主にRubyを中心としながらも、なるべく一般的な形で正規表現を解説しています。誤りやお気づきの点がありましたら@hachi8833までどうぞ🙇。
⚓Unicode文字コードポイント
Unicode文字コードポイントの表記方法も、正規表現ライブラリによってまちまちです。そもそもUnicode文字コードポイントで表せない正規表現ライブラリもたまにあります。困ったことです。
⚓その前に: Unicode文字コードポイントとは
まず、Unicodeという規格本体に文字集合(character set)というものがあります。その文字集合内の位置を表すのがコードポイント(code point: 符号点)です。
手元のかな漢字変換にある「文字パレット」を開くと、Unicodeの文字集合とそのコードポイントを見ることができます。U+00F9みたいなのがコードポイントで、16進数です。

ここで重要なのは、コードポイントはUnicodeそのものの規格なので、エンコードがUTF-8だろうと16だろうと32だろうとコードポイントは変わらないという点です。U+00F9の00F9はUnicodeのどのエンコードでも同じです。
Unicode文字コードポイントはほとんどが4桁です。
しかし、後から足された文字の中にはコードポイントが5桁や6桁のものがあります。かつてこれがMySQLの有名な「寿司ビール問題」を引き起こしました。特に最近はUnicodeに絵文字が大量に追加されているので、これまでこの種の問題に関心が薄かった英語圏も絵文字の普及とともにやっと真剣に考えてくれるようになったのはありがたいことです。
⚓正規表現でのコードポイント記法
ここからが本題です。
Unicodeの規格ではU+00F9というような表記が用いられていますが、正規表現ライブラリ(というよりライブラリを使うプログラミング言語)によって表記方法はまちまちです。以下はほんの一例です。
- 基本形
\uFFFF- Rubyなど
[\u{FFFF}]、[\uFFFF]、\uFFFF、\u{FFFF}- JavaScript、Pythonなど
[\uFFFF]、\uFFFF- PCRE、Perl、Golangなど
[\x{FFFF}]、\x{FFFF}- POSIX基本
- (機能なし)
- HTMLやXML(参考)

- Rubyは
{}があってもなくても許容します - JavaScriptやPythonは
{}を許容しません - PCRE/Perl/Golangは
{}が必須です
つまり、たとえばPythonとPerlの両方で同じ正規表現を動かそうとするとここが最も移植の障害になります😭。
コードポイントは正規表現の中に直接書くこともできますが、私は個人的に[\uFFFF]などのように文字セット[ ]の中に入れて書くのが好みです。次に説明するUnicode文字クラスと書式が揃って気持ちいいという理由です。
コードポイント記法を無理して使うことはない
