morimorihogeです。いつの間にか12月。師走だ。
先日の銀座Rails#27で話した内容のまとめ直し版記事です。
Webシステムを作っているとあちこちにいろいろな設定が増えていきますが、そういった設定(コンフィグファイルや各種設定値)をどうやって保持する方法があり、それぞれのメリット・デメリットなどをまとめてみた内容になります。
特定のコンフィグ実装について書かれた記事は多いのですが、コンフィグ設計全般に関してまとめられた記事はそこまで見かけることがなかったので、自分なりにまとめてみました。色々と抜け漏れなどあるかと思いますが、その辺りはTwitter、はてブ等でご指摘頂ければブラッシュアップしていきたい所存です。
※本記事はTechRachoアドベントカレンダー2020 1日目の記事になります。
⚓ 本記事で扱う「アプリケーションコンフィグ」の範囲について
単にConfigurationというと人によって想定範囲が大幅にブレてしまうので、まずはその辺りのスコープから整理していきます。
⚓ 12-Factor Appにおける「設定」の定義
DevOpsという言葉が流行った時期を知っている人なら恐らく一度は目にしたことがあると思われる12-Factor Appというものがあります。
12-Factor AppはWebアプリケーションやSaaSといったどこかのインフラにdeployされるソフトウェアのインフラ設計やデプロイ方式、管理方法などについてモダンな設計方針をまとめたもので、Dockerをはじめとするコンテナ型ソリューションとの相性も良く、インフラエンジニアやDevOpsエンジニアといった運用寄りのエンジニアの中では良く参照される資料となっています。
一方で、昨今のRailsアプリケーション開発ではサーバー環境のコンテナ化やフロントエンド周りのフロントエンドエンジニアへの役割分担化に伴い、Railsエンジニアがこれまでのインフラエンジニアの領分にも踏み込んで行かざるを得ないケースが増えているのではないでしょうか。
例えば、ECSやFargate他のDockerバックエンドのアプリケーションサーバーを利用している場合、アプリケーション用のDockerコンテナ設定(Dockerfileそのものや注入する環境変数、起動パラメータなど)はインフラエンジニア任せとはいかないため、アプリケーションサーバー側のエンジニア(=Railsエンジニア)がコンテナ設定を担うことが多いでしょう。
というわけで、12-Factor Appはもし読んだことがなければRailsエンジニアにもぜひ一読しておくことをお勧めします。
そんな12-Factor Appの中で「設定」は1章分を使って取り上げられています。12-Factor Appの中では「設定」の定義は
