[連載1回目へ]
こんにちは、hachi8833です。まだbyobu-configが自分の環境で動いてくれないので、ctrl-aだけ殺してデフォルトキーバインドでbyobuを使い始めているところです。
先週に引き続いて正規表現のUnicode文字プロパティについて調べていきます。改めて調べ始めてみるといろいろと奥深い世界であることに気付き、一人で勝手に盛り上がってます。
早速はてブでツッコミをいただきました。初回連載で[\p{Ideographic}]の記述がいきなり間違っていました。失礼いたしました。Ideographicは日中韓ベトナム(CJKVと略されます)のみが対象となります。前回分も修正いたしました。
Pの一族
正規表現向けのUnicode文字プロパティの解説として、日本語で読めるそこそこまとまった資料は、今のところマイクロソフトの .NET Frameworkの「正規表現での文字クラス」ぐらいしかありません。しかも.NET Framework専用です。他にあったら教えて下さい。
いつの日かもっとまともな資料を作りたいと思いますが、それまでのつなぎとして、よく使われそうなUnicode文字プロパティを中心に簡単に解説します。前回述べたように、この連載では文字プロパティを常に[ ]で囲んで文字クラスとして表記します。
今回扱う文字プロパティは、Unicode Character Categoriesの中からPを含むものにしました。名付けてPの一族。
P -- 約物たち
[\p{P}]は、あらゆる言語の文章で使用される句読点や記号、つまり印刷業界で言うところの約物(やくもの)を表す文字クラスです。今更ですが、内側の"P"はPunctuationのPで、大文字で書く必要があります。では外側の小文字の\pはというと、プロパティ(property)のpですね。
約物とは文章で使用される各種記号のことで、punctuationの訳語とされています。アルファベット語圏ではざっくり「英数字改行タブスペース以外のすべての文字」、日本でならざっくり「英数字改行タブスペース漢字カタカナひらがな以外のすべての文字」を表しているとお考えください。ただしこの「ざっくり」がクセモノです。
ではいつものようにRubularで試してみましょう。ところでいつの間にかというかやっとRubularがRuby 2.0に対応してくれました。これでOniguruma(1.9x系)とOnigumo(2.x系)の違いを簡単に確認できるようになったはずです。ありがたいことです。
すぐに試せるようにコピペ用の英語/日本語/台湾語の例文を下に置きました。内容は超適当なのでご注意ください。
1; This is, a pen. _Colon: used. "What a girl!?" =+|~ {} [] ()
2;これは、ペンです。_全角コロン:使ってます。「恐ろしい子?!」=+|〜
3;優秀的,這是一支鋼筆。―冒號:使用 “不祥的女孩?!” {}[]()
上の例文をYour test stringボックスに、[\p{P}]という文字クラス正規表現をYour regular expressionボックスに入力してみてください。
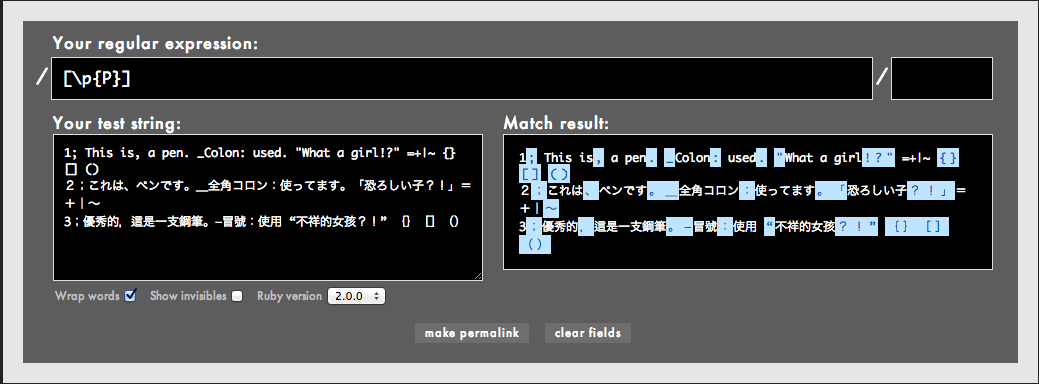
見てのとおり、こんなシンプルな表現で英語/日本語/台湾語固有の句読点、記号にマッチしています。わざと全角の記号も混ぜてますがそれらにもマッチしています。奥さん、ここでそっと泣いてください。
このように、特に多言語にまたがる処理においてはUnicode文字プロパティはきわめて有効です。
Pはすべての約物なのか?