そして意外に思われるかもしれませんが、私はそもそも[\uFFFF]のようなコードポイント記法をほぼまったく用いません。主な理由は上のように言語/ライブラリでの非互換性が大きいということと、コメントなしでは意味不明になりがちな視認性の悪さです。私は正規表現のメンテナンス性を重視するので、一度書いたら忘れてもいい正規表現ならともかく、後で細かく調整する正規表現は未来の自分が読んでくじけない書き方を常に目指しています。
駅の名前を全部覚えるみたいにコードポイントを覚えるくらいなら、文字セット[ ]の中に文字を直接書きます。
円周率なら3.1415926535897932384626までは覚えちゃいましたが。
以下の記事をご覧いただければおわかりいただけると思いますが、文字セット[ ]の中は別世界なので、相当特殊な文字であっても[ ]の中に安心して書けます。
ただ、特に[-ー-─―‐]のような「ハイフンと紛らわしい文字のセット」のような正規表現では、本来の-(U+002D、ASCIIだと2D)を文字セットの冒頭または末尾以外には置かないよう心がけています。-を途中に置くと「両側の文字の範囲」になってしまうので。
また、一部の結合文字のように、エディタやIDEやターミナルで入力すると挙動がおかしくなる特殊な文字があります。そういう場合には、仕方なくコードポイントで書くこともあります。
⚓Unicode文字クラスのプロパティ
Unicode文字クラスのプロパティは、\p{なんちゃら}という形で表記します(pはプロパティのことでしょうね)。マルチリンガルな正規表現で非常に有用性が高いのが特徴です。これが使えるライブラリは高機能と認めてよいと思います。
- 利用できる: Ruby、Perl、PCRE、Python、.NET Frameworkなど
- 利用できない: JavaScriptなど😢(ただしついにES2018で導入される予定❤️)
\p{なんちゃら}は比較的最近の機能であるためか、文字コードポイントなんかと違って、主要な言語での記法のブレが少ないのがありがたい点です🙏。
\p{なんちゃら}の「なんちゃら」の部分には、以下の3種類を指定できます。
- General categories(一般カテゴリとも)
[\p{L}](記号/約物/スペースでない)あらゆる文字(letter)、[\p{Zs}](スペース)、[\p{N}](あらゆる数字)、[\p{No}](漢数字や①などの数字)など- Scripts
Han(漢字)、Katanaka(長音を除くカタカナ)、Latin(ラテン文字: 要するにアルファベット)など- Blocks
In_CJK_Unified_Ideographsなど
上の表のリンクをクリックすると、それぞれの全リストを参照できます。
- 一般カテゴリは、上のリンク先の表では大文字1文字(カテゴリ)と小文字1文字(サブカテゴリ)の組み合わせがリストアップされています。
- たとえば大文字の
[\p{N}]とすると、[\p{Nd}](数値用の数字)と[\p{Nl}](ローマ字などの数字)と[\p{No}](漢数字や分数などの数字)といったサブカテゴリを一発で表せるので便利です。
- たとえば大文字の
- Blockなどはリストで
CJK Unified Ideographsなどと書かれていたりするので、自分でIn_を付けたりスペースを_に置き換えるなどしてIn_CJK_Unified_Ideographsのような形にする必要があります。面倒です😇。
