🔗 目次
- まえがき
- 解決したい問題
- 完成品
- 環境紹介
- まずはVRMファイルを用意する
- 環境構築
- VRMを画面に表示してみる
- VOICEVOXでしゃべってもらう
- 簡単なリップシンクを実装する
- 参考記事
- クレジット
まえがき
皆様こんにちは、BPSの協力会社として横浜を拠点に活動しております、株式会社ECNのFuseです。
突然ですが、みなさんは読書、してますか?そろそろ読書感想文の季節ですね。
ここ最近は雨で外に出ることが少なくなり、読書の機会も増えてきました。
ですが…
↑目次に戻る
解決したい問題
やっぱり一人で読書は寂しいものです。読書会とか参加できればいいのですがコミュ障の私には少ししんどいので
今日はフロントエンド技術を活用して指定したテキストを読みきかせてくれる女の子を錬成します。
完成品
動作動画
ソースコード

環境紹介
| 言語&フレームワーク&パッケージマネージャ | バージョン |
|---|---|
| node.js | v16.18.0 |
| typescript | 4.9.5 |
| npm | 8.19.2 |
| yarn | 1.22.19 |
| react | 18.2.0 |
| ライブラリ&パッケージ | バージョン |
|---|---|
| three | ^0.153.0 |
| react-three-fiber | 6.0.13 |
| @pixiv/three-vrm | ^1.0.10 |
| @types/three | ^0.152.1 |
| その他 | バージョン |
|---|---|
| UniVRM | 0.110.0_3f7d |
| VOICEVOX | 0.13.3 |
まずはVRMファイルを用意する
▶補足 : VRMとthree-vrmって何?(クリックで展開)
VRMとは
「VRM」はVRアプリケーション向けの人型3Dアバター(3Dモデル)データを扱うためのファイルフォーマットです。 glTF2.0をベース>としており、誰でも自由に利用することができます。
<
div style="text-align:right;"> VRMドキュメントより引用
VRMはVRMコンソーシアムという団体が提唱し、普及を進めている3Dアバター用ファイルフォーマットで、
- モデリングの知識がなくても比較的簡単に作成可能
- VroidStudioというソフトで作成可能。絵が描けなくともある程度は作れる
- クライアント側で作成したモデルを読み込んで使うこともできる
- ゲームなどに自分の作ったキャラクターを読み込ませ登場させることもできます
- テクスチャやマテリアルが一体化しており、ロードが楽
- モデルごとに個体差が激しいモーフ名が統一されており、アニメーションの作成が楽
- スカートや髪のような「揺れ物」が標準実装されている
- モデル情報だけでなく、ライセンス周りの情報も入っている
- ライセンスを確認し、モデルの使用可否をある程度アプリ側で判断することも可能
といった特徴があります。
three-vrmとは
three.vrmはそんなVRMをthree.js上で扱うためのライブラリ。これを使えば
上記の恩恵をブラウザ上でも受けることができます。
今回はちょうど業務でReactを使用しており、その知識を生かしてこれでスマホでも
女の子の読み聞かせを聞きながら寝落ちできると思い使用することに。
VRMファイルを使った記事を書く場合、真っ先に考える事になるのは使用するモデルです。
今回は同じくECNに所属している伊藤さんがデザインした当社のイメージキャラクターを許可を取り3D化させてもらいました!
