追記(2023/10/03)
YARPはその後「prism」と名前が変わりました。
参考: Rename YARP to prism by kddnewton · Pull Request #1602 · ruby/prism

追記(2024/02/08)
同じくKevin NewtonさんによるRuby 3.3のPrism解説記事もどうぞ↓。
Rubyパーサーを一新するprism(旧YARP)プロジェクトの全容と将来(翻訳)
私たちShopifyは、昨年を新しいRubyパーサーの作成に費やしました。このパーサーはYARP(Yet Another Ruby Parserの略)と呼ばれています。

本記事執筆時点のYARPは、「Shopifyのメインコードベース」「GitHubのメインコードベース」「CRuby」「rubygems.orgのダウンロード数上位100の人気gem」のあらゆるRubyファイルの解析で意味的に同等の構文木(syntax tree)を得られました。この度承認を受けてYARPがCRubyにマージされたので、晴れてコミュニティにこの成果を共有したいと思います。本記事では、この作業を行った動機、開発方法、そして今後の展望についてお話しいたします。
パーサーの概念やRubyへの適用方法に詳しくない方向けに、本記事末尾の背景知識セクションでこのあたりを解説していますので、合わせてご覧いただくことで読みやすくなると思います。
🔗 開発の動機
現在のCRubyパーサーには、長い間解決が望まれている問題がいくつも残されています。問題は、おおまかに「メンテナンス性」「エラー許容性」「移植性」「パフォーマンス」の4つに分類できます。それぞれについて以下で詳しく見ていくことにします。
🔗 メンテナンス性
メンテナンス性のほとんどは主観に支配されているので、少なくとも客観的な測定が非常に困難です。メンテナンス性は、以下のように多くの要素に分類できます。これらについて順に見ていくことにします。
- コードの読みやすさと理解のしやすさ
- コードへの貢献のしやすさ
- コードの変更しやすさ
- コードのドキュメント作成
- コードのテストのしやすさ
実は、現在のCRubyに対応するドキュメントは皆無です。設計のドキュメント化は、2002年のRubyソースコード完全解説1や2013年のRuby Under A Microscope(邦題: Rubyのしくみ)などの外部プロジェクトで試みられてきました。そうした数十年にわたる取り組みを別にすれば、現状で選べる最善の機会は1万4千行にもおよぶparse.yファイルを読んで理解することです。言うまでもありませんが、parse.yファイルを読んで理解する作業は非常に難易度が高く、万人がそうするべきとは思えません。
パーサーがこれほど複雑なので、変更するのも一苦労です。たとえば2か月前に出されたバグレポート#19392では、def test = puts("foo") and puts("bar")がまったく期待通りに動かないことが発見されました。このバグを修正しようとすると、パーサーの構造上どうやっても他のコードが壊れてしまいます。これは生成された(=手書きでない)パーサーにありがちな問題で、一見シンプルな変更であっても甚大な影響をもたらす可能性があるのです。
Rubyのコントリビュータリストに既存のパーサーをメンテナンスしている人がほんの一握りしかいないのも無理はありません。パーサーの25年の歴史において、コントリビュータは総勢わずか65名で、その中でコミット回数が10回を超えているのは13名です。昨年パーサーにコントリビュートした人もわずか9名で、コミット数が10回を超えたのはたった2名です。
メンテナンス性はオープンソースの中核であるにもかかわらず、私たちを取り巻く状況にはメンテナンス可能なパーサーが存在していないのです。
🔗 エラー許容性
エラー許容性(error tolerance)とは、パーサーで構文エラーが発生してもパーサーがそこで止まらずに解析を継続できる能力のことです。言い換えれば、パーサーがエラーを許容するようになることで、構文エラーが存在していても構文木の生成を続行できるようになります。
エラー許容性が重要な理由はたくさんあります。エディタやLanguage Server、Sorbetやsteepなどの型チェッカは、編集中または解析中のコードに関する正確なメタデータ(型、引数、スコープなど)を提供するためにパーサーに依存しています。パーサーがエラーを許容しないと、最初の構文エラーが発生した時点で中途半端なメタデータをダンプしてしまいます。そのため、パーサーを利用する側は、足りないメタデータを補完して状態を安定させるためにリトライしなければならなくなりますが、これはエラーになりやすく難しい作業です。
Ruby 3.2でCRubyのパーサーにいくつかのエラー許容性が取り入れられたものの、システマチックな方法論からはほど遠いものです。つまり、どんなにささいな構文エラーであっても、パーサーがそれを踏んだ途端に構文木の生成が失敗してしまいます。さらにファイルに構文エラーが複数あると(多くの場合コピペが原因でしょう)、最終的には1つずつ解決して先に進むしかないので、作業が非常に遅くなってしまいます。サイクルが遅くなれば開発者がいらつくようになり、Rubyが掲げる「開発者の幸せ」という理念にもとることになります。
