[連載1回目][連載2回目]
こんにちは、hachi8833です。調べて書くたびに発見があるのはいいのですが、毎度記事があふれ気味ですみません。
連載3回目は、Zの一族の解説に進む前に、これまでにあふれた記事を先に整理することにしました。また、量が多すぎて前回の最後の記事が埋もれ気味だったので今回の冒頭に再録しました。
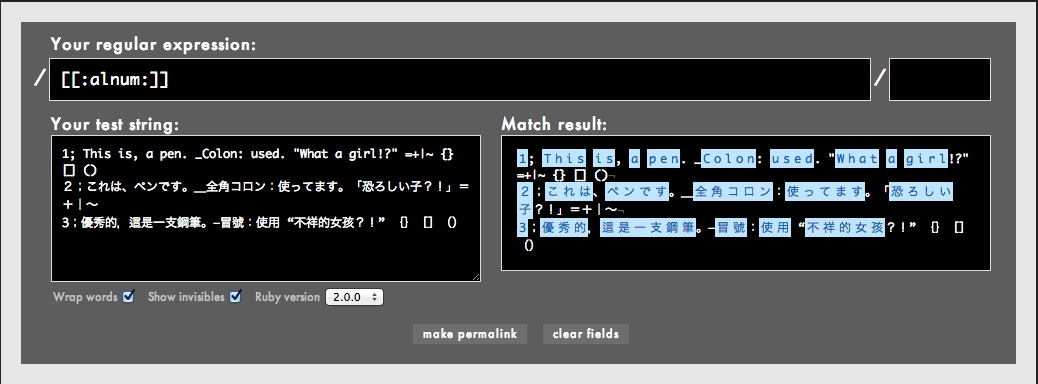
再録: [[:alnum:]]およびPOSIXブラケットについて
最近一部で話題になった[[:alnum:]]ですが、これ自体はUnicode文字プロパティでは「ありません」。見てのとおりUnicode文字プロパティは[\p{ }]で表しますが、鬼車ドキュメントなどによると[: :]はもともとPOSIXブラケットと呼ばれる文字集合を表すためのもののようです(実は本当にこの種のPOSIXブラケットを知りませんでした)。昔のことはわかりませんが、おそらくPOSIXでのみ通用するこうしたローカルお便利表現がそのままUnicodeに拡張されたことによって混乱が生じたのだと思われます。
ちなみに、rubularで前回の例文に[[:alnum:]]を試してみると、見事に日本語の文字もマッチしてます。
小飼弾氏の言う「みーんなアルファベット」というのは、こんなふうに考えてみてもよいかもしれません。「国語」という言葉をたとえば英語にする場合、それが「日本語」という意味であればJapaneseと訳しますが、「自国の言葉」という意味であればEnglishとするのが普通です。後者はアメリカの小学校の授業の時間割を想像してみればわかると思います。何語であっても、学校の授業の時間割で「国語」と書くのは変ではありません。
それと似たような事情で、Alphabetという言葉は、いわゆるAからZまでの文字という意味の他に、特に多言語の現場では「(言語を問わず)数字や記号でない、単語を綴るのに不可欠な、主要な文字」という意味を持たされることがありえます。POSIXブラケットはもともと前者の意味しか考慮していなかったのが、後付けで後者の意味も持たされるはめになったように思えます。
余談ですが、ギリシャ語やロシア語やアラビア語でもピリオドは英語と同一の約物が使われているのをご存知でしょうか(追記: アラビア語には独自のカンマがありますが、スタイルで指定されていれば英語と同じカンマも使用できます)。実はギリシャ語もロシア語もアラビア語も広い意味でアルファベット語族です。ヨーロッパ・中近東の大半の言語をアルファベット語族が占めていますが、いずれもピリオドは英語と同一のものが使われています。ただし引用符は言語による違いがかなり大きくなっています。
Unicode文字プロパティとはそもそも何なのか
やっと本題です。Unicode文字プロパティとは、Unicode(の事実上UTF-8)の規格の一環として設定されている、文字のカテゴリです。既にご紹介しましたが、改めて公式情報へのリンクを置きます。
- Unicode Character Database (Script) (Unicodeコンソーシアムによる公式なリスト)
Ruby 2.0で使用されている正規表現エンジンOnigmoでは、以下のUnicode文字プロパティ(と独自の別名)がサポートされています。
- onigmoのUnicode文字プロパティ (Ruby 2.0)

様子がわかるように、主なプロパティの各カテゴリーを重ねて貼っています。
ちなみにRuby 1.9までの正規表現エンジンOnigurumaで使用できる文字プロパティは以下で参照できます。見てのとおり、Onigmoと比べるとぐっと少なくなっています。
- onigurumaの文字プロパティ (Ruby 1.9)

scriptsとblocksの違い
突然ですが宿題を終わらせたいと思います。連載第一回の末尾に追記したUnicode文字プロパティの「Scripts」と「Blocks」ですが、この違いは何でしょうか。
http://www.unicode.org/Public/UNIDATA/Scripts.txt