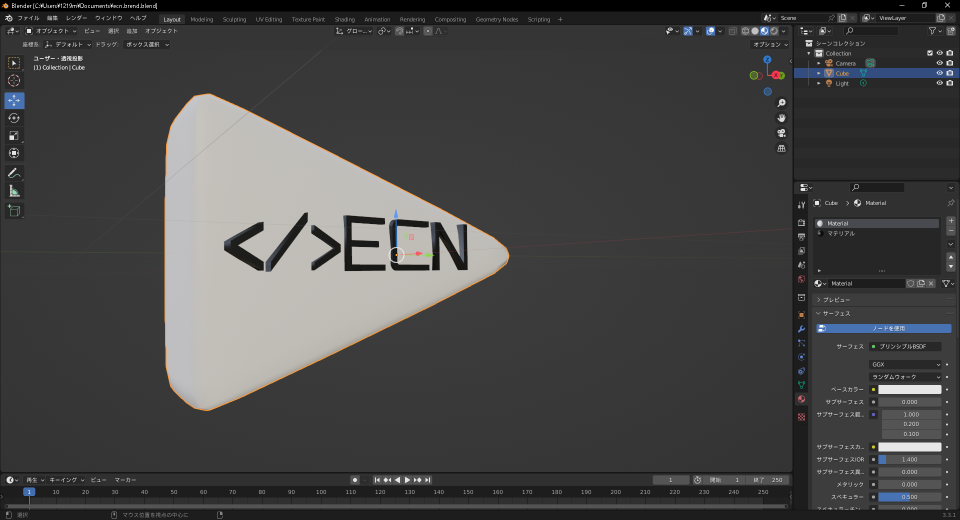
▲耳にくっつけるロゴ入りのアクセサリ
アクセサリはBlenderで作成しました。個人的に結構気に入ってます。
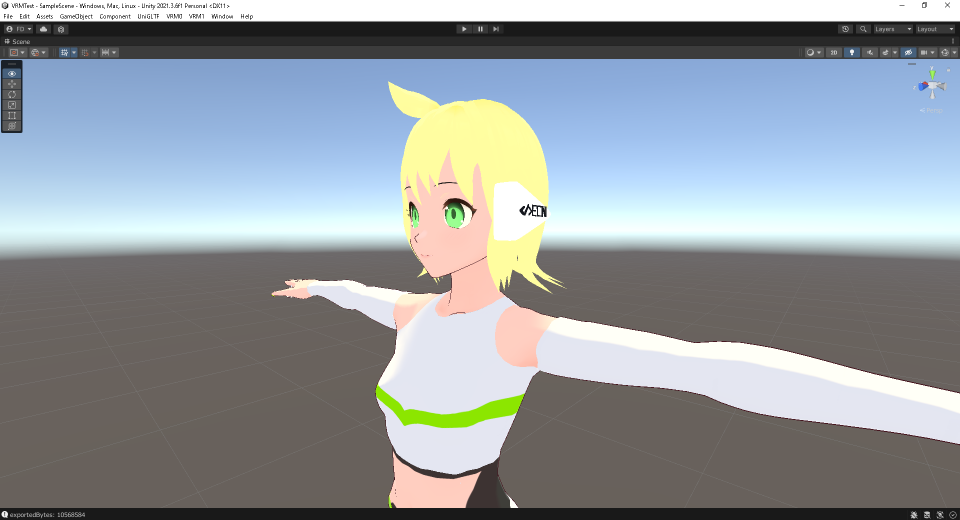
▲忘れずに頭ボーンの子に設定します。
Unityにて完成したモデルにアクセサリ類を装着し、VRMモデルとして再エクスポート!これにてモデルは完成です!
↑目次に戻る
環境構築
まずは環境構築を行います。少し長くなりますので折りたたんでます。知ってる人は飛ばしても大丈夫です。
▶yarnでの構築手順(クリックで展開)
TypeScriptを使ったReactアプリを生成し、
yarn create vite vrm_librarian --template react-ts
移動して、
cd ./vrm_librarian
最低限必要なものを一式インストールして、
yarn install
一度起動して、
npm run dev
▲いつもの画面
いつもの画面が出ることを一応確認したら
必要なパッケージを一式追加します。
yarn add -D three react-three-fiber @pixiv/three-vrm @types/three
VRMを画面に表示してみる
VRMを表示してみましょう。
生成直後のディレクトリ構成はこんな感じになっているので
vrm_librarian
├─node_modules
│ └(省略)
├─public
└─src
VRMモデルを入れるためのディレクトリを追加し、そこに先ほど作ったモデルを追加します。
vrm_librarian
├─node_modules
│ └(省略)
├─public
+│ └─VRM←ここにVRMを入れる
└─src
準備が終わったら、さっそくコードを書いていきます。
- VRMRender.tsx
import { GLTFLoader} from "three/examples/jsm/loaders/GLTFLoader.js"
import { useFrame } from 'react-three-fiber'
import { VRM, VRMUtils, VRMLoaderPlugin } from '@pixiv/three-vrm'
import { Scene, Group, Clock } from 'three'
interface Props {
url: string
}
let model:VRM | null=null
let scene:Scene | Group | null=null
const clock:Clock=new Clock(true)
export default function VRMRender(props: Props) {
useFrame(() => {//毎フレーム実装
if (model) {//モデルが読み込み済なら
model.update(clock.getDelta());//モデルの描画をアップデート
}
})
if (scene === null) {//まだシーンが読み込めてないなら
const loader = new GLTFLoader()//GLTF用のローダー
loader.register((parser) => {
return new VRMLoaderPlugin(parser)//VRM用のプラグインを登録
})
throw loader.loadAsync(//ロードを行う
props.url,
// 進捗を出力
(xhr) => {
console.log(((xhr.loaded / xhr.total) * 100).toString() + "%")
}
).then((tmpGltf) => {//ロードが完了したら
// eslint-disable-next-line @typescript-eslint/no-unsafe-member-access
const vrm: VRM = (tmpGltf.userData.vrm as VRM)//VRMのインスタンスを取り出す
console.log("ロード完了!")