たとえば、エディタがエラーを1度に1個ずつしか表示できなければどうなるかを考えてみましょう。エラーを潰してもまた次のエラーが出現することになり、開発者の時間が無駄になってストレスが溜まってしまうでしょう。以下のスニペットがあるとします。
class Foo
def initialize(a: 1, b = 2)
true &&
end
上のソースコードには構文エラーが3箇所あります(パラメータの順序、&&の右に式がない、endの脱落)。現在は、構文エラーに使われるruby -cを実行すると以下の結果が出力されます。
test.rb: test.rb:2: syntax error, unexpected local variable or method (SyntaxError)
def initialize(a: 1, b = 2)
^
test.rb:4: syntax error, unexpected `end'
end
^~~
ここでは問題1についての指摘はあるものの、問題2の指摘は的外れで紛らわしく、問題3にいたっては何も指摘がありません。
そういうわけで、YARPでは最初からエラー許容性を取り入れたいと考えており、設計のあらゆるレベルでエラー許容性が考慮されています。
🔗 移植性
移植性(portability)は、CRuby以外のコードベースでもパーサーを利用できる能力を指します。現在のパーサーはCRuby内部と強く癒着しているので、必要なデータ構造や機能を利用できるのはCRubyのコードベースに限られています。そのため、他のツールではCRubyのパーサーを利用できません。
その結果、コミュニティが分かれて多くのソリューションが開発されてしまい、それぞれ独自の問題を抱えています。ほとんどのパーサーが、(手書きではなく)文法ファイルから新しいパーサーを生成する形で長い間書かれてきました。私たちの調べたところでは、パーサーを書くのに使われた言語は9種類もあります。あるものは学術論文に掲載される形で、またあるものはproductionシステムに導入される形で独自の路線を進みました。本記事執筆時点では、活発にメンテナンスされているのは以下の12個であることが判明しています(うち6個はランタイム、6個はツール)。
- CRuby
- mruby
- JRuby
- TruffleRuby
- ruruby
- natalie
- Ripper
- parser
- ruby_parser
- tree-sitter-ruby
- Sorbet
- lib-ruby-parser
リファレンス実装以外のパーサーは、どれも独自の問題を抱えています。つまり、これらのパーサーを継承して構築された以下のようなツールも同じ問題に苦しむことになり、問題がツール全体に広がってしまいます。
Ripperをベースにしたツール- Syntax Tree、rubyfmt、rufo、syntax_suggest、ruby-lspなど
parsergemをベースにしたツール- rubocop、standard、unparser、ruby-next、solargraph、steepなど
ruby_parsergemをベースにしたツール- debride、flay、flog、fastererなど
これは明らかに最適とは言えません。Rubyに新しい構文が導入されるたびに、これらのパーサーもすべてアップデートしなければなりません。その分バグも発生しやすくなり、パーサーを使うツール全体も影響を受けることになります。
たとえば、4年前にRuby 2.7がリリースされたときにパターンマッチング構文が導入されました。CRubyを除いた10種類のパーサーのうち、現在パターンマッチングをサポートしているのはわずか5種類であり、問題が発生していないのはたった2種類です。
これらのパーサーをCRubyのパーサーに合わせて最新に保つためには、parse.yのあらゆる変更を見逃さないように注意深くウォッチして、自分たちの言語やランタイムで再現しなければなりません。現状の作業では多くの開発者が途方もない労力を注ぎ込むことになります。これは、メンテナンスや改善を単一のパーサーで行えればしなくても済んだはずの作業です。
移植性は、構文木の使いやすさにも直結します。パーサーから構文木の抽出に成功したとしても、構文木が現在のランタイムに密結合していれば移植できません。このトピックについては、YARPツリーの設計を解説するときに再度取り上げます。
🔗 パフォーマンス
CPUやCコンパイラは長年にわたって、パイプライン化、関数のインライン化、分岐予測などの技術によって目覚ましく改善されています。残念ながら、ほとんどのパーサージェネレータが生成するパーサーは、そうした技術を適用するのが困難です。生成されるパーサーのほとんどは、ジャンプテーブルやgoto文の組み合わせで動作しているため、より高度な最適化技術が通用しなくなってしまいます。そのため、(手書きではなく)生成されるパーサーには、超えることが極めて難しいパフォーマンス上の壁が立ちはだかっており、これを克服するには並々ならぬ努力が必要です。
