Ruby: "Gilded Rose"のリファクタリングKataをやってみた(翻訳)
小規模でありながら複雑なビジネスコードをリファクタリングするための「ストーリーファースト」のアプローチ
このところ執筆の時間をろくに取れていません。夏をめどに長い記事をいくつか書くつもりでしたが、残念ながら進捗は思わしくありませんでした。しかし昨晩、かの有名な(と思うのですが、それまで知りませんでした)リファクタリングKataをたまたま知って試してみたい衝動に駆られ、試しながら自分のコードの書き方についての考察をいくつか書き留めました。
🔗 Kataとは何か

Gilded Roseは、さまざまなプログラミング言語で利用できるリファクタリング"Kata"として広く知られています。内容は以下のとおりです。
最初に、リファクタリングの対象となるシステムの概要を紹介します。
- すべての
itemsには、アイテムを販売しなければならない日数を示すSellInという値がある。- すべての
itemsには、そのアイテムの価値の大きさを表すQualityという値がある。- システムは1日が終わるたびに、すべてのアイテムで
SellInとQualityの値を減らす。かなりシンプルですよね?面白くなるのはここからです。
- 販売期間をすぎると、
Qualityの劣化スピードが2倍になる。- アイテムの
Qualityは決して負の値にはならない。- アイテムのうち、熟成ブリーチーズ(Aged Brie)は古くなるほど
Qualityが上昇する。- サルファラス(Sulfuras)は伝説のアイテムであり、販売もされず、
Qualityが下がることもない。- バックステージパス(Backstage passes)は、
SellInの期限が迫るに連れて熟成ブリーチーズと同様にQualityが上昇する。
SellInの残り日数が10以下になると、Qualityは2上昇し、残り日数が5以下になると、Qualityは3上昇する。- コンサートが終了すると、
Qualityは一気に0になる。さて、私たちは最近、ある召喚アイテムのサプライヤーと契約しました。これに伴い、以下のようなシステム更新が必要となります。
- 召喚(Conjured)アイテムの
Qualityは、通常の2倍の速さで劣化する。
UpdateQualityメソッドは自由に変更可能で、すべての機能が正しく動く限り、新しいコードを追加できます。ただしItemクラスを改変してはいけません。
Kataメンテナーが提供しているRuby版の初期実装はC#の実装をそのままRubyに移し替えたもので、深くネストした45行程度の恐ろしいメソッドで、す。演習課題は、このコードを適切と思われる方法でリファクタリングすることです。
このKataに対するRubyのソリューションはインターネット上にたくさん転がっていますが、ほとんどの場合、アイテム種別ごとにクラスを用意してロジックをそれらに分割するという標準的な方法が使われていて、個別のクラスのアクションごとにワンライナーメソッドを用意し、メソッド名は5ワード程度の長さにするというスタイルです。最近のRubyコミュニティの多くがこのスタイルを好んでいます。
このコードに対する私のアプローチは、ひと味違っています。私ならこのタスクをどう解決するかを本記事で示してみたいと思います。
「こんなのは業務で役に立たないおもちゃタスクなのでは?」たしかに並列処理もなければSQLの微調整もなく、マイクロ秒以下を争うようなベンチマークがあるわけでもありません。
率直に申し上げると、現代のコードベースの多くで書かれているビジネスコードのうち、驚くほど多くのビジネスコードがこの種の「シンプルに入り組んだ」タスクを解決しようとしています。しかし、この「無視できるほどの微細なレベル」における思考の表現方法が未熟なせいで、実行速度や安定性やシステム全体の設計に悪影響が生じていることがあまりにも多すぎます。だからこそ、私は主任開発者として「フレーズレベル」の表現力や、メソッドレベルのソリューションについて頻繁に言及しているのです。
🔗 単体テストを追加する
このコードには次のような「統合テスト」があります。
いくつかのアイテムの結果を30日分出力するスクリプトと、期待される出力結果ファイルがあります(オリジナルのKataでは特殊なツールでチェックするよう指示していますが、スクリプト言語ならチェック用スクリプト)をゼロから簡単に作れます)。
しかし、アトミックなテストがまだいくつか不足しているので、まずはここから手を付けることにします。
私のテスト方法は、以下のようなシンプルなものです。