しかしUnicode文字プロパティは強力な分、諸刃の剣にもなりえ、動作範囲を確認せずに使用すると思わぬ挙動に足をすくわれることもあります。Rubularなどで常に動作を確認してから使うようにしましょう。
具体的には、rubularでマッチした結果をもう一度よく見てください。実は先ほどの例文には+=|~などの記号もこっそり混ぜてあるのですが、お気付きになりましたでしょうか。そして[\p{P}]はこれらにはマッチしていないのです。奥さん、ここで泣き止んでください。
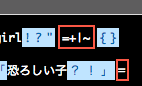
これはどういうことなのでしょうか。「英数字改行タブスペース以外のすべての文字」の集合を今ここでだけ仮に「記号」(signs)と呼ぶとすると、[\p{P}]で表される約物は、記号のすべてではなく、部分集合なのです。先ほど「ざっくりがクセモノ」と書いたのはこういうことです。
念のため確認しておきましょう。広辞苑による約物の定義は以下のとおりです。
約物: (印刷用語) 文字・数字以外の各種記号活字の総称。句読点・括弧類・圏点・漢文用返り点など。
また、WikipediaのPunctuationを見ると、+や-記号もしっかりPunctuationに含まれています。
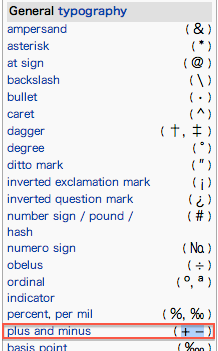
しかしながら、Unicode文字プロパティの定義では、プラス記号やマイナス記号は算術記号(Symbol, Math)に分類されています。ちなみに算術記号は文字クラスでは[\p{Sm}]と書きます。

つまり、一般的な約物の定義とUnicode文字プロパティの定義が同じとは限らないということです。しかしこれは考えてみればある程度仕方のないことでしょう。上の約物の定義は普通に考えてもコンピューター出現前のもので、コンピューター上の処理上の都合など考慮されているはずがありません。Unicodeコンソーシアムはたぶん相当悩んだか議論した末に、なるべく汎用性が高まるように現在の仕様を作り上げたのだと想像できます。
さて、約物に加えて算術記号にもマッチするようにしたい場合は、たとえば文字クラスに\p{Sm}を追加して[\p{P}\p{Sm}]とするとよいでしょう。御存知のとおり、文字クラスでは順序は無関係なので\p{P}と\p{Sm}のどっちが先でも結果は同じです。横着して[\p{PSm}]と書くとエラーになります。もちろん使用する場合にはRubularなどで必ず確認してからにしてください。
Unicode文字プロパティを使用する場合は、いきなり集合の大きな文字プロパティを使うより、最初のうちは集合の小さな文字プロパティを文字クラス [ ] の中で必要なだけ列挙するようにし、慣れてきたら大きな集合も使ってみるようにするとよいかもしれません。そのためにも、以下に説明するようなサブカテゴリも把握しておくとよいでしょう。
Pc -- アンダースコアたち
Pの下にはいくつかのサブカテゴリがあります。[\p{Pc}]は、約物のうちアンダースコア系の約物のみにマッチします。cはconnectorのcです。
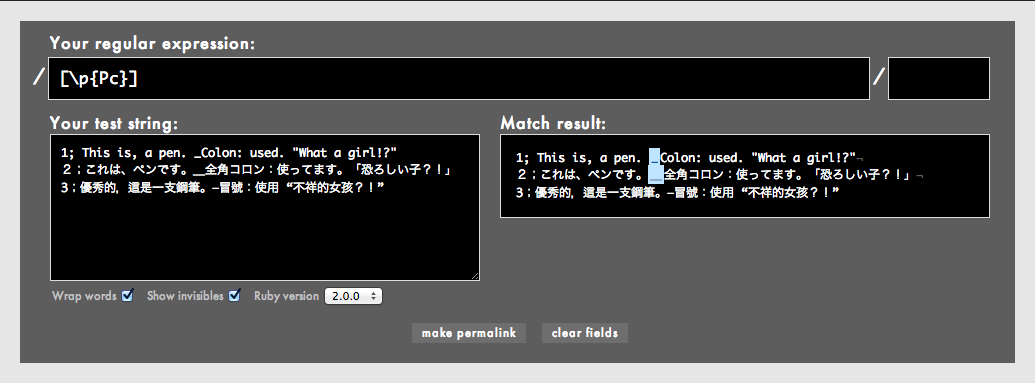
見てのとおり、[\p{Pc}]にするとマッチが随分と減りました。全角のアンダースコアにもマッチしています。
個人的にアンダースコアは記号というより英数字に分類されるような気が何となくしてたのですが、ここに示されているとおりアンダースコアは接続用の約物に分類されるのですね。