🔗 パーサーを開発する
以上の問題と動機を踏まえて、私たちは昨年5月にソリューションの設計をスタートしました。ほどなく、完全に書き直すとなると作業量が膨大になるものの、これまで特定された問題は先送りにせずにすべて対処しなければならないことが明らかになりました。そこで、後に「もうひとつのRubyパーサー」と呼ばれるパーサーの設計に本格的に取り組みました。
🔗 設計
最初に、プロジェクト用の設計文書を作成しました(これは現在もGoogle Documentsで参照できます)。私たちは、MatzやCRubyチーム、JRubyやTruffleRubyのチーム、そして私たちが把握する限り多くのツールgem(特にparserやirb)のメンテナーたちと打ち合わせる前に、この文書を共有しました。
これらの議論から、さらに重要な「設計上の決定事項」が浮かび上がってきました。そのいくつかを以下に記します。MatzとCRubyチームがこの設計に満足したことで、手法についての合意が取れ、YARPの準備が整い次第マージすることが決定されて、本格的な作業が開始されました。
🔗 実装言語の選定
パーサーはC言語で書きます。実装言語については活発な議論が行われましたが、最終的にC言語に落ち着きました。相互運用性についてはC++やRustといったさまざまなオプションが検討されました(Wasmによるクロスコンパイルすら検討されていました)。
この決定に落ち着いた理由は2つあります。1つは技術的な理由で、パーサーはCコンパイラが使えるあらゆるプラットフォームをターゲットにすべきというものです。2つ目は人的な理由で、RubyパーサーのメンテナンスはCRubyチームがメンテナンスする予定ですが、このチームはC言語で開発しているグループです。私たちの主要な目的のひとつがメンテナンス性であり、実際にメンテナンスを行うグループが快適に使える言語にするのが合理的でした。
🔗 パーサーの構造
使うパーサーは手書きの再帰下降(recursive descent)パーサー2です。メジャーなプログラミング言語の大半がこのトレンドに乗っています。開発者が使うトップ10言語のうち、7言語が手書きの再帰下降方式を採用しています。同様に多くのツールもBisonから手書きに乗り換えています(例: gccやGo言語)。C#がこの方式を使うことを決定した理由についてもHacker Newsのエントリで見られます。
手書きの再帰下降方式を例外的に採用していない言語が3つあります。すなわちPython、PHP、Rubyです。現在のPHPとRubyはBisonを使っていますが、Pythonは最近PEGパーサー3と呼ばれる別の再帰下降方式に乗り換えました(詳しくはPEP-617を参照)。Pythonのこの記事でひときわ興味深い点は、Rubyの歴史において回避しなければならなかった曖昧さの一部が垣間見えることです。例として、以下のスニペットが引用されています。
with (
open("a_really_long_foo") as foo,
open("a_really_long_baz") as baz,
open("a_really_long_bar") as bar
):
実はこの文法は、LL(1)解析(Pythonで生成しているパーサーのスタイル)を用いるコンテキストマネージャで表現することは不可能なのです。その理由は、この文脈では開き丸かっこ(が曖昧になるからです。Pythonではこれを回避するために、文法の曖昧さをあえて増やし、ツリービルダで実際の文法を強制したのです。
Rubyよりも歴史の長い言語がBisonを廃止するのは、少しも驚くことではありません。Bisonは文脈自由文法(context-free grammar)4用のパーサーを生成するためのツールです。この言語クラスでは、あらゆる個別の文法規則を決定性に基づいてトークン集合に還元可能です。
しかしRubyの文法は(Pythonもそうだったように)、正しく解析するためにかなりの量のコンテキストが不可欠であり、文法の集合は(文脈自由ではなく)文脈依存(context-sensitive)と呼ばれるものになります。CRubyでは、利用可能なパーサーをBisonで生成するために大量のコンテキストやロジックやステートがlexerに送り込まれます。すなわち、解析するステートの集合がすべて揃っていないと、Rubyコードを精密に字句解析できないのです。
キングス・カレッジ・ロンドンのLaurence Tratt教授は、これについて詳細に調査しました。教授による成果は、今年のRubyKaigiで3回も引用されました。The future vision of Ruby Parser、Parsing RBS、そして私たちのYARPです。以下は、1番目の発表で引用された教授の論文の第2パラグラフです。
