⚓ 正規表現とは何か
正規表現は「Regular Expression」を直訳したもので、しばしばRegexpとかRegexと略されます(たまにREとも略されます)。正規表現について詳しく説明するときりがありませんが、さしあたって「言語やツール内で利用できる一種のサブ言語」と考えておけばほぼ間に合います。
前回ご紹介した、正規表現に用いられる特殊な記号をメタ文字(メタキャラクタ)と呼びます。
たとえば、以下は正規表現の例です(Rubular)。
[。、,.]{2,}
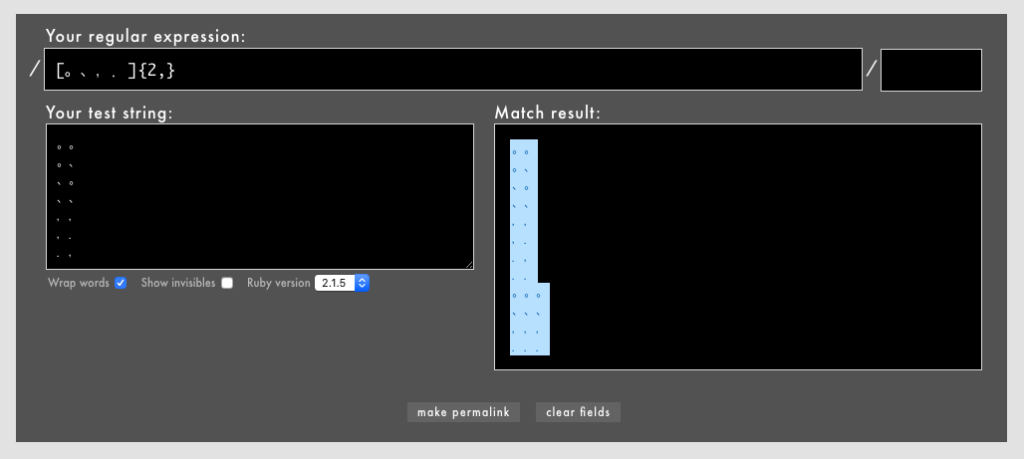
これは、『「。」「、」「,」「.」のいずれかが2文字以上続いている』ことを表しています。「。。」のように同じ2文字の連続だけではなく、「。、」のように異なる2文字にもマッチします。
⚓ 補足: 正規表現は理論が先に生まれた
正規表現は、理論が実装よりも先に誕生している点が特徴で(SQLも理論から先にできた言語です)、言語学や形式言語理論などの研究の過程で編み出された表現手段の一種です。当初は、表現に不可欠なごくわずかな記号しかなかったようです。
それが後にコンピュータでの文字列の検索や置き換えの表現方法として取り入れられ、実装や拡張が繰り返されて現在に至っています。
正規表現の背景などについて詳しくはWikipediaや正規表現をチョムスキー言語学まで遡って理解する(翻訳)などに譲ります。
参考: 正規表現 - Wikipedia
⚓ 正規表現機能の使いみち
正規表現は、コンピュータでの検索や置き換えの対象となる文字列を指定するのに使われています。
- 基本機能
- 特定の文字パターンにマッチするかどうかを判定する
- Rubyなら
"文字列".match?(/正規表現/)などと書ける
- 付加機能:
- 特定の文字パターンにマッチしたものを置き換える
- Rubyなら
"文字列".gsub(/正規表現/, "置き換え文字列")
- Rubyなら
- マッチした文字パターンを分解して部分を取り出したり部分置き換えする(今後解説します)
- 特定の文字パターンにマッチしたものを置き換える
正規表現は、コード内のサブ言語の一種としての使い道の他に、テキストエディタやコマンドラインツールでも検索・置換機能のために内部でしばしば正規表現がライブラリまたは独自実装の形で利用されています。また、ApacheやSafariといった規模の大きいソフトウェアにも正規表現ライブラリが組み込まれています。
正規表現はプログラミングで「時々」とても重要になりますが、サブ言語だけあってほとんどの場合主役ではなく、一部の好き者を除いてガンガン使いまくる人はあまりいません。
現実のプログラミングでは、ある種の問題、具体的には「ある程度以上複雑な文字のマッチングや置き換え」を解決するときに使われることが多く、その場の問題が解決されればむしろ正規表現のことなど忘れていたい開発者の方が多いかもしれません。
正規表現は無理して使うものではありませんが、文字のマッチングや置き換えを扱うときに遅かれ早かれ使うことになります。また、Rubyのメタプログラミングでは正規表現が援用されることがしばしばありますので、プログラミングの幅を広げることができます。
⚓ 補足: 正規表現はプログラミング言語ではない
正規表現は言語の一種ですが、プログラミングで使われるにもかかわらず、正規表現は厳密に言うとプログラミング言語ではありません(上述のSQLもやはりプログラミング言語ではなく、クエリ言語です)。プログラミング言語と呼ばれるためには「チューリング完全」という性質を満たす必要がありますが、正規表現やSQLはこの性質を満たさないので「チューリング不完全」とされています。
なお、条件分岐とジャンプなどで「ループを形成する機能」がある言語はチューリング完全になるはずです。