アプリケーションの 設定 は、デプロイ(ステージング、本番、開発環境など)の間で異なり得る唯一のものである。
(略)
アプリケーションは時に設定を定数としてコード内に格納する。これはTwelve-Factorに違反している。Twelve-Factorは 設定をコードから厳密に分離すること を要求する。設定はデプロイごとに大きく異なるが、コードはそうではない。
The Twelve-Factor App III.設定より
とされています。deploy間で異なるものを対象とするのが特徴ですね。
12-Factor Appでは環境変数が設定の格納方法として推奨されていますが、これは12-Factor Appではアプリケーションはプロセスとして実行することが想定されていることから相性が良いという点もあると思います。
⚓ 本記事で扱う「設定」の範囲
本記事では取り扱う「設定」の範囲を12-Factor Appの範囲よりやや広げてアプリケーション設定にまで拡張します。
Railsアプリケーションでは12-Factor Appの扱うインフラレベルでの設定(接続先外部システムのエンドポイントURLやAPI KEY、動作スレッド数など)以外にも、様々な「アプリケーションの設定」を行うことがあります。
言語別の言語ファイル、休祝日定義設定、デバッグモードのON/OFF、その他ビジネスロジックで利用するパラメータなど、様々な設定があります。
具体的には、本記事では「外部から調整可能な何らかのデータを渡すことにより、アプリケーションの動作を変更し得るもの」として以下のようなものを広義の「アプリケーション設定」として扱って行きます。
- 環境変数や引数など、プロセス実行時に引き渡されるもの
- プログラムの外からファイルやURLとして渡されて読み込むもの
- DBの特定テーブルなどに入っていて都度読み出す設定情報など
⚓ 様々な設定注入方法
Railsアプリケーションを前提として考えた場合に、どのような設定の実装方法があるのか、ざっと一覧してみます。
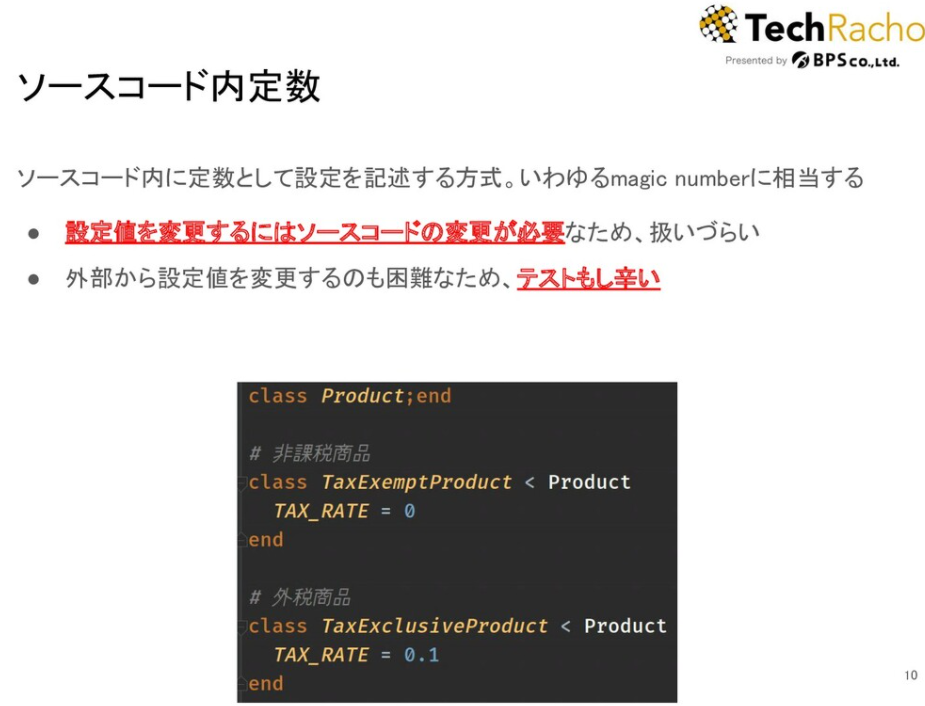
⚓ ソースコード内定数
いわゆるmagic numberと呼ばれる奴です。これは設定なのかといわれると怪しいところではありますが、ソースコードを書き換えてdeployすることで変更可能な設定である、という見方も出来なくはないため、方式として挙げておきます。
典型的なアンチパターンというかバッドプラクティスなため深く解説することはしませんが、作り捨てのアプリケーション開発だったり、定義した値が変わらないことが保証されている時以外では選択し辛い方式です。
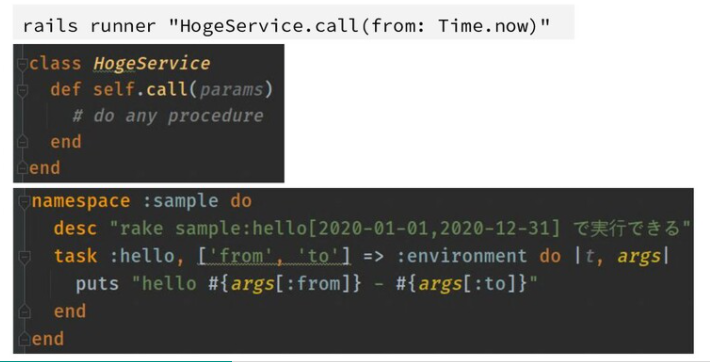
⚓ コマンドライン実行時引数
