今回は特別編として、論理ORを表す|の注意について書きます。
今回を含め、本シリーズでは主に日本語の文章でのマッチを扱う場合を念頭においています。
⚓|のワナ
はじめの八歩でご紹介した論理ORを表す|(代替構成体)は、柔軟かつ可読性の高い正規表現を書くのになくてはならないメタ文字です。
しかし|には大きなワナがあります。
- 例: /
課長|課長補佐|課長補佐代理|課長補佐代理心得/というパターン(Rubular)
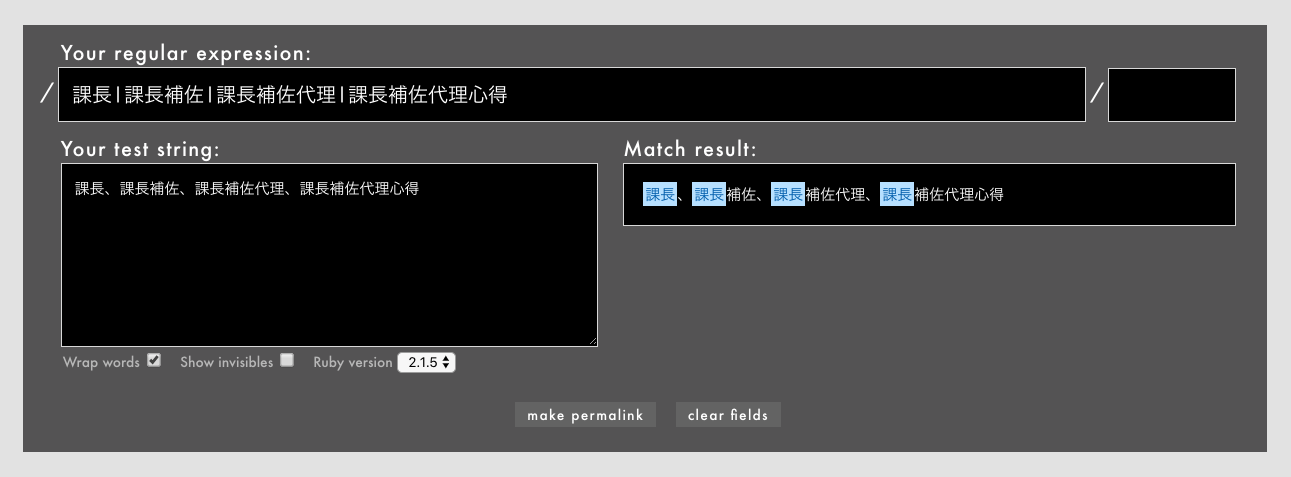
「課長」「課長補佐」「課長補佐代理」「課長補佐心得」にマッチさせたいと思って課長|課長補佐|課長補佐代理|課長補佐心得と書いていますが、実際には「課長」にしかマッチしていません。処理によっては重大なバグになる場合があります。
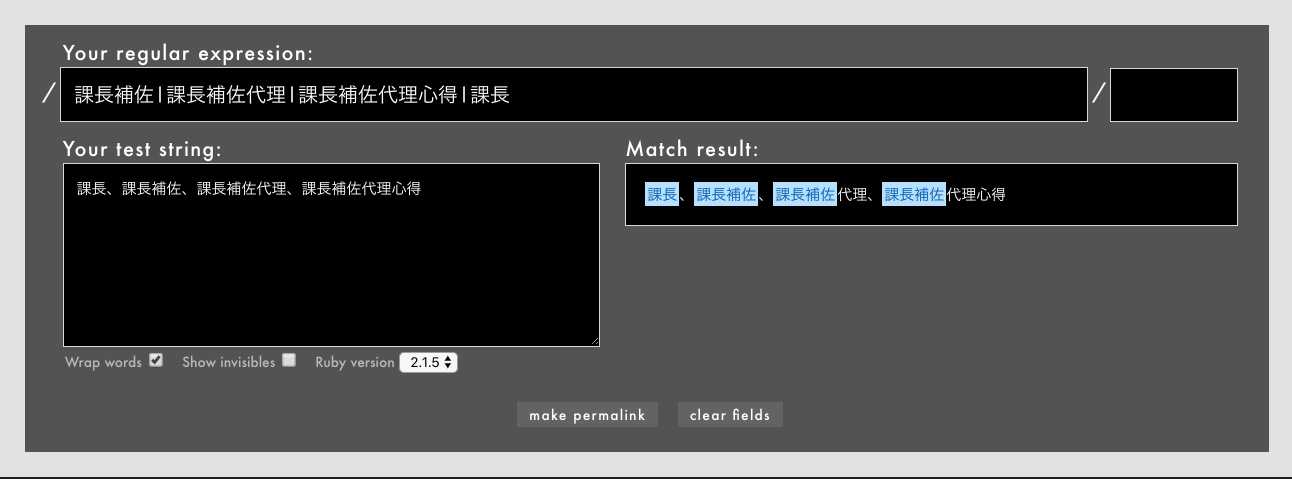
それではと、「課長」を正規表現の一番右に移動してみると、今度は「課長」「課長補佐」までしかマッチしていません。
- 例: /
課長補佐|課長補佐代理|課長補佐代理心得|課長/というパターン(Rubular)
⚓|の動作
|の動作についてまとめます。
|で区切られた正規表現は、左から右に評価される- 評価の結果一致すれば、そこで終了し、次の評価に進む