- 私はTDD/BDDを好んでいます(「テストを書いてからコードを変更する」を堅苦しくない形で理解しています)。
-
私は、テストをコードと同じように扱うことにしています。
つまり、テストを書きやすく読みやすいものにしておくことで、自分が使っている言語の表現力を活かして、コードをできるだけ「自分の意図だけをくっきり示し、それ以外の余分なものを一切表現していない」状態にしたいのです。
後者は、少なくとも近年のRubyコミュニティでは、驚くほど逆風にさらされています。これについて以前かなり感情に走った記事を書いたことがありましたが、そこでの主張を繰り返すつもりはありません。ただ、私や同僚の経験ではこの方法は有効であり、当面変えるつもりはないということだけ申し上げておきます。
さて、「意図をくっきり表現する」ことについてですが、私がテストを「理論的に」書きたいと思っているのは、以下のような意味においてです。
- "this"のようなアイテムの場合
- 「N日後にはこんな値を得られるべき」
- 「M日後にはこんな値を得られるべき」
- それ以外のアイテムの場合
- 「N日後には...」
- (などなど)
つまり私の場合は以下のようにテストを書きました。
require_relative 'gilded_rose'
require 'saharspec'
require 'saharspec/its/with'
RSpec.describe GildedRose do
before { days.times { gilded_rose.update_quality } }
let(:gilded_rose) { GildedRose.new([item]) }
alias_matcher :become, :have_attributes
describe 'standard item' do
subject(:item) { Item.new(name="+5 Dexterity Vest", sell_in=10, quality=20) }
it_with(days: 1) { is_expected.to become(sell_in: 9, quality: 19) }
it_with(days: 10) { is_expected.to become(sell_in: 0, quality: 10) }
it_with(days: 11) { is_expected.to become(sell_in: -1, quality: 8) }
it_with(days: 15) { is_expected.to become(sell_in: -5, quality: 0) }
end
describe 'aged brie' do
subject(:item) { Item.new(name="Aged Brie", sell_in=2, quality=0) }
it_with(days: 1) { is_expected.to become(sell_in: 1, quality: 1) }
it_with(days: 5) { is_expected.to become(sell_in: -3, quality: 8) }
end
# ...以下省略
このテストコードでは、私のRSpec拡張ライブラリであるsaharspec(RSpecの思想と互換性を保つことを試みていますが、そのアイデアをさらに推し進めています)を使っており、その名もexperimentalという最近のブランチでit_withというメソッドを実装しています。

このit_withメソッドは、既にRSpecにあるコードの単なるショートカットです。
it_with(days: 1) { is_expected.to become(sell_in: 9, quality: 19) }
上のテストコードは、以下の素のRSpecコードに対応します。
context 'when it is day 1' do
let(:days) { 1 }
it { is_expected.to become(sell_in: 9, quality: 19) }
end
これは、同一のロジックに対して、「パラメータと期待される値」のさまざまな対応関係を指定する形で、たくさんのテストを書きたい場合に不可欠です。
テストのそれ以外の部分、たとえばsubjectの暗黙のテスト(it { is_expected.toは、上のsubjectで宣言されているものに暗黙で適用される)や表現力のあるマッチャーは、既にRSpecが提供しているものです。ただし、繰り返し申し上げますが、この種のツールを多用することは近年下火になっています。
