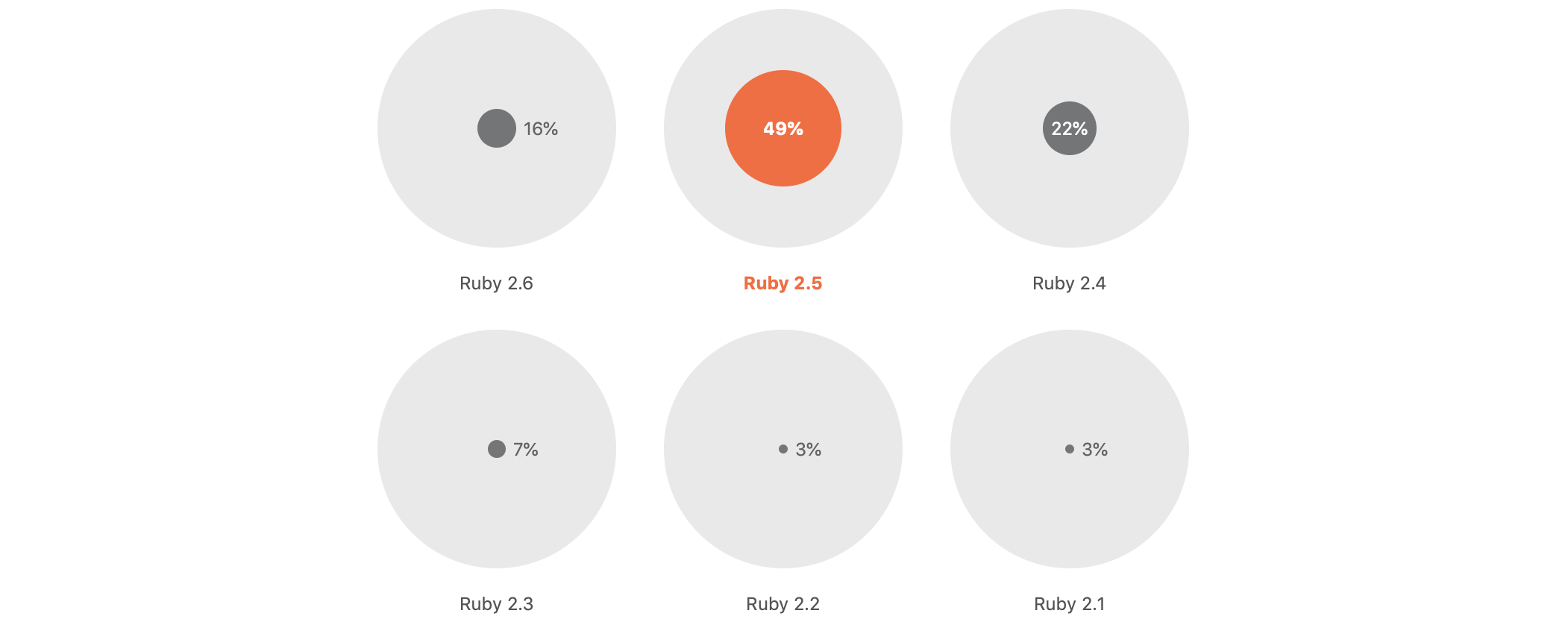
ご覧のとおり、2.3はとっくに主流ではなくなっています。そしてアンケート調査時点での最新バージョンである2.6は3位に甘んじています。
最もよく使われているのは、常に最新から3つのRubyバージョンのうち2つまたは3つのバージョンです。そして3つの新しいバージョンのうち、最新バージョンはいつも最下位です。
もうひとつの洞察は「バージョンを上げるつもりのない回答者が30%もいる」ことです。
どうしてこうなったのでしょう?おそらくですが、「アップグレードのためのアップグレード」はコストが高すぎると思われているのでしょう。「動いているならそのままでもいいでしょ?」という具合に。
アップグレードするときの正しい動機とは何でしょう?パフォーマンスの改善(次のRubyでは必ずそうなるから)でしょうか?そうとも限りません。新しい機能があると開発者の乗り換えが進むからでしょうか?(2.7で非推奨化および変更されたキーワード引数の挙動のように)乗り換えが高くつくのでなければイエスでしょう。
結論: 理屈のうえでは言語に追加された最新の機能は開発者を魅了するでしょうが、実際にすぐ適用されることはめったにありません。
そこで私は、現在の環境とは独立に現実のプロジェクトで誰もがモダンなRubyを味わえるようにする方法を模索することを決意しました。
⚓#yield_selfや#thenのトランスパイル
Ruby Nextの技術的な概要に触れる前に、私の個人的な「Rubyの現代化」についてお話ししておきたいと思います。
2017年の冬、ちょうどクリスマスツリーの下にRuby 2.5がお目見えしたときのことです。そのときから私が注目していた機能は、ある意味議論のタネになりそうでした。それがあのKernel#yield_selfメソッドです。当初このメソッドについては自分も少々懐疑的でした。「これで果たして自分のRubyの書き方が変わるかどうか、疑問だ」と。
ともあれ、業務アプリでこれを試してみることに決めました(幸い私たちはRubyをできる限り早期に、x.y.1リリースあたりでアップグレードしようとしていました)。そして使えば使うほど、このメソッドが好きになってきました。
最終的に#yield_selfは私のgemのひとつでコードベースに取り入れられましたが、当然ながらRuby 2.4でのテストはコケました。これを修正する最もシンプルな方法は、Kernelモジュールにモンキーパッチを当て、古いRubyが新しいRubyと同じ声で「鳴く」ようにすることでした。
