はじめまして、hachi8833です。
正規表現において、使わないまま死ぬのはあまりにもったいない「Unicode文字プロパティ」について解説します。これについてネット上にまとまった情報がほとんどなく、しかたがないので自分で書くことにしました。書きながら早くも記事があふれてきたので、見出しに「連載」の文字を追加などしてみました。たぶん他所ではほとんど見かけることのない連載になると思います。よろしくお願いします。
通常の開発においては、目的を達成する正規表現を作成してコードが動けば事足りるものであり、コーディング中に正規表現と延々付き合うことは普通ないでしょう。料理人は包丁を研ぐのに時間をかけすぎないものです。しかし特殊な業界の特殊な人々(日本に5人もいないと思います)は、来る日も来る日も正規表現を書き続けていたりするので、このUnicode文字プロパティは本当にありがたいものです。私の場合、もう古典的な \w とか [a-zA-Z] とか \d のような非UnicodeというかPOSIXレガシーな表現は、作り捨てのコード以外では使っていません。
Unicode文字プロパティの紹介
数字にマッチする[0-9]とかアルファベットにマッチする[a-zA-Z]のような文字クラスを指定することはよく行われています。しかし、日本語のように文字種の多い言語ではこういうクラス指定はあまりお気軽ではありません。
たとえばひらがなだけにマッチさせたい場合は[ぁ-ん]と表します (小さい「ぁ」から開始しなければならない点に注意)。でもこれでは使いたくなったときにその場で正確に思い出せる人はほとんどいないでしょう。
漢字だけにマッチさせたいというときには従来から[一-龠]という表現がよく使われていますが、実は龠より先にも漢字はあります。ただそれらは日常まず使うことのないような、分厚い漢和辞典の後ろの方にしかないレアな漢字だったり古代中国の漢字だったりする「と思われる」ので、実用上何とかなっているというだけです。どうにもすっきりしません。
しかしUnicodeの文字プロパティに対応している正規表現エンジンであれば、漢字を[\p{Han}]と疑問の余地なく簡潔に書くことができます。さらに、漢字どころか古代エジプトの象形文字を含めたあらゆる象形文字(ここでは「アルファベット」ではない文字という意味)にマッチさせたければ[\p{Ideographic}]と書くことすらできます。さらに、[\p{Ideographic}]と書くと日本語中国語韓国語ベトナム語の漢字すべてにマッチします。あなたは泣けてきませんか。私は泣きました。全世界にも泣いていただきたいものです。
なお、[\p{Han}]で表現される漢字には日本語だけではなく中国語や韓国語で使用される漢字もすべて含まれます。ホー・チ・ミンは漢字では「胡志明」と書くので、ベトナム語でマッチすることがいつの日かあるかもしれません。油断なりません。