http://www.unicode.org/Public/UCD/latest/ucd/Blocks.txt
誰も教えてくれないのでUnicode Standard Annex #44のBlockの項を参照してみると、Blocksは文字どおりコード表のおおまかな区分を示しているだけのものであり、互いに重なっていません。そしてUnicode Standard Annex #44のScriptの項を参照してみると「Script values for use in regular expressions and elsewhere.」とあり、まさに正規表現のための規格であることが示されています。調べてみたら何ということもありませんでしたね。
Ruby2.0のUnicode文字プロパティにはどんなものがあるか
それでは改めて、Ruby2.0のOnigmo Unicode文字プロパティをもう少し詳細に見てみましょう。ここでは概観にとどめますのでRubularでの確認は行いません。どうしても気になる方は各自でRubularで確認するか、Onigmoのヘッダファイルを参照してみてください。
公式プロパティ
以下の中項目は、Unicodeコンソーシアムに同じ表記が記載されている、公式のScriptsプロパティです。公式情報を参照して適用範囲を確認できます。本連載で主に取り上げているのは、このMajor and General Categoriesです。
- Major and General Categories
- Scripts
公式プロパティの別名
以下の中項目は、文字どおり上の公式のScriptsプロパティの別名です。何の説明もありませんが、おそらく上のMajor and General Categoriesの表記があまりに短くて意味が取りにくく、かつScriptsの短縮形が欲しいという需要に応えたものではないでしょうか。上の別名として使ってもよいと思いますが、Onigmo以外では使えない可能性があります。
- PropertyValueAliases (General_Category)
- PropertyValueAliases (Script)
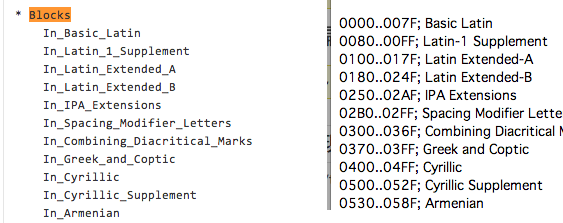
Blocksプロパティ
以下は、おそらく公式のBlocksプロパティですが、右の公式情報と比較してみるとわかるとおり、表記はIn_とアンダースコアを加えた独自のものになっています。
- Blocks
独自のプロパティ
以下の中項目は、Unicodeコンソーシアムに同じものがない、またはそれらを組み合わせるなどした、Onigmo独自のプロパティです。POSIX部分は他の正規表現エンジンと共通のものもあると思いますが、完全に同じかどうかまではわかりません。PropertyAliasesは、だいたいPropListの別名であるようです。DerivedCorePropertiesは、公式規格を合成したプロパティのように思えます。DerivedAgesにいたってはメンテナンス用のプロパティのように思えますが、これを使う人は世界でも10人いないと思われます。
- POSIX brackets
- Special
- DerivedCoreProperties
- PropList
- PropertyAliases
- DerivedAges
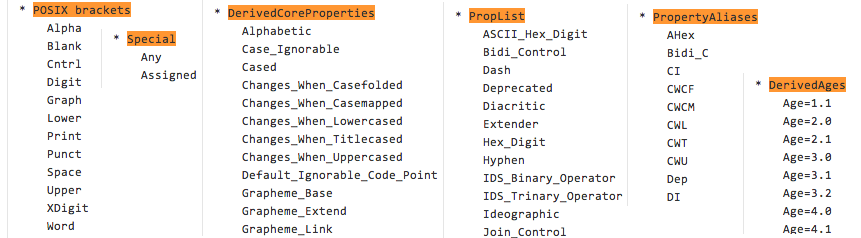
こうしてみるとわかるように、ruby2.0の正規表現で使用されているUnicode文字プロパティは、UnicodeコンソーシアムによるUnicode文字プロパティの規格とイコールではありません。さらに、規格にない独自のプロパティ表記まであることがわかりました。perlやpythonなど他の言語でも、このような違いはあると思われます。さらに文字プロパティは将来変わる(少なくとも追加される)可能性があります。
正規表現のPOSIXレガシー文字クラスよりも規格が整備されていることもあり、どうせ正規表現エンジンを作るならUnicode文字プロパティを取り入れようというのが近年の流れであると思われます。といっても関係者に取材したわけではなく、ショッピングチャンネル同様あくまで個人の感想です。