特定の言語では、エラー復帰アルゴリズムを手書きすることが可能である。これによってエラーからの復帰が全般に改善されるが、作るのは難しい。
次に同教授は、LR解析5と再帰下降解析を比較するブログ記事で以下のように述べています。
既存の言語は多くの場合、LR文法を指定することを困難または不可能にする方向に進化してきた。この流れに逆らおうとしても勝ち目はないので、おとなしく再帰下降解析を使うこと。
および
エラー復帰で期待できるパフォーマンスを最大化する必要があるなら、再帰下降解析がベストチョイスである。
現実には、lexerにステートを大量に保存しなければ、LRパーサー(Bisonで生成するタイプのパーサー)によるRuby文法解析は正確になりません。ほとんどのプログラミングコミュニティは自分たちの言語のパーサーについて同様の結論を下して、手書きの再帰下降パーサーに移行しています。Rubyも同じ道を進むべきときが来たのです。
手書きの再帰下降パーサーに乗り換える最後の理由は、実はMatz本人によるものです。1995年にリリースされたRuby 0.95のリポジトリには小さなToDoファイルがあるのですが、そこにこんな項目があったのです。
- 手書きパーサー(再帰降下)
🔗 API/AST
私たちは当初、混乱を最小限に留めるため、構文木をCRubyと同じにするつもりでした。しかし多くのランタイムチームやツールチームと議論を重ねた結果、独自の構文木をゼロから設計することに決まりました。この構文木は、ランタイムとツールのどちらとも調和しやすくなるよう、そして今後のメンテナンスや拡張を楽に行えるように設計されました。
CRubyの現在の構文木には、利用側にとって無意味な情報があるかと思えば、肝心な情報が入っていないこともあります。たとえばvcallはローカル変数またはメソッド呼び出しのいずれかを表す識別子ですが、これはパーサーが気にすべきことです。しかしこれは解析時に解決済みになるにもかかわらず、RipperのAPIに露出し続けて混乱の元になります。逆に、linterやエディタで重要な位置情報(=行頭から何文字目かを表す)が構文木にほとんど含まれていません。
私たちは構文木を再設計するとともに、JRubyチームやTruffleRubyチームとも密に連携してシリアライズAPIを開発しました。このAPIによって、ランタイムはFFI(Foreign Function Interface: 外部関数インターフェイス)呼び出しを1回行えばシリアライズ済みの構文木を取得できるようにします。シリアライズ済み構文木を取得できれば、私たちの構造化ドキュメントを介して、それをデシリアライズしてオブジェクトにするJavaクラスを生成可能になります。このオブジェクトは、独自のツリーや中間表現のビルドに利用できます。
構文木の再設計は、本プロジェクトで非常に重要度が高い作業のひとつでした。これによって、Rubyにこれまで存在していなかった「標準化された構文木」が提供されました。標準が確立されたことで、コミュニティがRubyの構造を議論するための知識や情報を集約できるようになり、そしてRubyのあらゆる実装で利用できるツールの構築も可能になったのです。これによって、今後ツール同士のコラボ(RuboCopとSyntax Treeなど)や、メンテナーやコントリビュータ間のコラボも盛んになることが見込めます。
🔗 パーサーの構築
設計が固まったところで実装に取りかかりました。実装を開始してすぐに、「詳細なテストスイートを十分な個数揃えること」が最大の難関であることが判明しました。独自の構文木であるがゆえに、既存のテストスイートではテストできなかったのです。
幸い、lexerの出力を既存のlexerのものと揃える形で実装していたので、私たちのパーサーが出力したトークンが既存のlexerと一致するかどうかのテストを実行できました。この方法によって、Shopifyのモノリスでlexerの出力と100%同等になるまで作業が少しずつ進みました。100%に達したら、次はruby/ruby、rails/rails、そして多くの巨大コードベースで同様に作業しました。最終的に、rubygems.orgのダウンロード数トップ100 gemもダウンロードしました。
この作業中に、ありとあらゆる困難に直面しました(特に文法の曖昧さに関連する問題)。このあたりに関心のある方向けの寄り道コースとして、本記事末尾の「困難な点」セクションでRubyのエキセントリックな側面について詳しく解説しています。
🔗 メンテナンス性
本記事冒頭でも述べたように、私たちはメンテナンス性の問題を中心に据えたいと思っていました。それによってこのパーサーが可能な限りメンテ可能になり、構文木のあらゆるノードがサンプル付きでドキュメント化され、明示的にテスト可能になります。このドキュメントは以下で参照できます。
参考: yarp/config.yml at main · ruby/yarp · GitHub
さらに、多くの設計ドキュメントをmarkdown化したものも以下で参照できます。