多くのプログラミング言語では、OR論理を「左から順に評価し、一致すればそこで終了する」というコンセプトで処理することで処理の軽減をはかっています。一致が既にあれば、それ以上評価を進めても論理値は変わらず、そこから先の評価は無駄になるからです。
⚓原因
上の例で踏んだワナには以下の要素があります。
- 正規表現内で
|で区切られた文字列同士に、お互いの部分文字列(substring)が含まれている - 対象文字列に、部分文字列と長い文字列が両方含まれている
- 対象文字列で複数のマッチ文字列を取るのが目的
つまり、注意すべきは部分文字列と順序と複数マッチです。
コワいのは、対象文字列の方に部分文字列と長い文字列が両方ないと、この問題になかなか気づけないことです。
対策
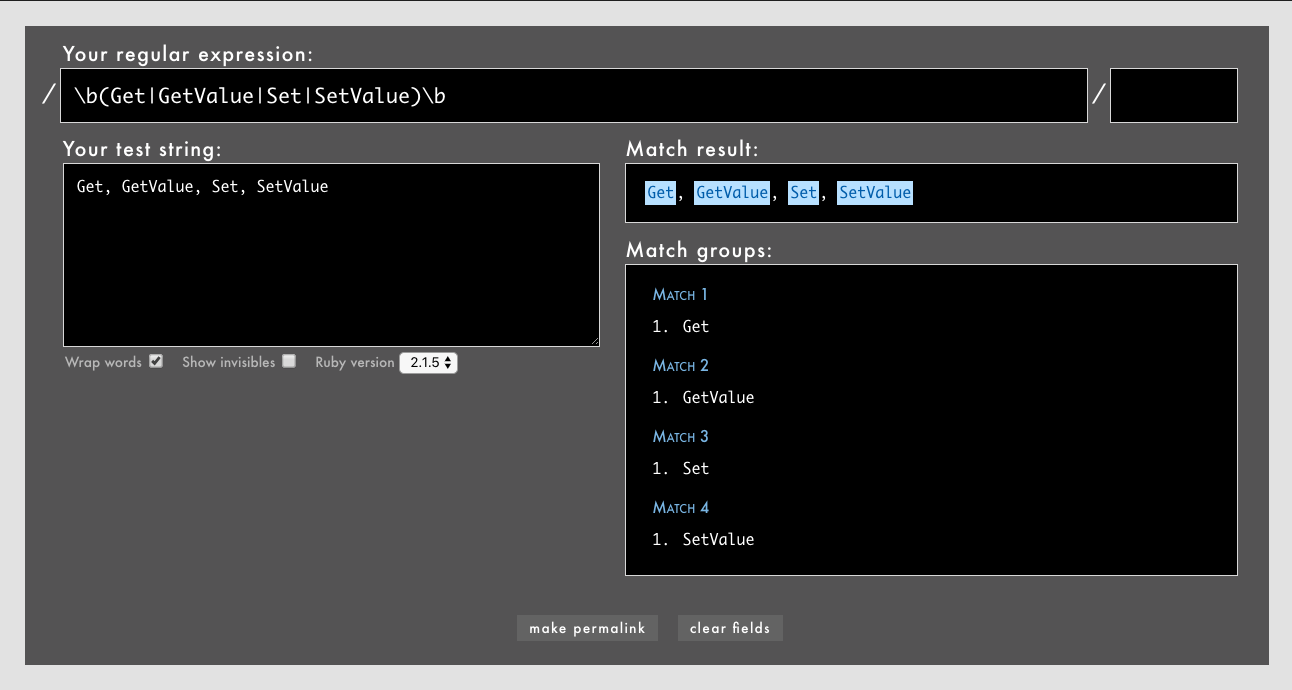
⚓対策1(アルファベット向け): (\bと)\bで囲む
アルファベット語圏や韓国語のように単語がスペースで区切られる言語が対象であれば、たとえば\b(Get|GetValue|Set|SetValue)\bのように(\bと)\bで囲むことで回避できます。
なお、\bは語の区切りを示す位置指定子です(ショートハンドについては今後説明します)。
- 例: /
\b(Get|GetValue|Set|SetValue)\b/というパターン(Rubular)
しかし残念ながら、日本語や中国語のようにスペース区切りでない文字列では\bで囲んで回避する手法が使えません。
⚓対策2(日本語向け)