そして英語圏の正規表現エンジン作者は、非アルファベット言語の文字プロパティといった多言語化に冷淡なことが多く、文字プロパティをマイナーな言語まですべて正規表現で実装するという、面倒な割に喜ぶ人の少ない機能は後回しにされがちなのか、Unicode文字プロパティの実装の進み具合は言語やエンジンによって差があります。
なお、私が公式の規格についこだわってしまう理由は、特定の正規表現エンジンに依存できないという事情があったためです。通常の開発であれば、自分が使用している正規表現エンジンに手頃な文字プロパティがあればそれを使っておしまいですが、複数の言語環境/アプリケーション環境で共通に動作する正規表現を書くためには、方言や独自拡張を極力避ける必要がありました。
そんな事情もありまして、本連載はRubyを使用して解説していますが、基本的にはUnicode文字プロパティを導入している他の言語でもだいたい通用すると思います。立ち読みしかしたことがありませんが、オライリーの正規表現クックブックという本では8種類ぐらいの正規表現方言をすべて記述していて、涙ぐましくもボリュームを増やしておりました。
Unocodeコンソーシアムのいい仕事
ところで、この連載のために調べていて気付いたのですが、何とUnocodeコンソーシアムは正規表現でUnicode文字プロパティを扱うときの規格まで提唱しているのです。既存のPOSIXレガシーな文字クラスについても配慮されているようです。
このことはどのぐらい知られているのでしょうか。それともとっくに常識で、知らなかったのは私だけでしょうか。いずれにしろ、方言だらけになってしまった正規表現の進むべき方向がここに示されています。大変な作業であることは重々承知のうえですが、正規表現エンジン作者の皆様がなるべくこの提案に沿って今後の実装を行っていただけるとうれしく思います。今からでも遅くはありません。
おまけ1: 表記の違い
今回のおまけとして、簡単ですが言語ごとの文字クラスの指定方法の違いを列挙してみました。わかりにくいですが、"否定" 表現かどうかは、pが大文字か小文字かで示されています(大文字のPが否定を表す)。
- Ruby
\p{property-name}
\p{^property-name} #(否定)
\P{property-name} #(否定)
- PHP、perl
\p{Propert-name}
- Python
\p{property=value}
\P{property=value} #(否定)
\p{value}
\P{value} #(否定)
- .NET Framework (必ず文字クラスとして [ ] に含める必要があります)
[\p{property-name}]
[\P{property-name}] (否定)
できれば、これらの言語ローカルな否定表現よりも、標準的な文字クラスの否定[^ ]を使用する方が、特に後々の別言語への移植の際に災いを避けられることでしょう。
おまけ2: UTF-8
話は全然変わりますが、まつもと先生の「コードの未来」という本を読んでいて、UTF-8がRob PikeとKen Thompsonという超大物たちが作った規格だったということを今頃になって知りました。そういえば、UTF-8は最初の方のページがASCIIとまったく同じなので非Unicodeの処理系でもそのままコードを実行できてその点は便利だなーと何となく思ってたのですが、すべて意図されたものだったのですね。失礼いたしました。
でももしかすると単に英語圏の都合を優先しただけなのかもしれません。実際、スペイン語のように英語と違う文字をほんのわずかしか含まない言語の文章をUTF-8で保存すると、次に開いたときにエンコード自動検出に失敗してASCIIで読み込まれ、それらの文字が化けてしまったという事故がありました。
次回こそ「Zの一族」に続けたいところですが、本連載で一番書きたいテーマである「文字プロパティの演算」について稿を改めて書くことにいたします。
[連載1回目][連載2回目]