RakeタスクやRails runner経由でRailsプロセスを実行する場合、実行時に引数として設定を渡すことができます。
CI経由で実行したり、不定期に実行する可能性のあるメンテナンス用タスクなんかは引数で振る舞いを変更できるようにしておくと汎用性が高まって便利になることがあります。
- RakeやRailsコマンドが実行できるシェルが取れる場合(CI runner経由を含む)に柔軟に利用できる
- Rails runner経由の場合はRubyコードを記述することもできるので、
Time.nowなどの定数値以外のものも引き渡し可能
といった利点があります。
⚓ 環境変数
12-Factor Appでオススメされている設定方法です。Rails及びRubyではENVから取得することができます。
Dockerなどでも多く用いられている設定方法で、汎用的なソフトウェアでは最もメジャーな設定方法の一つです。
- Rails向けに限らずPaaSやCIツールが設定サポートしているケースが多く、サービス間のつなぎ込みの点では最も柔軟かつ汎用性が高い
- Rails以外のソフトウェアと設定値を共有したい場合にも、同じ方法で渡すことができる
- 文字列しか渡せないため、複雑なデータ構造を渡すには不向き

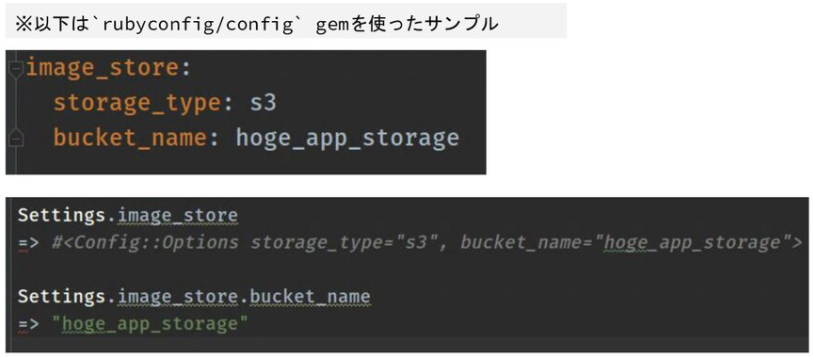
⚓ 定義型設定ファイル(YAML、JSONなど)
rubyconfig/config Gem(旧rails_config)などを代表とする、YAMLファイルやJSON形式の設定ファイルに記述し、アプリケーション側から読み込む方式です。
Railsの設定方式としてはメジャーどころで、database.ymlやsecrets.yml、暗号化機能が入りますがcredentials.yml.encなどもこの方式の一つとして考えることができると思います。
- ArrayやHashなどの文字列以外の構造データを格納することができる
- 階層構造に対応するので、パラメータ数が増えてもnamespace的な整理が可能
- リポジトリにコミットせずに、deploy先別にファイルを用意してまるっと差し替えるなどの運用が可能
柔軟性と記述容易性のバランスが良い印象ですね。
⚓ ソースコード形式設定ファイル
config/initializers/*に置かれるような、RubyコードとしてRailsアプリケーションの実行時に初期化・設定のために読み込まれるファイルになります。
初期化用といった用途にも使われるため、厳密に設定のためだけに使われる訳ではありませんが、実質アプリケーション設定として利用されるケースも多いためここで取り上げています。