参考: yarp/docs at main · ruby/yarp · GitHub
最後に、以下のように豊富なインラインコメントも可能な限りコード内に記述してあります。
参考: yarp/src/yarp.c at fc9ee8f566f71ed76a53d58e2b036aeaf39415fd · ruby/yarp
今年始めにこのリポジトリをオープンソースとして公開して以来、ありがたいことに総勢31名ものコントリビュータがパーサーにコードを追加してくれました。今後さらに貢献しやすくするために、コントリビューションガイドの改善作業に取り組んでいるところです。
🔗 エラー許容性
YARPには多くのエラー許容機能がすぐ使える形で組み込まれており、今後もさらに多くの機能を追加する予定です。
開発者がエディタの編集画面でソースコードを入力するとき、式を最後まで入力し終わるまでは、ほぼ確実に何らかの構文エラーが存在するものです。そのため、有効なプログラムにあるはずのトークンやノードが入力完了まで欠落していることは珍しくありません。
そういうわけで、私たちが最初に構築したエラー許容機能は、不足しているトークンを挿入する機能でした。たとえば、本来あるはずのendキーワードが欠落している部分にパーサーがさしかかると、足りないトークンを自動的に補ってプログラムの構文解析(parse)を続行します。
YARPは、構文木で不足しているノードも補います。たとえば1 +のように、式の右辺が脱落している部分にパーサーがさしかかると、右辺用のノードを自動的に補ってプログラムの構文解析を続行します。
さらに、トークンがあるはずのないコンテキストにトークンが存在している部分にYARPがさしかかると、そのトークンをスキップして構文解析の続行を試みます。これは、コードをコピペしたときにうっかり周りの余分なものが紛れ込んでしまった場合に便利です。
最後に、YARPには「コンテキストベースの復旧」と呼ばれる手法も含まれており、エラー発生箇所のコンテキストを分析することで構文エラーから復旧できるようになります。これと似たものが、Microsoftが独自開発したPHPパーサーでも採用されています。
foo.bar(baz, qux1 + qux2 + qux3 +)
上のコードでは、引数リストが)で閉じていることをYARPが認識するので、qux3の後ろの+の部分で欠落しているノードを補ってから、すべての引数を構文解析します。そこから先は、引数に何も問題がなかったかのように構文解析を続行します。
以上の機能がすべて合わさると、YARPがLanguage Serverを経由して、冒頭のスニペットファイル内のすべてのエラー箇所に以下のように赤いアンダーラインを表示するようになります。
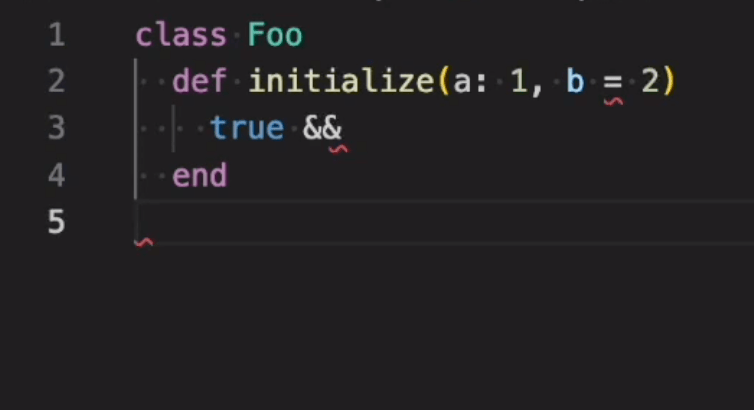
エラー許容について今後も追求したい点はまだまだありますが、現状のパーサーについては満足しています。エラー許容の動作を実際に見てみたい方は、YARPに同梱されているLanguage ServerとVSCodeプラグインでお試しいただけます。動作方法についての解説を読んでみると、エラー許容機能のおかげでエディタに複数のエラー箇所が「同時に」表示されていることに気づくでしょう。
🔗 移植性
YARPは、外部のパッケージ/関数/構造に依存していません。言い換えれば完全に自己完結しているので、単体でビルドして任意のツールで利用できます。つまり、優秀なFFIやbindgenを備えている言語なら、そこから構文解析関数に直接アクセスして構造を直接取得できるということです。さらに、今後RustやZigなどの言語でも最小限の手間でRuby用ツールを構築可能になるということでもあります。
言語にこのサポートがない場合や、C関数呼び出しのコストが高い場合のために、別途シリアライズAPIも提供しています。このAPIは、最初に構文木を解析して内部構造に変換してから、呼び出し元の言語やツールで読み取れるバイナリ形式にシリアライズします。このAPIは特にJRubyやTruffleRubyを念頭に置いて設計されていて、両チームのメンバーも活発に開発を支援しています。
現時点で、JRubyには実際に動作するプロトタイプが存在しており、TruffleRubyもYARPをマージしました(#2768)。この作業中に、YARPのデシリアライズが構文解析よりも10倍程度高速であるという興味深い発見がなされました。今後、TruffleRubyで起動を高速化するために標準ライブラリのシリアライズ版を提供する可能性もあります。
C言語APIとシリアライズAPIの両方が取り入れられたことで、あらゆるRuby実装で共通して利用可能な標準ツールを構築可能になり、Rubyの構文木について議論するための共通言語をコミュニティが開発することも可能になったのです。今後、上述したすべてのツールが同じパーサー基盤上で動作する時代が到来する可能性も見えています。
