訳注
以下の記事は、今回の内容に深く関連する新しい成果が紹介されているので、合わせて読むことをおすすめします。
参考: LLM のアテンションと外挿 - ジョイジョイジョイ
また、2025年に公開された以下のWebサイトは、LLMの内部をビジュアル表示で学べます。
🔗 ChatGPTのしくみとAI理論の根源に迫る:(10/16)ChatGPTの内部を覗いてみよう(翻訳)
いよいよChatGPTの内部がどうなっているかについて議論する準備が整いました。
今さらですが、ChatGPTは結局のところ巨大なニューラルネットそのものなのです(なお、本記事執筆時点のGPT-3と呼ばれるバージョンには、1750億の重みパラメータがあります)。
ChatGPTは、これまで解説してきたさまざまなニューラルネットと実に多くの点が似通っていますが、ChatGPTの設計は言語を扱うことに特化しています1。その中でも、最も注目すべき機能は、ニューラルネットの「トランスフォーマー(transformer)」と呼ばれるアーキテクチャです。
これまでの章で最初に解説してきたニューラルネットでは、どの層にあるニューロンも、その直前の層に存在するニューロンと(少なくとも何らかの重み付けパラメータを伴って)接続されるのが基本でした。しかし、構造が既にわかっている特定のデータを扱う場合、このようにネットワークを網の目のようにもれなく接続する、いわゆる完全接続ネットワーク(fully connected network)2は、(おそらく)やりすぎなのです。
そのため、たとえば画像処理の初期段階ではいわゆる畳み込みニューラルネット(convolutional neural nets)(略してconvnets)を使うのが一般的です。畳み込みニューラルネットのニューロンは、画像をピクセルに分割したものに似たグリッド上に効果的に配置され、それによってグリッド上の最寄りにあるニューロンにのみ接続されるようになります3。
トランスフォーマーというアイデアは、少なくともテキストを構成するトークンのシーケンスという「特定の構造」を対象にするという点では、畳み込みニューラルネットで画像という特定の構造を対象にする場合と似ています4。しかし畳み込みニューラルネットは特定の領域を固定的に定義しますが、トランスフォーマーは固定的な方法ではなく、注意(attention)、すなわち、あるテキストシーケンスに他のテキストシーケンスよりも文字通り「注目する(paying attention)」という(動的な)概念を導入します。
将来、汎用ニューラルネットをトレーニングする形であらゆるカスタマイズを行う方が有利になる日が来るかもしれませんが、現時点では、トレンスフォーマーがやっているように(そしておそらく人間の脳でもやっているように)「モジュール化(modularize)」することが重要であると思われます。
では、ChatGPTは(正確にはChatGPTのベースとなっているGPT-3ネットワークは)、具体的に何をやっているのでしょうか?
最初の章を思い出して欲しいのですが、ChatGPTの全般的な目標は、それまでトレーニング(Web上にある数十億ページものテキストを読ませるなど)で得た情報を元にして、テキストの続きを「まともな形で」生成することでした。つまり、どの時点でもある程度まとまった量のテキストが与えられているときに、その続きとして追加するトークンを適切に選べるようにすることが目標です。
