概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: Using Atomic Transactions to Power an Idempotent API
- 原文公開日: 2017/09/06
- 著者: @brandur
- サイト: https://brandur.org/
アトミックなトランザクションで冪等APIを強化する(翻訳)
ソフトウェア業界ではいろんな人がさまざまなことに取り組んでいますが、新しい埋め込みファームウェアの開発者でもなければ、現代のソフトウェア開発の根幹であるHTTP上でリクエストを処理するCRUDアプリを構成する要素は10個程度です。多くのアプリの背後にはRuby on RailsやASP.NETといったMVCフレームワークや、PostgreSQLやSQL ServerといったACID準拠のリレーショナルデータベースがあります。
過酷な本番環境は、HTTPリクエストの処理中にありとあらゆる不測の事態を呼び起こす可能性があります。クライアントの切断、リクエスト処理中に失敗するアプリケーションのバグ、そしてタイムアウトは、いずれも平常時のリクエスト量でも十分発生しうる特殊条件です。データベースはトランザクションによって完全性の問題からアプリを保護できるので、トランザクションを最大限に活用するために、このことについて少し時間を割く価値は十分あります。
1件のHTTPリクエストと1件のデータベーストランザクションの間には驚くべき対称性が存在します。(データベース)トランザクションと同様に、HTTPリクエストもやはり処理のトランザクション単位であり、開始/終了/結果がはっきりしています。クライアントは一般にリクエストがアトミックに実行されることを期待しており、そしてクライアントはそうであるかのように振る舞います(もちろん実装にもよりますが)。ここではあるサービスを例に、HTTPリクエストとトランザクションを互いにうまく作用する方法を見ていくことにしましょう。
「1対1対応」モデル
ある典型的な冪等(idempotent)HTTPリクエストを例に考えます。HTTPリクエストは背後のトランザクションと1対1対応しなければなりません。どんなHTTPリクエストも、その内部の単一トランザクションに含まれるあらゆる操作は「コミット」か「失敗」のどちらかになります。
![]()
一見すると、冪等性を要求するというのは大げさな注意事項に思えますが、多くのAPI操作の冪等性は、エンドポイントの動作や振る舞いのメッセージのやりとりの後で、冪等でない操作(ネットワーク経由でのバックグラウンドジョブ呼び出しなど)に進むことによって保つことができます。
冪等でないAPIの場合はもう少し配慮が必要になります。本記事ではそのために必要な概要を解説します。詳しくは今後別記事でフォローしようと思います。
単純なユーザー作成サービス
それでは、単純な「create user」エンドポイントを提供する簡単なテストサービスを作ります。クライアントがemailパラメータ付きでリクエストを送信すると、エンドポイントは201 Createdステータスでレスポンスを返してユーザーが作成されたというシグナルを伝えます。エンドポイントは冪等でもあり、クライアントが同じパラメータでエンドポイントにリクエストを送ると200 OKステータスでレスポンスを返して問題がないことを伝えます。
PUT /users?email=jane@example.com
この動作の背後では以下の3つが行われています。
- ユーザーが既に存在するかをチェックし、存在する場合は中断して何もしない。
- ユーザーのレコードを1つ新規作成する。
- 新しい「ユーザーアクション」レコードを1つ挿入する。これはユーザーIDやアクション名やタイムスタンプへの参照を持つ監査ログでも使われる。
ここではPostgreSQL、Ruby、ORM(ActiveRecordまたはSequelスタイル)で実装しますが、上のコンセプトはどんな技術を使った場合にも応用できます。
データベーススキーマ
このサービスではシンプルなPostgreSQLスキーマを定義し、usersとuser_actionsのテーブルを含めます1。
CREATE TABLE users (
id BIGSERIAL PRIMARY KEY,
email TEXT NOT NULL CHECK (char_length(email) <= 255)
);
-- "user action"監査ログ
CREATE TABLE user_actions (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL REFERENCES users (id),
action TEXT NOT NULL CHECK (char_length(action) < 100),
occurred_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
バックエンドの実装
サーバーのルーティングではユーザーが存在するかどうかをチェックします。存在する場合はすぐにレスポンスを返し、存在しない場合はユーザーとユーザーのアクションを作成してからレスポンスを返します。トランザクションのコミットはどちらの場合も成功します。
put "/users/:email" do |email|
DB.transaction(isolation: :serializable) do
user = User.find(email)
halt(200, 'User exists') unless user.nil?