私たちは、この成果が技術力の勝利の賜物であることにも大いに満足していますが、さらに嬉しいのは、これがコミュニティの力がもたらした勝利でもある点です。これまで個別のパーサーをメンテするのに時間を取られていた凄腕の開発者たちが全員解放されたことで、自分たちのツールを改良することに投資できるようになったのです。パーサーのコードに注がれる視線が増え、パーサーでエラーが発生したときのバグ修正を支援する人も増え、より多くの人が新機能追加を支援できるようになります。
🔗 パフォーマンス
パーサーが意味的に同等の構文木を生成可能になったので、次はパフォーマンスに着目しました。新しい構文木が従来のものと違っているうえ、従来よりも実行できる機能が増えた(例: stringノードでエスケープなしの文字列を提供してYARP利用側の利便性を図る)ので、比較に適したデータが見当たりません。
現時点でお伝えできるのは、YARPはShopifyにある約50,000ものRubyファイルの構文解析を4.49秒程度で完了できることと、そのときのメモリフットプリントのピークが10.94 Mbであるということです。言うまでもなく、私たちはここまでの結果に大興奮しています。
今後はパフォーマンスが最優先事項となる予定で、私たちが実験を重ねてきた多くの最適化も既に行われています。こうした最適化の中には、構文木のノードに特化したメモリ使用量の削減や、アリーナ(arena)アロケーションによる局所性の向上、より高速なハッシュ探索による識別子解決の高速化などがあります。
🔗 統合
YARPがシンプルな式を構文解析できるようになった時点で、他のランタイムやツールとの統合を行う形で私たちの手法や設計を検証したいと考えました。
JRubyチームとTruffleRubyチームはシリアライズAPIの実験を開始し、私たちも両チームのニーズを満たすべく共同で取り組みました。いくつかの興味深い微調整(可変長整数のシリアライズ、定数プールの提供などの最適化)を経て、両チームのニーズに合うフォーマットを見出しました。今ではどちらもチームも、YARPを自分たちのランタイムに統合する作業に大きな力を注いでおり、OracleはTruffleRubyのメインパーサーをYARPにするための専任開発者たちをフルタイムで割り当てています。
私たちは他のツールとも連携して、静的解析やコンパイルに必要なメタデータが構文木に揃っているかどうかを検証しました。

Syntax Treeは、フォーマッタとしても利用可能な構文木ツールスイートで、Ripperの代わりにYARPを用いて実行する実験用ブランチもあります。初期の結果では、RipperをYARPに置き換えたことでパフォーマンスが2倍近く上昇したケースがいくつか見られました。また、このリポジトリには私たちが構築したVSCodeプラグインもあり、エラーの発生箇所やメッセージが正しいかどうかの検証に使われています。このプラグインの開発は現在も継続しています。
最近の私たちは、parser gemやruby_parser gemと同じ構文木を生成する実験を手がけ始めています。目的は、これらのライブラリの利用者側が新しいパーサーのメリットをシームレスに享受できるようにするためです。初期の結果は非常に有望で、どちらのgemでもメモリ使用量の削減と速度向上が見られました。
そして先週、ついにYARPをCRubyリポジトリにミラーリングして、CRuby内でのビルドや、CRubyと同じテストスイートやCIを実行可能にする作業を開始しました。これはYARPをCRubyにマージする最後のステップであり、私たちはマージを実現する作業で大変盛り上がっています。後数日もすれば作業は完了するでしょう6。
🔗 今後の道筋
このようにしてYARPは現在の姿となり、今後の道筋も示されました。YARPをさまざまなRubyランタイムと統合する作業は今も続けられており、今後さらに多くのプロジェクト(mrubyやSorbetなど)でも試してみたいと思います。速度、メモリ消費、精度についての作業は今後も続けます。MatzとCRubyチームは、今年12月にリリース予定のRuby 3.3で、YARPをライブラリとして提供することに合意しました。つまり、次期バージョンのRubyでrequire "yarp"と書けば構文木をさまざまに操作できるようになるのです。この興奮をかきたてるリリースの前に、他にもいくつかのことが行われるでしょう。
- サードパーティがこれを用いて自分たちのプロジェクトに統合できるように、このプロジェクトをgemとしてリリースする予定があります。
- JRubyチームやTruffleRubyチームと引き続き協力して、構文木の構造やシリアライズAPIが両チームのニーズを満たすよう作業します。近いうちに、両チームの言語ランタイムにYARPがメインパーサーとして取り入れられる形でリリースできればと思います。
- Syntax TreeライブラリはメインパーサーとしてYARPを採用する予定です。つまり、ruby-lspでもそのメリットを全面的に享受できるようになります。
- Ripperライブラリとの互換性を引き続き改善し、(不安定であることを自ら認めている)RipperのAPIに依存する他のライブラリが、移行手段として私たちが提供する互換性レイヤを利用できるようにします。
