morimorihogeです。生活リズムが崩壊気味でねむい。
Rubyをそれなりに書いている人ならご存じのプロを目指す人のためのRuby入門(いわゆるチェリー本)の改訂2版が12/2についに発売されました。
改訂版発売に伴い著者の伊藤 淳一(@jnchito)さんからQiitaアドベントカレンダー企画としてRubyプログラミング問題にチャレンジ! -改訂版・チェリー本発売記念-というイベントが行われているのでエントリーして解いてみたので、記事にしたいと思います。後半にオマケもあります。
方針決め
今回のコンセプトとしては「あまり変な(こだわった)ことはせず、愚直に作りきる」としました。人に見せるコードだと思って頑張りすぎると完成しない可能性が出てしまうので、きちんと動くコードを書いて提出することを最低目標とします。
幸い課題の前提として最もめんどくさそうな異常系の考慮については不要ということなので、汎用性についてはそこまで考えすぎないで良さそうです。
普段業務でコードを書いている時も、僕のスタンスは「まずはやりたいことが正常系で動くコードを書き、その後リファクタリングや異常系のチェックを入れていく」という流れにすることが多いので、そんな感じで取り組んでみました。
PRについては以下に上げていますので、興味のある方はどうぞ。
ざっくり設計とめんどくさそうなポイント洗い出し
まずはざっくりやることを分解しつつ、めんどくさそうな部分がどこにあるかを考えてみます。
今回の課題は TenjiMaker#to_tenji の実装となっていますが、想定入出力を見てみると大体以下の処理に分解できそうです。
#to_tenjiの引数に渡されたローマ字文字列(A HI RU,KI RI Nなど)をかな1文字ずつ相当に分解する- かな1文字ずつのローマ字文字列(
A,HI,RU)を点字を表す内部表現に変換する - 複数文字分の点字内部表現から複数の点字で構成された3行の
o,-表現の文字列に変換する
それぞれとりあえず頭の中でどんな感じにしようかなーと思ったかを追いかけてみます。
ローマ字文字列(A HI RU, KI RI Nなど)をかな1文字ずつ相当に分解する
これはいわゆるユーザー入力に相当する部分の最初の処理になるので、本来なら入力値チェックや例外系の考慮が厄介になるところなのですが、今回の課題では、
- ヘボン式で入力されたローマ字(例
SHI MA U MA、KI TSU NE) - ありえないローマ字や半角大文字以外の文字(例
XYZ、ne ko、羊) - 半角スペースで区切られていない(例
HIYOKO) - 半角スペースが2文字以上入っている(例
TO RA) - 空文字列や文字列以外のオブジェクト(数値やnil)
が最初から考慮不要となっています。それならもう text.split(' ') で配列にして終わり、ですね。
文字列 <-> 配列変換を行う以下の2つのメソッドはとても良く使うので、いちいち検索しないでも使える程度に覚えていますね。
- String#split: 文字列を引数で渡したセパレータ文字列で分割した配列を返す
- Array#join: 配列を引数で渡した文字列を挟んで結合した文字列を返す
かな1文字ずつのローマ字文字列(A, HI, RU)を点字を表す内部表現に変換する
この辺は結構作る人によって癖の出る部分かなと思いますが、今回は「こだわったことはしない」ということで、恐らく多くの人が思いつくであろうビット表現で表すことにします。
READMEで指定された資料を読むと、今回の仕様範囲で扱う日本語点字は1文字あたり6ビットで表現できそうです。
ここで、どのビットを点字1文字の中のどの点に対応させるかという問題が出ます。
後々の文字列処理のことを考えると上位ビットから
12
34
56
とするのがプログラム内部では扱いやすいようにも思えましたが、今回は「愚直に作る」というコンセプトに合わせて参考資料ページの割り当てを採用しました。
14
25
36
ちなみに前者の方式ではなく後者の参考資料ページの番号割り振りを採用するのにはきちんとした意図があります。
他の資料も見てみようと思い、Wikipediaの「点字」ページを読んでみると、
左側を上から1の点、2の点、3の点、右側を上から4の点、5の点、6の点、として点に番号を記し、~
という記載がありました。
ここから読み取れることとして、点字を一般的に使う人達にとっては後者の番号割り振りが一般的で「Xの点」という名前までついているという情報があります。
業務開発でもいえる事なのですが、システムの利用者サイドが持っている概念とプログラム側の設計概念はなるべく近づけておくのが大事です。
- プログラマ側で考える「Xビット目の点」と利用者が考える「X番目の点」が食い違うことにより、コミュニケーションミスが起こりやすくなってしまう
- 業務システム開発とかで厄介な奴です。仕様の読み違えやビジネスサイド<->エンジニアサイドの用語変換コストは馬鹿にならないので言葉や定義は揃えたいですね。DDDの文脈とかでも言われるやつです。
