今回あたりから正規表現が本領発揮しつつ、魔界入りし始めます。今回の記事は自分でもかなり苦しみました。まだ見落としがあるかもしれませんので、今後も更新すると思います。
正規表現の先読み・後読みは言葉で説明するとわかりづらいので、具体例から先に学ぶのがよいと思います。Rubularの実行例を用意しましたので、ぜひ自分で動かして遊んでみましょう。
⚓正規表現はじめの十二歩: 「先読み」と「否定先読み」
(?=正規表現)- 先読み(look-ahead)次の場合に使う
- ・その位置の直後に
正規表現がある場合にのみマッチさせたい - ・だが直後のその
正規表現はマッチに含めたくない (?!正規表現)- 否定先読み(negative look-ahead): 次の場合に使う
- ・その位置の直後に
正規表現がある場合にのみマッチから除外したい - ・だが直後のその
正規表現はマッチに含めたくない
なお、一般に正規表現の先読みや後読みはキャプチャの対象となりません。従って、\1や\2などでは参照できません。
- 注: 今回の記事では、位置という言葉を「文字と文字の間を指す」ものとして使います。位置は文字そのものを指さないのでご注意ください。
⚓先読みの例
- 例: /
(通過|通化)(?=スワップ)/という正規表現(Rubular)
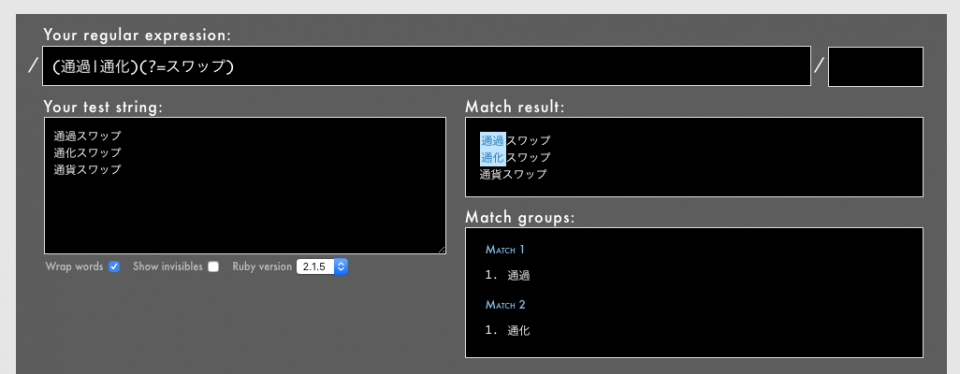
上の例は、「通過スワップ」というタイポの「通過」、または「通化スワップ」というタイポの「通化」にマッチします。それ以外にはマッチしません。
- 例: /
(?=を祈)/というパターン(Rubular)
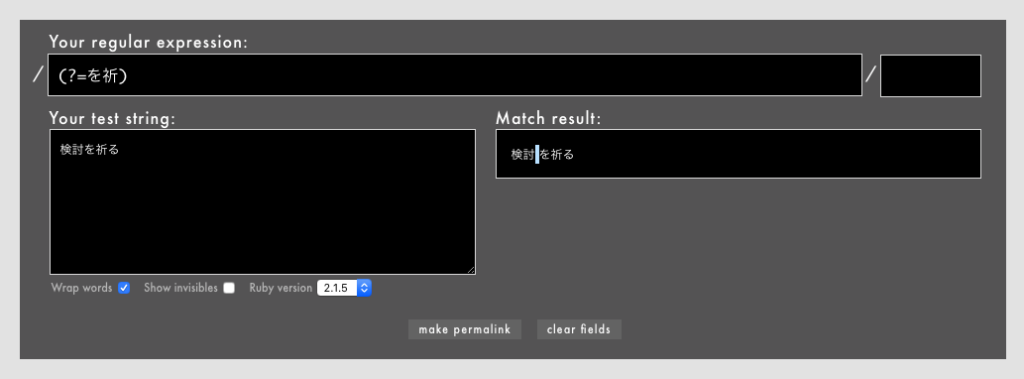
これはあえて先読みだけを記述したものです。「検討」と「を祈る」の間、つまり文字と文字の「間」にマッチしていることにご注目ください。これが「位置」です。
⚓否定先読みの例
- 例: /
せっかく(?!なら)(?!だから)/というパターン(Rubular)
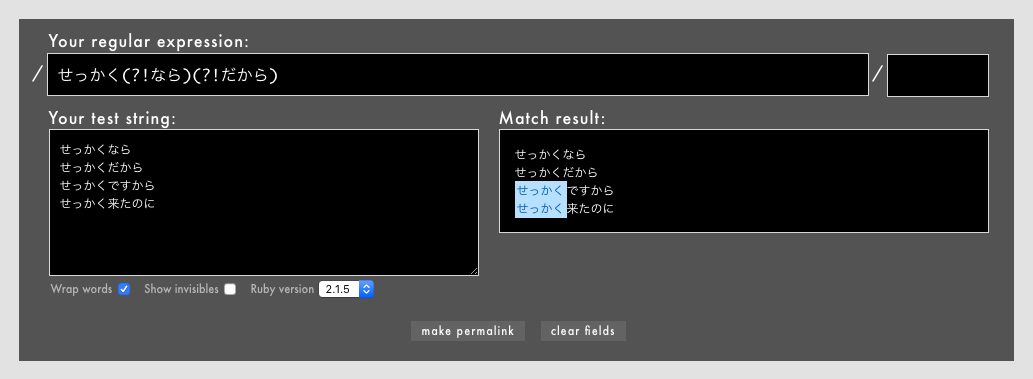
(?!なら)(?!だから)と2つ置いていることにご注目ください。上述したように、位置指定子はそれ自体は文字ではないので、このように複数置いて条件を追加できます。言葉で表せば「その文字の直後はならでもだからでもない」という意味です。
⚓正規表現はじめの十三歩: 後読みと否定後読み
(?<=正規表現)- 後読み(look-behind): 次の場合に使う
- ・その位置の直前に
正規表現がある場合にのみマッチさせたい - ・だが直前のその
正規表現はマッチに含めたくない (?<!正規表現)- 否定後読み(negative look-behind): 次の場合に使う
- ・文字列の直前に
正規表現がある場合にのみマッチから除外したい - ・だが直前のその
正規表現はマッチに含めたくない
⚓後読みの例
- 例: /
(?<=再)コンパル/というパターン(Rubular)
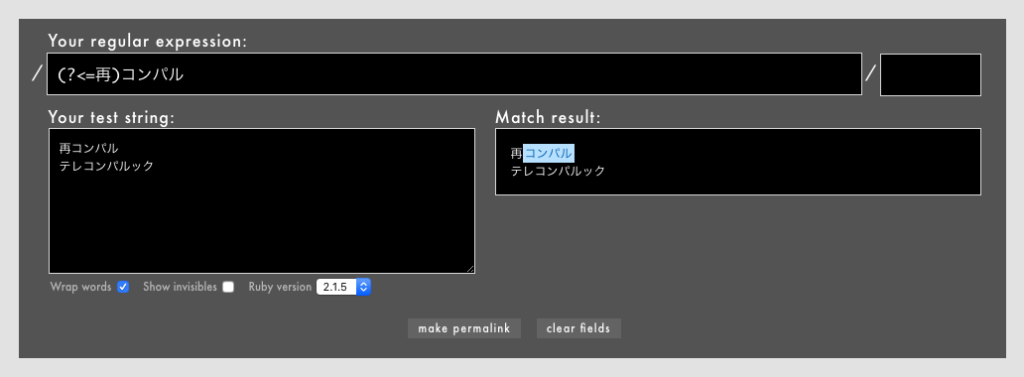
「再コンパル」というタイポを検出します。「再」をハイライトせず「コンパル」だけをハイライトできます。
⚓否定後読みの例
- 例: /
(?<!テ)クノロジー(?!パーク)/というパターン(Rubular)