日本語で使える方法のひとつは、|でつなぐときは常に長い文字列から順に並べることです。
- 例: /
課長補佐代理心得|課長補佐代理|課長補佐|課長/というパターン(Rubular)
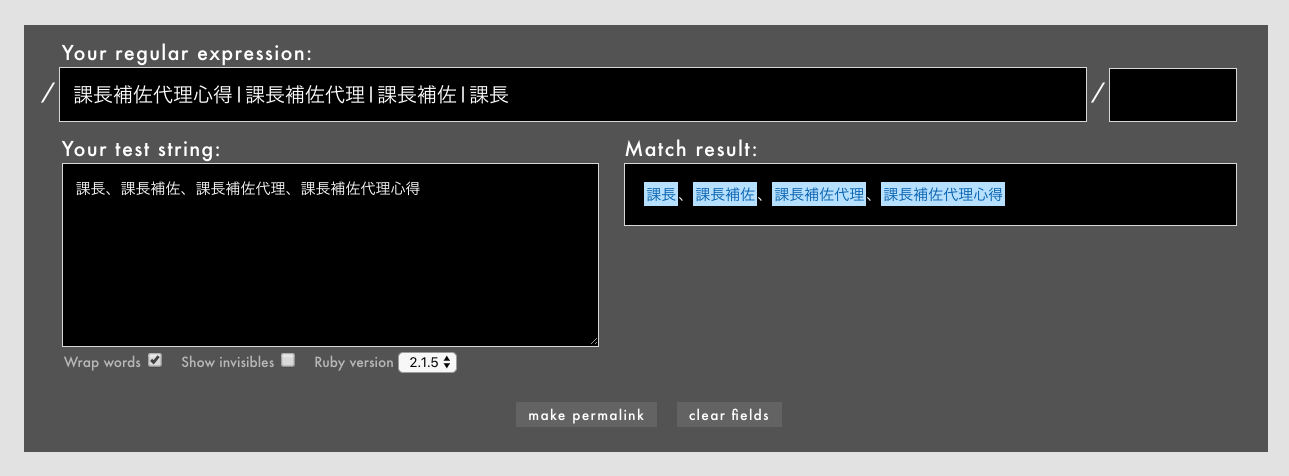
これで期待どおりマッチします(これらを含むさらに長い役職名を除外しなくてよいのであれば、ですが)。
ただし、|は多用されるので、正規表現が複雑になると知らず知らずこのワナを踏んでしまう可能性は常につきまといます。常に長い文字列から列挙することは、なかなか徹底できないかもしれません。また、単語の途中の部分マッチが悪さをする可能性も考えられます。
⚓参考: DRYに書くのは意外に難しい
DRYはDon't Repeat Yourselfの略で、主にRubyなどのプログラミング言語で同じコードを繰り返し書くことを徹底して避けるという心得のことです。
同じ考えは正規表現にもある程度当てはまります。
- 例: /
課長(補佐(代理(心得)?)?)?/というパターン(Rubular)
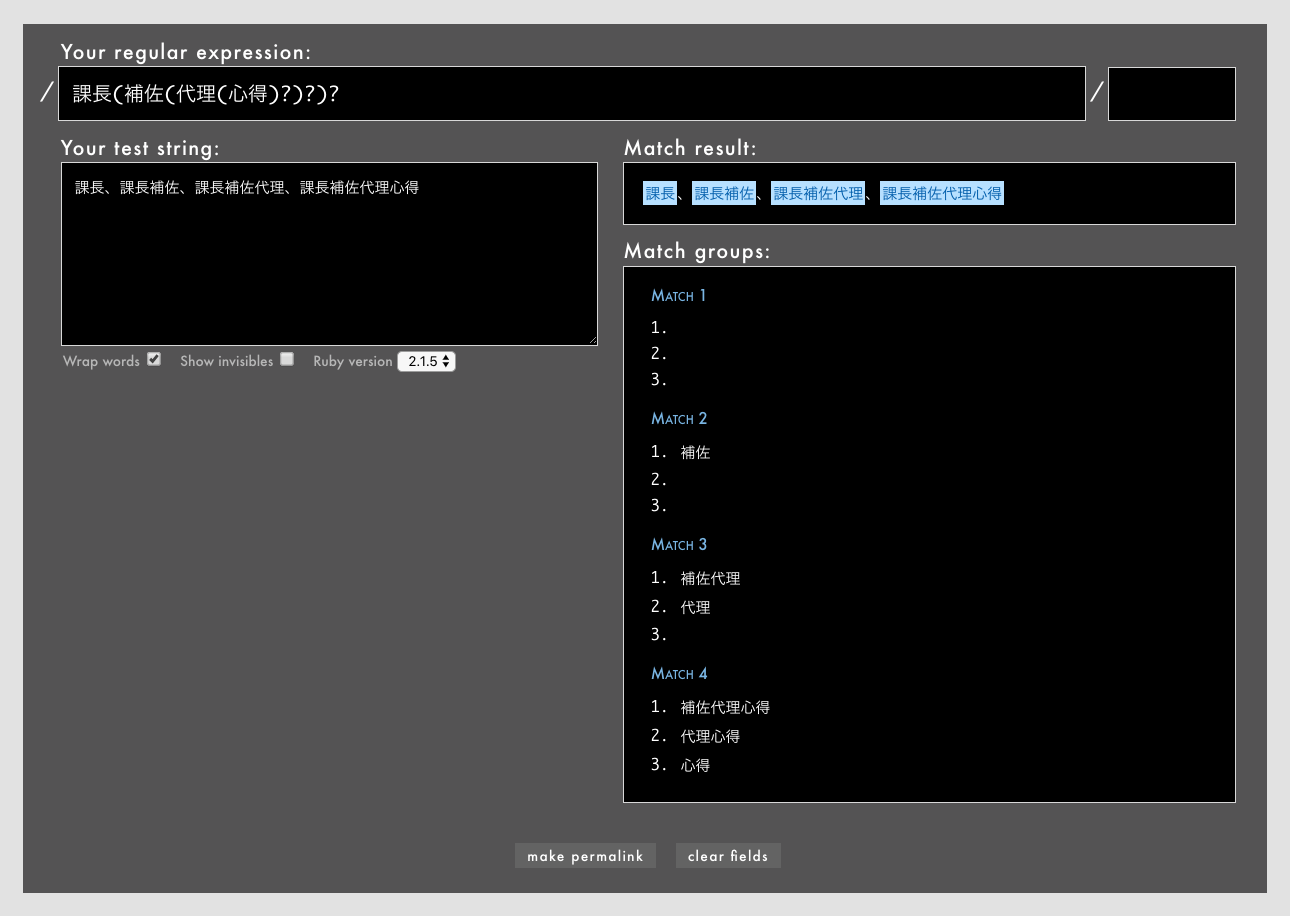
課長(補佐(代理(心得)?)?)?の中に、「課長」に続く語を()?で入れ子にして記述しています。
しかしこれで完璧かと思いきや、実は対象文字列によっては思わぬものにマッチしてしまいます。
- 例: /
課長(補佐(代理(心得)?)?)?/で期待外のマッチが起きる(Rubular)