gem開発のベストプラクティスを守る者として(特にgem開発のチェックリストの作者として)、モンキーパッチはあくまで最後の手段であり、ライブラリでモンキーパッチを当てるのは禁じ手だということは認識していました。要するに、モンキーパッチの当たったメソッドを他の誰かが同じ名前で定義するとコンフリクトが生じます。#yield_selfでそれをやるのは容認し難いシナリオです。しかし数か月後、今度は#thenエイリアスがRuby trunkにマージされたのです🙂。
つまり「モンキーパッチではない」モンキーパッチが必要ということです。
Rubyにはそれをやる方法が既にあるのです。そのパッチは以下のような感じになります。
module YieldSelfThen
refine BasicObject do
unless nil.respond_to?(:yield_self)
def yield_self
yield self
end
end
alias_method :then, :yield_self
end
end
というわけで、ここからしばらくrefinementsについてお話しします。
⚓refineならうまくやれる
Refinementは、Rubyで最も注目に値する機能といっても過言ではありません。一言で言うとrefinementは「レキシカルスコープでモンキーパッチを当てる」ことです。しかしこの定義だけでは、この機能がどんな野獣かを理解するのに役立つとは思えません。次の例で考えてみましょう。
以下の3つのスクリプトがあるとします。
# succ.rb
def succ(val)
val.then(&:to_i).then(&:succ)
end
# pred.rb
def pred(val)
val.then(&:to_i).then(&:pred)
end
# main.rb
require_relative "succ"
require_relative "pred"
puts send(*ARGV[0..1])
Ruby 2.6以降で実行すれば、以下のように正しい結果が得られます。
$ ruby main.rb succ 14
15
$ ruby main.rb pred 15
14
Ruby 2.5で実行してみると、以下のように例外が発生します。
$ ruby main.rb succ 14
undefined method `then' for "14":String
もちろん#thenを#yield_selfに置き換えればすべて期待どおりに動作しますが、それはやらないことにしましょう。代わりに、上で定義したYieldSelfThenというrefinementを使います。
このrefinementコードをyield_self_then.rbファイルに入れて、そのrefinementをsucc.rbファイルの中だけで有効にします。
# main.rb
+ require_relative "yield_self_then"
require_relative "succ"
require_relative "pred"
...
