概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: Using sets for many-to-many relationships
- 原文公開日: 2018/09/25
- 著者: Francisco Soto
訳文中のSQL文はsqlfum.ptで整形しました。
SQL: 多対多のリレーションを「集合」で扱う(翻訳)
- 本記事は、以前の私のブログ記事(2012/11)の再録です。
多対多とは何か
多対多リレーションシップを検索するために、データモデリングを扱うことは非常によくあります。関連する行を多数持つ2つのエンティティが自分のテーブルと他方のテーブルにそれぞれある形です。
よく使われるのは「記事」と「タグ」の例で、この場合1件の記事に多くのタグがあり、1件のタグに多数の記事があります。他にも「本」と「読者」の例もよく使われ、この場合1人の読者は多くの本を読むことができ、1冊の本は多くの読者に読まれます。
古典的なスキーマ
こうしたリレーションシップで用いるスキーマはどのようにしてモデリングするのでしょうか。
最初に、教科書どおりのやりかたについて説明します。この方法にはそれぞれメリットとデメリットがあります。「記事」と「タグ」の例で説明するのが楽なのでこれを使うことにすると、このモデルの問題は最終的に次のようになります。
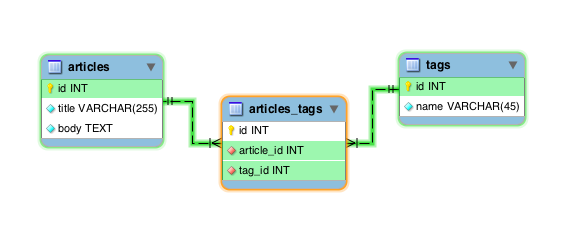
ここではarticlesとtagsという2つのエンティティがあり、両者を互いに結びつける第3のテーブルを用います。この第3のテーブルを結合テーブル(join table)または中間テーブル(junction tables)と呼びます(訳注: 本記事では以下中間テーブルと表記します↓)。
@osa522 呼び方がいろいろあるので悩みました。脚注に "交差テーブルは、関連テーブル、結合テーブル、多対多テーブル、マッピングテーブルなどと呼ばれることもありますが" と書きましたが、そういえば「中間テーブル」という呼び名もありましたね…… #sqlap
— Takuto Wada (@t_wada) December 19, 2013
中間テーブルには、2つのメインテーブルを指す外部キーがあります。1つの行は2つのメインテーブルの間の関係を1件作成し、多数の行は多対多の関係を作成します。
一方から他方をたどるのは簡単です。つまり、ある記事にどんなタグがあるかとか、あるタグにどんな記事が関連付けられているかです。たとえば、以下のクエリを実行すると、すべての記事とそれらのタグを出力します。
SELECT
articles.title, tags.name
FROM
articles
INNER JOIN articles_tags
ON articles_tags.article_id = articles.id
INNER JOIN tags ON tags.id = articles_tags.tag_id;
title | name
---------------------------+-------------
Buzzword about buzzwords! | open source
Buzzword about buzzwords! | ruby
Buzzword about buzzwords! | programming
古典的スキーマのメリット
リレーションシップについてのメタデータが必要な場合、このモデルが唯一の手法となります。メタデータは、たとえば「作成日」「作成者」であったり、「了承済み」「保留中」「キャンセル」などのステータスである可能性もあります。
もうひとつのメリットは、リレーションシップを簡単に変更できることです。追加や削除が必要な場合は、必要な行を変更するだけでよく、それ以外の部分は変更されません。
古典的スキーマのデメリット
このモデルは、リレーションシップそのものだけが欲しい場合で、かつデータのカーディナリティが本質的に小さい場合(=同じ組み合わせが多数出現する場合)には、極めて冗長になってしまいます。
上の例で言うと、タグの組み合わせが同じである記事が多数ある場合です。
article_id | tag_id
-------------+-------------
1 | 1
1 | 2
2 | 1
2 | 2
3 | 1
3 | 2
タグidが1と2という組み合わせが複数の記事で繰り返し出現しています。これでタグidが1と2の記事が100万件になると、中間テーブルの行数は200万件になってしまいます。