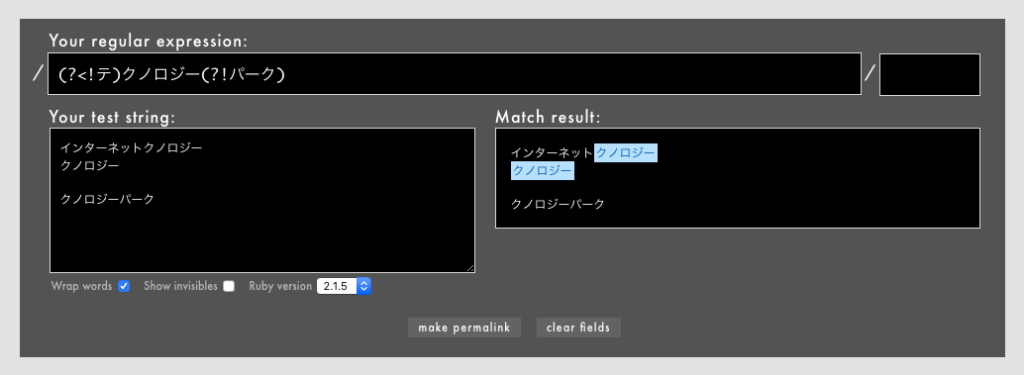
「クノロジー」というタイポを検出します。否定後読みを用いて、タイポでない文字列を除外しています。
否定後読み(?<!テ)と否定先読み(?!パーク)を同時に使っているのがポイントです。なお、クノロジーパークという施設は実在します。
⚓先読み/後読みとは
改めて説明します。
(?=正規表現)- 先読み(look-ahead)
(?!正規表現)- 否定先読み(negative look-ahead)
(?<=正規表現)- 後読み(look-behind)
(?<!正規表現)- 否定後読み(negative look-behind)
先読みと後読みは、条件付け、限定、フィルタに利用できます。正規表現のパワーを飛躍的に高める有用な表現トップクラスなのでぜひ使いこなしましょう。特に、マッチした部分をハイライトするときや置換するときにぜひとも欲しくなる記法です。割と覚えにくいので、私はカンペを作りました。
なお、先読みと後読みの両方をまとめて「lookaround」と呼ぶこともあります。最初見たときに「見渡す」という意味のlook aroundかと思ってしまいました。
先読みや後読みは難しく言うと「位置指定子」ですが、「position specifier」みたいな英語があるわけではないようです。
先読みや後読みはあくまで位置を指定する記法なので、それ自体は文字ではありません。つまり文字カウントとしてはゼロです。上述の例で先読みを単独で使うと文字と文字の「間」にマッチしましたが、その理由がこれです。
なお、先読みと後読みは残念ながらライブラリによって機能にかなり差があります(後述)。
参考: 正規表現のマッチングをどこからでも―「境界アサーション」と「ルックアラウンドアサーション」:ECMAScriptで学ぶ正規表現(7) - @IT
⚓参考: 「先」と「後」はマリオになったつもりで考えよう
日本語訳の「先読み」「後読み」は誤解を招きやすいという問題があります。というのも、日本語の「先」や「後」がそもそも曖昧さを含んでいるからです(「前」「後」も同じく曖昧です)。
「先」「後」は、以下のように時間軸上の概念を表すこともあれば、空間上の概念を表すこともあるので、紛らわしくなります。
- 時間軸上のイベント発生の順序を表す「先」「後」
例「先に片付けよう」「その作業は後でいいよ」 - 空間上の方向を表す「先」「後」(正規表現はこっち)
例「先が見えない」「後ろに目があるようだ」
その意味で、英語の「look-ahead」「look-behind」で覚える方が間違えにくいかもしれません。
「先」「後」は、自分がマリオになったつもりで文字を読み進めるときの進行方向で考えるとよいでしょう。
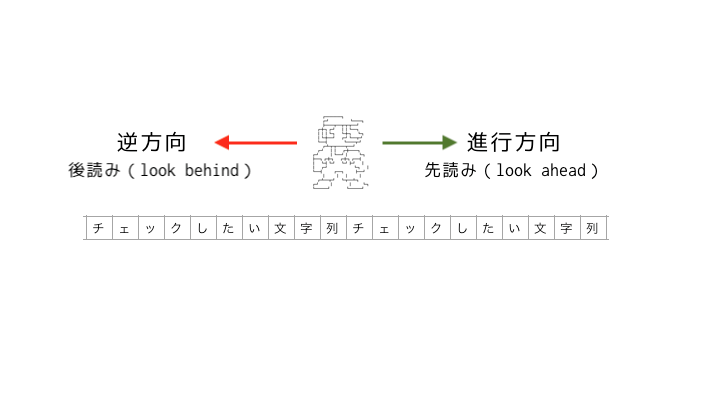
- 「先読み」は現在の位置より先(進行方向、文末に近い方)を対象とする
- 「後読み」は現在の位置より後ろ(進行と逆方向、文頭に近い方)を対象とする
これならたとえアラビア語のような「右から左に書く言語」(BiDi)であっても統一的に扱えます(というよりそう考えるしかありません)。そういえば最近のマリオは3Dと2Dを行き来できますね。
⚓参考: (?なんちゃら)って?