YARP自体がCRubyにマージされた後も、さまざまな作業が計画されています。以下はその一部ですが、もちろんこれだけに留まりません。
- 前方スキャン(forward scanning)によるエラー許容: パーサーが複数の解釈が可能になるような場所でエラーが発生した場合、可能な解釈方法のすべてについて数トークン先に進めて、構文エラーが最も少ない解釈を受け入れるという方法が考えられます。
- アリーナアロケーション: 現在のノードは個別の
malloc呼び出しでアロケーションされますが、コストが高くなってメモリが断片化したりメモリの局所性が失われる可能性があります。 - メモリ使用量: 私たちは全般に構文木をメモリ上で比較的小さく保っていますが、冗長な情報を除去したりメモリ上の構文木サイズを全般的に削減したりする余地は常に残されています。
- パフォーマンス: 明らかにこれは大きなトピックですが、CRubyとの同等性を達成できたので、パフォーマンス向上方法の検討を始められるようになりました。
🔗 まとめ
全体として、私たちはこのプロジェクトの作業と、そこから見えるRubyツールの未来に大興奮しています。皆さんがこれで何かを作るところを早く見たくてたまりません!ご質問がおありの方や、または自分も参加してみようかなとお思いの方は、GitHubまたは私のTwitterまでお気軽にお知らせください!
🔗 付録
背景知識についてもっと詳しく知りたい方向けに、以下に補足情報を置いておきます。
🔗 背景知識
パーサー(parser: 構文解析器)はプログラミング言語の一部であり、ソースコードを読み取って、ランタイムが理解できる形式に変換する役割を担っています。パーサーの高レベルな役割には、プログラムの流れを表す木構造の作成も含まれます。
ソースコードには、しばしば「インデント」の形で木構造が表れることがあります。たとえば、以下のコードスニペットを見てみましょう。
def foo
bar
end
defはトップレベルのノードです。このノードにはfooという名前などさまざまな属性が含まれます。
トップレベルの子ノードにはstatementsがあります。statementsの本体にはステートメントのリストがあります。この場合、最初のステートメントはcallノードであり、これはメソッド名としてbarを持ちます。
パーサーの責務は、このようなノードを作成して木構造を構築してから、実行するためにプログラミング言語の他の場所に渡すことです。CRubyの場合、パーサーはYARV(Yet Another Ruby Virtual Machine)という仮想マシンに渡すための構文木を生成する責務を担っています。コンパイルが終わって生成されたコードは、実行に使われます。
構文木を生成する最初のステップは、ソースコードを切り分けて個別のトークンにすることです。この処理はトークン化(tokenization)というふさわしい名前で呼ばれます。Rubyの場合は、ソースコードから以下のようなトークンを見つけ出します。
- 演算子(
~、+、**、...など) - キーワード(
do、for、BEGIN、__FILE__など) - 数値(
1、0b01、5.5e-5など) - その他
これらのトークンは遅延評価されます。その理由は、トークンの意味(例: fooという識別子が単なるメソッド呼び出しなのか、ローカル変数なのか、場合によってはシンボルなのか)を決定するには膨大なコンテキストが必要だからです。これは、パーサーが必要に応じて取り出せるトークンのストリームと考えるとよいでしょう。
構文木を生成する次のステップは、トークンに文法(grammar)を適用してトークンを分析することです。文法とは、プログラムが有効になる形でトークンの組み合わせ方を定義するルールの集合です。
たとえば、「プログラムとは、ステートメントのリストである」「ステートメントとは、メソッド定義、メソッド呼び出し、または定数定義である」という文法があるとしましょう。この文法では、トークン同士を組み合わせる順序も指定できます。
たとえば、メソッド定義はdefキーワードで始まり、その後ろに識別子、引数リスト、メソッド本体が続き、最後にendキーワードを置きます。これを生成規則(production rule)と呼びます。
文法が適用されて曖昧な点がすべて解決されると、最終的に構文木が構築されます。次に、この構文木が仮想マシンに渡されて、コンパイルおよび実行されます。
CRubyのパーサーは、これまでBisonというツールで生成されていました。Bisonは、LRパーサー(left-to-rigt、右端導出)を生成するパーサージェネレータです。Bisonに文法ファイル(CRubyの場合はparse.y)を渡すと、C言語によるパーサー(parse.c)を生成します。重要な点は、Bisonでは上述のトークンストリームが不可欠であることです。
トークンストリームを生成するツールはいろいろありますが、これまでCRubyでは手書きのlexerが使われていました。このlexerは、ソースコードをトークン化し、必要に応じてトークンを(yylex関数で)Bisonに渡す役目を担っています。