先ほどから何度も参照していますが、先週に続いて文字関連の便利サイトであるfileformat.infoをここでご紹介します。このサイトにはファイル形式に関する情報が大量に集約されていますが、その中にUnicode文字プロパティの情報もあります。試しに同サイトのPunctuation, connectorにマッチする文字一覧を見ると、マッチする文字がわかりやすく表示されています。
もちろん、Unicode文字プロパティについては最終的に一次情報を参照するのが確実なのですが、grepせよと言わんばかりにテキストファイルをドンと置いただけのシンプルなものなので、fileformat.infoのような見やすいサイトのありがたみが増すというものです。もちろんUnicodeコンソーシアムにもUNICODE CHARACTER DATABASEのようなもう少し整形された情報もありますが。
本連載では以後、文字プロパティをすぐ参照できるように、セクションの最後に以下のようにリンクを置くことにします。
[Pc : Punctuation, connectorにマッチする文字一覧]
Pd -- ハイフン/ダッシュたち
[\p{Pd}]はハイフン/ダッシュ系の約物にのみマッチします。dはdashのdです。
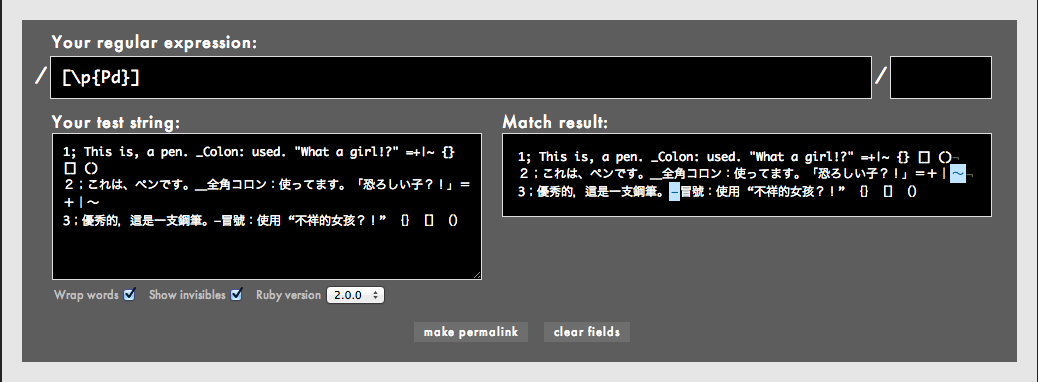
よく見ると、半角のチルダ(tilde: 波ダッシュ、ニョロなどとも呼ばれます)「~」にはマッチしていませんが、全角チルダ「〜」は[\p{Pd}]にはマッチしています。実は半角チルダは算術記号に分類され、全角チルダはダッシュに分類されています。
ハイフンについてはたっぷり書くことがあるのですが、きりがないので次回以降に回します。
[Pd : Punctuation, dashにマッチする文字一覧]
Ps Pe --かっこの仲間たち
[\p{Ps}]と[\p{Pe}]はそれぞれ開始(start)かっこ系、終了(end)かっこ系を表します。全角半角問わず、丸かっこ角かっこ波かっこなどのあらゆるかっこがここに含まれます。

説明はopenとcloseなのに[\p{Ps}]と[\p{Pe}]ではstartとendの頭文字を使用しているのは、おそらくこの後のPoとかぶらないようにするためと思われます。やや苦し紛れですね。
参考: ギュメについて
余談ですが、« » ‹›のような引用符を見かけたことはありますでしょうか(不等号ではありません)。これらはフランス語では「ギュメ」と呼ばれるもので(山かっことも呼ばれているようです)、実はヨーロッパの大半では引用符といえばこれのことだったりします。
たまたま英語圏で全然使われてなかったために知らない人も多いと思いますが、実は日本の書籍では意外にこの引用符、使われています。それも縦書きの本で。特に文芸書や絵本で見かけることが多いので、今度書店に行ったら注意して見てみてください。
[Ps : Punctuation, openにマッチする文字一覧]
[Pe : Punctuation, closeにマッチする文字一覧]
Pi Pf -- 向きを持つ引用符たち
[\p{Pi}]と[\p{Pf}]はそれぞれ開始(initial)引用符、終了(final)引用符を表します。向きのある、いわゆる有向引用符(カーリークォートなどとも呼ばれます)や有向アポストロフィはすべてここに含まれます。
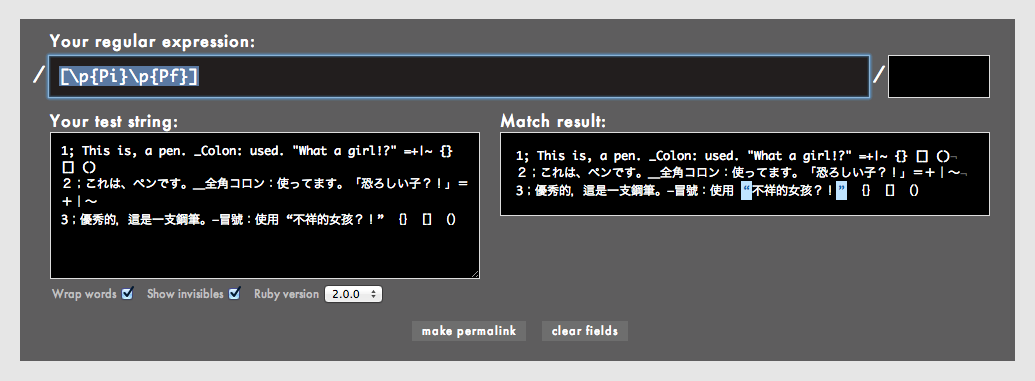