高機能な正規表現ライブラリの多くは、先読みや後読みといった拡張機能を(?なんちゃら)の形で表します。
?の直後に来る文字で機能を指定する=: 先読み!: 否定先読み<=: 後読み<!: 否定後読み- 他にもいろいろある(今後ご紹介)
POSIX系にありがちな
[: :]や[[: :]]形式の拡張は普遍性(特にUnicode対応)に不安があるため、私は使わないようにしています。
⚓先読み/後読みのポイント
⚓1. 原理的にはいくつでも追加できる
先読みや後読みは、前回学んだ\Aや\zと異なり、原理的には正規表現の途中にいくつでも置けます(もちろん文字セット[]の中は除きます)。
その気になれば/(?<!(?<=トテ))/のように入れ子にすることすら可能です(実装に依存する可能性がありますが)。今のところ意味のある例をちょっと思いつきません。
- 例: 全部使った場合: /
(?<=東京)(?<!大阪)特許(?=許可)(?!許諾)/(Rubular)
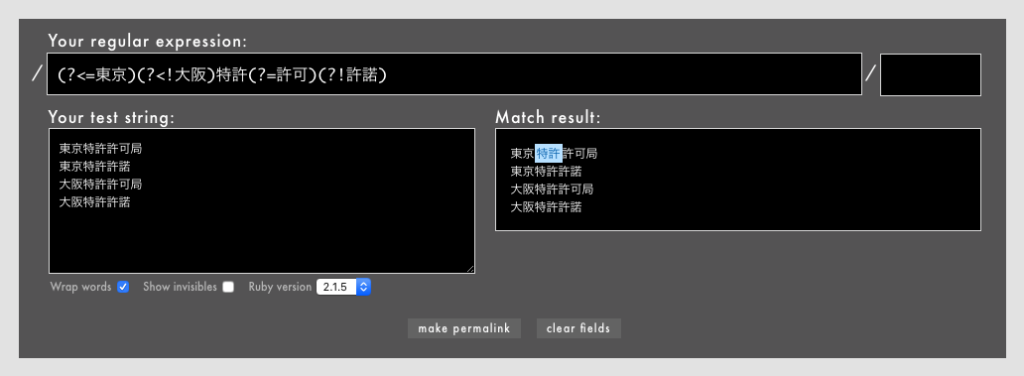
言葉で説明すると、以下をすべて満たすもののみがマッチします。
- 「特許」の直前は「東京」である
- 「特許」の直前は「大阪」ではない
- 「特許」の直後は「許可」である
- 「特許」の直後は「許諾」ではない
参考: 正規表現にも「AND」が隠れているでも説明しましたが、正規表現の文字やメタ文字(|は除く)は「AND」の関係を表すので、(?<=東京)(?<!大阪)と続けて書くことで、その位置に関する条件を追加できます。指定できるのはあくまで位置であり、文字ではないことに注意しましょう。
ただし上の例は実用上は非常に冗長ですので真似しないでください。上では条件を4つも指定していますが、条件は先読みに1つ、後読みに1つあれば十分です。
⚓2. 先読みや後読みはいくつ連続しても「1つの位置」に集約される(重要)
今回の最大の目玉です。ちょっとわかりにくいので、具体例を出します。
- 例: /
(?<!東京)(?<!大阪)(?<!神戸)(?<!京都)(?<!博多)特許事務所/というパターン(Rubular)
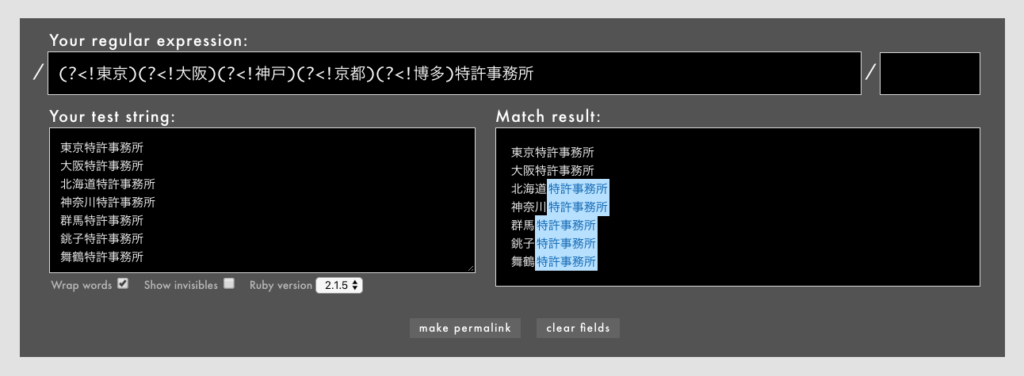
(?<!東京)のような否定後読みを5つ連続で置いていることにご注目ください。連続している限り、先読みや後読みをいくつ置いても、その位置はただ1箇所を指します。
先読みや後読み以外の正規表現をすべて削除してみるとこのことがよくわかります。
- 例: /