# succ.rb
+ using YieldSelfThen
+
def succ(v)
v.then(&:to_i).then(&:succ)
end
今度は、succコマンドを実行すると正しい結果が得られます。
$ ruby main.rb succ 14
15
ただしpredは今度も失敗します。
$ ruby main.rb pred 15
undefined method `then' for "14":String
先ほどのrefinementの定義の「レキシカルスコープが適用された部分」を思い出しませんか?YieldSelfThenモジュールにrefineメソッドで定義された拡張部分は、using宣言を追加したsucc.rbの「中からしか見えません」。そのプログラムの他のRubyファイルからは「見えません」。何も拡張されていないように動作します。
つまり、refinementによってモンキーパッチに手綱を付けて制御できるようになります。そう、refinementは安全なモンキーパッチなのです。
refinementは安全なモンキーパッチです。
refinementがRubyに導入されたのは2.0のときでしたが(当初はエクスペリメンタルで、2.1以降は安定しています)、あまり反響を得られませんでした。ウケなかった主な理由は以下のようにさまざまです。
- 初期段階では大量のエッジケースがあった(モジュールがサポートされていない、
sendがサポートされていないなど)。この点はRubyがリリースされるたびに改良されていますし、今ではRuby(MRI)の主要な機能として認知されています。 - Rubyの別実装でのrefinementサポートが遅れていた。JRubyのコアチーム(特にCharles Nutter)がこの方面の改良に大きな業績を残してくれたおかげで、JRuby 9.2.9.0以降でrefinementを利用できるようになりました。
あえて申し上げると、今やrefinementに関する重大な問題はすべて過去のものになっています。「refinementはエクスペリメンタルで使い物にならない機能だ」という議論は最早正しくありません。
そういうわけで、私はバックポートの問題をrefinementで解決することに賭けたのです。
新しいAPIはrefinementで安全にバックポートできます。
2.7より前のRubyに「ユニバーサルrefinement」を追加するだけで、古いRubyを新しいRubyと同じように「鳴かせる」ことができました。Ruby Nextのアイデアは元々ここから始まりました。「ひとつのrefinementがすべてを統べる」とはまさにこのことです(訳注: The Lord of the Ringsのもじり)。
# ruby_next_2018.rb
module RubyNext
unless nil.respond_to?(:yield_self)
refine BasicObject do
# ...
end
end
unless [].respond_to?(:difference)
refine Array do
# ...
end
end
unless [].respond_to?(:tally)
refine Enumerable do
# ...
end
end
# ...
end
# ...and then in your code
using RubyNext
幸い、私はこのプロジェクトを2018年にはリリースしていませんでした。Ruby 2.7に追加された新機能によって、私のrefinementアプローチだけでは足りないことが判明したのです。当たり前のことですが「構文はrefinementできません」。Ruby Nextを作るうえで最も興奮する作業であるトランスパイラづくりはこのときから始まりました。
⚓トランスパイルで構文をrefineする
2019年になるとRuby構文が積極的に進化を遂げ始め、以下のような多くの新機能がmasterブランチにマージされました(全部が生き残ったわけではありませんが)。
- #12125: メソッド参照演算子
->- (最終的に#16275で取り消し)
- #15799: パイプライン演算子
|> - パターンマッチング
- ナンバードパラメータ
まるで新幹線のようなスピード進化を目にして、「こういうのを全部まとめて自分のプロジェクトやgemに入れられたらいいんじゃないか?」と私は考えました。果たしてそんなことが可能なのでしょうか?それが可能であることがわかったのです。以上がRuby Nextの誕生秘話でした。
Ruby Nextには、refinementによるポリフィルのコレクションに加えて、もうひとつの強力な機能として「RubyからRubyへのトランスパイラ」が導入されました。
一般に「トランスパイラ」は、あるソースから別のソースへのコンパイラ、つまり、入力と出力のフォーマットが同じコンパイラを指す用語として使われています。つまり、Ruby NextはRubyコードを別のRubyコードに「コンパイル」しますが、機能は失われません。より正確に言えば、Ruby Nextトランスパイラは以下のように、最新版またはエッジ版のRuby向けソースコードを、より古いバージョンと互換性のあるソースコードに変換します。
![]()
フロントエンド開発の世界ではトランスパイラが広く普及しています。JavaScript用のBabelやCSS用のPostCSSもそうしたツールです。
このようなツールが存在する理由は、ブラウザ同士に非互換性があることと、言語の進化(より正確には仕様の進化)が早いためです。このことに驚く方もいるかもしれませんが、これと同じ問題がRubyにもあるのです。さまざまなブラウザがあるようにRubyのランタイムもさまざまですし、上述したようにRuby言語も急速に変化しています。もちろん、ここ5年のフロントエンド開発の惨状と比べれば大したスケールではありませんが、Rubyも今のうちに備えておくのがよいと思います。
⚓ASTからASTへの変換
ここでRuby Nextのトランスパイラの動作を簡単に見てみることにしましょう。技術的な詳細については今後の記事(またはカンファレンスのスピーチ)に譲ることにして、今は基本的な部分を押さえておきます。
トランスパイルをネイティブに実行する方法といえば、「コードをテキストとして読み込む」
「gsub!をいくつか適用する」「結果を新しいファイルに出力する」方法が考えられます。しかし残念ながら、この手法はたとえばメソッド参照演算子(.:)にsource.gsub!(/\.:(\w+)/, '.method(:\1)')を適用するような最もシンプルなケースにすら使えません。これが通用するのは、文字列やコメントの中に.:が含まれていない場合です。つまり「コンテキストを知っている何か」、すなわちAST(抽象構文木: abstract syntax tree)が必要になります。
![]()
ASTの理屈は抜きにして、さっそくやってみましょう。RubyソースコードからASTを生成するにはどうすればよいでしょう?