お気付きになった方もいると思いますが、半角の引用符「"」や「'」(ストレートクォートなどとも呼ばれます)にはマッチしていません。半角引用符は、[\p{Pi}]や[\p{Pf}]ではなく、次の[\p{Po}]に含まれています。無念。
参考: 引用符は本来「向きがある」のが正式
ところであまり知られていないのですが、アルファベット圏においては、引用符やアポストロフィは向きがあるものが本来「正式」です。向きを持つ引用符は「スマートクォート」「有向引用符」などとも呼ばれます。
" "' '-- 向きがない引用符(ASCIIにある)“ ”‘ ’-- 向きがある引用符(ASCIIにはない)
半角の引用符「"」や「'」はもともと入力/表示用などの間に合わせのものであり、使用するスタイルガイドにもよりますが、多くの場合公式文書や出版物では引用符やアポストロフィとしては使用しません (インチ単位表記などに使うことはあると思いますが)。
考えてみれば、POSIXというかASCII文字には有向引用符はありません。ここから先は推測ですが、これはコンピュータ出現以前のタイプライター文化の影響を受けた可能性があります。キーを簡単に増やせないタイプライターでは向きのない引用符を採用してキーを節約していたのが、ほぼそのままコンピュータの世界に持ち込まれたのだと思います。かつてはタイプライターで作成された原稿を書籍にする際、印刷職人が半角引用符を有向引用符に置き換えていたことでしょう。
現在でも、英語圏におけるDTPソフトウェアの重要な役割の一つが、これらの半角引用符を内容に合わせて有向引用符に置き換えることです(なお、機械的に有向引用符に置き換えられるとは限りません)。
もっともこれは出版物の話であり、Web上のドキュメントやオンラインヘルプなど、コンピューター上で完結する文章では引用符が有向であるかどうかそれほど気にされなくなりつつあります。
[Pi : Punctuation, initial quoteにマッチする文字一覧]
[Pf : Punctuation, final quoteにマッチする文字一覧]
Po --その他もろもろ
[\p{Po}]は上記以外の約物の集合です。oはotherです。

その他という割には、ピリオドやカンマ、疑問符、感嘆符、コロンなど、いかにも約物らしいものの大半がここに押し込められていて、ちょっと投げやり感があります。とは言うものの、これらの約物はどの言語にも共通してあるとは限らないので、コンソーシアムとしてもそう簡単に文字プロパティを増設するわけにはいかないと思います。とはいうものの、もう少し細かい分類があってもよさそうなものです。将来の増設に期待しましょう。
[Po : Punctuation, otherにマッチする文字一覧]
おまけ: [[:alnum:]]およびPOSIXブラケットについて
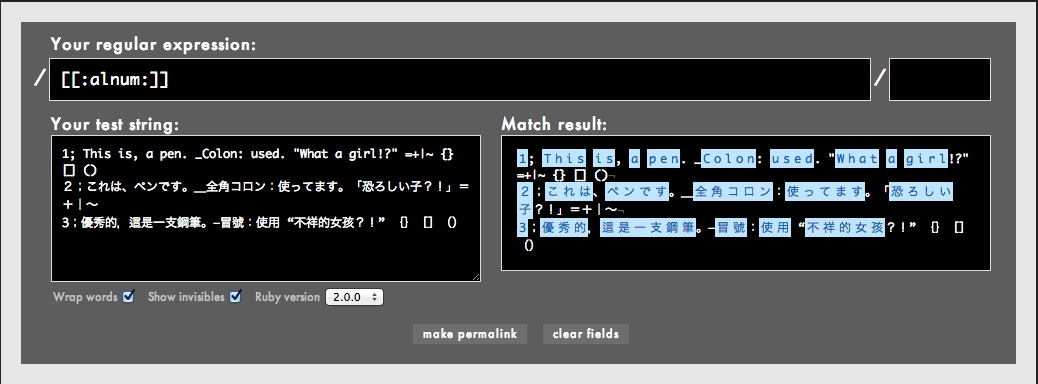
最近一部で話題になった[[:alnum:]]ですが、これ自体はUnicode文字プロパティでは「ありません」。見てのとおりUnicode文字プロパティは[\p{ }]で表しますが、鬼車ドキュメントなどによると[: :]はもともとPOSIXブラケットと呼ばれる文字集合を表すためのもののようです。昔のことは知りませんが、おそらくPOSIXでのみ通用するこうしたローカルお便利表現がそのままUnicodeに拡張されたことによって混乱が生じたのだと思われます。