同じように、たとえばひらがなの文字クラスは[\p{Hiragana}]とすっきり書くことができます。幸いなことに、現在は多くの正規表現で文字クラスにUnicodeの文字プロパティを使用できるようになっています。
さらに、英語や日本語どころかあらゆる言語での約物(パンクチュエーション:英語の感覚で言うとアルファベットと数字以外のすべて)とマッチさせたければ[\p{P}]と書けばよいのです。もう一度泣いてください。ただしタイ語のように句点に相当するものがそもそもない(文は半角スペースで区切る)という恐ろしい言語もありますのでご注意ください。
Unicode文字プロパティを使ってみる
それでは実際に文字プロパティを使ってみましょう。今はrubular.comなどのように正規表現をその場で試せるWebサービスがいくつもあるので助かります。以後、特に断りのない限り、rubular.comとruby 1.9の組み合わせで説明します (rubularでRuby 2.0が使えないのが何とも残念)。
[\p{Han}]と入力し、test stringに適当な日本語を入力してみましょう。こんなふうにその場で結果を確認できます。
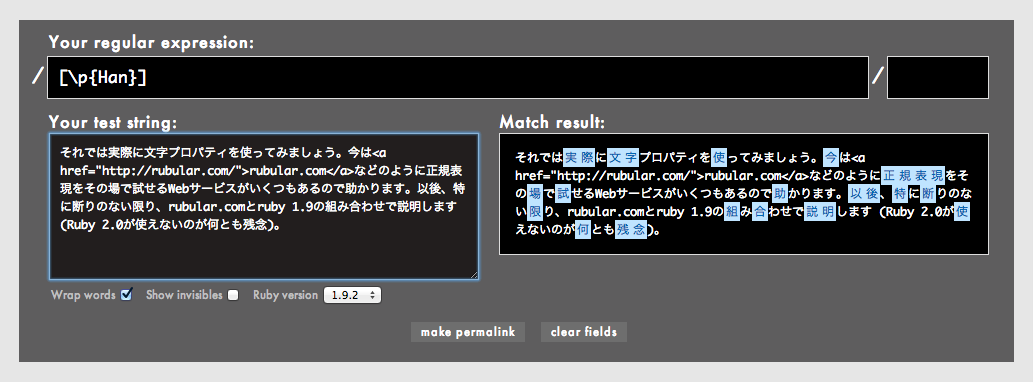
文字プロパティの表記は大文字小文字を区別しますので、hanではなくHanと書くのが正式です。Rubularでは小文字のhanでも認識されていますが、当てにしない方がよいでしょう。
ところで、Unicode文字プロパティを使用する場合はできるだけ(必ずと言いたいところです) 文字クラスを表す [ ] の中に置くようにしています。Unicode文字プロパティは本質的に文字クラスを表現するためのものだからです。perlなど一部の言語では [ ] で囲まなくても文字クラスを使用できてしまいますが、行儀がよろしくありません。.NET Frameworkのように [ ] で囲まないとエラーになるのが望ましい実装と言えます。
では今度は[\p{han}\p{Katakana}]と書いてみましょう。今度は漢字とカタカナだけにマッチしました。皆様御存知の通り、文字クラスでは記述の順序は無関係です。
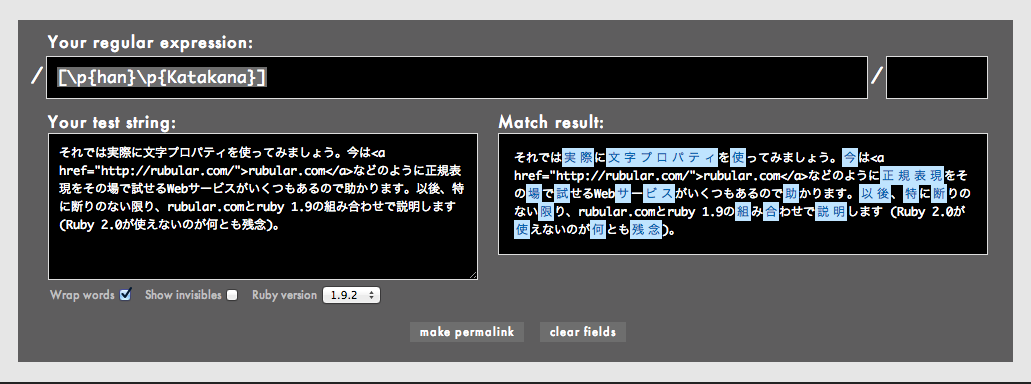
おやおや、ちょっと変です。「サービス」の長音がマッチしていません。どうなっているのでしょうか。
ここで強い味方をご紹介します。w3cのrichard ishidaさんのwebサイト (https://r12a.github.io/applist) では文字コードに関する強力かつ美しいWebツールがいくつも公開されていて、私は日々拝み倒しながら使っておりますが、その中からString analyserを使いましょう。Text you want to look upボックスにこの長音文字を入力してGoをクリックしてみましょう。