- pureなRubyコードが書けるため、値の設定だけでなく読み込みに時間のかかる初期化の重いオブジェクト生成なども可能
- lambdaやProcなども設定することができるため、定数による設定ファイルでは書けないロジックも記述できる(例:
Time.now.yesterdayなど)
定義型設定ファイルの例ではdeploy先別に用意することがありますが、こちらの例ではそういったことはあまりしないように思います。
※どうしても設定を分けたい場合、initializers配下のソースは変更せずに、環境変数を使って設定を差し替え可能にするなどを良く見る印象です
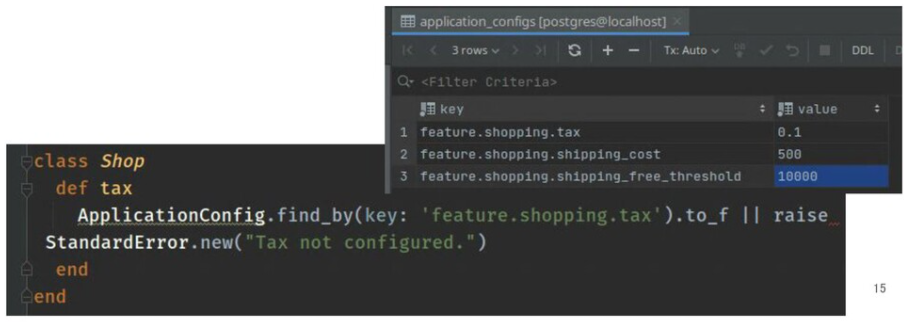
⚓ DBやKVSの設定情報用テーブル
アプリケーション設定情報用のkey-value(設定名:設定値)の組になったデータを格納するテーブルを用意し、必要に応じて参照・更新する方法です。
- 古くからある方式で、feature toggleなどによく利用される
- プロセスの再起動なしに値の更新が可能
- DBアクセスが都度発生するため、DBサーバーが遠かったり設定値が多すぎると速度面が問題になる可能性がある
deploy(プロセスの再起動)なしにオンデマンドで設定値を変更したい場合には良く使われる手法です。
この方法だと運用サイドのチームでも機能や設定の切り替えができるため、うまく使うことで開発チームの手を借りることなく施策を打てるという利点があります。
一方で、あまりにも柔軟にしすぎるとお互いに依存する設定値の組み合わせ数が爆発してしまい、開発時には想定していないバグを引き起こすこともあるため、何を動的設定可能にするかは慎重に決める必要があります。
⚓ その他
フロントエンド系の開発ではサーバーサイドを介さずにGoogle Tag Manager(GTM)などの外部ツールを使って設定を行うこともあると思います。例えばGTMで条件に合わせて表示する内容を切り替えるA-Bテストなどが出来ますが、こういったものは今回非サーバーサイドのものということで、考慮対象外とします。
また、AWSなどのクラウドインフラの機能を使うことで、アプリケーションサーバーには一切手を付けずにcanary deployなどを行うことも昨今ではできそうですが、こうしたインフラサイドだけで可能な設定についても考慮対象外としておきます。
新機能 – 加重ターゲットグループの使用によって Application Load Balancer がデプロイメントをシンプルに
⚓ 各設定実装方法の特徴と使いどころ
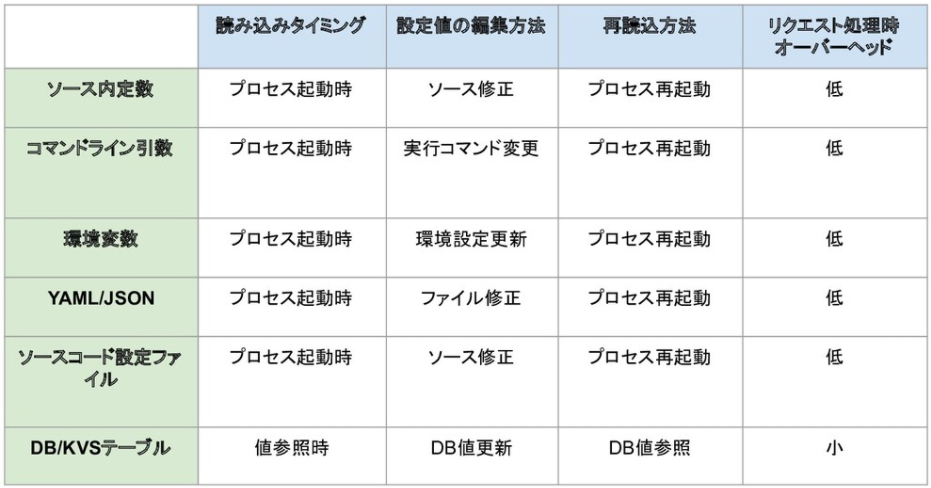
ここまでに挙げてきたそれぞれの手法について、ざっくり整理してみたのが下図です。