ブログ記事で実際にこのようなことが起こることはまずないと思われますが、行数が数百万件にのぼる他のデータセットでもこの原則は変わりません。
古典スキーマでは、容量が無駄に使われる(容量のコストは低いのですが)だけではなく、この容量の節約が重要になってきます。理由は、テーブルが小さいほどインデックスも小さくなり、それによってテーブルへのアクセスに必要なI/O操作の頻度も下がり、その分データベースマネージャでキャッシュされるデータが増加するからです。
行数が少ないほど操作は高速になります。
この冗長さは、メインテーブルへの参照が中間テーブルに存在することから生じます。組み合わせを作成する必要が生じるとき、既存の組み合わせについては考慮されません。既存の組み合わせを再利用できないのであれば、同じ組み合わせをまた作成するしかありません。
集合スキーマ
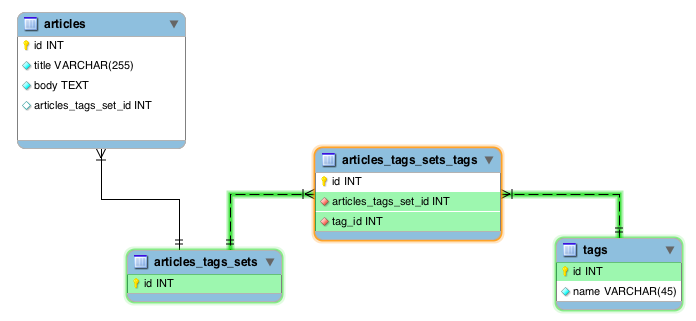
集合とは何か
以下は、Wikipediaにある、抽象データ型としての集合(セット型とも)からの引用です(参考: Wikipedia日本語版)。
コンピュータサイエンスにおける集合(set)とは、特定の値を保存する抽象データ構造の一種である。集合の中には順序も重複値も存在しない。集合は、数学における有限集合の概念をコンピュータで実装したものである。
Wikipedia英語版より大意
すなわち、値が重複しないデータ構造です。古典スキーマが冗長になる問題の解決に「少しは」使えそうな雰囲気です。
方法
単に中間テーブルを1つ導入するのではなく、さらにsetsというテーブルも導入します。そしてarticlesとtagsのリレーションではなく、setsとtagsのリレーションを設定します。
この場合のシナリオは次のようになります。
ユーザー1:
- ユーザーは記事を1件作成し、それにタグを2つ付ける。
- タグが存在しない場合は作成する。
- ここで自問自答: この組み合わせは
articles_tags_sets_tagsテーブルにあるか? - 答えはノーなので、
articles_tags_setsを1行作成する。 - そのsetの項目の
idを使って、今度はarticles_tags_sets_tagsを1行作成する。
articles_tags_set_id | tag_id
---------------------+--------
1 | 1
1 | 2
- その記事に適切なsetの項目ができたので、記事を作成し、articlesテーブルの
articles_tags_set_idカラムを使う集合に関連付ける。
ユーザー2:
- ユーザーは記事を1件作成し、それにタグを2つ付ける。
- タグは2つとも存在するので作成は不要。
- ここで自問自答: この組み合わせは
articles_tags_sets_tagsテーブルにあるか? - 答えはイエスなので、この組み合わせを表す
articles_tags_setsのidを引っ張ってくるだけでよい。 - このsetの項目idを用いて、
articles行を作成する。
何を行ったかおわかりでしょうか?記事が2件作成されましたが、集合の項目が再利用されています。記事のタグ組み合わせが同じになるたびに、再利用できています。
article_idを中間テーブルから取り除いて代わりにset_idを導入したことで、組み合わせを1つ作成しておけば記事がいくつあっても再利用できます。2つのタグが100万件の記事で使われていても、中間テーブルにはたった2つの行しかありません。凄いとは思いませんか?
組み合わせが一意であることから、これはsetと呼ばれます。そしてsetの1つの項目は、タグの一意の組合せを表します。
クエリ
記事1件に属するタグを検索するクエリは次のようになります。
SELECT
articles.title, tags.name
FROM
articles
INNER JOIN articles_tags_sets_tags
ON
articles_tags_sets_tags.articles_tags_set_id
= articles.articles_tags_set_id
INNER JOIN tags
ON tags.id = articles_tags_sets_tags.tag_id;
title | name
---------------------------+-------------
Buzzword about buzzwords! | programming
Buzzword about buzzwords! | startups
Buzzword about buzzwords! | ruby
...