🔗 困難な点
🔗 演算子とキーワード
*という演算子は、乗算を意味することもあればsplat演算子を意味することもあります。さらに、*演算子とオペランドの間にスペースがいくつあるかでも意味が変わることがあります。
同様に、...はrangeを意味することもあれば、引数のforwardを意味することもあります。
doキーワードは、ブロック(foo do end)、lambda(-> do end)、ループ(while foo do end)などさまざまなコンテキストで使われます。
どの演算子やキーワードを選択するかの決定は、さまざまな要素に依存しているのですが、どれについてもドキュメントが皆無だったのです。
🔗 終端子(terminator)
Rubyの式は、ほとんどのコンテキストで、改行やコメントやセミコロンで区切られますが、そうでない場合もあるのです。改行を無視すべきかどうかを決定するために、多くのステートをトラッキングしています。
たとえば以下のコードでは改行が無視され、1はbar:ラベルに関連付けられます。
{ bar:
1 }
しかし以下のコードでは、bar:の後ろの改行は無視されず、1はfooメソッドにおける唯一のステートメントになります。
def foo bar:
1
end
🔗 ローカル変数
メソッド呼び出しの丸かっこ()は省略可能なので、指定された識別子がローカル変数なのかメソッド呼び出しなのかを見分けるのが難しくなることがあります。
たとえば、以下のコードではaというメソッド呼び出しに正規表現を引数として渡していると解釈される可能性もあれば、a/bという除算と解釈される可能性もあります。
a /b#/
この違いは、aがローカル変数かどうかによって変わります(もっとエキセントリックな例についてはTRICK 2022の強烈なエントリをご覧ください)。この曖昧さのせいで、Rubyパーサーはローカル変数の解決を構文解析中に行わなければなりません。
🔗 正規表現
「正規表現は終端子までスキップして構わないのだから、正規表現の構文解析は別に難しくないよね」とお思いかもしれません。しかし、終端子は1種類ではなく、さまざまな終端子のどれかが使われる可能性もあるのです。
たとえば%r{foo}という正規表現なら、次の}はすぐ見つけられるので難しくありません。しかし残念ながら、正規表現は(他の%系リテラルと同様に)開始と終了の終端子を揃える形になります。つまり、%r{foo {}}という正規表現が有効なのは、パーサーが{文字と}文字の出現回数をトラッキングしているからなのです。
厄介なのは、正規表現が現在のスコープにローカル変数を導入する場合もあることです。たとえば、/(?<foo>.*)/ =~ barと書くとfooというローカル変数が導入され、ここには名前付きキャプチャグループとマッチする文字列が入ります。つまり、ローカル変数で複雑になった正規表現を正しく構文解析するために、Rubyは正規表現パーサーも提供しなければならなかったのです(CRubyにはOnigmoパーサーが埋め込まれているので作業をOnigmoに丸投げしていますが、既に述べたように外部に依存したくありませんでした)。
🔗 エンコーディング
CRubyは、ソースコードファイルのエンコードがUTF-8であることを前提としていますが、ファイルの冒頭にマジックコメントを追加することで変更可能になっています。パーサーはこうしたマジックコメントを理解して以後の識別子をすべて新しいエンコードに切り替える責務も負っています。これは、たとえば定数なのかローカル変数なのかを決定したりするうえで重要です。
CRubyは、実は90ものエンコーディングを扱っています(Ruby 3.3の時点)が、これらはダミーエンコーディングではなく「ASCII互換」と呼ばれるものであり、ソースファイルのエンコーディングオプションとして利用可能になっています。YARPではその中から最も広く使われている23のエンコーディングを扱っており、必要に応じてさらにサポートを増やす計画があります。
関連記事
- 訳注: このRubyソースコード完全解説を英訳したのがRuby Hacking Guideです。 ↩
- 再帰下降構文解析 - Wikipedia ↩
- Parsing Expression Grammar - Wikipedia ↩
- 文脈自由文法 - Wikipedia ↩
- LR法 - Wikipedia ↩
- 訳注: YARPのCRubyへのマージは既に完了しています。ruby/yarp: Yet Another Ruby Parser、#7964 ↩
概要
原著者の許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。
なお、本記事では「パーサー」(parser: 構文解析器)はカタカナで、lexer(字句解析器)は英ママで表記します。
参考: 構文解析 - Wikipedia
参考: 字句解析 - Wikipedia