こんにちは、hachi8833です。「ライフ」カテゴリの記事でアドベント書きたかったのですが、こちらの小ネタにします。
正規表現の先読みと後読みについては「正規表現の先読み・後読み(look ahead、look behind)を活用しよう」をご覧ください。
以下は基本的にRubyの正規表現(onigmo)を使います。他の正規表現ライブラリではこのとおりにならない可能性があります。
Rubyの正規表現の後読みは長さを不定にできない
以下の文字列が対象です。
word work wording working interesting partitioning subscribe subscriber subscription
量指定子の場合
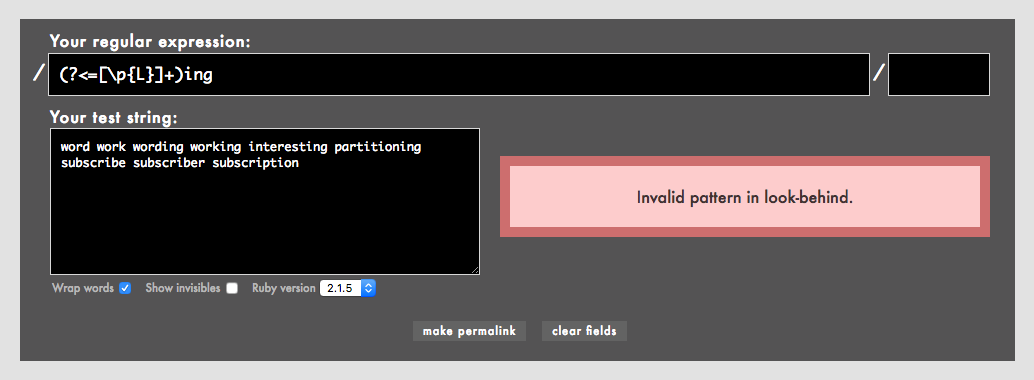
たとえば、ingで終わる1文字以上の長さの英単語のingだけにマッチさせたいと思って次の正規表現を書いたとします。+は1文字以上のマッチを表します。
(?<=[\p{L}]+)ing
しかしやってみると、Invalid pattern in look-behind.と表示されます。なお、+を最小一致の+?に変えてもだめでした。
代替|の場合(更新2021/10/14)
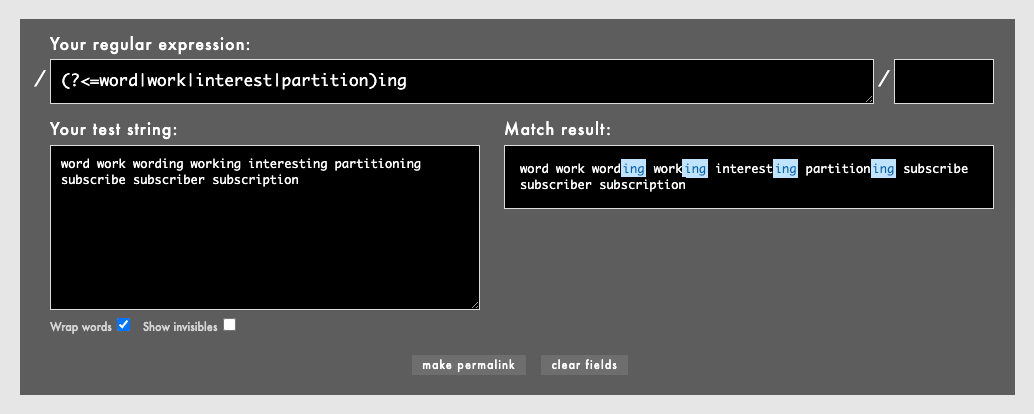
任意の長さの代わりに、代替|を用いて長さの異なる特定の語のリストを後読みで使うとどうなるでしょうか。
(?<=word|work|interest|partition)ing
代替|のリストは通ります。よかった!