これならわかりやすいですね。
このクエリは先ほどのクエリとほとんど同じ形になっていますが、中間テーブルにarticle_idを置くのではなく、記事のテーブルにarticles_tags_set_idがある点が異なります。このクエリの振る舞いは先ほどのクエリと完全に同じなので、リレーションシップの検索のコストはゼロであり、このテーブルが数十万行に増加しても、通常の中間テーブルの増加より小さく、データベースが扱う行数が極めて少なくて済むので、このJOINは高速になります。
集合の項目が既に存在するかどうかは次のように検索できます。
SELECT
articles_tags_sets.id AS set_item_id
FROM
articles_tags_sets_tags
JOIN articles_tags_sets
ON
articles_tags_sets.id
= articles_tags_sets_tags.articles_tags_set_id
WHERE
articles_tags_sets_tags.tag_id IN (3, 1)
AND (
SELECT
count(*)
FROM
articles_tags_sets_tags AS c
WHERE
c.articles_tags_set_id
= articles_tags_sets_tags.articles_tags_set_id
)
= 2
GROUP BY
articles_tags_sets.id
HAVING
count(*) = 2;
set_item_id
------------
20
クエリはシンプルとまでは言えませんが、複雑というほどでもありません。最初に、行の数(ここでは2行)にマッチする集合の項目を検索し、次にその組み合わせに正確にマッチする集合の項目を検索しているだけです。
注意点
この手法は手放しで利用できるものではありません。デメリットがいくつもあります。
デメリットの中でも筆頭かつ最大のものは、保存と更新に余分なコストがかかることです。1つの行を親テーブルと関連する行に保存しなければならなくなるたびに、子の特定の組み合わせが存在するかどうかを最初にチェックしなければなりません。その組み合わせが存在しない場合には作成しなければならないので、中間テーブルの行を出力すれば済むというわけにはいきません。
更新の場合、組み合わせに新しい行を1つ追加すると、チェックの必要な集合項目を新たに扱うことになります。その集合項目が存在しない場合は全体を作成しなければならないので、中間テーブルに1行挿入すれば済むというわけにはいきません。
このコストは、利用期間と利用状況の増大とともに返済されます。システムの運用が始まって間もない頃は、集合項目がまったく存在しないので、毎回時間と操作というコストを要します。それからしばらく時間が経てばさまざまな組み合わせが揃ってくるので、時間とともに再利用が効くようになってきます。
しかしこれによって別の問題が生じます。扱うデータは「記事とタグ」のように本質的に冗長でなければなりません。そうでないデータに対してこの手法を使うと、組み合わせの集合項目が再利用されず、逆にどんどん作成されてしまいます。この手法を使う場合は、データに繰り返しと冗長性が含まれているかどうかを分析したうえで決定する必要があります。おそらくデータベース全体に適用するのではなく、一部のテーブルに適用することになるでしょう。
さらに別の問題があります。この手法が使えるのはリレーション「だけ」が必要な場合に限られます。リレーションが親の多くの行で共有されるため、リレーションにその他の情報(メタデータ)が必要な場合には使えません。
現実の利用法
現実に使える事例として、私が業務で使っているデータベースからデータの一部を使ってご紹介します。
曲(song)のリストがあり、曲ごとに承認国のリストがあり(平均3〜5か国)、さらに曲ごとに販売方法が異なる(ストリーミング、ダウンロード、ラジオなど)とします。曲と国の組み合わせごとに、その国でのさまざまな販売方法が存在することになるので、多対多リレーションシップが必要になります。
データ件数:
| テーブル名 | 行数 |
|---|---|
| Song | 2.5 million |
| LocalizedSong | 12 million |
| DistributionType | 34 |
曲と国の組み合わせごとの流通の種類のリレーションシップは、平均して10〜15になります。
ここで普通の中間テーブルを使ったために、平均して125万行になり、クエリのスケールが極めて困難になってしまったのです(問題は多対多リレーションシップだけではなく、データモデルが複雑だったためでもあります)。
私たちの場合、カーディナリティが極端に低かった(多くのアルバムは同じレーベルに属し、販売の承認国と流通方法は1つのレーベルで同じ、アルバム内のどの曲も流通方法は同じ、など)ため、このリレーションシップを例の手法に切り替えました。それにより、リレーションシップのテーブルの行数を22,000程度にまで削減できたのです。削減前は1億2千5百万行でした!
この手法は、このようなスケーリングを扱う場合に非常に有用です。
最後に
私はRailsな方々向けに、この手法のコンセプトをhas-many-with-setという素敵なgemにまとめました。
このgemを気に入っていただいた方やご質問のある方は、私までお知らせいただければご相談に乗ります。このgemは、INgroovesでの私のスケーリング業務の一環として設計されたものであり、そのコンセプトを皆さんと共有いたします。皆さんにこのgemを気に入っていただければ、あるいはせめて皆さんが本記事からなにがしか得るものがあればと願っています。
このgemを活用して皆さまの会社のサーバー費用を削減し、社内でヒーローとなりましたら、ぜひお知らせください。私にとって何よりの喜びとなるでしょう。
おたより発掘
これは良くやる手法なんだけど、一見冗長に見えるし関連テーブルのデカさに気がつくのはだいぶ運用されてからなのでリファクタリングして変更するケースが多々ある。https://t.co/5aNGV7o9aQ
— いぬうだ (@vourja) April 6, 2019