ちなみに、rubularで先ほどの例文に[[:alnum:]]を試してみると、見事に日本語の文字もマッチしてます。
小飼弾氏の言う「みーんなアルファベット」というのは、こんなふうに考えてみてもよいかもしれません。「国語」という言葉をたとえば英語にする場合、それが「日本語」という意味であればJapaneseと訳しますが、「自国の言葉」という意味であればEnglishとするのが普通です。後者はアメリカの小学校の授業の時間割を想像してみればわかると思います。何語であっても、学校の授業の時間割で「国語」と書くのは変ではありません。
それと似たような事情で、Alphabetという言葉は、いわゆるAからZまでの文字という意味の他に、特に多言語の現場では「(言語を問わず)記号でない、単語を綴るのに不可欠な、主要な文字」という意味を持たされることがありえます。POSIXブラケットはもともと前者の意味しか考慮していなかったのが、後付けで後者の意味も持たされるはめになったように思えます。
余談ですが、ギリシャ語やロシア語やアラビア語でもピリオドは英語と同一の約物が使えるのをご存知でしょうか(追記: アラビア語には独自のカンマがありますが、スタイルで指定されていれば英語と同じカンマも使用できます)。実はギリシャ語もロシア語もアラビア語も広い意味でアルファベット語族です。ヨーロッパ・中近東の大半の言語をアルファベット語族が占めていますが、いずれもピリオドは英語と同一のものが使われています。ただし引用符は言語による違いがかなり大きくなっています。
もひとつ余談ですが、私自身はこの種のPOSIXブラケットは使ったことがありませんでした。というよりそもそもそんなものがあるということに気付いてませんでした。幸か不幸か、かなり長い間Unicode世界(UTF-8またはUTF-16)だけに住み、文字集合としてはUnicode文字プロパティのみを使ってきたのですが、この種のPOSIXブラケットに気付かなくてむしろ幸いでした。Shift_JISだのEUCだのBCDだのといった非Unicode世界のことは考えたくもありません。Rubyも2.0でUTF-8ネイティブになってからやっと本気で勉強する気になったくらいです。そういうわけで、私はPOSIXブラケットは今後も使わないと思います。
追記:
こんなやりとりを見つけました:
[ruby-list:49460] Re: 正規表現の文字クラス[:alpha:]のマルチバイトキャラクタに対する挙動について
(略)
しかし,Ruby の正規表現は果たして上記の鬼車のページに書かれてある
とおりなのかという問題があります。答えは否。
Ruby 1.9 は鬼車を採用していますが,その仕様は若干違うんです。
たとえば,\d は鬼車の上記の仕様では全角数字を含みます。
それどころか,
http://www.fileformat.info/info/unicode/category/Nd/list.htm
に挙っているような極めて多様な十進数字にマッチします。
しかし,Ruby 1.9, 2.0 の \d は [0-9] と等価です。また,Unicode のコード番号で文字を指定する書式は,鬼車の上記の仕様
では \x{ } ですが,Ruby 1.9, 2.0 では \u{ } です。違いがこの二つ以外にあるのかどうか,私は知りません。
どなたか教えてください。
公式リファレンスマニュアルの編集にも支障を来しています。
(略)
もっと簡潔な内容にするはずが、今回も膨れ上がってしまいました。次回「Zの一族」に続きます。
[連載1回目]