入力と出力のペアを簡潔にテストする方法はこれだけではありません。以下のような真理値表を使う方法もあります。
{
1 => {sell_in: 9, quality: 19},
10=> {sell_in: 0, quality: 10},
11=> {sell_in: -1, quality: 8},
}.each do |day, attrs|
context "when it is day #{day}" do
before { day.times { gilded_rose.update_quality } }
it { is_expected.to have_attributes(**attrs) }
end
end
RSpecのshared_examples機能を使う方法もあります。
shared_examples "change by day" do |day, **attrs|
context "when it is day #{day}" do
before { day.times { gilded_rose.update_quality } }
it { is_expected.to have_attributes(**attrs) }
end
end
it_behaves_like 'change by day', 1, sell_in: 9, quality: 19
it_behaves_like 'change by day', 10, sell_in: 0, quality: 10
# ...
どの方法にもそれぞれメリットがありますが、it_withのアプローチは以下の点が私の好みです。
- 間接的な要素(入出力ペアと、両者の関係が、テスト内の離れた場所にあるなど)が存在しない
- テストが失敗した行の位置が正確に表示される
RSpecでは、テストの一部をわざと壊したときに行数を明示するようになっています。これを示すため、以下のテストでテストの1つを意図的に変更してみました。
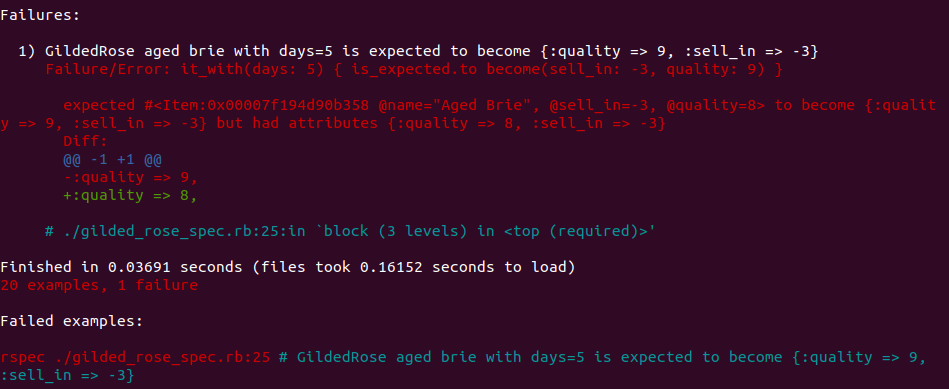
最後の行のコマンドrspec ./gilded_rose_spec.rb:25は、失敗したテストだけを素早く再実行してデバッグを楽にするのに必要です(これは、真理値表方式やshared_examples方式では困難です)。
開発者がテストに他の記述を追加しなくても、テストやエラーの情報が最終行のコメントでとてもわかりやすく表示されている点にご注目ください。英文法的に少々微妙ですが、とても明確です。
🔗 実装
テストが正しくパスするようになったら、実装に取りかかります。
要件を読み返してみると、すべての条件をシンプルな依存関係として記述可能であることに気づくかもしれません((name, sell_in) => Qualityの変化)。
現代のRubyでこれを最も自然な形で表現するには、Rubyのパターンマッチングが向いています。テストの失敗や数値の微調整を何度か繰り返した末に、すぐさま以下のようなコードができました。
class GildedRose
def initialize(items)
@items = items
end
def update_quality
@items.each { update_item(_1) }
end
def update_item(item)
return if item.name == "Sulfuras, Hand of Ragnaros"
change =
case [item.name, item.sell_in]
in ["Aged Brie", ..0]
+2
in ["Aged Brie", _]
+1
in ["Backstage passes to a TAFKAL80ETC concert", ..0]
-item.quality
in ["Backstage passes to a TAFKAL80ETC concert", ..5]
+3
in ["Backstage passes to a TAFKAL80ETC concert", ..10]
+2
in ["Backstage passes to a TAFKAL80ETC concert", _]
+1
in [_, ..0]
-2
in [_, _]
-1
end
item.sell_in -= 1
item.quality = (item.quality + change).clamp(0..50)
end
end
コードの可動部分は多くありません。
- 処理の不要な「伝説のアイテム」は冒頭のガード句(
return if)で早期脱出させる - 要件をほぼ文字通りにシンプルな対応関係(
[アイテム名, 残り日数を表すrange] => Qualityの変更量)に書き直した - 「Qualityは0〜50以外にしてはならない」という要件は、
Comparable#clampで素直に書き換えた。
これにより、「値の変更」操作と「rangeの制御」を切り離せるようになります(なおリファクタリング前のナイーブな初期実装では、条件文でrange内かどうかを判定して操作を実行していました)。