model=vrm//モデルを変数に保存
VRMUtils.removeUnnecessaryJoints(vrm.scene)//不必要に結合されたジョイントを削除
VRMUtils.rotateVRM0(vrm)//VRMのバージョンが古いと後ろを向いているので前を向かせる
scene=vrm.scene//シーンを設定
}).catch((error) => {
console.log("読み込みエラー発生")
console.log(error)
})
}
return <primitive object={scene} dispose={null} />//読み込んだシーンを返す
}
詰まりどころとしてはthree-vrmは一度バージョンアップでVRM.From()関数が削除され、
モデルをロードする流れが大きく変わったのですが旧バージョンの資料しかなかったのが中々に辛かったです。
また、Suspense用にPromiseを投げるときはhooksの中で投げるとキャッチできずにエラーを吐くので気を付けましょう。
その後はVRMRender.tsxをラップしたVRMWrapper.tsxとロード中に表示されるスピナーCupeSpinner.tsxを作成し、
- VRMWrapper.tsx
import { Suspense } from 'react'
import VRMAsset from './VRMRender'
import CubeSpinner from './CubeSpinner'
export default function VRMWrapper() {
return (
<Suspense fallback={<CubeSpinner />}>//ロード中はスピナー(もどき)を表示
<VRMAsset url='./VRM/ECNちゃん.vrm' />
</Suspense>
)
}
- CubeSpinner.tsx
import { useState } from 'react'
import * as THREE from 'three'
import { useFrame } from 'react-three-fiber'
export default function CubeSpinner() {
const geometry = new THREE.BoxGeometry(0.5, 0.5, 0.5);
const material = new THREE.MeshBasicMaterial({ color: 0x00ff00 });
const [scene] = useState<THREE.Scene>(new THREE.Scene())//描画対象になるシーン
const cube = new THREE.Mesh(geometry, material);
scene.add(cube);
cube.position.y = 1
useFrame(() => {//毎フレーム実装
cube.rotation.x += 1;
cube.rotation.y += 1;
})
return <primitive object={scene} dispose={null} />
}
元からあるApp.cssを必要最低限の内容に書き換えた後に
#root {
background-color: #ffffff;
}
App.tsxを次のように書き換えます。
- App.tsx
import './App.css';
import VRMWrapper from './VRMWrapper';
import { Canvas } from 'react-three-fiber'
function App() {
return (
<div style={{ width: "100vw", height: "100vh" }}>
<Canvas flat>
<gridHelper />{/*グリッド線を床に表示*/}
<VRMWrapper /> {/*モデルを表示*/}
<ambientLight />{/*環境光を表示*/}
</Canvas>
</div>
);
}
export default App;
ファイルを保存し、アプリを開くとこのように前を向いたTスタンスのモデルが表示されます。
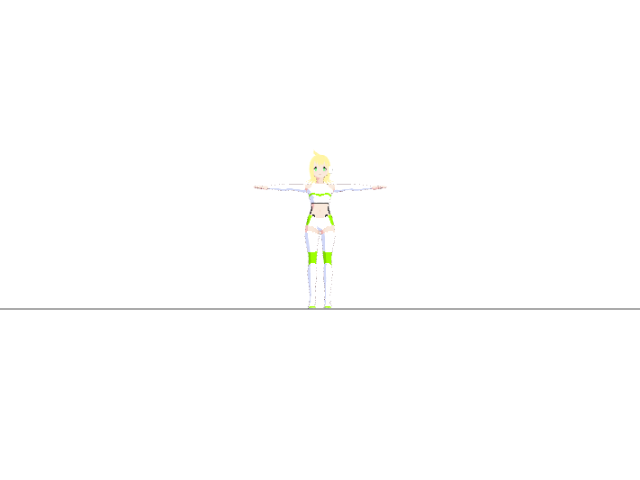
▲かわいい
ですがこのままではいくらなんでも遠すぎます。カメラの位置を調整すれば…
- App.tsx
import './App.css';
import VRMWrapper from './VRMWrapper';
import { Canvas } from 'react-three-fiber'
function App() {
return (
<div style={{ width: "100vw", height: "100vh" }}>
<Canvas flat camera={{
fov: 45, //画角
near: 0.1,//描画距離(最小)
far: 1000,//描画距離(最大)
position: [0, 1, 2],//位置を調整する
rotation: [0, 0, 0]//角度の単位はラジアンなので注意
}}>
<gridHelper />{/*グリッド線を床に表示*/}
<VRMWrapper /> {/*モデルを表示*/}
<ambientLight />{/*環境光を表示*/}
</Canvas>
</div>
);
}
export default App;
ばっちり描画できました!