ChatGPTのアルゴリズムは、以下の3つの基本ステージで構成されています。
- それまでのテキストをトークン化したシーケンスを受け取り、それらを表す埋め込み(つまり数値の配列)を見つけ出す。
- その埋め込みに対して、ネットワーク内の次の層へとさざ波が広がるように値を伝搬させる「ニューラルネットの標準的な手法」で処理を進め、それによって新しい埋め込み(つまり新しい数値の配列)を生成する。
- この配列の末尾部分を受け取って、そこから約50,000個もの値を生成し、次の候補になりうるトークンごとの確率に変換する。
原注
ここで使われるトークンの個数は、英語で一般に使われる単語数とだいたい同じぐらいですが、完全な単語に相当するトークン数は約3,000個で、残りは語の断片です(-ingなど)。
ここで重要なのは、ChatGPTの処理パイプラインは「あらゆる部分がニューラルネットワークだけで実装されている」ことと、「処理で使われる重み(weight)パラメータは、ニューラルネットワークのエンドツーエンドトレーニングだけで決定される」ことです。言い換えれば、人間はこのパイプラインで全体アーキテクチャの設計以外に何ひとつ手を加える必要がなく、トレーニングデータによる「学習」だけで成立するのです。
とはいうものの、ChatGPTのアーキテクチャのセットアップ方法には、ニューラルネットで培われたあらゆる経験則や秘技を反映した、細かなノウハウがたくさん存在します。そこまで話すと細かすぎて本筋から逸れますが、ChatGPTのようなものを構築するうえで何が必要かを理解するためにも、そうした細かな部分を2つ3つ説明しておくのは有益であろうと思います。
🔗 1: 埋め込みモジュール
最初に埋め込みモジュール(embedding module)について説明しましょう。以下の図は、GPT-2をWolfram言語で模式的に説明したものです。
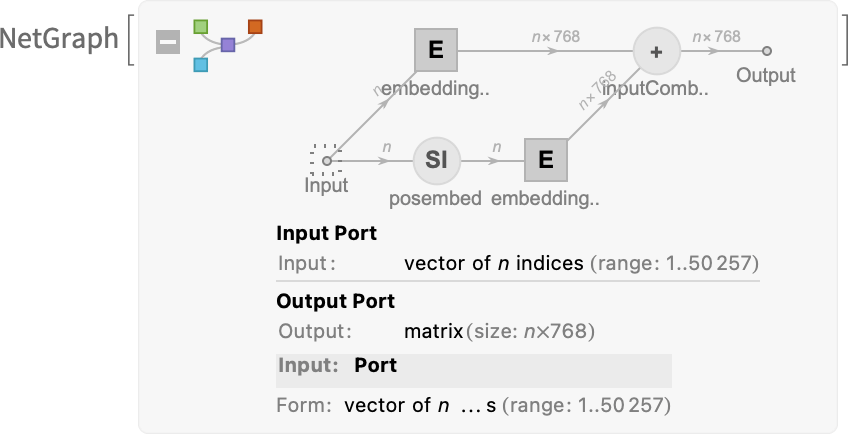
図の左側にある入力(input)に渡すものは、nトークンのベクトル(vector of n tokens)です(このデータも、上述のセクションと同様に1〜50,000程度の整数値で表されています)。
個別のトークンは、単層ニューラルネット(single-layer neural net)によって埋め込みベクトルに変換されます(GPT-2の場合は要素768個、ChatGPTで使われているGPT-3では要素12,288個)。
それと並行して、「二次経路」としてトークンの位置の整数値表示のシーケンス(sequence of (integer) positions)を受け取り、それらの整数から別の埋め込みベクトルを生成します。
最後に、トークン値から生成した埋め込みベクトルと、トークン位置の埋め込みベクトルを足し合わせることで、埋め込みモジュールから埋め込みベクトルの最終的なシーケンスを得られるという流れです。
トークン値から生成した埋め込みベクトルと、トークン位置の埋め込みベクトルを足している理由についてですが、ここに科学的な裏付けがあるとは到底思えません。単に、いろんなことを試した結果、このように足してみるとうまくいくらしい、という程度の話に過ぎません。