コードにコメントを追加した部分をもっと詳しく見てみましょう(コードの横幅が広くなりすぎないようにアイテム名を短縮しています)。
case [item.name, item.sell_in] # 「name」と「days to sell」のペアを比較する
# ...
in ["Backstage passes", ..0 ] # 条件「backstage pass, anything <=0」にマッチしたら
-item.quality # 残りのqualityを削除する
in ["Backstage passes", ..5 ] # それ以外の場合は、条件「backstage pass, anything <= 5」にマッチしたら
+3 # +3ポイント追加(追加を強調するため、あえて+を書いている)
in ["Backstage passes", ..10] # (以下同様)
+2 #
in ["Backstage passes", _] # nameがまだマッチし、sell_inがそれ以外の値の場合は
+1 # フォールバック値を返す
Rubyは、パターンマッチング内部で配列の個別の値に対するマッチングメソッドとして#===を使います。
また、マイナス無限大〜0を表すbeginless rangeである..0にも===が独自に定義されており、数値がrange内であればtrueを返します。
これでだいたいできました!コアメソッドは空行も含めて25行に短縮されました。しかも使っているのはシンプルな式4つと、条件やネストは1階層だけになりました。
余談
Rubyのlinter/スタイルチェッカーであるRuboCopは、デフォルト設定で以下を警告します。
- Cyclomatic complexity for update_item is too high. (10/7)(update_itemの循環参照)
- Method has too many lines. (22/10)(メソッドの行数が多い)
- Perceived complexity for update_item is too high. (10/8)(update_itemの複雑度が高い)
今皆さんが目にしているコードの複雑度や行数がそこまで犯罪的かどうかの判断はお任せします(個人的には、かなり昔から「メソッドの行数は少なく、メソッド名は詳しくわかりやすく」というこだわりはやり過ぎだと思っています)。
もう1つご注意いただきたい点があります。
元のKataのテキストでは「コードをゼロから書き直すのではなく、コードを小さく書き直しながらテストを実行することを何度も繰り返す形で、設計を段階的に改善する練習を行ってください」と指示しています。
しかし私のリファクタリングは、私がキャリアを積み重ねる中で確信するようになった手法のひとつをデモンストレーションする形になっています。
つまり、本当にヤバいコードがやってきたら、少なくとも範囲が狭ければ、一部をゼロから一気に書き直す方がむしろやりやすい場合が多いということです。小さな改善を多数積み重ねる方法は、元の意図が明確に伝わるような形に収束できない可能性もあります。
仮にそういうリファクタリング要件が指定されていない状況で私がヤバいコードに遭遇したとしたら、おそらく最初しばらくの間は、元の要件が明確になるまで小さな改善を繰り返し積み重ねる方法で作業を進めるかもしれません。その場合、まず真っ先にif文を(条件を繰り返し書くコストに目をつぶってでも)線形化してみて、分岐が実際にはいくつあるのかを実際に確かめてから、そのうえで要件をより良い形で実装する方法を検討したでしょう。
私は別ブランチで指示通りに作業しようとしましたが、早い段階で自分に正直に作業していなかったことに気づきました。要件に関する知識を頭から拭い去れなかったせいで、「そうそう、< 50の繰り返しがめちゃくちゃ多いんだよね」とばかりに途中をすっ飛ばしてしまいました。今後このKataをもう一度練習することがあれば、今度は正直に最初は要件を読まずにコードから要件を復元してみるのも一興ですが、今回はこのような形で進めました。
🔗 新しい要件を実装するのに必要なもの
Kataのトータルな目標は、コードを更新しやすくすることだったのを思い出しましょう。それでは、新しい要件↓に取りかかるとしましょう。
さて、私たちは最近召喚アイテムのサプライヤーと契約しました。これに伴い、以下のようなシステム更新が必要となります。
- 召喚(Conjured)アイテムの
Qualityは、通常の2倍の速さで劣化する。
要件をspecに落とし込むために、以下のテストブロックを追加する必要があります。