Rubyエコシステムには以下のようにさまざまなAST生成ツールがあります。
これらのツールで以下のコード例から生成したASTを見てみましょう。
# beach.rb
def beach(*temperature)
case temperature
in :celcius | :c, (20..45)
:favorable
in :kelvin | :k, (293..318)
:scientifically_favorable
in :fahrenheit | :f, (68..113)
:favorable_in_us
else
:avoid_beach
end
end
RipperはRuby 1.9から標準で使えるツールで、ソースコードからS式(symbolic expressions)を生成できます。
$ ruby -r ripper -e "pp Ripper.sexp(File.read('beach.rb'))"
[:program,
[[:def,
[:@ident, "beach", [1, 4]],
[:paren,
[:params,
[:rest_param, [:@ident, "temperature", [1, 11]]],
],
[:bodystmt,
[[:case,
[:var_ref, [:@ident, "temperature", [2, 7]]],
[:in,
[:aryptn,
nil,
[[:binary,
[:symbol_literal, [:symbol, [:@ident, "celcius", [3, 6]]]],
...
ご覧のとおり、戻り値は深くネストしていて、ところどころに識別子(id)があります。Ripperは残念なことに、ASTのノードにどんな種類があるかというドキュメントが存在せず、しかもノードにこれといったパターンが見いだせません。さらに重要なのは、Ripperは古いRubyで新しいRubyのコードをパースできないことです。かといって、トランスパイルのためだけに最新版Ruby(特にエッジ版)を使えと開発者に強要するわけにもいきません。
最近Ruby 2.6で追加されたRubyVM::AbstractSyntaxTreeというモジュールは、より洗練されたオブジェクト指向のAST表現を提供してくれますが、惜しくもRipperと同じくバージョンに依存するという問題があります。
$ ruby -e "pp RubyVM::AbstractSyntaxTree.parse_file('beach.rb')"
(SCOPE@1:0-14:3
body:
(DEFN@1:0-14:3
mid: :beach
body:
(SCOPE@1:0-14:3
tbl: [:temperature]
args: ...
body:
(CASE3@2:2-13:5 (LVAR@2:7-2:18 :temperature)
(IN@3:2-12:16
(ARYPTN@3:5-3:28
const: nil
pre:
(LIST@3:5-3:28
(OR@3:5-3:18 (LIT@3:5-3:13 :celcius) (LIT@3:16-3:18 :c))
...
最後のParserは、元々Evil Martiansの@whitequarkが開発した純粋なRuby gemです。
$ gem install parser
$ ruby-parse ./beach.rb
(def :beach
(args
(restarg :temperature))
(case-match
(lvar :temperature)
(in-pattern
(array-pattern
(match-alt
(sym :celcius)
(sym :c))
(begin
(irange
(int 20)
(int 45)))) nil
(sym :favorable))
...