(?<=東京)(?<!大阪)(?<!神戸)(?<!京都)(?<!博多)/というパターン(Rubular)
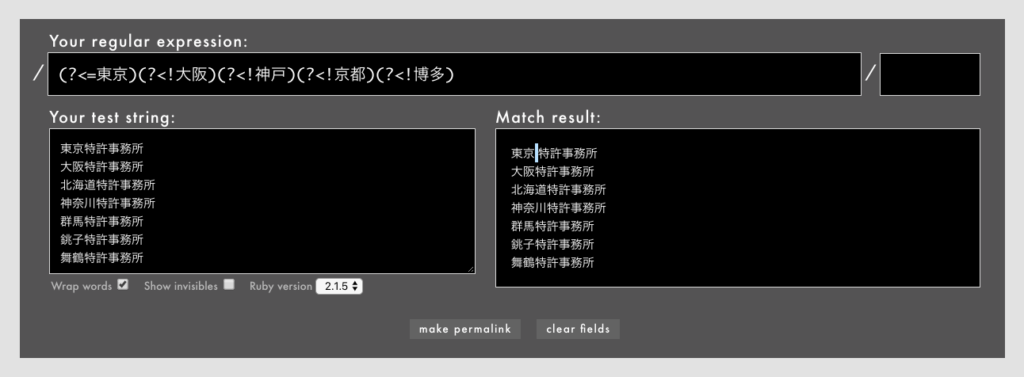
上は、最初の1つだけ後読み、後は否定後読みにしたものですが、5つある後読みが1箇所だけを指しているのがおわかりいただけるかと思います。
この連続する後読み同士を試しにRubularで入れ替えてみてください。結果はまったく変わりません。
言い換えると「連続する先読み後読み同士の位置関係や順序は消滅する」ということです。これは、以下の性質から導かれます。
- 先読みや後読みは文字ではない
- 正規表現で連続する2つの表現同士の関係はANDになる
なお、連続する先読みや後読みは、たとえ丸かっこ()で仕切っても位置を分断できません。
- 例: /
((?<=東京))((?<!大阪))/(Rubular)
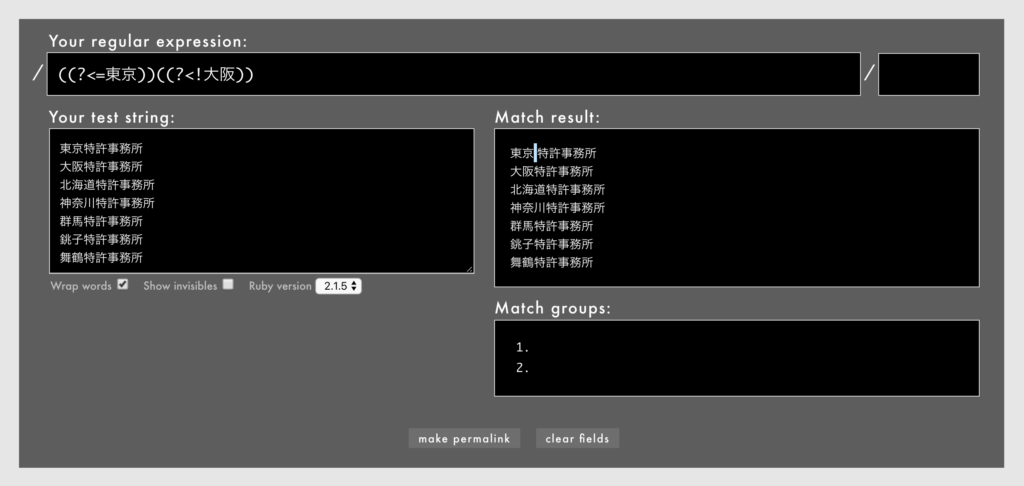
上は連続する(?<=東京)と(?<!大阪)をそれぞれ()に入れていますが、位置はやはり1箇所に収束しています。
⚓⚠️注意: 連続で無意味な組み合わせを作らないこと
これで安心して先読みや後読みを連続させられると思いたいところですが、連続しているもの同士はANDの関係になっていることに注意しましょう。
たとえば、肯定先読みの2つ以上の連続や、肯定後読みの2つ以上の連続は、たいてい無意味です。
- 例: /
(?<=東京)(?<=大阪)/という無意味なパターン(Rubular)
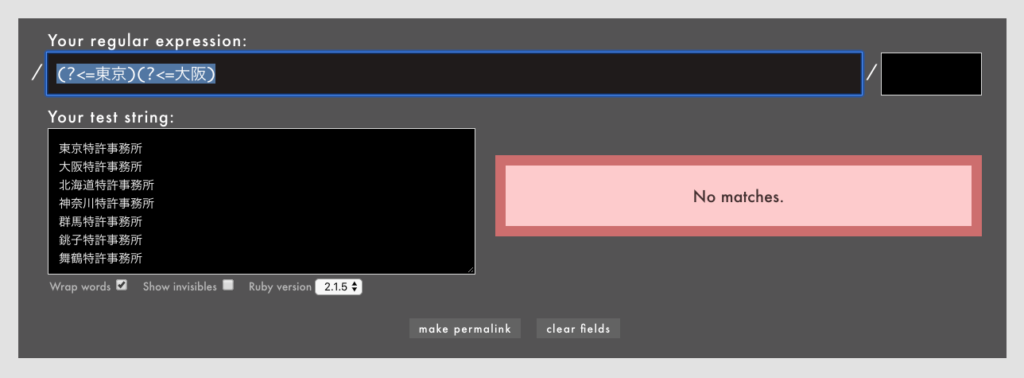
/(?<=東京)(?<=大阪)/は「その位置の直前にあるのは東京であり、かつ大阪である」ということになるので、正規表現としてはvalidでも、マッチすることは永久にありません。メタ文字が入ればまた違うとは思いますが。
また、肯定先読みと肯定後読みの連続は冗長です。これもメタ文字が入ればまた違うとは思いますが。
- 例: /
(?<=東京)(?=特許)/という冗長なパターン(Rubular)
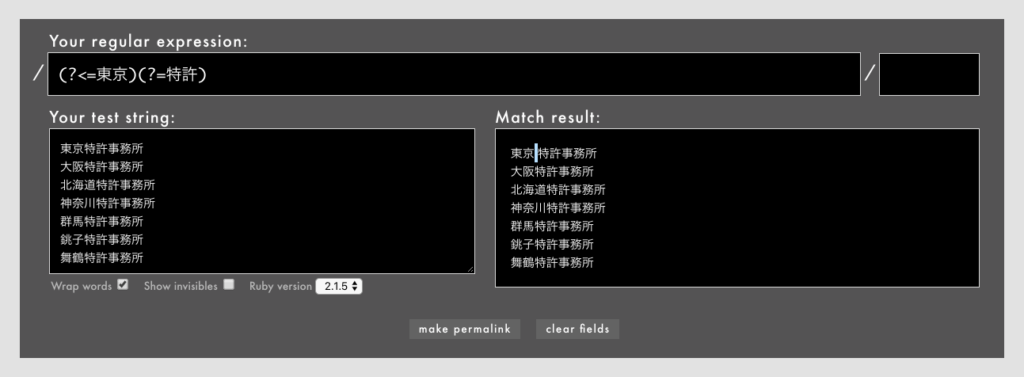
この場合、/(?<=東京)(?=特許)/と書くぐらいなら/(?<=東京特許)/などと1つにまとめて書く方が素直です。
また、否定先読みと否定後読みの連続も無駄の多いパターンです。これもメタ文字が入ればまた違うとは思いますが。
- 例: /
(?<!東)(?!京)/(Rubular)