# ユーザーを作成
user = User.create(email: email)
# ユーザーのアクションを作成
UserAction.create(user_id: user.id, action: 'created')
# 成功のレスポンスを返す
[201, 'User created']
end
end
このときに生成されるSQLでは、おおよそ以下のような感じでINSERTに成功します。
START TRANSACTION
ISOLATION LEVEL SERIALIZABLE;
SELECT * FROM users
WHERE email = 'jane@example.com';
INSERT INTO users (email)
VALUES ('jane@example.com');
INSERT INTO user_actions (user_id, action)
VALUES (1, 'created');
COMMIT;
並列性の保護
察しのよい方なら、ある問題がここに潜んでいることに気づくでしょう。usersテーブルのemailカラムにはUNIQUE制約がありません。この制約がない場合、2つの別のトランザクションがSELECT部分を同時に実行すると結果が空になる可能性が生じます。どちらのトランザクションもその後にINSERTを実行するので、行が重複したままになってしまいます。
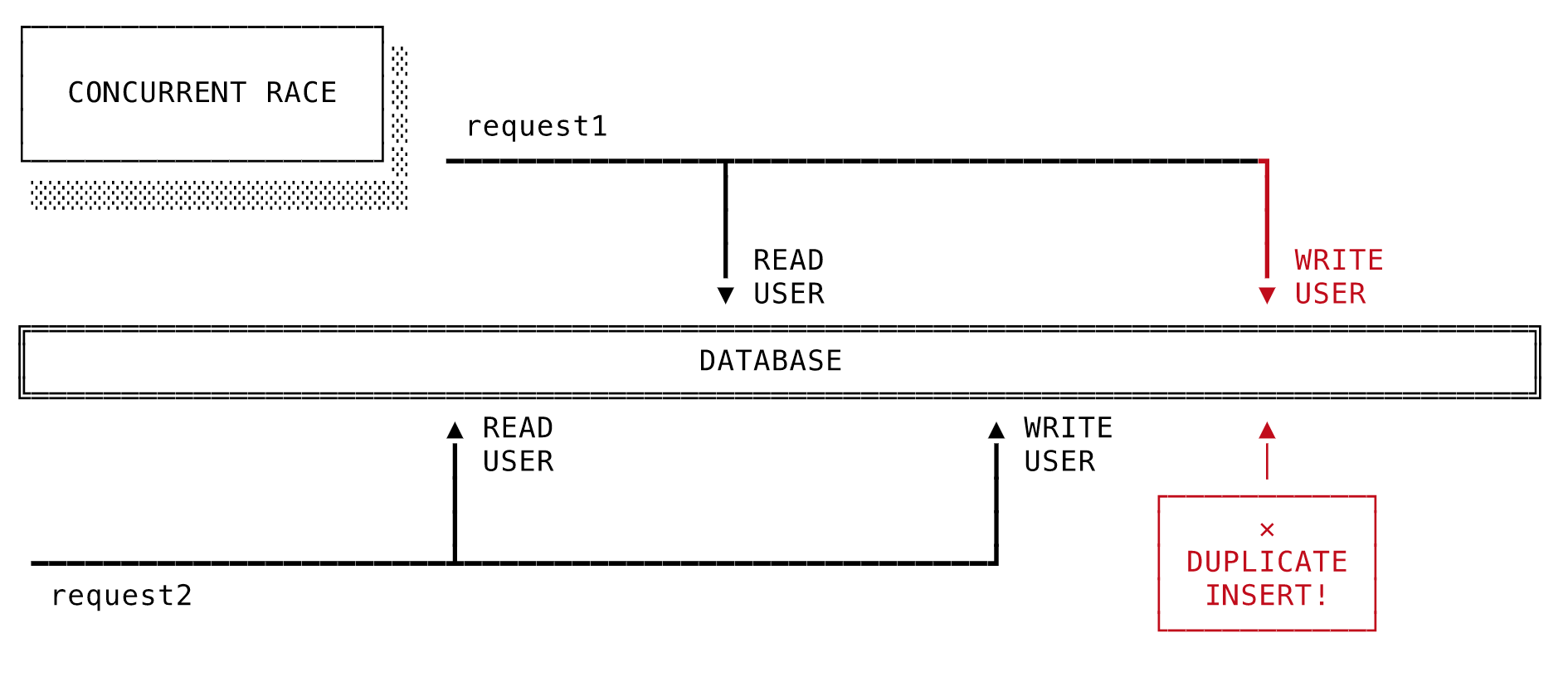
幸い、上の例では既にUNIQUE制約よりも強力なメカニズムを用いてデータの正しさを保護しています。DB.transaction(isolation: :serializable)でトランザクションを呼び出すと、トランザクションがSERIALIZABLEという独立性(isolation)レベルで開始されるので、魔法のように強力にデータの正しさを保証します。この独立性レベルは、未決の各トランザクションが同時ではなく順次実行されているかのようにトランザクションの直列実行をエミュレーションします。仮に上の例で競合が発生すると、トランザクションの1つが他方の結果を汚してしまうので、一方が次のメッセージを表示してコミットに失敗します。
ERROR: could not serialize access due to read/write dependencies among transactions
DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt.
HINT: The transaction might succeed if retried.