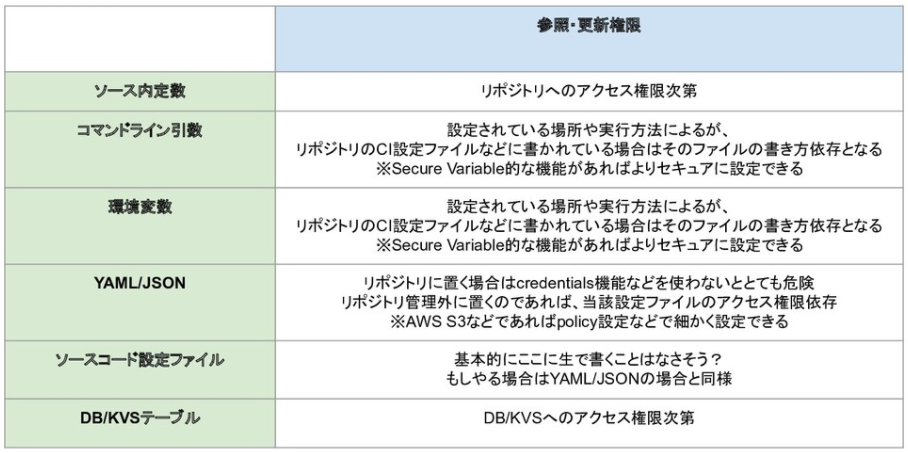
機微情報を格納すると想定した場合のセキュリティ視点では以下の図の通りになります。
これらを見つつ、各設定方式について比較していきます。
⚓ 設定値の読み込みタイミングによる違い
今回挙げた方式の中ではDB/KVSテーブル方式以外、すべて設定値の読み込み・再読み込みはプロセスのライフサイクルに一致します。すなわち、設定値の変更にdeployが必要になるということです。
昨今ではCI、CD環境の整備により10年以上前に比べれば格段に新コードがdeployしやすくなりましたが、それでもdeployには少なからず時間がかかります。
ダウンタイム許容の小規模なシステムであればそれほど問題にはなりませんが、ゼロダウンタイムを要求される環境の場合、冗長化されたサーバー群に順にdeployしていくなどの手順が必要となるため、deploy実行から完全に完了するまでの間には数分~数十分程度かかるのが一般的でしょう。
裏を返せば「今すぐ(秒~1分以内に)設定変更したい」というニーズにこれらの方式は対応できません。
大規模なリリースの場合にはBlue-Green deploymentのように複数の正環境を用意して切り替え可能にするということも考えられますが、普段の一般的な運用で回すには大げさすぎるのではないでしょうか。
そんなわけで、「deployせずに待ち時間なしに設定変更したい」というニーズがある場合にはDB/KVSに設定値を格納する必要がありそうです。
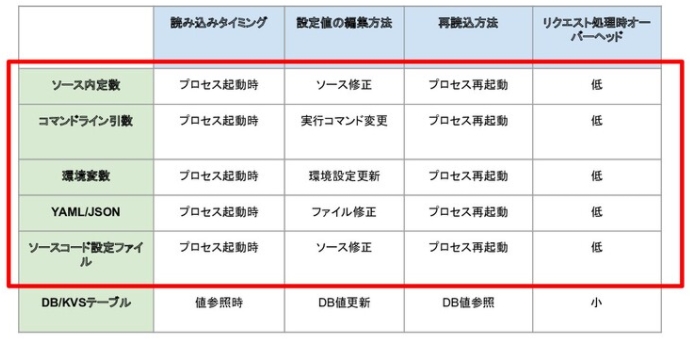
⚓ 設定変更方法による違い
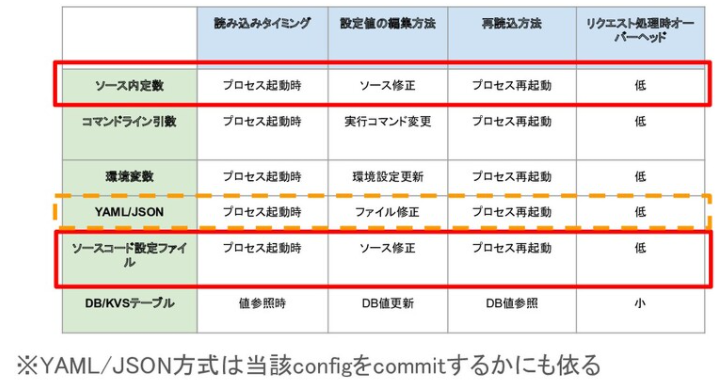
設定値の変更にリポジトリにコミットされているファイル修正が必要な場合、運用上のニーズによる設定変更が機能開発のソース変更と混じるという問題が発生します。
これはbranchのmerge運用がカオスになりやすい要因の一つで、設定値変更のためのhotfixがちょくちょく発行されるのを許容するのか、という問題になってきます。
※ここはどちらが正解、というよりは開発チームで決めて運用すべきところだと思います。
もし運用で変更する可能性のある設定を導入する必要がある場合、設定値を変更する場合のフローを意識しておくとbranch管理で頭を悩ませる可能性が少しは低くなって良いかもしれません。
⚓ 秘密情報管理の観点
API Keyなどの情報は最低限のメンバーにしか見えないようにしたいため、権限管理が気になります。
ソース内定数方式などは論外ですが、環境変数やファイル方式、クラウドインフラが持つセキュアパラメータ管理サービスを使うなど様々な方式があり、色々なオプションが考えられるところです。