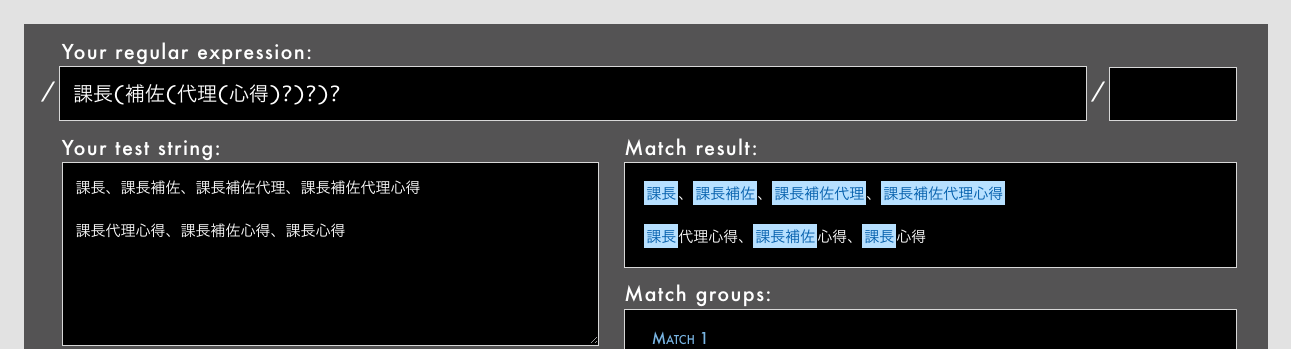
「課長代理心得」「課長補佐心得」「課長心得」が現実的かどうかは別として、これらにもマッチしてしまいました。
DRYな方法で期待外のマッチを排除しようとすると、正規表現の可読性がどんどん落ちてしまいます。
- 例: /
課長(補佐(代理(心得)?)?(?!(代理|心得)))|課長(?!(補佐|代理|心得))/というパターン(Rubular)
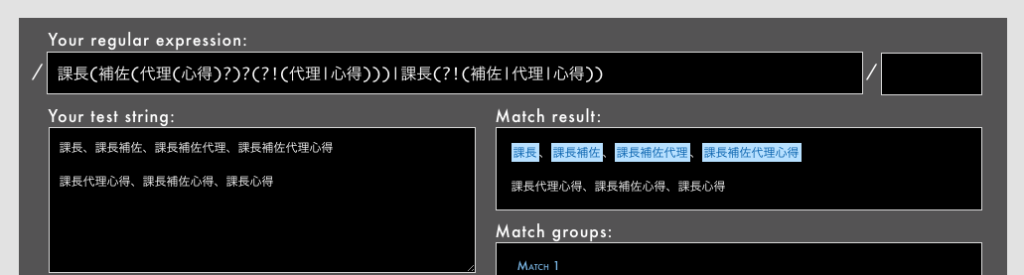
この複雑な正規表現は、正直言うと場当たり的な対応の産物で、しかもこれで網羅できていない可能性が十分にあります。
DRYはプログラミングでは重要な心得ですが、特に日本語を対象とする正規表現ではDRYな方向に頑張るとかえってこじらせてしまう可能性があります。
基本的にはDRYはほどほどにし、順序に注意して|で単純に列挙する方が無難だと思います。
⚓ネガティブマッチもテストしよう
特に自然言語を対象に正規表現をかける場合、ネガティブな対象文字列(マッチして欲しくない文字列)についても事前に十分作ってテストすることが重要です。
マッチして欲しい文字列だけでテストすると、多くの事故につながります。先の「課長代理心得」「課長補佐心得」「課長心得」のような意地悪な対象文字列をできるだけたくさん作ってテストしましょう。