- (Rubular)
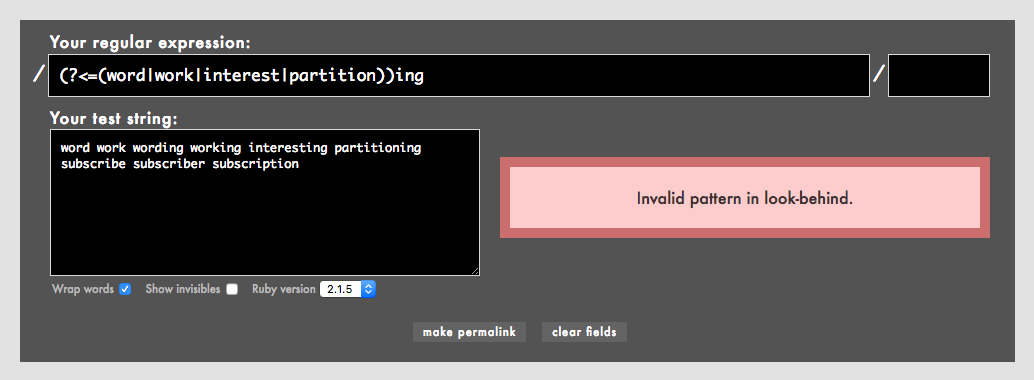
しかし以下のように同じ代替|のリストをグループ()で囲むとどうなるでしょう。
(?<=(word|work|interest|partition))ing
代替|をグループ()で囲むと残念ながらInvalid pattern in look-behind.になりました。
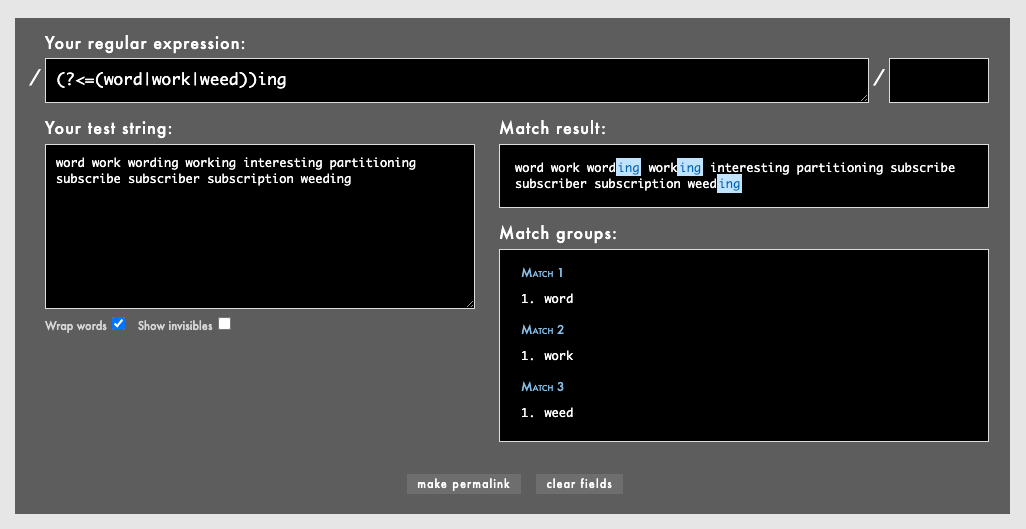
ただし以下のようにリスト内の各要素の長さをすべて同じにすれば、代替|をグループ()で囲んでも通ります。
(?<=(word|work|weed))ing
なぜ後読みで量指定子が使えないのか
後読みは本体がマッチした後で文字どおり遡ってチェックされるはずなので、量指定子(quantifier: 量化子とも呼ばれます)の長さが不定だと効率が非常に落ちることは想像がつきます。Onigmoの仕様まではチェックしていませんが、おそらくそうした理由で長さ不定の後読みをサポートしていないのではないかと推測しています。
ちょっとだけPerlでも試してみましたが、こちらもnot implementedだそうです。
$ perl -e '"word work wording working interesting partitioning subscribe subscriber subscription" =~ /(?<=[\\p{L}]+)ing/;'
Variable length lookbehind not implemented in regex m/(?<=[\\p{L}]+)ing/ at -e line 1.
後読みに使える量指定子
Rubyの場合、少なくとも次のように{,10}{4}のように長さを固定した量指定子では後読みが機能します。これがなかったらわたし的につらいです。
(?<=\b[\p{L}]{4})ing
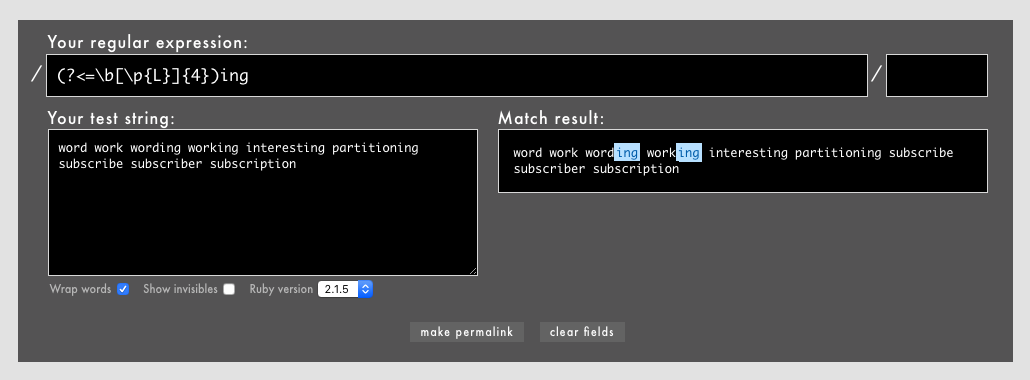
追記(2018/10/25): 少なくとも、
+、*、?、{N,M}、{N,}のように長さ不定の量指定子はRubularのRuby 2.1.5ではだめでした。
他にも使えるものがあるかもしれませんが、いずれにしろ量指定子を不用意に使うと効率が落ちるので、あまりやんちゃしないようにしましょう。
先読みでは長さを不定にできる
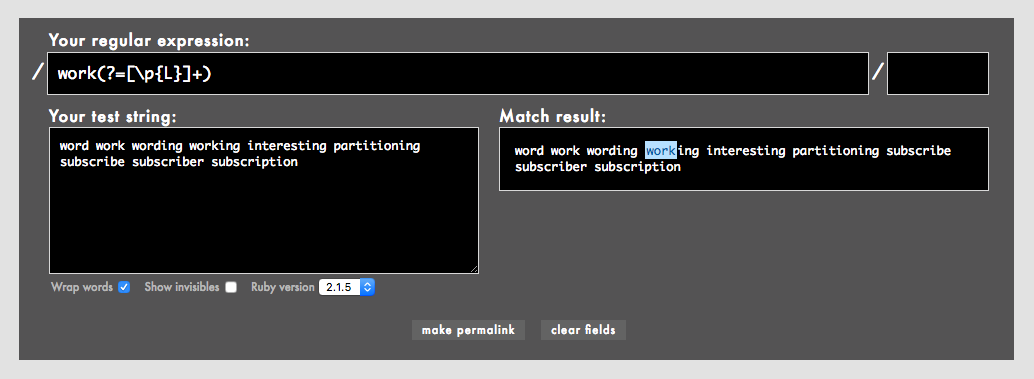
Ruby正規表現の先読み(look ahead)では、次のように長さ不定の量指定子を使えます。
