正規表現で漢数字のマッチをUnicode文字クラスで一発で表現できないかと試行錯誤したことがありました。
- 普通っぽい漢数字:
〇一二三四五六七八九十百千万億兆京 - マニアックな漢数字:
零〇壱一弐二参三肆四伍五陸六漆七捌八玖九拾十陌百阡千萬万億兆京
でも結局、ユースケースに応じて文字セット[]でべた書きプラスアルファするよりないというのが私なりの結論です。
日本の元号の漢数字にマッチさせる
- 例: 日本の元号(明治以降)の漢数字にマッチ: /
(?<=明治|大正|昭和|平成)[二三四五六七八]?[一十]?[元一二三四五六七八九十〇](?=年)/(regex101)
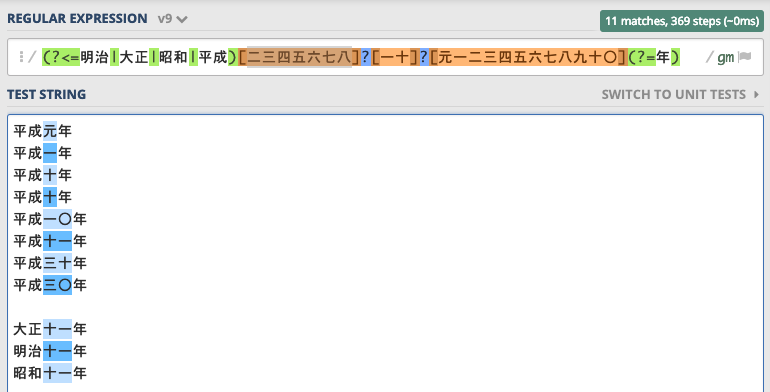
ご覧のとおり、「平成元年」だの「平成一〇年」「平成三〇年」というパターンにも対応しています。
一見冗長に見えるかと思いますが、一応以下のように文字セット[]を桁ごとに分けて精度を高め、かつメンテしやすくしているのがポイントです。
[二三四五六七八]?: 十の位の最初の桁九は現実的でないと思ったので入れていません七八は将来に備えて入れてみましたが、今のところは出現していませんのでやりすぎかもしれません
[一十]?: 十の位が単独の場合の桁[元一二三四五六七八九十〇]: 一の位
もっとも上の場合「平成八一〇年」などの非現実的な漢数字にもマッチしてしまいますが、これらを除外すると可読性が落ちるばかりなのでやっていません。
なお、「年号の漢数字だったら以下のように[元一二三四五六七八九十〇]+(?=年)ぐらいで十分じゃね?」とお思いになるのももっともです。こちらは「平成〇一八九十年」のような非現実的な漢数字にいくらでも長くマッチしますが、お好きな方をどうぞ。
- 例: 雑な年号漢数字マッチ: /
[元一二三四五六七八九十〇]+(?=年)/(regexp100)
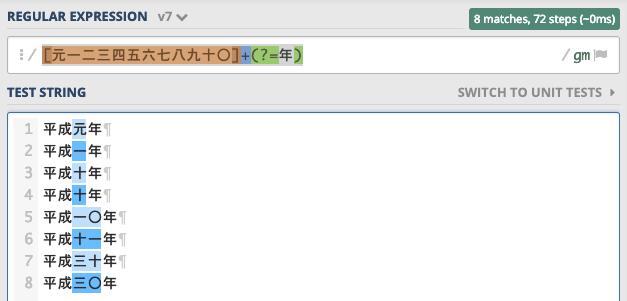
私は*や+を使うマッチが個人的にキライなので、2番目にするなら+を{1, 3}にすると思います。
数値にマッチするUnicode文字カテゴリ
Unicodeの文字クラスの文字カテゴリには、「数値」を表すNというカテゴリがあります。Nはその下にいくつかのサブカテゴリがあります。
実はN単体のカテゴリというものはUnicodeの文字カテゴリにはないのですが、正規表現では[\p{N}]とすると以下のNdとNlとNoのすべてをまとめて表現できます。