Parser gemは先の2つと異なり、Rubyのバージョンに依存しません。サポートされているバージョンのRubyであれば任意のRubyコードをパースできます。APIの設計もよくできていて、ソースリライトのような便利なビルトイン機能もいくつかあります。しかもRuboCopなどの有名なツールで実績を積んでいます。
Parserにはさまざまなメリットがありますが、惜しくもRubyとの互換性は100%ではありません。つまり、妙ちきりんなコードを書くと、Rubyとしては正当であってもParserで正しく認識できなくなります。
以下は最もよく知られている例です。
<<"A#{b}C"
#{
<<"A#{b}C"
A#{b}C
}
str
A#{b}C
#=> "\nstr\n"
Parserが上のコードから生成したASTは以下のようになります。
(dstr
(begin
(dstr
(str "A")
(begin
(send nil :b))))
(str "\n")
(str "str\n")
(str "A")
(begin
(send nil :b))))
ここで問題なのは(send nil :b)というノードです。Parserはヒアドキュメントのラベル内にある#{...}を式展開として扱いますが、これは式展開では「ありません」。どうか皆さんがこの黒知識を駆使して、Parserに依存するライブラリを片っ端からぶっ壊したりしませんように😈。
ご覧いただいたとおり、どのツールも一長一短です。エクスペリメンタルなプロジェクトのために、わざわざパーサーをスクラッチから書いたりMRIのパーサーから抽出したりするのはしんどすぎます。
私はRubyのキモい部分に目をつぶって生産性を優先し、Parser gemを使うことに決めました。
Parserを選ぶもうひとつのセールスポイントは、Unparserというgemの存在です。名前からわかるように、Parserで生成したASTからRubyコードを生成できます。
⚓RubyからRubyへのトランスパイル
Ruby Nextのトランスパイラコードは最終的に以下のような感じになりました。
def transpile(source)
ast = Parser::Ruby27.parse(source)
# 必要なAST変更を実行
new_ast = transform ast
# 新しいソースコードを返す
Unparser.unparse(new_ast)
end
#transformメソッド内では「rewriterのパイプライン」経由でASTを渡します。
def transform(ast)
rewriters.inject(ast) do |tree, rewriter|
rewriter.new.process(tree)
end
end
各rewriterは、単一の機能について責務を持ちます。例のメソッド参照演算子のrewriterを見てみましょう(実際にはこの提案はRubyで取り消されましたが、デモ用には十分でしょう)。
module Rewriters
class MethodReference < Base
def on_meth_ref(node)
receiver, mid = *node.children
node.updated( # (meth-ref
:send, # (const nil :C) :m)
[ #
receiver, # ->
:method, #
s(:sym, mid) # (send
] # (const nil :C) :method
) # (sym :m)
end
end
end
やっていることは、meth-refノードを、対応するsendノードに置き換えているだけです。簡単ですね!
しかしこういうシンプルな置き換えばかりではありません。たとえばパターンマッチング用のrewriterは800行を超えています。
現在のRuby Nextトランスパイラは、rangeの開始値省略を除くRuby 2.7の全機能をサポートしています。
beach.rbをトランスパイルした結果を見てみましょう。
def beach(*temperature)
__m__ = temperature
case when ((__p_1__ = (__m__.respond_to?(:deconstruct) && (((__m_arr__ = __m__.deconstruct) || true) && ((Array === __m_arr__) || Kernel.raise(TypeError, "#deconstruct must return Array"))))) && ((__p_2__ = (2 == __m_arr__.size)) && (((:celcius === __m_arr__[0]) || (:c === __m_arr__[0])) && ((20..45) === __m_arr__[1]))))
:favorable
when (__p_1__ && (__p_2__ && (((:kelvin === __m_arr__[0]) || (:k === __m_arr__[0])) && ((293..318) === __m_arr__[1]))))
:scientifically_favorable
when (__p_1__ && (__p_2__ && (((:fahrenheit === __m_arr__[0]) || (:f === __m_arr__[0])) && ((68..113) === __m_arr__[1]))))
:favorable_in_us
else
:avoid_beach
end
end
「何だこれは?」「見るに堪えない!」とお思いの方、ご心配なく。これは人間が読んだり編集するコードではなく、Rubyラインタイムに解釈させるためのコードです。機械ならこんなコードでも問題なく理解できます。
トランスパイルされたコードは機械のためのものであり、人間用ではありません。
ただし、トランスパイルされたコードの構造を元のコードにできる限り近づけたい場合がひとつあります。ここで言う「コードの構造が同じ」とは、レイアウトや行番号が同じという意味です。
上のトランスパイル済みコード例の7行目(:scientifically_favorable)は、元のコード(in :fahrenheit | :f, (68..113))と違っています。
このズレが問題になるのは「デバッグ時」です。デバッガ、コンソール(IRBやPryなど)では元のコードの情報を使いますが、ランタイムの行番号は違ってきます。デバッグ頑張れ😈!