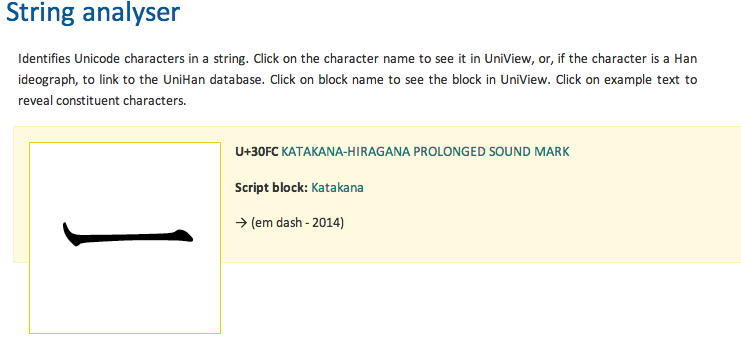
こんなに大きな長音文字をまじまじと眺めることは人生においてそうないと思います。実はこんな形をしているんですね。漢字の一にも似ていますが、もちろん違う字です。
さて、ここにはScript block: Katakanaと明言されています。その文字をクリックしてみれば一目瞭然 (「ヿ」みたいに生まれてこのかた一度も見たことのないようなカタカナまで出てきて胸騒ぎがしますが)。
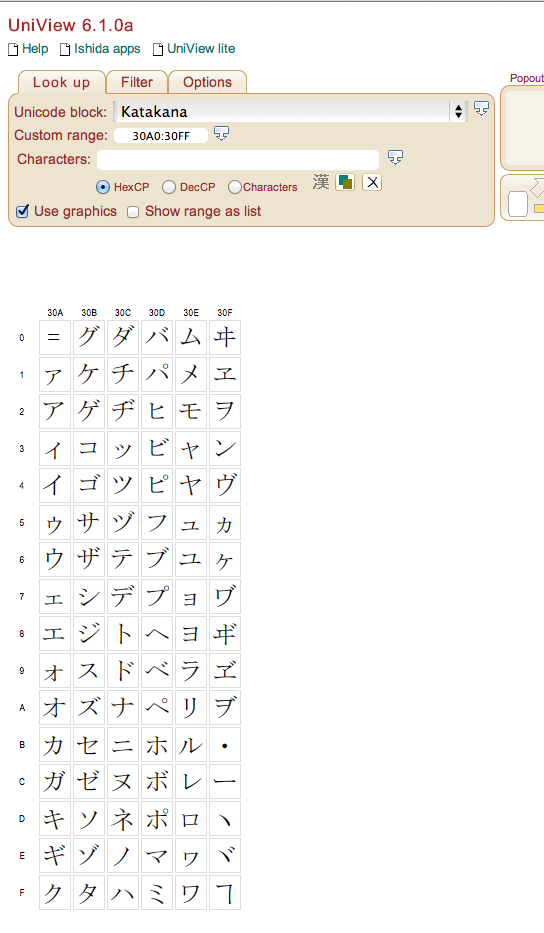
はい、これにてRuby 1.9(というかonigurumaですね)のKatakana文字プロパティの落とし穴が発覚しました。バグが発覚しました。w3cとUnicodeコンソーシアムの関係はよくわかりませんが、あのw3cの中の人が長音文字はカタカナですと言っているのですから、そうでないのはおかしいですね。
心配になってきました。Ruby 2.0のonigumoではどうでしょうか。
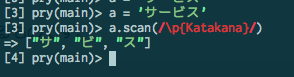
何ということでしょう。こちらも長音がKatakanaに含まれていません。
これを回避するには、[\p{Katakana}ー]のように文字クラスに長音をじかに追加してください。Katakanaでスッキリといかないのが残念ですが、バグが修正されるまでの辛抱です。
と偉そうに書いてますがこれに気付いたのはついさっきです。文字プロパティは正規表現ごとに実装がかなり異なっているので、皆様もPerlやPythonやPHPなどでこの辺りをチェックして青ざめてみたりプルリクしたり月に向かって吠えたりしてください。
このバグがこれまで発覚せずにここまで来てしまったのも、文字プロパティを使う人が少ないからです。それにしても、こうした文字プロパティを使う人が少なすぎます。もっとじゃんじゃん使ってください。叩けば他にもホコリが出るかもしれません。
日の当たらない正規表現シリーズ、次回に続きます。
緊急追記
上の記事で[\p{Katakana}]に長音が含まれないのは仕様であり、正しいとの情報をいただきました。
私も今になって知ったのですが、\p{}で参照されるのは以下でいうScriptsの方であり、Blocksではないのだそうです。
http://www.unicode.org/Public/UNIDATA/Scripts.txt
http://www.unicode.org/Public/UCD/latest/ucd/Blocks.txt
おかげさまで勉強になりました。ありがとうございます!
次回にこの辺りを研究します。