この場合、/(?<!東)(?!京)/などと書くぐらいなら/(?<!東京)/などとまとめて書く方が素直です(それでもパターンとして有意義とは言えませんが)。
⚓3. パターンの途中にも置ける
先読み・後読み・否定先読み・否定後読みは位置指定子なので、一応パターンの途中にも置けます。
- 例: /
..(?<!には)(?<=、)にわ/というパターン(Rubular)
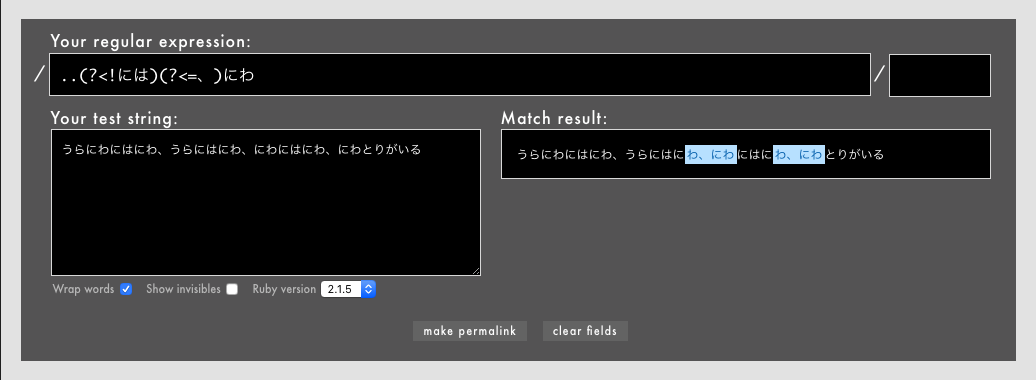
なお、通常は位置指定子をパターンの途中に置く積極的な意味はそれほどないと思われます。
⚓4. 先読みや後読み「そのもの」には量指定子を付けられない
先読みや後読みが位置のみを表すので、先読みや後読みそのものに?や+といった量指定子を付けられません(付ける意味もありません)。
- 例: /
(?<![青赤\n\r\t])+巻紙/というパターン(regex101)
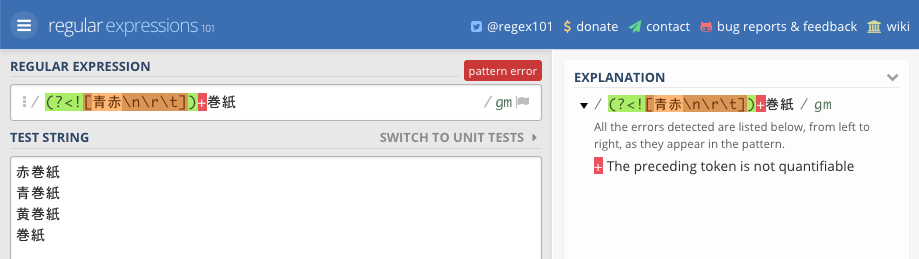
regex101で試すと上のようにエラーになります。
なぜかRubularではエラーになりませんが、これはエラー扱いにする方がよいように思えます。
⚓⚠️注意: 先読み/後読みでも「否定」にはご用心
否定表現は、すなわち文字セットの補集合を表します。
[^文字]のような否定文字セットは改行文字にもマッチすることを前回説明しましたが、似たようなことが否定先読みや否定後読みでも起きます。
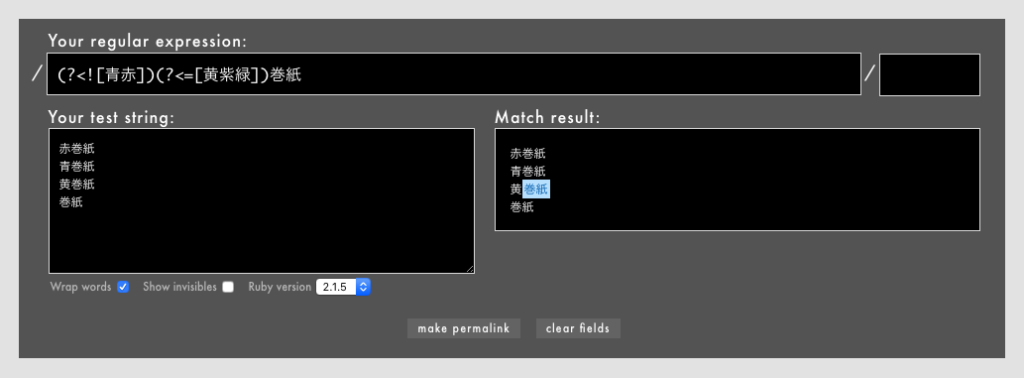
- 例: /
(?<![青赤])巻紙/というパターンで想定外のマッチが発生(Rubular)
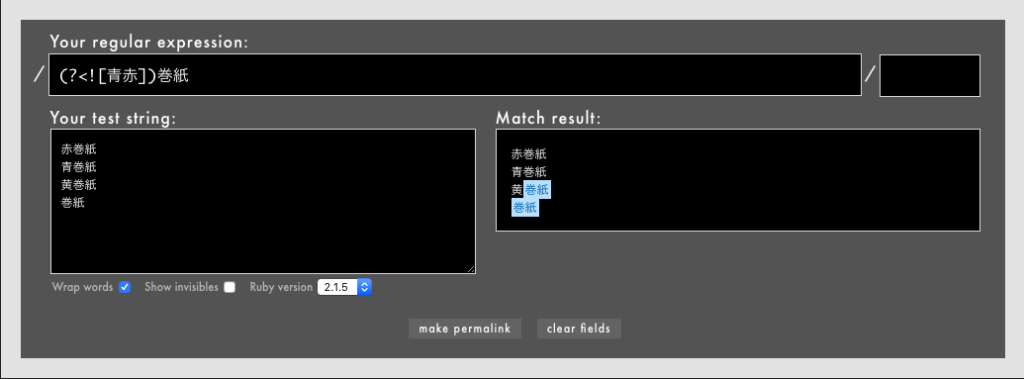
上の例では、「黄巻紙」以外に単なる「巻紙」にまでマッチしてしまいました。改行文字や非文字(冒頭位置や末尾位置など)も/(?<![青赤])巻紙/に該当するからです。
文字セットの補集合は途方もなくデカイことを思い知らされます。そんなものに+や*のような凶悪な量指定子を付けたらどれだけパフォーマンスが落ちるかと思うと🤢。もっとも先読みや後読みそのものには量指定子を付けられませんが。
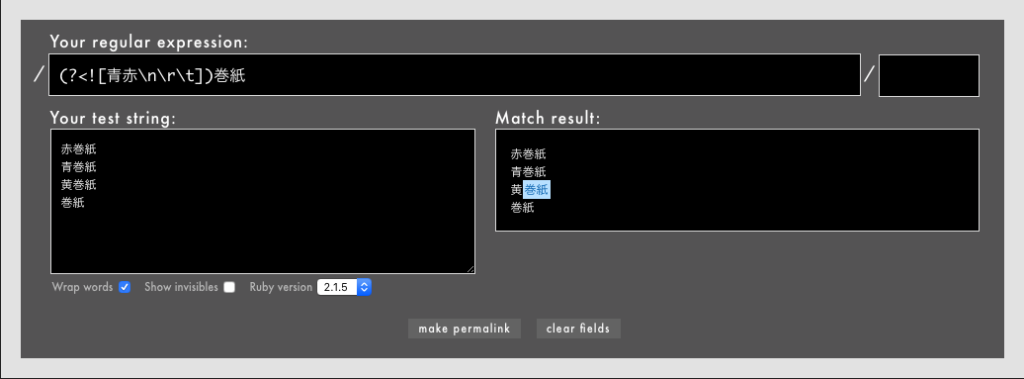
単なる「巻紙」を除外したい場合は、次のように\nや\rや\tといった改行文字や非表示文字を文字セットの除外に追加するか、/(?<![青赤])(?<=[黄紫緑])巻紙/などのように明示的な条件を追加するなどの対策が必要です。