↑目次に戻る
VOICEVOXでしゃべってもらう
次に女の子に読み上げてもらいたいので、VOICEVOXと連携して女の子がしゃべってくれるようにします。
VOICEVOXによる音声生成の流れについては以前の記事を見ていただけると助かります。
AudioContextにテキストから生成した音声を流すクラスTextToTalk.tsを作ります。
メソッドチェーンを使った簡潔な実装です。
- TextToTalk.ts
export class TextToTalk {
public readonly ac: AudioContext
public constructor(ac: AudioContext) {
this.ac = ac
}
public Talk(text: string) {
const url_query = `http://localhost:50021/audio_query?text=${text}&speaker=8`
const url_synth = "http://localhost:50021/synthesis?speaker=8&enable_interrogative_upspeak=true"
fetch(url_query, { method: 'post', headers: { 'accept': 'application/json' }, body: null })
.then(res => res.text())
.then(query => fetch(url_synth, { method: 'post', headers: { "accept": "audio/wav", 'Content-Type': 'application/json' }, body: query }))
.then(res => res.arrayBuffer())
.then(synth => this.ac.decodeAudioData(synth))
.then(buffer => {
const bufferSource = this.ac.createBufferSource()
bufferSource.buffer = buffer
bufferSource.connect(this.ac.destination)
bufferSource.start()
})
.catch(()=>{console.log("音声合成時エラー")})
}
}
その後、ボタンを押すと音声を再生するUI、ReadUI.tsxを作り…
- ReadUI.tsx
import { useState } from "react"
import { TextToTalk } from "./TextToTalk"
interface Props {
talker: TextToTalk
}
export default function ReadUI(props: Props) {
const [text, setText] = useState<string>("")
function TTS() {
props.talker.Talk(text)
}
return (
<div style={{position:"absolute",bottom:0}}>
<label htmlFor='text'>読み上げる文章</label>
<textarea name='text' id='text' rows={2} cols={50} defaultValue={text} onChange={(e) => { setText(e.target.value) }} />
<button onClick={() => TTS()}>読み上げ</button>
</div>
)
}
App.tsxに追加します!この時、後の実装に備えVRMWrapperにもtalkerを渡してVRMRenderにバケツリレーしておきます!