この問題を克服するために、Ruby Next 0.5.0ではトランスパイルの「リライトモード」を導入しました。ここではParserのリライト機能を用いて、変更をその場でソースコードに反映します(なおRuboCopのオートコレクト機能も同じ方法です)。
Ruby Nextでは、速度と予測可能性を高めるため、デフォルトでトランスパイルの「生成モード」(AST->AST->Ruby)を利用します。いずれの場合も、実際に「バックポートされたコード」は似たようなものになります。
⚓パフォーマンスと互換性
ここでよくある疑問は「Ruby 2.7のエレガントなcase-inをcase-whenに変換した場合、パフォーマンスの違いをどうやって比較すればよいのか?」でしょう。驚かないでください、ベンチマークの結果はこうです。
Comparison:
transpiled: 1533709.6 i/s
baseline: 923655.5 i/s - 1.66x slower
トランスパイルされたコードの方がネイティブ実装より速いことをどうやって知ったかというと、パターンマッチングのアルゴリズムに最適化を少々追加したのです(#deconstruct値のキャッシュなど)。
この最適化で互換性が失われないと私が信じている理由ですか?またひとついい質問をありがとうございます。
トランスパイルされたコード(とバックポートされたポリフィル)が期待どおり動作するために、私はRubySpecとRuby自身のテストコードを用いています。ただし、トランスパイルされたコードがMRIと100%互換性があるということではなく、少なくとも期待どおり動いているということです(実を言うと、互換性を損なうエッジケースをいくつか見つけてしまったのですが、内緒にしておきます🤫)。
⚓実行時間とビルド時間
トランスパイルの内部動作についてひととおり学んだので、いよいよ皆さんお待ちかねの疑問「ライブラリやアプリケーション開発にどうやってRuby Nextを統合するか」にお答えする時間がやってまいりました。
私たちRubyistは、フロントエンド開発者とは異なり、コードを「ビルド」する必要がないのが普通です(mrubyやOpalなどを使っていれば別ですが)。ruby my_script.rbを呼べばおしまいなのですから。ではトランスパイルされたコードをどうやってインタプリタに注入するのでしょうか?
Ruby Nextではコードの性質に応じて2とおりの戦略を前提としています。つまり「gem開発」と「アプリケーション開発」です。
アプリケーション開発向けには「ランタイムモード」を提供しています。このモードでは、アプリケーションのルートディレクトリから読み込まれた(requireされた)すべてのRubyファイルは、VM内部で評価される前の時点でトランスパイルされます。
この処理については以下の擬似コードで説明します。
# Kernelにパッチを当ててrequireをハイジャックする
module Kernel
alias_method :require_without_ruby_next, :require
def require(path)
realpath = resolve_feature_path(path)
# アプリケーションのソースファイルのみをトランスパイルする(gemは除外)
return require_without_ruby_next(path) unless RubyNext.transpilable?(realpath)
source = File.read(realpath)
new_source = RubyNext.transpile source
# トランスパイルするものがない場合
return require_without_ruby_next(path) if source == new_source
# requireで読み込むのと同じ方法でコードを読み込む
RubyNext.vm_eval new_source, realpath
true
end
end
実際のコードはここにあります。
実行時トランスパイルは、以下の2つのステップで有効にできます。
- Gemfileに
gem "ruby-next"を追加する - アプリケーションのブートプロセスのできるだけ早い段階で
require "ruby-next/language/runtime"を追加する(Railsプロジェクトのconfig/boot.rbなど)
新しいライブラリを使ってこんなに強力なモンキーパッチを当てるのはいくらなんでも怖すぎるとお思いの方(私もそう思います🙂)のために、Bootsnapとの統合もサポートしています。これならパッチを当てる責務のコアをShopifyに任せられます🙂(Shopifyはここを正しくやる方法をわかっているので)。