- 例: /
(?<![青赤\n\r\t])巻紙/というパターン(Rubular)
- 例: /
(?<![青赤])(?<=[黄紫緑])巻紙/というパターン(Rubular)
ことほど左様に、否定表現はコワいと改めて思います。正規表現は最初に極力肯定的な表現を追求し、否定表現は最後の手段ぐらいに考える方がよいと思います。私も知らずにまだまだ否定表現のワナを踏んでいるかもしれません💦。
興味のある方は「ド・モルガンの法則」を調べてみるとよいでしょう。
⚓先読み/後読みはライブラリごとの差が大きい
先ほども書きましたが、正規表現の先読み/後読みは残念ながらライブラリによって差が大きいのが現状です。
たとえば、Go言語に組み込みの正規表現には、後読み機能自体がそもそもありません。
JavaScriptは数年前まで後読み機能がありませんでしたが、現在(2021/04/08)はChromeとFirefoxで先読みも後読みもフルに使えるようになりました。Safariは残念ながらまだ後読みに対応していません(caniuse.com)。
なお、Go言語向けのdlclark/regexp2というサードパーティパッケージは.NET Frameworkの正規表現ライブラリを移植したもので、パフォーマンスはともかく機能は.NET Framework並です。
先読みは、メジャーな正規表現ライブラリなら問題なく使えます。
後読みで問題なのは、多くのライブラリで制約がかけられている点です。Ruby、PHP、Python(PCRE)など、ほとんどの正規表現ライブラリでは、後読み/否定後読みの中のパターンの長さを不定にできないようになっています(先読みにはこうした制約はありません)
これは(私にとっては)かなり厳しい制約です。その場合?や+や*のような長さ不定の量指定子は使えません。
(?<=.+)や(?<=.*):*や+はもちろんダメ(?<=テクノロジー?):?ですらダメ(?<!テクノロジー?): 否定後読みでも?すらダメ
たとえ量指定子を使わなくても、長さが不定になる表現は後読みの中でグループ()に入れると使えません(/(?<=東京|大阪|北海道)特許事務所/のようにグループに入れなければOKです)。
- 例: /
(?<=(東京|大阪|北海道))特許事務所/というパターンはダメ(Rubular)
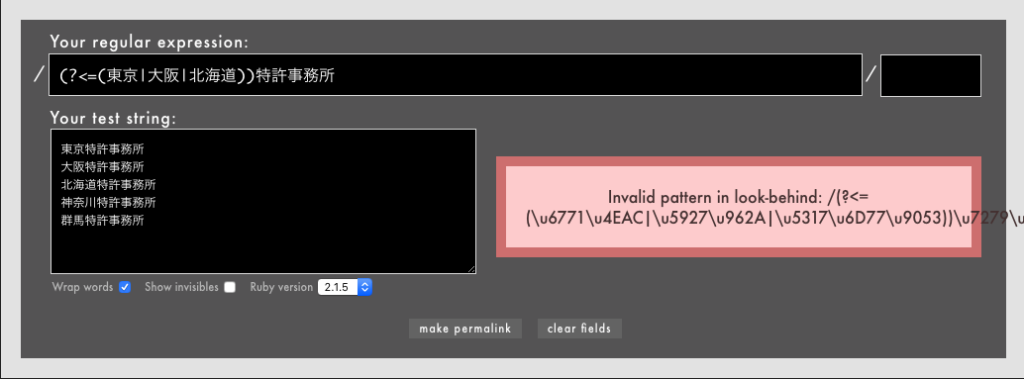