Nd: 数字で表す数値(Decimal Number)- 半角数字(
[0123456789]) - 全角数字(
[0123456789]) - アラビア文字やクメール文字の数値など
- その他多数
- 半角数字(
Nl: 文字で表す数値(Letter Number)- ローマ数字(
Ⅷやⅷなど) - その他多数
- ローマ数字(
No: その他の数値(Other Number)- 分数(
¼など) - 上付き下付き数値(
¹など) - 外字由来の装飾数字(
①、❶、⓵、⑴、⒈、㊄など) - 古代の数字(
𐄡: エーゲ文字の900など) - 漢文訓読用数値(
㆒、㆓、㆔、㆕) - その他多数
- 分数(
もっとも、私の場合N系の文字カテゴリが正規表現で必要になったことはありませんが。
漢数字の〇だけは数値扱い
[\p{N}]でありとあらゆる数値にマッチすると書きましたが、いわゆる漢数字の中で[\p{N}]にマッチするのは〇(漢数字の〇)だけです。以下をご覧ください。
- 例: あらゆる数値文字にマッチする/
[\p{N}]/(Regex101)
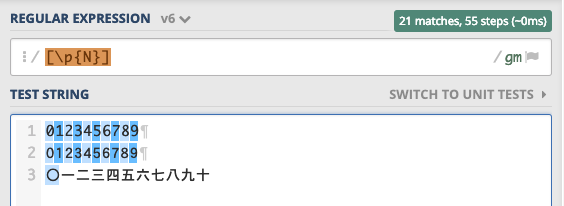
考えてみれば、漢数字一二三四五六七八九十百千万億兆京は人名地名などにも使われるのですから数字扱いするのは無理がありますね。
紛らわしい「漢文訓読用の漢数字」
と思っていたら、先ほどのNo: その他の数値(Other Number)の中に漢数字としか思えないものがあるじゃありませんか。
compart.comより
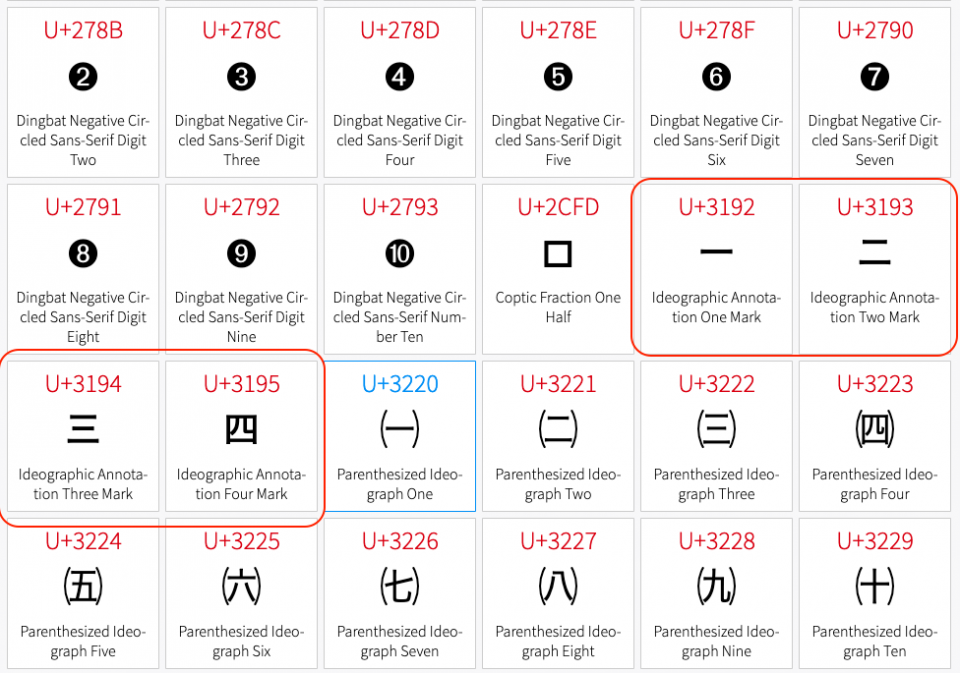
思わず五より大きい漢数字を探しそうになってしまいました。
しかし種を明かせば、これは「Kanbun」(漢文)というUnicodeブロックです。以下を見ればおわかりのように、日本で漢文の読み下し(訓読)用に漢文の横に付けられる「訓点」と呼ばれる特殊な文字です。この「㆒、㆓、㆔、㆕」は例外的に数値に分類されているのです。
compart.comより

こうして眺めてみると、訓点はどことなく古代に狂い咲いたマークアップ言語のように思えてきませんかそうですか。本文で一度読んだ文字は二度と読まれないという性質から、チューリング不完全なのは確かだと思いますが。
この訓点を使う人は非常に少ないと思われるので普段はそこまで気にする必要はないと思いますが、[\p{N}]のような広大な文字セットを使うときにはふと思い出してみるとよいと思います。
参考: 漢文訓読 - Wikipedia