チューリング不完全かどうかは、言語の良し悪しとは別です。むしろ正規表現やSQLの仕様は、積極的にチューリング完全にならないことを目指しています。これによって無限ループが原理的に発生しなくなり、どんなに時間がかかろうと「いつかは必ず終わる」ことを確信できるからです。
もし正規表現がうっかりチューリング完全になってしまうと、正規表現だけでプログラミングできるようになり、メインのプログラミング言語の役割を侵食してしまいかねません。
参考: 本の虫: うっかりチューリング完全になっちゃったもの
⚓ 正規表現を使えるCLIツールの例
正規表現の使えるコマンドラインツールとしてはgrepが有名ですが、他にも文字列置き換えに特化したsedなど、ここに書ききれないほどさまざまなコマンドがあります。
なお、私自身はripgrepというgrepよりも高機能/高速なツールを使っています。

pecoというインタラクティブなフィルタツールも非常に便利なのでよく使いますが、これにも正規表現モードがあります。

⚓ 正規表現は「ライブラリ」で実現される
正規表現の機能は、プログラミング言語やツールのコアに組み込まれることはあまりなく、多くの場合その言語やツールのライブラリ(エンジンとも呼ばれます)という差し替え可能な形で導入されます。
したがって、異なる言語であってもライブラリが同じであれば同じ正規表現が使えますし、逆に同じ言語であっても正規表現ライブラリが変更またはアップデートされれば機能が追加されたり、逆に一部で互換性がなくなることもありえます。
Rubyの場合、Onigmo(鬼雲)というライブラリが使われています。以前はoniguruma(鬼車)というライブラリでした。
正規表現をサポートするエディタの中には、正規表現のライブラリを差し替えることでより強力な正規表現の機能を使えるものもあります(秀丸エディタなど)。
⚓ 正規表現には「方言」がある
正規表現のライブラリや実装が多様であるため、残念ながら正規表現には方言がものすごく多いという問題があります。具体的には、さまざまな言語/ライブラリ/ツールで実装されている正規表現はたいてい独自拡張されています。
第1回で説明した正規表現はほぼ確実に共通で使えるのが救いです。
ライブラリやツールごとの互換性については以下のWikipediaページによくまとまっています。
参考: Comparison of regular expression engines - Wikipedia
⚓POSIX系
Linuxコマンド系ではよくPOSIXまたはPOSIX互換という言葉を見かけます。POSIXには「POSIX基本正規表現(BRE)」と「POSIX拡張正規表現(ERE)」があります。
どちらも現代(私)の目から見るとかなり機能が不足しがちで、しかも統一されているとも言えません。私は「POSIX互換」と書いてある正規表現ライブラリを見るとがっかりする方です。
かつPOSIX拡張正規表現の中には[[:name:]]だの[:alpha:]という、Unicodeコンシャスかどうかも疑わしい独特のショートハンド方言があったりします。[: :]だったり[[: :]]だったりと書式もばらつきがちです。
参考: POSIX Basic and Extended Regular Expressions
参考: POSIX Extended Regular Expression Syntax - 1.50.0
ここは私個人の意見ですが、少なくとも正規表現を複数のライブラリにまたがって使う場合、
[[:name:]]や[:alpha:]といった形式のショートハンドは避ける方が無難だと思います(ショートハンドについては今後の記事でご紹介します)。私はこれらを使いません。