ここは私の推測ですが、多くの正規表現ライブラリではこの書き方を自粛しているのだと思います。理由としては特に後読みや否定後読みはただでさえ検索の効率が落ちやすく、その中で長さ不定の量指定子などを許すとさらに効率が落ちてしまう可能性があるためです。
なお、.NET Frameworkや現在のJavaScriptなら後読みや否定後読みでも長さ不定の量指定子をフルに使えます。詳しくは以下の記事にあるスライド「正規表現のlook behindで量指定子を使いたい」をご覧ください。
⚓「後読みで長さ不定の表現が使えない」問題の回避方法
「長さが不定の文字列をどうしても後読みの中で使いたい!」という方に、いくつかの回避方法をご紹介します。
⚓1. 全体を|で分割して回避(否定でない後読みなら)
この|による全体分割は強力な味方です。応用範囲が広く、可読性もよいのでぜひ活用しましょう。
- 例: /
(?<=(東京|大阪))特許事務所|(?<=(北海道|神奈川))特許事務所/というパターン(Rubular)
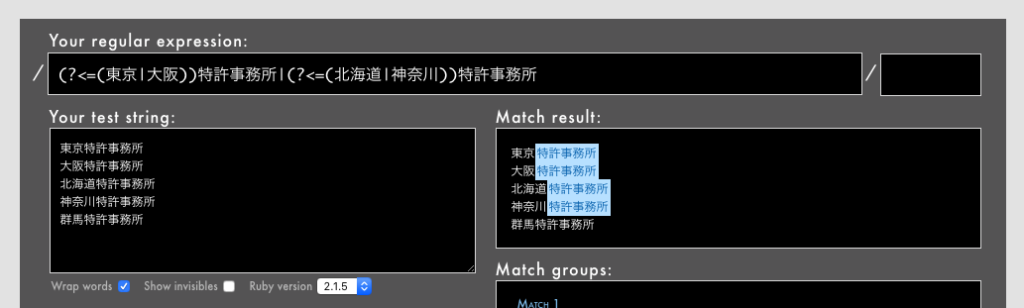
それぞれの後読みの中で文字列の長さを揃えるのがコツです。
ただし、これも否定後読みでは注意が必要です。
そもそも「AまたはB」でないや「Aでない」または「Bでない」という否定がらみのロジックの可読性が低い(非常に間違えやすい)という問題があります。
また、Rubyの否定後読みでは、長さが同じであっても/(?<!(東京|大阪))特許事務所/という書き方自体が許されません。否定後読みの中で()を使うだけでもエラーになります(ちょっと厳しすぎる気もします)。
- 例: /
(?<!(東京|大阪))(?<!(北海道|神奈川))特許事務所/というパターンは許されない(Rubular)
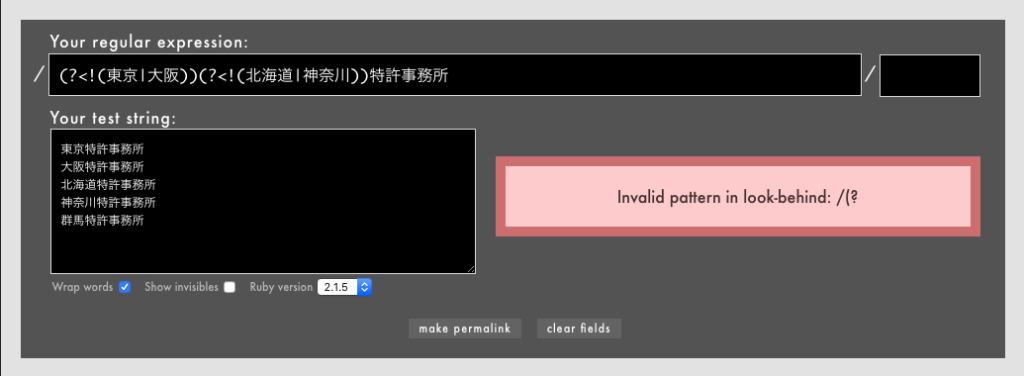
PHPやPythonでは長さが同じ否定表現/(?<!(東京|大阪))特許事務所/であれば許されます(regex101.com)。
⚓2. 複数の肯定後読みを()で囲んで|でつなぐ
文字列の長さごとに肯定後読みを書き、それらを()で囲んで|でつなぐ方法もあります。()の入れ子が増えるのが難点ですが、可読性はさほど下がりませんし、この方がコンパクトに書ける場合もあるので、これもおすすめです。
- 例: /
((?<=(東京|大阪))|(?<=(北海道|神奈川)))特許事務所/というパターン(Rubular)
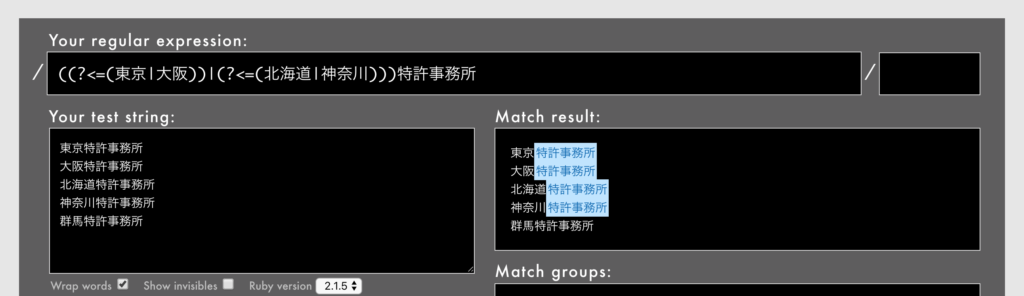
