🔗 ChatGPTのしくみとAI理論の根源に迫る:(3/16)AIの「モデル」とは何か(翻訳)
たとえば、(1500年代後半にガリレオが行ったのと同じように)ピサの塔の各階から下に投げ落とした丸い砲弾が地面に落ちるまでの時間を知りたいとします。
各階から投下された大砲の弾が地面に落ちるまでの時間を知りたければ、1階の場合にかかった時間、2階の場合にかかった時間...という具合に全部の階について地道に時間を計測し、その結果を表にまとめてもよいでしょう。
しかし、測定するだけが能ではありません。ちまちま時間を測定して記録しなくても、理論科学の真髄とも言える方法、すなわち、回答を計算する手順を与えてくれるモデル(model)1を作る方法を使ったってよいのです。
丸い砲弾を何階から落とすと、下まで落ちるのに何秒かかるか、という以下のような(そこそこ理想化された)データが手元にあるとしましょう。
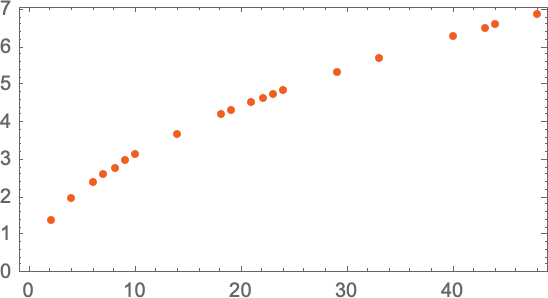
上のデータには、あいにく空白の部分があります。つまりその階での測定データがないということです。そのような「データにない階から砲弾を落としたときの時間」を計算で得るにはどうしたらよいでしょうか?
もちろん、これは物理学における「わかりきった」問題なので、既知の物理法則を応用すれば、このような特殊ケースでも、計算で空白のデータを埋めることは可能です。
物理学はそれでよいのですが、それ以外の分野(たとえばAI)で、測定データしかなく、どんな基本法則が現象を支配しているかも判明していないような世界では、データの空白部分を何らかの方法で数学的に推測する形で埋めることになります。
たとえば、以下のような直線をモデルとして使えばうまくいく「かもしれません」。
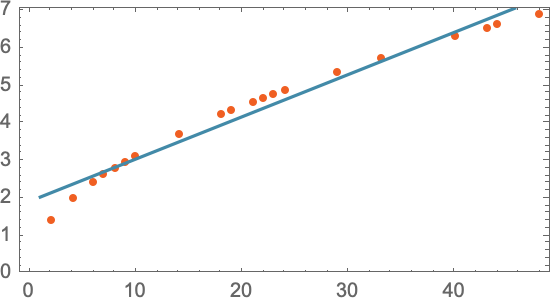
どんな直線を選ぶかは1種類とは限らず、いろんな直線の選び方が考えられますが、上のグラフの場合は、与えられたデータに対して平均的な距離が最も短い(つまり近い)直線を選んでいます。この直線を使えば、どの階についても、砲弾が下まで落ちるのに何秒かかるかを、曲がりなりにも推定できます。
さて、そもそも私たちは、上の予測を立てるために「なぜ」直線を使うことを選んだのでしょうか?実は、直線を使ったことについて別に深い理由はありません。単に、直線は数学的にも単純なので、データが十分揃っていれば、こうやって雑に直線をびっと引くような数学的操作でもうまくいくことに、私たちが慣れているというだけのことです。
上のような雑な直線で近似する代わりに、もっと数学的に複雑な方法(たとえば )を試してみれば、運よく以下のように精度を上げられる「かもしれません」。
)を試してみれば、運よく以下のように精度を上げられる「かもしれません」。
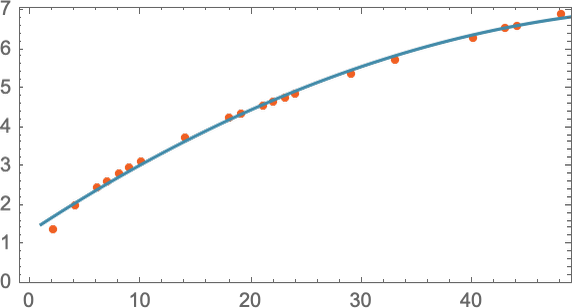
ただし、古典物理学のようにわかりきった世界ならともかく、AIのような未知の世界では、数学的に複雑なものを選んでおけばうまくいく、とは限りません。
たとえば、 をWolframの
をWolframのFindFitというツールで無理やりフィットさせようとしても、以下のように失敗します。
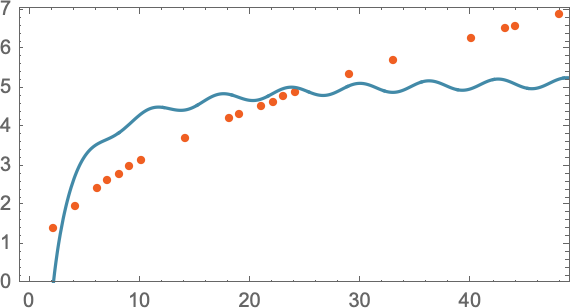
ここで、AIにおいて「モデルレスモデル(model-less model)」というものは決して存在しないことをぜひとも理解しておかなくてはなりません。「モデルのないのがモデル」というものはありえないのです。
どんなモデルを使おうと、そのモデルの中には必ず何らかの構造があり、そこには、自分たちのデータと適合させるための設定用パラメータ(parameter)(いわゆるダイヤルやノブのようなもの)がずらりと揃っているものなのです。
そしてChatGPTの場合、1750億個もの「大量のつまみ」が使われています。
しかし驚くべきことに、確かにそういうパラメータは大量に使われていますが、ChatGPTの基本的な構造には、たった1750億個のパラメータ2があれば、十分機能できるのです。つまり、たった1750億個程度のパラメータがあれば、次にどんな語が来るかという確率を計算できるモデルを作れるようになりますし、それを用いれば、まともな文章を十分な長さで生成できるようになるのです。
概要
原文サイトのCreative Commons BY-NC-SA 4.0を継承する形で翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。原文が長大なので、章ごとに16分割して公開します。
スタイルについては、かっこ書きを注釈にする、図をblockquoteにするなどフォーマットを適宜改善し、文面に適宜強調も加えています。
元記事は、2023年2月の公開時点における、ChatGPTを題材とした生成AIの基本概念について解説したものです。実際の商用AIでは有害コンテンツのフィルタなどさまざまな制御も加えられているため、そうした商用の生成AIが確率をベースとしつつ、確率以外の制御も加わっていることを知っておいてください。
本記事の原文を開いて、そこに掲載されている図版をクリックすると、自分のコンピュータでもすぐに実行して試せるWolfram言語コードが自動的にクリップボードにコピーされるようになっています。
コモンズ証 - 表示 - 非営利 - 継承 4.0 国際 - Creative Commons