- もしかするとこの番号の付け方には何か他の意味が含まれているのかもしれず、番号を付け直してしまうとその意味が失われてしまう可能性がある
- 僕は点字については素人です。確認した範囲の資料には書かれていませんが、もしかするとNの点 <-> Mの点の順序や番号間の距離に何らかの意味があるかもしれません。もし順序に意味があった場合、システム側で順序割り当てを変えてしまうと本来の意味が設計の過程で失われてしまいます。
- こうしたビジネスドメイン素人による間違った仕様の再解釈は危険なので、業務開発であれば点字の専門家などに質問してみたりするところですが、今回は聞く相手もいないということで、安全側に倒す意味で世間一般の解釈の通りプログラム側も設計することにします。
実装についてはどうしましょうか。
点字仕様を見ていると、各文字は以下の2ケースになりそうです。
- A: 母音を表す点(1,2,4の点)と子音を表す点(3,5,6の点)の組み合わせで作れる文字
- B: 例外ケース(今回の文字範囲では「や」「ゆ」「よ」「わ」「ん」)
Aだけであればロジックだけで組んでも良いのですが、Bのケースにも対応しないといけないということで、今回は、R2T_TABLE(ローマ字 to 点字テーブル)というローマ字のシンボルをキー、点字バイナリを値とするハッシュ表を作り、
R2T_TABLE[:A]
=> 0b100000
R2T_TABLE[:KU]
=> 0b100101
といった感じで取り出せるようにします。
こうしたあらかじめハッシュ表で辞書を作って参照させる方式のメリット・デメリットは以下の様な感じかと思います。
- O(1)で参照できるため参照が早い
- ハッシュ表の初期生成のコスト(CPU・メモリ)はかかる
- key-valueの1:1対応でしかないので例外ケースに対応しやすい拡張性を持つ
- 実装が複雑になりづらいので扱いやすい
今回の点字メーカープログラムは具体的なユースケースの指定はありませんでしたが、任意のローマ字文字列を点字に変換するという仕様からある程度長い文字列が渡されることもありそうに思えます。
長い文字列が渡されることも考慮に入れてみると、1文字ずつ毎回点字データを生成するロジックとして組むよりもあらかじめ作っておいた辞書から参照する方がパフォーマンス的にも有利そうですね。
Aのケースについては lib/tenji_maker/code.rbで、
# 母音ビット
BIT_A = 0b100000
BIT_I = 0b110000
BIT_U = 0b100100
BIT_E = 0b110100
BIT_O = 0b010100
VOWEL_BITS = {
A: BIT_A,
I: BIT_I,
U: BIT_U,
E: BIT_E,
O: BIT_O
}.freeze
# 子音ビット
BIT_KA_COLUMN = 0b000001
BIT_SA_COLUMN = 0b000011
...
CONSONANT_BITS = {
K: BIT_KA_COLUMN,
S: BIT_SA_COLUMN,
...
}.freeze
といった感じで定数を定義し、母音(vowels)、子音(consonant)それぞれについて R2T_TABLE に入れて行きます。
# あ行は子音なし
VOWEL_BITS.each do |v_char, v_bit|
R2T_TABLE[:"#{v_char}"] = v_bit
end
# 母音bit | 子音bitで表現できる文字
CONSONANT_BITS.each do |c_char, c_bit|
VOWEL_BITS.each do |v_char, v_bit|
R2T_TABLE[:"#{c_char}#{v_char}"] = c_bit | v_bit
end
end
Bの例外系については例外としか言いようがないので、
# 例外ケース
BIT_YA = 0b001100
BIT_YU = 0b001101
...
BIT_N = 0b001011
STICKY_ROMES = {
YA: BIT_YA,
YU: BIT_YU,
...
N: BIT_N
}.freeze
という感じで定義しておき、
# 例外系
STICKY_ROMES.each do |s_char, s_bit|
R2T_TABLE[:"#{s_char}"] = s_bit
end
でR2T_TABLEに設定します。
複数文字分の点字内部表現から複数の点字で構成された3行のo, -表現の文字列に変換する
地味にこれが一番面倒でした。ビットで表現されたものを今度はo, -の文字列表現に変換してやるのですが、あまりスマートな方法が思い浮かばなかったので泥臭くやっています。
まず、1文字分の点字バイナリ表現を文字列表現に変換する #stringify_tenji を実装するのには、Kernel.#format を使いました。
- 参考: Kernel.#format
フォーマット文字列として %06B を指定することで、
0: 上位ビットを0で埋める6: 6桁表示B: 2進数表示