gem開発向けの場合は、まず「優れたライブラリとは何か」についてさまざまな側面から考えるべきです(依存ライブラリの個数や、考えられる副作用など)。GemCheckもご覧ください。その結果、gemの中でRuby Nextをランタイムモードで有効にするのはどうもよくなさそうだということが見えてきました。
やりたいのはそれではなく、その時点でサポートするすべてのRubyバージョンでコードが動くgemをリリースできるようにしたい、つまりコードを事前にトランスパイルしたいのです。Ruby Nextでこのフローを使うには、以下の手順に沿って進めます。
- Ruby Next CLIを用いてトランスパイル済みのコードを生成します(
ruby-next nextify lib/)。このコマンドを実行するとlib/.rbnextフォルダが作成され、古いバージョンのRubyで必要なファイルがその中に置かれます。 - Rubyの
$LOAD_PATHを設定して、RubyNext::Language.setup_gem_load_pathを呼び出したときにlib/.rbnext/<バージョン>に対応するファイルを自分のgemのルートファイル(エントリポイント)で探索するようにします(詳細)。
その結果、.gemパッケージが追加される分容量がかさばってきます(=一部のファイルが重複する)。しかしそのおかげで、ライブラリのユーザーはトランスパイルのことを一切気にする必要がなくなります。そしてついにgemでモダンなRubyが使えるようになるのです!
⚓「Rubyのバックポート」から「未来のRubyづくり」まで使えるRuby Next
ここまではRuby Nextの構文やAPIバックポートツールとしての側面だけを見てきました。正直に申し上げれば、私が当初Ruby Nextをこしらえた理由はまさにこれであり、それ以上細かな点までは考えていませんでした。
しかし2019年11月に開催された2つの出来事、つまり「メソッド参照演算子導入の取り消し」と「RubyConf」の後で、パラダイムシフトが起きました。このときの私は、Matz自身を含む多くのきら星のようなRubyistたちとRuby言語の評価について議論するチャンスを得られたのです。
なぜ.:というたった2つの記号を巡ってあれほど多くのドラマが生まれたのでしょうか?メソッド参照演算子を取り巻く状況はかなり型破りなものでした。メソッド参照演算子は2018年12月31日にmasterにマージされましたが、ほぼ11か月後の2019年11月12日に取り消されました。以下のようなコード例付きのブログ記事が公開され、私もこの機能をバックポートするためのトランスパイラを作成していたのですが...。多くのRuby開発者はメソッド参照演算子が便利であることに気づき、2.7のリリースを心待ちにしていたのです。
参考: Reverted Ruby 2.7 new feature: Method reference operator - DEV
参考: Ruby 2.7 adds shorthand operator for Object#method | Saeloun Blog
しかしこの機能は、とある理由でキャンセルされました(#16275)。masterで1年近く生きながらえた新機能が消されるなんてことがあるのでしょうか?もちろんあります。元々この機能のステータスはエクスペリメンタルでしたから。
ここでの正しい質問は「実験は行われたのか?」でしょう。しかしそれについてはノーだと思います。というのも、この機能を使ったコミュニティメンバーはごく少数しかいなかったからです。ソースからエッジ版Rubyをビルドしたり、Hello Worldより複雑なアプリケーションでプレビューリリースを使ってみたりする開発者はめったにいません。
そしてRuby 2.7には大きなエクスペリメンタル機能が入りました。言わずとしれたパターンマッチングです。アプリケーション開発者やライブラリ開発者は、「エクスペリメンタル」という言葉を見ると一気に警戒を強めます。本質的には、実験が失敗すればかなりの量のリファクタリングが必要になるというリスクはあります(refinementが導入されたときのことを覚えてますか?)。結果を精査し、その機能を促進するか取り消すかを決めるのに必要な「実験データ」を十分揃えられるでしょうか?
つまり、もっと多くの人を実験に巻き込む必要があるのです。
現時点では、Ruby言語そのものの開発に携わる人や熱狂的なRubyハッカーのほとんどは、ruby/rubyのmasterブランチを追いかけてissueトラッキングシステムにあがった提案について議論しています。
さまざまなバックグラウンドやプログラミングスキルを備えたRuby開発者をもっとたくさん募って、フィードバックを集められないものでしょうか?