ここではSERIALIZABLEの仕組みには立ち入りませんが、SERIALIZABLEが多種多様なデータ競合を検出できることと、競合時にコミットしようとするとトランザクションが失敗することを知っておけばよいでしょう。
失敗のリトライ
このコード例でも競合はめったに発生しませんが、競合によってHTTP 500エラーがクライアントに表示されないようアプリのコードで正しく扱いたいと思います。これを行うには、リクエストのコアとなる操作をループでラップします。
MAX_ATTEMPTS = 2
put "/users/:email" do |email|
MAX_ATTEMPTS.times do
begin
DB.transaction(isolation: :serializable) do
...
end
# 成功: ループを終了する
break
rescue Sequel::SerializationFailure
log.error "Failed to commit serially: #{$!}"
# 失敗: 次のループにフォールスルーする
end
end
end
この例で、HTTPリクエストにマップされる同じトランザクションが次のように複数発生したとします。
![]()
これらのループは通常よりもコストがかかりますが、上述のとおり異常な競合から保護するために行っています。実際には、呼び出し側がよほど連続でリクエストをかけない限りめったに発生しません。
これはSequelなどのgemを使えば自動的に行えます(このコードは先のループと同様に振る舞います)。
DB.transaction(isolation: :serializable,
retry_on: [Sequel::SerializationFailure]) do
...
end
レイヤーでのデータ保護
ここまでシリアライズ可能なトランザクションの威力をお目にかけましたが、現場ではシリアライズ可能な独立性レベルを使いながら同時にemailにUNIQUE制約もかけたいと思うでしょう。INSERTの重複はSERIALIZABLEで保護できますが、誤ったトランザクション呼び出しやバグを含むコードからもアプリを保護するチェックとしてUNIQUE制約を追加することには価値があります。
バックグラウンドジョブ
重い操作でクライアントを待たせないために、HTTPリクエスト中にバックグラウンドキューにジョブを追加して帯域外で実行するのはよく使われるパターンです。
上述のuserサービスにもうひとつ手順を追加しましょう。userやuserアクションのレコードの作成に加えて、新しいアカウントが1つ作成されたことを外部のサポートサービスに通知するAPIリクエストを作成します。このジョブをリクエスト帯域内で行わなければならない理由はないため、バックグラウンドジョブとしてキューに入れることにします。
put "/users/:email" do |email|
DB.transaction(isolation: :serializable) do
...
# 新しいユーザーが作成されたことを
# 外部サポートサービスに通知するジョブをキューに入れる
enqueue(:create_user_in_support_service, email: email)
...
end
end
これをSidekiqなどの一般的なジョブキューで行うと、トランザクションのロールバック時(上述の2トランザクション競合の場合など)にキューのジョブが不正になってしまうかもしれません。ジョブが参照しようとするデータは既に存在しないので、ジョブワーカーが何度リトライしても成功するはずはありません。
トランザクションをステージングするジョブ
これを回避する方法の1つは、データベースにジョブのステージング用テーブルを作成することです。ジョブをキューに直接送信するのではなく、最初にステージング用テーブルに送り、キュー追加を担当するenqueuerが後でテーブルを一括読み出ししてジョブキューに置きます。
CREATE TABLE staged_jobs (
id BIGSERIAL PRIMARY KEY,
job_name TEXT NOT NULL,
job_args JSONB NOT NULL
);
enqueuerはジョブを選択してキューに置き、その後ステージング用テーブルからジョブを削除します2。以下はおおまかな実装です。
loop do
DB.transaction do
# 長大なバッチからジョブを読み出す
job_batch = StagedJobs.order('id').limit(1000)
if job_batch.count > 0
# それぞれを実際のジョブキューにINSERTする
job_batch.each do |job|
Sidekiq.enqueue(job.job_name, *job.job_args)
end
# これらのレコードを同じトランザクションから削除する
StagedJobs.where('id <= ?', job_batch.last).delete
end
end
end
ジョブは1つのトランザクション内でステージング用テーブルに挿入されるため、独立性(ACIDの「I」)によって、INSERTトランザクションがコミットされるまで他のトランザクションから見えなくなることが保証されます。ロールバックしたステージングジョブはenqueuerからは決して見えないため、ステージングからジョブキューが作成されることもありません。
私はこのパターンを「transactionally-staged job drain」と呼んでいます(訳注: 著者の考案したパターンのようです)。
Queなどのライブラリを使ってジョブキューをデータベースに直接置く方法も一応可能ですが、PostgreSQLなどのシステムでは肥大化の危険があるため、おそらくよいアイデアにはならないでしょう。
冪等でないリクエスト
本記事で取り上げた方法は、互いに冪等なHTTPリクエスト同士をうまく扱うことができます。よく設計されたAPIの大半はおそらくこのように健全でしょう。しかしエンドポイントが冪等でないことも必ずありえます。例としては、クレジットカードの外部支払いゲートウェイへの問い合わせや、プロビジョニングされるサーバーへのリクエスト、その他同期的なネットワークリクエストが必要なすべてのケースが考えられます。
そのようなリクエストの場合はもう少し洗練された手法が必要ですが、本記事のシンプルなケースと同様、本記事で使ったデータベースではその点をカバーしています。本記事のパート2では、ステージングを複数持つ(マルチステージング)トランザクションの最上位で冪等なキーを実装する方法を取り上げます。