いずれにせよ秘密情報は他のアプリケーション設定とは別に管理する必要があるという点は常に意識しておく必要があります。
・・・とまあ、機微情報の扱いについてはまとめてようとしてみましたが、ちょっと今回の範囲でまとめて話すには範囲が広すぎるということで、本記事では触り程度ということでご了承ください。
※一点大事なのは、どんなセキュアな場所に保存したとしても、shellが取れてrails consoleが触れると見られない情報はないため、もしrails consoleを実行可能な環境を用意する場合は取り扱いに充分注意することが大事です。
⚓ その他のトピック(抜粋)
入りきらなかったテーマをピックアップします。
⚓ 複数の設定方式に同時対応する
OSSやDockerで配布されているアプリケーションなど、様々な人が様々な環境で動作させることを想定とする場合には、これまでに挙げた設定方式の複数に対応することで、より柔軟かつ汎用的なソフトウェアになります。
よく見るのは
- (最優先)環境変数の設定値
- 設定ファイルの設定値
- アプリケーションのデフォルト設定値
といった順に優先度が設定されており、より優先度の高い設定で下位の設定を上書きできる、という仕様です。
Nginxを-gオプションでforegroundモードで動かしたり、動作検証の時だけDEBUG=1などを環境変数で渡して起動できるようにする機能などが代表的です。
ただ、すべての設定を環境変数で上書きできるようにするというのも煩雑になりすぎて難しい話なため、どの設定を上書き可能にするのかなどは実際に利用していく中でカスタマイズしていく部分なのかなとも思います。
⚓ デフォルト値問題
可能ならデフォルト値は設定し、デフォルト値でいい感じにアプリケーションが動くようにしておくべきです。
これはRailsのCoC(Convention over Configuration)原則にも則していますし、何より設定が匠の技化しないために大事なことです。
また、デフォルト値がある場合でも、設定ファイルで上書き可能なのであれば、リポジトリに全設定可能パラメータのデフォルト値が記載された「デフォルト設定ファイル(*.default.confなど)」があるととても便利です。
「何が設定変更可能なのか」という情報はまとめておかないとブラックボックス化しやすい情報なので、設定項目が多くなれば多くなるほどデフォルト設定ファイルは用意しておくことをオススメします。
⚓ まとめ
というわけで、(主にRails)アプリケーションコンフィグの設計パターンということで、整理を試みてみました。
元々まとまっている情報を参考にしたわけではないので稚拙な部分もあったかと思いますが、コンフィグの設計について考える一助になれば幸いです。
ではでは。