として文字列化しています。
その後、2桁ずつの形式に文字配置した後 01 -> -o に置き換えます。泥臭いけど動くということで。
lib/tenji_maker/util.rbとして、以下の関数を定義しています。
# 1文字分の点字バイナリをhuman readable文字列形式(改行区切りのo-表現)に変換する
# 例: 0b100000
# ->
# o-
# --
# --
def stringify_tenji(binary)
chars = format('%06B', binary).chars
"#{chars[0]}#{chars[3]}\n#{chars[1]}#{chars[4]}\n#{chars[2]}#{chars[5]}".gsub!('0', '-').gsub!('1', 'o')
end
また、複数の点字表現を結合するには1文字ずつの点字形式を行ごとに分割してから結合してやる必要があるので、以下のようなコードになりました。
# 引数として渡された点字バイナリ表現配列から点字表現として結合した文字列を返す
# 例: [0b100000, 0b111111]
# ->
# o- oo
# -- oo
# -- oo
def stringify_tenjis(tenjis)
output = ['', '', '']
tenjis.map { stringify_tenji(_1) }.each do |tenji|
tenji.split("\n").each_with_index do |row, index|
output[index] << "#{row} "
end
end
output.map(&:strip).join("\n")
end
コードのアピールポイント
最低限コードだけ読んでも意図が分かる程度にコメントを入れたり、前節で書いたようになるべくドメイン側の仕様を過度にプログラム側で最適化しないようにしたところでしょうか。
一応半年・1年後に自分が読んでも何をしようとしたか理解できるイメージはあります。
パフォーマンス面については複数実装を書いてベンチマークしてみたりしないと、実際のところどれくらい早いかの判断をするには早計かなと思います。
あとは、アピールポイントという程でもないかもしれませんが、いくつか知ってると便利な書き方としては、
R2T_TABLE[:"#{s_char}"]
という文字列リテラルの手前に:を付けるとシンボルのリテラルにできる(この書き方だとハイフンなどが入っていてもシンボルにできる)書き方や、
tenjis.map { stringify_tenji(_1) }.each do |tenji|
で使っている暗黙のブロックパラメータ _1 (Ruby 2.7から導入されたnumbered parameter)などでしょうか。
他にも、もっと点字のビット数が多くなってくるなら 0b100_000 といいった数値リテラルに任意の _ を入れて読みやすくするテクニックなども考えましたが、これは6桁だとむしろ冗長で読みにくくなるのでやめました。
こうしたRuby本体に存在する「知ってるとちょっと便利」な書き方は使わないと忘れてしまうので、可読性が失われない範囲で積極的に使っていきたいものですね。
オマケ:Unicode点字
Wikipediaの「点字」ページを見ていたら、Unicode点字に関する記述がありましたので、Unicode点字を出すように書いたコードを作ってみました。
こんな感じで、⠇⠄⠞⠓ という点字が表示されます。
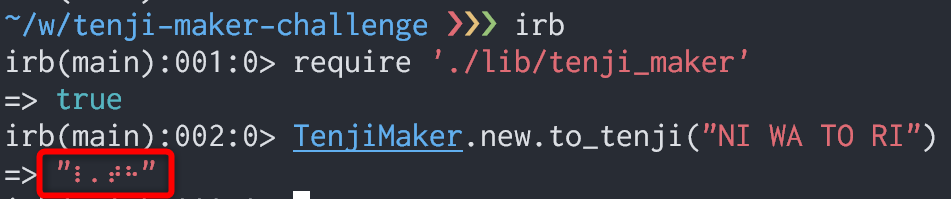
もちろんテストは失敗しますので、解答としてはレギュレーション違反です。
Failure:
TenjiMakerTest#test_ni_wa_to_ri [/home/morimori/webapps/tenji-maker-challenge/test/tenji_maker_test.rb:39]:
--- expected
+++ actual
@@ -1,3 +1 @@
-"o- -- -o o-
-o- -- oo oo
-o- o- o- --"
+"⠇⠄⠞⠓"
ちなみにUnicodeのコードポイントをチマチマ書き写していて気づいたのですが、Unicode点字の並び順にもなんとなく法則性がありそうです。
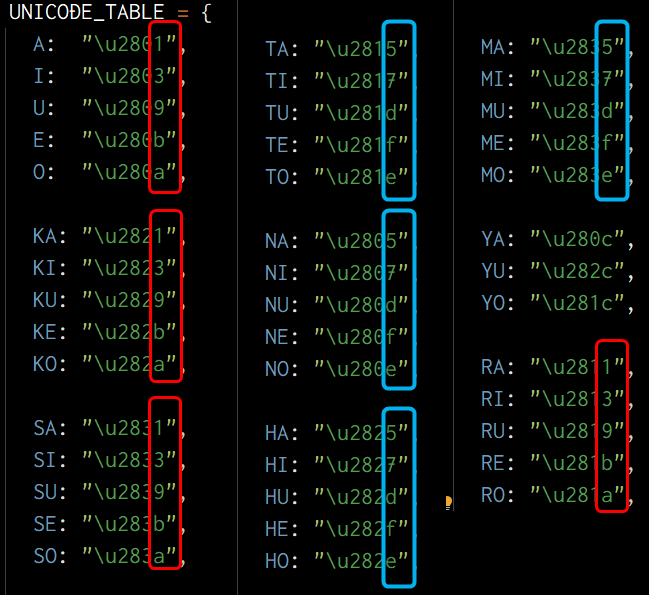
よくよく見てみると6点点字のU+2800 - U+283Fの範囲は2進数で、
1 8
2 16
4 32
になっていそうですね。8点点字の場合は
1 8
2 16
4 32
64 128
と下に拡張しているように見えます。なかなか興味深いですね。
まとめ
この記事は他の参加者の記事を一切読まずに書いているのですが、設計やおまけネタが丸被りしていないことを祈りつつ、チェリー本を注文しようと思います。
12月はRuby 3.1のリリースもあるはずなので楽しみですね!皆様も良いRubyライフを :)