少なくとも、[[:alpha:]]がその名に反して漢字やひらがなやカタカナにまでマッチしてしまうことは覚えておくとよいと思います(Rubular)。また、「POSIX基本表現だけ使えばどこででも使える」という最大公約数的な考えも現実的ではないと思います。現実に複数ライブラリで共有したいのはもっと高度な機能であることが多いので(今後扱います)、POSIX基本表現を安易に最大公約数と考えない方がよいと思っています。
⚓ PCRE系
正規表現ライブラリの中でもうひとつメジャーなのはPCREと呼ばれるPerl 5互換の正規表現ライブラリです。PCREで拡張されている正規表現はかなり強力なのですが、それでも(私には)少し足りない機能があります。
また、Perl 5はPCREそのものを用いていますが、PHPやPythonの正規表現やRubyのOnigmoなどはPCREにかなり近いながらも独自実装であり、実際にはPCREよりさらに機能が足りない部分や独自の拡張がありますので、PCREと完全互換ではありませんし、お互い同士にも互換性のない部分があります。機能が不足する場合、開発者がより強力な正規表現ライブラリを導入することもあります。
個人的には.NET Frameworkの正規表現ライブラリが総合的に見て最も強力だと思います。ドキュメントも充実しています。
通常の開発やエディタでの検索置換であれば方言を意識する必要はほとんどありませんが、正規表現を複数の言語やプラットフォームで共有する場合は、方言やライブラリ(種類やバージョン)を意識しなければならなくなります。
⚓ 正規表現の用語はあまり統一されてない
正規表現ライブラリのドキュメントで使われている用語は、ライブラリ間では統一されているとは言い難いものがあります。歴史を考えると仕方がないとも言えますが、ライブラリごとにそこそこ違っていたりするので、機能を探しているときに迷わせてくれます。その点を頭の隅に置いておきましょう。
⚓ メタ文字を含まない文字列も正規表現の一種
基本的なことですが、厳密に言うと?や+などのメタ文字を含まない単なる文字列も正規表現の一種です。言い換えると、あらゆる文字列は正規表現の部分集合とみなせます。したがって、メタ文字を含まない正規表現も「ありです」(Rubular)。
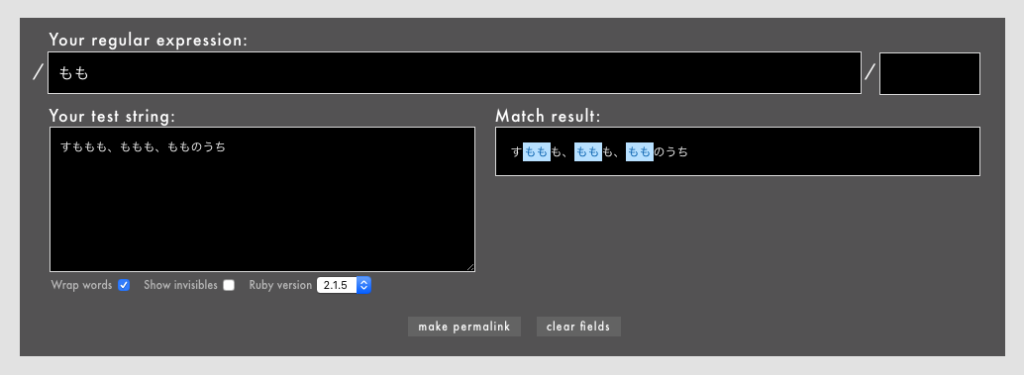
ついでながら、どこからどこまでが正規表現かを表す区切り方は言語やツールの実装によって異なります。Rubyの場合は/ /で囲むことで正規表現を表せます(他の記号を使うこともできる)が、grepなどでは" "で囲んで指定することもあります。エディタの検索窓では区切り文字が不要な場合がほとんどです。
⚓参考: 正規表現にも「AND」が隠れている
ここは今すぐ理解しなくても構いません。
前回ご紹介した正規表現の|というメタ文字は、論理演算で言う「OR」に相当します(否定については今後扱います)。
「ORがあるならANDだってあるよね?」という気持ちになるのは当然です。しかし正規表現のメタ文字をいくら探してもそんなものはありません。
実は正規表現の場合、「文字を並べて書くこと自体がANDを表す」のです。言い換えると、ANDは文字と文字とのつながりに隠れています。ANDに相当するメタ文字がないのはそのせいです。
たとえば/AB/という正規表現があるとします。これは次の意味になります。
Aという文字がある- かつ
- その後ろに
Bという文字がある
何だかあまりに当たり前な主張ですが、学問としての正規表現はミニマムをよしとするところがあって、「どんな文字列でも抽象的に表せる最小の表現方法」を追求した結果なのだと想像しています。
ANDの関係は、文字とメタ文字の間、メタ文字とメタ文字の間であっても同じように成立します。