describe 'conjured item' do
subject(:item) { Item.new(name="Conjured Mana Cake", sell_in=10, quality=30) }
it_with(days: 1) { is_expected.to become(sell_in: 9, quality: 28) }
it_with(days: 10) { is_expected.to become(sell_in: 0, quality: 10) }
it_with(days: 11) { is_expected.to become(sell_in: -1, quality: 6) }
it_with(days: 15) { is_expected.to become(sell_in: -5, quality: 0) }
end
そして以下が実装のメインとなるcase文の一部です。
in [/Conjured/, ..0]
-4
in [/Conjured/, _]
-2
前述したように、パターンマッチングでは個別の値を===でチェックします。また、Regexp#===は「特定の文字で始まる任意の文字列」かどうかをチェックするのにも利用できます。
余談
場合分けを固定の文字列で指定していたのを、「指定の文字列が含まれているかどうか」をチェックする形に変更しなければならなくなると、それまでうまく進んでいたリファクタリングが突然動かなくなります。
そういうわけで、変更は空行を含めて8行に収まりました(統合テストも更新したのでコミット量はこれより多少増えますが)。
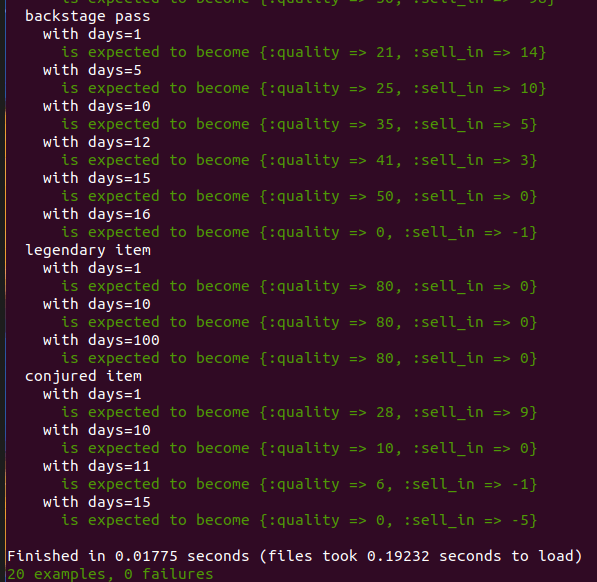
どうやら悪くなさそうです、が...
🔗 ウクライナ通信🇺🇦
ほんの少しお時間をください。私が生活しているウクライナが現在も侵略を受けていることを思い出していただくため、記事の途中にはさむことにしています。どうかお読みください。
とあるニュース・トピック: 武装解除されたウクライナ兵捕虜を剣で処刑する写真がSNSに放流されました。
とある背景情報: 「カナダ人」映画監督Anastasia Trofimovaの映画『Russians at War』の上映が多くの国際映画祭で決定されました。この映画はドキュメンタリーということになっていますが、実際にはロシアのプロパガンダチャンネルであるRTに雇われた人物によるプロパガンダです。
とある募金活動: ポクロフスクでもっとも重要な前線指揮を支援するためのPayPal募金活動。
引き続き記事をどうぞ。
🔗 本当にこれでいいのか?
ここで、こういう率直な疑問が生じます。「現実のアプリケーションだったら、1個のメソッドで大量の条件が使われているのをこのまま放置してよいものだろうか?」
要件の量や不確定な部分を考慮して率直に答えるなら、「はい」です。
しかし1つ気に食わないのは、パターンマッチングの中で同じ名前チェックが何度も繰り返されていることです。より「DRY」な代替案としては、以下のように昔ながらのcase/whenで書き直す方法が考えられます。
change =
case item.name
when "Aged Brie"
case item.sell_in
when ..0 then +2
else +1
end
when "Backstage passes to a TAFKAL80ETC concert"
case item.sell_in
when ..0 then -item.quality
when ..5 then +3
when ..10 then +2
else +1
end
else
case item.sell_in
when ..0 then -2
else -1
end
end
このソリューションは一長一短です。
- メリット: 名前チェックの重複が解消され、アイテムが論理的にグループ化されて見やすくなる
- デメリット:
case item.sell_inが重複する
同じパラメータを複数の場所でチェックしていることが見落とされやすく、その分壊れやすくなる(つまり、別のロジックが導入されて、分岐の一部で現在と異なる変数が使われるようになると、全体像が失われ始める)
現実のアプリケーションあれば、私ならその時点でよいと思った方を選ぶかもしれません(し、開発中に乗り換えるかもしれません)。
ケースが増えてきたら(あるいは私がアーキテクトとしての腕を上げたと思えるようになったら)、以下のように条件を定数ハッシュ化する「データ中心アプローチ」も検討に含めるかもしれません。
{
"Aged Brie" => {