前述のように、Rubyの否定後読みの中ではそもそも()を書けないので、肯定後読みが対象です。
ここはあくまで想像ですが、否定後読みの中で()を許すと((?<!(東京|神奈川))のような人間が間違えやすい「否定とORの併用」ロジックの乱用を誘発するので、戒めのために禁止しているのかもしれません。
しかし否定先読みでは((?!(東京|大阪))という書き方は許されています。
このことについては私の中で戒めだと思うことにします。
⚓3. {N}で長さ指定して回避
{N}量指定子による一意の長さ指定は例外的に使えます。{N,M}などの範囲量指定子は使えません。
これを1.や2.のように|でつなげても構いませんし、要注意ながら否定後読みでも使えます(否定表現を|でつなぐのは避けたい)。
もっとも、普段から+や*のような凶悪な量指定子ではなく、{N}や{N,M}のように大人しい量指定子を積極的に使いたいものです。
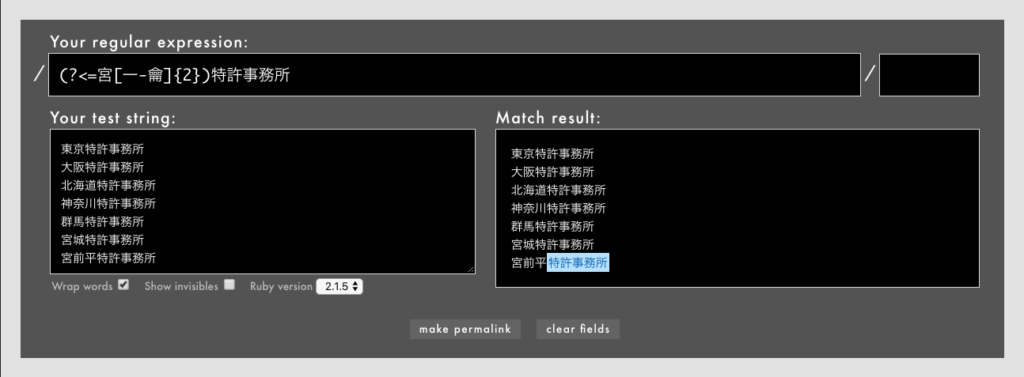
- 例: /
(?<=宮[一-龠]{2})特許事務所/というパターン(Rubular)
⚓まとめ
- 先読みや後読みは非常に強力な正規表現
- 先読みや後読みは複数置いても大丈夫
- 連続する先読みや後読みは1つの位置に集約される
- 無意味な連続を作らないよう注意しよう
- 否定表現は巨大な補集合を呼び込むので、原則として避けよう(特に
|と混ぜると間違えやすい) - 「
パターンA|パターンB」のように、論理OR|で素直に表せる表現を検討しよう
正規表現は常に冒頭から末尾に向けて探索を進めるので、マッチの頻度が高いものを左に寄せると速くなります。たとえば( | | )は途中でマッチすればそこで処理を終えるので、頻度の高いものを左に置くようにしましょう。
⚓参考: 正規表現についてめちゃくちゃ詳しく学べるサイト
最後に、本記事を書いていて見つけたおすすめサイトをご紹介します。

サイト自体に、主要な正規表現ライブラリ同士の機能や構文を比較できる機能があります(一度に2つですが)。
regular-expressions.infoより

しかも正規表現について極めて詳細な解説が惜しげもなく公開されていて、私もちょっと読んだだけでいくつもの発見がありました。長年追い求めていた正規表現の神⛩を見つけたような思いです。英語圏の神なので、日本語特有のノウハウはさすがにありません。
このサイトでは強力な正規表現チェックアプリも販売していますが、惜しくもWindows用のみです😢。
更新情報