work(?=[\p{L}]+)
おまけ: .NET Frameworkだとできる
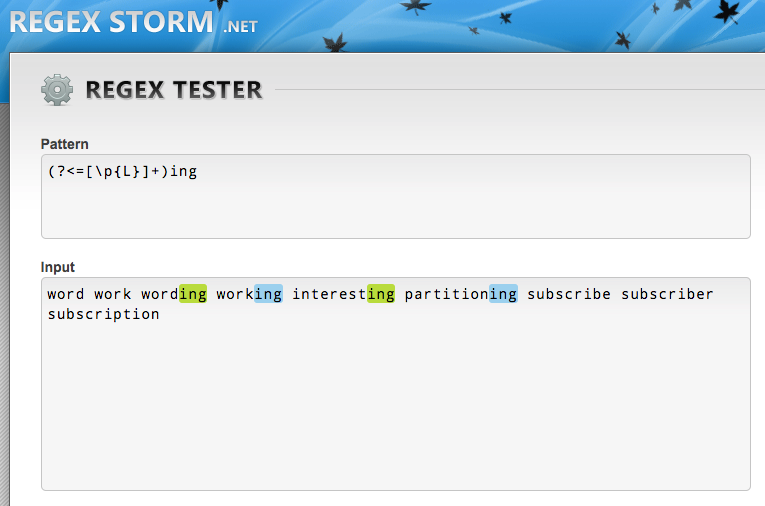
遠い昔の記憶では、.NET Frameworkでは後読みで長さ不定の量指定子を使えたはずだったので、チェックしてみました。当時はこれが当たり前だと思っていたので、他のライブラリでできないことを知ったときはショックでした。
たった今見つけたregexstorm.netというサイトで.NET Frameworkの正規表現をチェックしたところ、後読みであっさり長さ不定の量指定子を使えました。Mac環境だとおいそれと.NET Frameworkの正規表現を確認できないので、このサイトは助かります。
また、.NET Frameworkの正規表現ライブラリをGo言語に移植したdlclark/regexp2という私の大好きなパッケージで試したところ、こちらでも長さ不定の量指定子を使えました。
package main
import (
"fmt"
"github.com/dlclark/regexp2"
)
func main() {
re, err := regexp2.Compile("(?<=[\\p{L}]+)ing", 0)
if err != nil {
fmt.Println("err compile: ", err)
}
ma, err := re.FindStringMatch("word work wording working interesting partitioning subscribe subscriber subscription")
if err != nil {
fmt.Println("err match: ", err)
}
fmt.Println(ma)
}
$ go run regexp2.go
ing
効率を犠牲にしても後読みで長さ不定の量指定子をサポートしているのか、それとも実装が凄いのかは調べていませんが、私の中ではやはり.NET Frameworkの正規表現が今のところ最強です。
フィードバック
ちょっと前の記事だけど、「後読みに使える量指定子」のパターンは、{,10}が文字クラスの中にあるし、余分なスペースがあるので量指定子になっていないと思います。 /cc @hachi8833https://t.co/EWbNBVeOOZ
— Akinori Musha (@knu) October 25, 2018
ご指摘ありがとうございます!修正しました。
更新情報