ここで再びフロントエンド開発界隈に目を向けてみたいと思います。
JavaScript(正確にはECMAScriptですね)の仕様はTC39グループによって進められています。このグループにはJavaScriptの開発者や実装者、学術関係者などが集結し、JavaScriptの定義をメンテナンスしたり進化させるための「コミュニティとの共同作業」を推し進めています。
同グループでの新機能導入プロセスは、十分に定義された「ステージ」に沿って進められます。成熟度(maturity)には「Proposa(提案)l」「Draft(ドラフト)」「Candidate(候補)」「Finished(完成)」という4つのステージがあり、末尾のFinishedに達した機能だけが仕様に収録されます。
ProposalステージやDraftステージの機能はエクスペリメンタルとみなされます。こうしたエクスペリメンタルな機能を取り込むうえで特に重要な役割を演じているツールがひとつあります。それがBabelです。
随分前から、Draftステージが受け入れられるのに必要な要件に「機能には2種類の実装が必要である。ただし実装の一方はBabelなどのトランスパイラにあってもよい。」という一文が含まれています。
すなわち、エクスペリメンタル機能の調査にトランスパイラを活用できるということです。
Babelの例は、トランスパイラを活用した調査がきわめて効果的なアプローチであることを如実に示しています。
そこで提案したいのですが、Ruby言語の開発でもこれと同じようなアプローチを採用してみてはどうでしょう?「マージか取り消しか」の二者択一ではなく、「トランスパイラのユーザーから広くフィードバックを集め、それを元に機能を受け入れる」というプロセスがあってもよいのではないでしょうか。
Ruby Nextは、Rubyを未来に向けて前進させる、そんなトランスパイラを目指しています。
最近、自分のプロジェクトでまたRuby Nextを使い始めています(Ruby gem向けのanyway_configやmruby向けのACLIをご覧ください)。プロジェクトは既にエクスペリメンタルの段階を過ぎていますが、オープンソースとしての旅はまだ始まったばかりです。
Ruby Next(そしてRubyの新機能)を手っ取り早く試す最も簡単な方法は、以下のようにrubyコマンドで-ruby-nextオプションを指定することです。
$ ruby -v
2.5.3p105
# 以下のgemをインストールしておくこと
$ gem install ruby-next
$ ruby -ruby-next -e "
def greet(val) =
case val
in hello: hello if hello =~ /human/i
'🙂'
in hello: 'martian'
'👽'
end
greet(hello: 'martian') => greeting
puts greeting
"
👽
ご覧のように、Ruby Nextでは既にendレスメソッド定義(#16746)や右代入(#15921)という2つのエクスペリメンタル機能をサポートしています。これらの機能が果たして3.0まで生き延びられるかどうかについて私からは何とも言えませんが、皆さんにもRuby Nextでぜひこれらの機能を試してRubyコアチームにフィードバックしていただければと思います。いかがでしょう?
私は、Ruby Nextが新機能の採用や言語の進化で重要な役割を果たして欲しいと願っています。今なら、皆さんのライブラリ開発やアプリケーション開発でRuby Nextを使うことで、そうした未来に一歩踏み出せるのです。私のアイデアについてのご意見がありましたら、肯定否定を問わずぜひお気軽にコメントをどうぞ。
もちろん、アプリケーション開発で私たちがお力添えできることがありましたら、ぜひEvil Martiansの問い合わせフォームまでお気軽にお問い合わせください。
Evil Martiansでは外宇宙流の製品開発よろずご相談承ります。
おたより発掘
RubyNextなんてものがあるのか!!
会社やめるとき3000万PVあるサービスのメジャーアップデートを一人でやって去ったんだけどメンタル的にすごいしんどかった。ライブラリの互換性が保証されてなくて一つでもミスったら終わるという地獄https://t.co/4iTjqyzb8A— ケイゴ (@keigorian0331) May 20, 2020
polyfillとして使ったり後方バージョンにコード変換できるruby-nextというgemがあるのか。ECMAScriptのような言語の進化プロセスの可能性にも言及していて面白い / “Ruby NextトランスパイラでRubyの新機能を使おう(翻訳)|TechRacho(テックラッチョ)〜エンジニアの「…” https://t.co/G9eSwlVdbC
— ohbarye (@ohbarye) May 21, 2020