なお、Unicode文字クラスで言う文字(letter)は「記号やスペースといった約物(punctuation)や数値(number)などでないもの」という補集合的な意味で捉える必要があります。
⚓注意
- 特に
[\p{L}]や[\p{N}]のような一般カテゴリは、マッチする範囲が非常に大きいので注意が必要です。余分なマッチを呼び込んでいないか、使う前によーくチェックしましょう。 - 逆に、
[\p{Zs}]はありとあらゆるスペース文字にマッチするので、ゼロ幅スペースのようないたずらにしか使えないようなスペース文字すら捉えられます。うまく使えば非常に有用です。 -
カタカナにマッチさせたい場合、たとえば
[\p{Katakana}]+だけでは長音ーが含まれないので注意が必要です。[\p{Katakana}ー]+などのように長音も忘れず含めましょう。- なお、厳密にやるなら
[\p{Katakana}][\p{Katakana}ー]+のように冒頭の長音を排除したいところです。
- なお、厳密にやるなら
- 通常の全角カタカナの他に半角カタカナにもマッチさせたいなら、/
[\p{Katakana}ーー゙゚]+/のように半角の濁点と半濁点と長音ー゙゚も加える必要があります(Rubular)。- なお、半角の濁音と半濁音は、前の文字に貼り付く特殊な文字につき単独ではコピペ困難な可能性があります。以下をお使いください。
⚓利用例
私は日本語を相手にする正規表現をよく使います。その中で多用している有用な文字クラスは、[\p{Han}]+(漢字にマッチ)、[\p{Hiragana}]+(ひらがなにマッチ)[\p{Katakana}ー]+(カタカナにマッチ)の3つです。
- 例: /
[\p{Han}]+/で漢字にマッチ(Rubular)
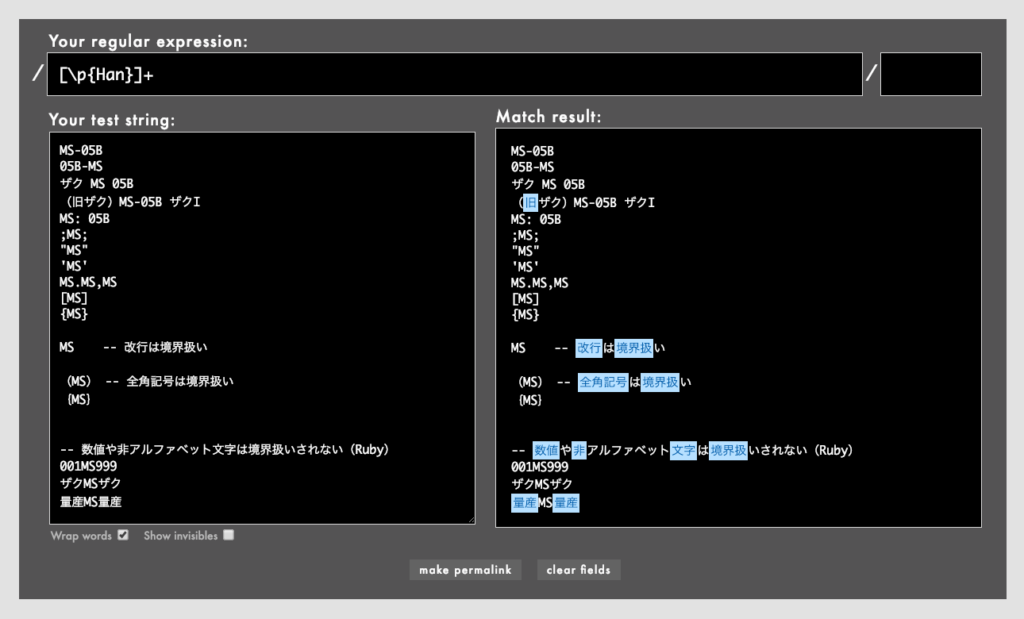
- 例: /
[\p{Hiragana}]+/でひらがなにマッチ(Rubular)
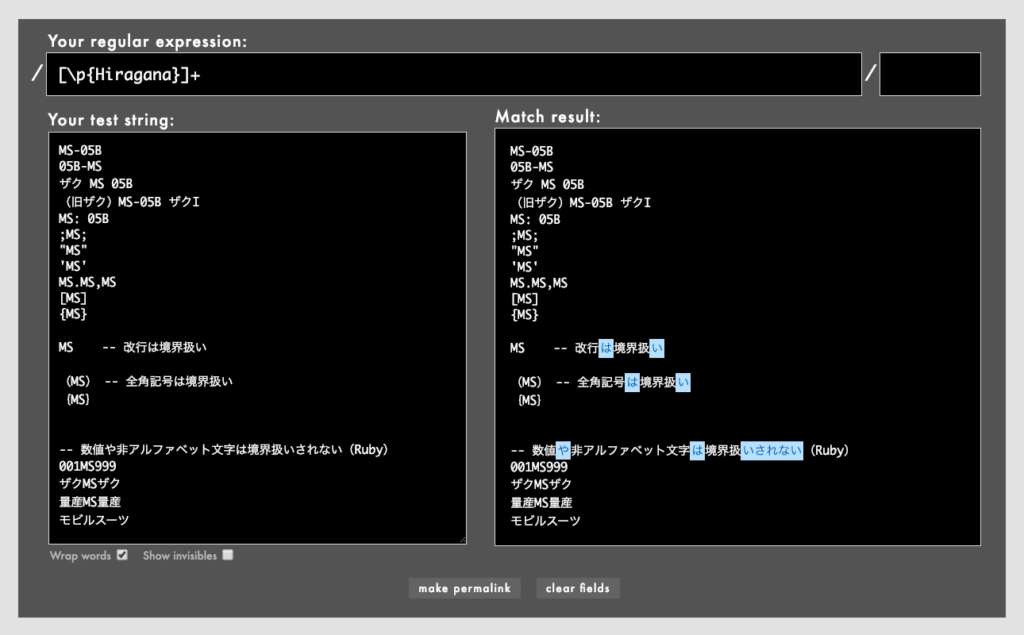
- 例: /
[\p{Katakana}ー]+/でカタカナにマッチ(Rubular)
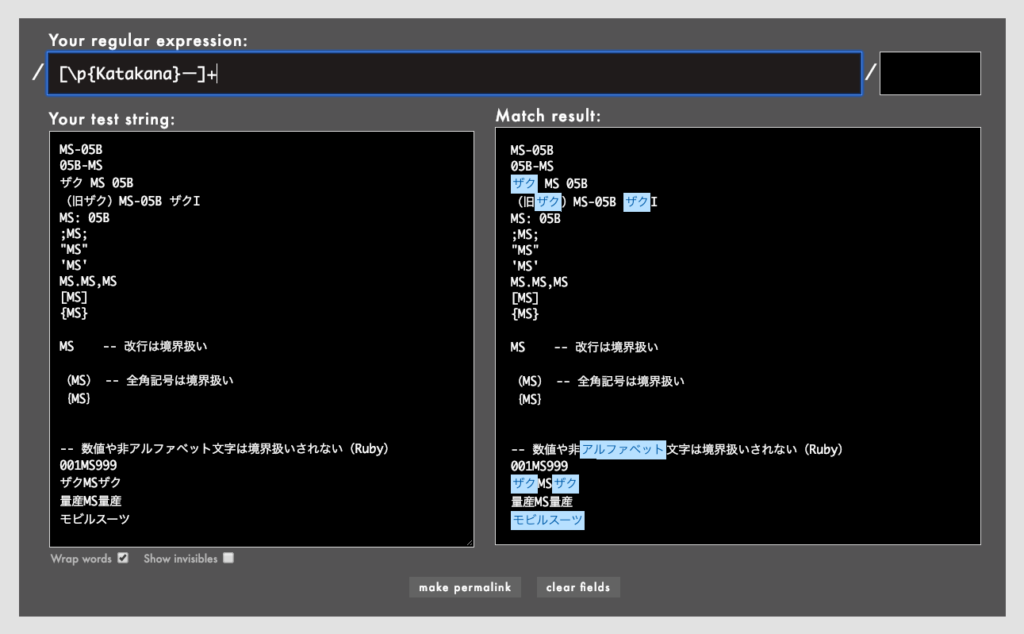
これらは誤動作の心配もなく、#3で紹介したような[一-龠]や[ぁ-ん]といった文字セットよりずっと洗練されています。私にとって、ないと生きていけない機能であり、これらが使えない正規表現ライブラリに用はありません。
⚓おまけ: 文字セットの演算
文字セット同士の差分を取れると、正規表現を簡潔に書くうえで非常に有用です。詳しくは以下の記事をご覧ください。
おたより発掘
正規表現ってちょっと覚えるだけでなく書き方が変わるので、いざ必要になった時に思い出せるように記憶の片隅に入れておきたい。
そしてRubular最高。はじめての正規表現とベストプラクティス https://t.co/tpNDUJDVDQ
— two_sann (@two_sann) February 21, 2019
更新情報