..0 => +2,
1.. => +1
},
"Backstage passes to a TAFKAL80ETC concert" => {
..0 => :nullify, # ゼロにするための特殊値
1..5 => +3,
6..10 => +2,
11.. => +1
}
# ...(以下続行)
}
そしてこの変更に基づいたコードを選択することになるでしょう。
しかし、そうした定数をどのような形で網羅的に構造化するか(およびそういう構造化が本当に必要かどうか)を決めるのに十分なケースを網羅できたことを理解した後でなければ、私はこの方法を選びません。
ここから、さらなる疑問が生じます。
🔗 「でもチューショーカすればいいのでは?」
どうやら、Rubyistたち(に限りませんが)は、この種のタスクに対して直感的に、個別のケースを「対応するロジック片を実装する多数のクラス」に切り出す形で表現する方法を真っ先に思いつくようです(あまりによく見かけるので、私は「脊髄反射OOP」と呼んでいます)。
かく言う私もそうでした。しかし年月を経るうちに、こういう脊髄反射OOPをこらえることを学びました。同様に、(先ほどの「定数への切り出し」のような)早すぎる段階の抽象化に飛びつかなくなりました。
何らかのアルゴリズムを実装するのに必要なコード量は、基本的に1画面に収まるようにすべきですが、ストーリを1箇所に凝縮できると便利な場合がよくあります。
1箇所ですべてを見渡せるようになって、あちこちのクラスや小メソッドを開いたり探し回ったりせずに済むようになれば、どの変数が重要でどの変数がそうではないか(qualityは重要だが、sell_inはまったく重要ではない)、振る舞いにはどんな種類があるか(定数を1増やす、1減らす、nullにする)がはっきり見えるようになります。
そうなれば、たとえば「qualityが毎日半減する」ケースや「天候に応じてQualityの変化方法を変える」といったケースが(まだ?)網羅されていないこともただちに判明します。
私はこれを「ストーリーファースト方式」と呼んでいます。以下は私が最近EuRuKoで登壇したときのスライドです。動画も近いうちに公開されるようです。

訳注
その後動画が公開されました↓
当然ながら、このKataの要件に含まれる条件の個数はたかが知れているので、今後コードの量が増えてくれば、もっと適切な構造が見えてくるようになるかもしれません(おそらく脊髄反射的なものにはまったくならないでしょう!)。
- 「伝説のアイテム」は今後増える可能性があるか
- その場合意味付け(
qualityは一定で、sell_inは変更されない)は常に同じか - それとも常に過去と違うものが追加されるか
- その場合意味付け(
qualityの変更方法には、「増やす」「減らす」「nullにする」以外のパターンはありうるか- 同じ増減量を共通で使っているのはどの変更方法か、他と異なる増減量を使っているのはどの変更方法か
何かを切り出して抽象化することを検討する必要が生じる場合があるとすれば、可能なケースの個数が1画面に収まらなくなるほどコードが増えたときぐらいでしょう。そうやって切り出したものは、ほとんどの場合、小さなユーティリティとして、ストーリーを書いた言語における新しい「用語」として位置づけられるでしょう(1つにまとまったストーリーを切り刻んだ、互いに何の関係もない大量の部品になるのではなく)。
今回はこのぐらいにしておきましょう。結論の一部に(あるいはまったく)同意できないとしても、皆さんが他人の思考プロセスをたどる旅に興味を抱いていただければ幸いです。
お読みいただきありがとうございます。ウクライナへの軍事および人道支援のための寄付およびロビー活動による支援をお願いいたします。このリンクから、総合的な情報源および寄付を受け付けている国や民間基金への多数のリンクを参照いただけます。
すべてに参加するお時間が取れない場合は、Come Back Aliveへの寄付が常に良い選択となります。
概要
元サイトの許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。また、レイアウトの一部を見やすく変更しています。
参考: Refactoring Kataを使ってRubyのリファクタリングを練習する - マイペースなRailsおじさん
なお、Kataは日本語の「型」という言葉が由来ではありますが、どちらかというと日本の武道における型(の習得方法)というニュアンスに近いのと、プログラミング言語における型(type)と紛らわしいため、本記事ではKataと表記します。