「だからどうした?」と言われればそれまでです。このことを知ったからといって正規表現の書き方がすぐに上達するわけでもありません。しかし正規表現が複雑になり始めたときに、これが助けになることがきっとあると思いますので、何となく頭の隅にでも置いておいてください。
⚓ ワイルドカードと正規表現の違い
⚓ ワイルドカードとは
WordやExcelなどの検索置換機能、OSのファイル検索機能、シェル(bashやDOS窓など)のファイル名展開機能、一部のWebサイト内検索機能などで使われる?や*という特殊な記号をワイルドカード(wildcard)と呼びます。元々はトランプのジョーカーのような任意のカードになれる特殊なカードを指す言葉です。
*- 任意の文字列を表すワイルドカード
?- 任意の1文字を表すワイルドカード
たとえば*.txtとすると「.txtで終わるすべてのファイル名」を表現できます。
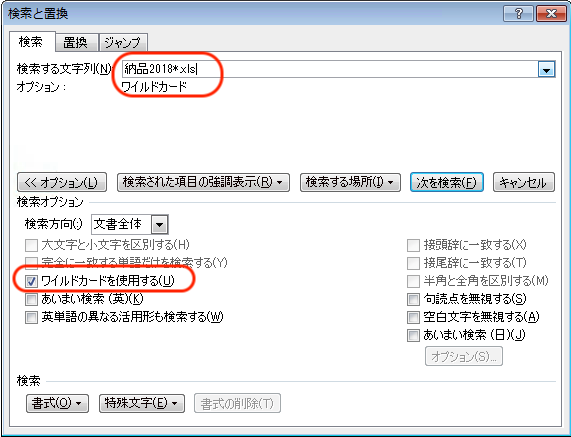
記号が2種類なので、一般ユーザーにわかりやすいのが特徴です。WordやExcelでは、ワイルドカードの機能が少し独自拡張されており、正規表現に少し似たことができます。
#「の」の連続を検出するWordのワイルドカード
[!。の]{1,}の[!。の]{1,}の[!。の]{1,}の[!。の]
参考: ワイルドカード (情報処理) - Wikipedia
参考: 【まとめ】ワイルドカード(正規表現)に関する記事一覧 | みんなのワードマクロ
⚓ ワイルドカードは正規表現ではない
しかし、ワイルドカードは正規表現とは異なるものです。
- ワイルドカードは表現力が乏しい
- ワイルドカードの記号は正規表現の記号と意味が異なる
ワイルドカードと正規表現は見た目の印象がよく似ており、Wordの拡張ワイルドカード機能は一見正規表現のように見えるので、紛らわしいのですが、少なくとも両者の?や*という記号は以下の点が決定的に異なります。
- ワイルドカードの
? - 「1文字そのものの代わりに置く」(
new?など) - 正規表現の
? - 「直前の1文字を後ろから修飾する」(
/news?/など)
- ワイルドカードの
* - 「任意の長さの文字そのものの代わりに置く」(
*.xlsなど) - 正規表現の
* - 「直前の1文字を後ろから修飾し、その文字がゼロ文字以上であることを表す」(
/./*\.xls/など)
まとめると、?や*という記号は、ワイルドカードでは「文字の代替」、正規表現では「直前の文字を修飾する量指定子」となります。
⚓ 第1回で*を紹介しなかった理由
*- 直前の1文字の0回以上の繰り返しを表すメタ文字
正規表現を使ったことがある方なら誰もが知っている*(=直前の文字のゼロ回以上の繰り返し)というメタ文字ですが、第1回ではあえて含めませんでした。
取り上げなかった理由は、ワイルドカードの*の考え方に毒されたと思われる.*という正規表現が安易に用いられることが多いためです。
正規表現の書き方は一種類ではないので「機能すればよい」と割り切ることもできますが、.*や.+といった正規表現はしばしば曖昧さにつながり、不要なマッチを呼び込みやすくなると個人的に考えています。最長一致や最短一致も意識しなければなりません。
本音を言えば、.+すら基本には含めたくなかったぐらいです。
もちろん.*や.+がどうしても必要になることもありますが、その前に{N, M}などのより限定的な量指定子が使えないか、.のような範囲の広すぎるメタキャラクタではなく[]などでもっと限定できないかを検討するようにしています(これらについては今後の記事で解説します)。
これまで多くの正規表現を書いてきましたが、幸いにして*や.*を使う機会は(使い捨ての正規表現を除けば)一度もなく、+や.+もごくたまに使う程度です。
更新履歴