⚓参考: |正規表現エンジンのタイプによって挙動が変わる
今は簡単な説明にとどめますが、実は今回紹介した|の動作は正規表現エンジンのタイプによって異なることがあります。大きく分けて次の2つがあります。
- テキスト制御型(text-directed)エンジン(少数派)
- 正規表現制御型(regexp-directed)エンジン(多数派)
テキスト制御型では、|の順序やかっこ()をどのように変えても最長にマッチします。|のようなごく基本的なメタ文字の動作が異なるというのは少々驚きです。
幸い、RubyやPCREやPythonなど、メジャーな正規表現エンジンのほとんどは正規表現制御型なので、通常は心配ありません。
テキスト制御型のエンジンは、awkやegrepなどわずかです。
詳しくは今後説明します。
- #1: 基本となる8つの正規表現
- #2: 正規表現とは何か/ワイルドカードとの違い
- #3: 冒頭/末尾にマッチするメタ文字とセキュリティ、文字セットの否定と範囲
- #4: 先読みと後読みを極める
- #5(特別編)
|と部分マッチのワナ(本記事) - #6: 文字セットのショートハンド
- #7: Unicode文字ポイントとUnicode文字クラス
- #8: 対象の構造を意識した「適度にDRYな」書き方
- #9:
.*や.+がバックトラックで不利な理由 - 10: 危険な「Catastrophic Backtracking」前編
更新情報