- App.tsx
import React from 'react';
import './App.css';
import VRMWrapper from './VRMWrapper';
import { Canvas } from 'react-three-fiber'
+import ReadUI from './ReadUI';
+import { TextToTalk } from "./TextToTalk"
+const talker = new TextToTalk(new AudioContext())
function App() {
return (
<div style={{ width: "100vw", height: "100vh" }}>
<Canvas flat camera={{
fov: 45, //画角
near: 0.1,//描画距離(最小)
far: 1000,//描画距離(最大)
position: [0, 1, 2],//位置を調整する
rotation: [0, 0, 0]//角度の単位はラジアンなので注意
}}>
<gridHelper />{/*グリッド線を床に表示*/}
! <VRMWrapper talker={talker} /> {/*モデルを表示*/}
<ambientLight />{/*環境光を表示*/}
</Canvas>
+ <ReadUI talker={talker} />
</div>
);
}
export default App;
- VRMWrapper.tsx
import { Suspense } from 'react'
import VRMAsset from './VRMRender'
import CubeSpinner from './CubeSpinner'
+import { TextToTalk } from './TextToTalk'
+interface Props{
+ talker:TextToTalk
+}
!export default function VRMWrapper(props:Props) {
return (
<Suspense fallback={<CubeSpinner />}>//ロード中はスピナー(もどき)を表示
! <VRMAsset url='./VRM/ECNちゃん.vrm'talker={props.talker} />
</Suspense>
)
}
- VRMRender.tsx
+import { TextToTalk } from "./TextToTalk"
interface Props {
url: string
+ talker:TextToTalk
}
無事に音声を再生することができました。
が、口が動いてないので腹話術みたいですね…
簡単なリップシンクを実装する
このままでは不気味なので、リップシンクを実装します。
リップシンクの実装にも様々な手法がありますが、今回は単純にボリュームに応じて口を開閉させます。
pixiv公式のリップシンクの実装を参考に、TextToTalk.tsを改修していきます。
- TextToTalk.ts
const TIME_DOMAIN_DATA_LENGTH = 2048;
export class TextToTalk {
public readonly ac: AudioContext
public readonly analyser: AnalyserNode;//音声解析用ノード
public readonly timeDomainData: Float32Array;//スペクトルデータ格納用配列
public constructor(ac: AudioContext) {
this.ac = ac
this.analyser = ac.createAnalyser()//AudioContextから生成する
this.timeDomainData = new Float32Array(TIME_DOMAIN_DATA_LENGTH);
}
public Talk(text: string) {
const url_query = `http://localhost:50021/audio_query?text=${text}&speaker=8`
const url_synth = "http://localhost:50021/synthesis?speaker=8&enable_interrogative_upspeak=true"
fetch(url_query, { method: 'post', headers: { 'accept': 'application/json' } })
.then(res => res.text())
.then(query => fetch(url_synth, { method: 'post', headers: { "accept": "audio/wav", 'Content-Type': 'application/json' }, body: query }))
.then(res => res.arrayBuffer())
.then(synth => this.ac.decodeAudioData(synth))
.then(buffer => {
const bufferSource = this.ac.createBufferSource()
bufferSource.buffer = buffer
bufferSource.connect(this.ac.destination)
bufferSource.connect(this.analyser)//アナライザーに接続しておく
bufferSource.start()
})
.catch(()=>{console.log("音声合成時エラー")})
}
public GetLevel(): number {//音量を取得するための関数
this.analyser.getFloatTimeDomainData(this.timeDomainData)//スペクトル情報を取得
let volume = 0.0
for (let i = 0; i < TIME_DOMAIN_DATA_LENGTH; i++) {
volume = Math.max(volume, Math.abs(this.timeDomainData[i]))//スペクトルの最大値を取得
}
volume = 1 / (1 + Math.exp(-45 * volume + 5))
if (volume < 0.1) volume = 0;//0.1未満は0とみなす
return volume
}
}
GetVolume()を作り終えたら、VRMRender.tsxを毎フレーム音量を取得し口を開閉できるように作り変えればリップシンクは完成です!
- VRMRender.tsx(一部抜粋)
useFrame(() => {//毎フレーム実装
if (model) {//モデルが読み込み済なら
model.update(clock.getDelta());//モデルの描画をアップデート
model.expressionManager?.setValue("aa",props.talker?props.talker.GetLevel():0)//口を音量に応じ開ける
}
})
無事、音声に合わせて口を動かすことができました!
最終的なディレクトリ構造とファイル一覧
vrm_librarian
│ .eslintrc.cjs
│ .gitignore
│ index.html
│ package.json
│ tsconfig.json
│ tsconfig.node.json
│ vite.config.ts
│ yarn-error.log
│ yarn.lock
│
├─public
│ │ vite.svg
│ │
│ └─VRM
│ ECNちゃん.vrm
│
└─src
│ App.css
│ App.tsx
│ CubeSpinner.tsx
│ index.css
│ main.tsx
│ ReadUI.tsx
│ TextToTalk.ts
│ vite-env.d.ts
│ VRMRender.tsx
│ VRMWrapper.tsx
│
└─assets
react.svg
参考記事
- ReactのSuspense対応非同期処理を手書きするハンズオン
-
React (Typescript) + react-three-fiber + three-vrmでVRMモデルを表示してみる #React
クレジット
利用音声
![]()
株式会社ECNはPHP、JavaScriptを中心にお客様のご要望に合わせたwebサービス、システム開発を承っております。
ビジネスの最初から最後までサポートを行い
お客様のイメージに合わせたWebサービス、システム開発、デザインを行います。