「方法論が"そこそこ正しい"ものでありさえすれば、細かな調整はトレーニングをみっちり行えばたいてい何とかなる」、「ニューラルネットがどう構成されているかを"エンジニアリングレベルで理解する"必要などまったくない」、これはある意味で、ニューラルネット業界における教訓のひとつです。
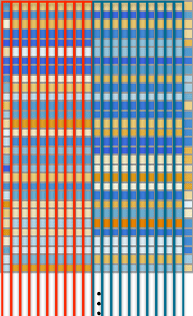
hello hello hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye byeという文字列(10個の"hello"と10個の"bye")を埋め込みモジュールで処理すると、以下のような感じでニューラルネット内を処理が進んでいきます。
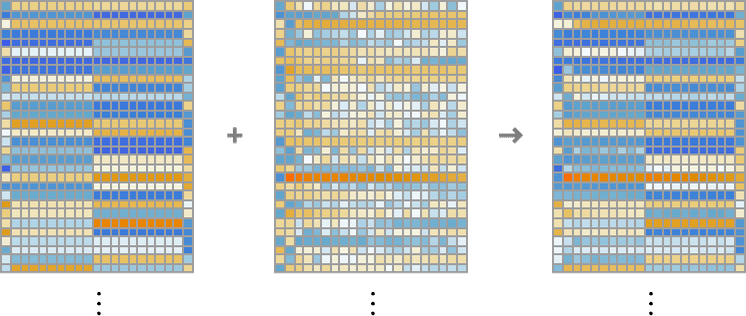
上の図には3つの要素が横並びに配置されていて、どの要素も埋め込みベクトルの各次元を縦方向に表示しています。上の図の左の要素はトークン値の埋め込み、真ん中は位置埋め込み、右は両者を足し合わせた最終的な埋め込みを表しています。
左の要素の横方向を見ると、埋め込みベクトルの左半分は"hello"に相当する埋め込みが10個、右半分は"bye"に相当する埋め込みが10個、規則正しく配置されています5。真ん中の要素の配列は「位置埋め込み」ベクトルであり、どことなくランダムな構造で、規則がよく見えません。真ん中の要素のこの構造は、まさしく「たまたまそう学習されたもの」に過ぎません(ここではGPT-2の場合)。
🔗 2: アテンションブロックとアテンションヘッド
さて、埋め込みモジュールの次にあるのは、トランスフォーマーの「メインイベント」とも言うべき、「アテンションブロック(attention block)のシーケンス」です(GPT-2では12個、ChatGPTのGPT-3では96個)。アテンションブロックはかなり複雑で、理解の難しいエンジニアリングシステムや、はたまた生物学的システムを彷彿とさせます。
ともあれ、以下に単一の「アテンションブロック」の模式図を示します(GPT-2の場合)。
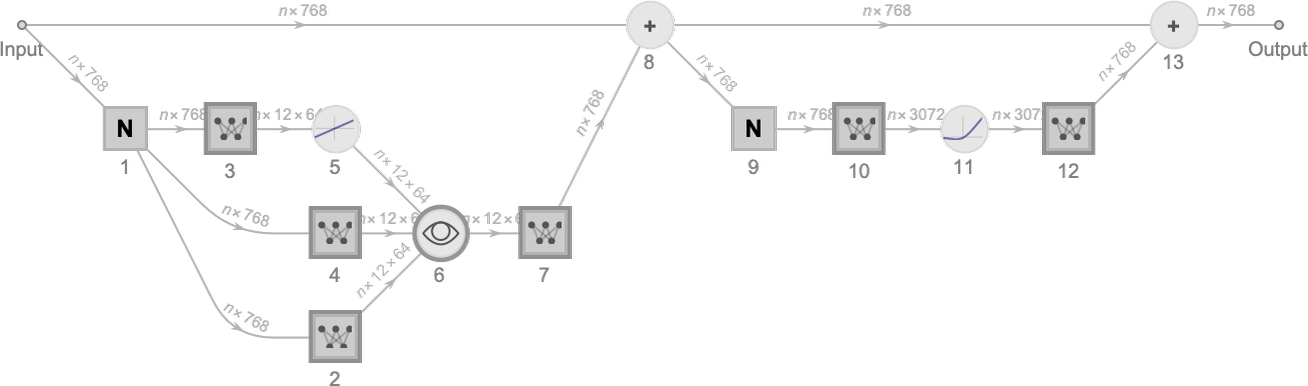
各アテンションブロックには、複数の「アテンションヘッド(attention head)」が存在します(GPT-2では12個、ChatGPTのGPT-3では96個)。そして、これらアテンションヘッドの1つ1つが、埋め込みベクトル内にあるさまざまな値のチャンク(chunk: 小さな塊)に対して独立して処理を行います。
原注
埋め込みベクトルを小分けにしてチャンクにするとうまくいく理由や、埋め込みベクトル内のチャンクがそれぞれ「何を意味するのか」について、具体的には何もわかっていません。これも例によって、「効果があることがわかっている」という経験則の1つにすぎません。
では、これらのアテンションヘッドはどんな処理を行うのでしょうか?
アテンションヘッドとは、基本的にトークンのシーケンス(つまりこれまで生成したテキスト)を「振り返って(looking back)」、「ここまでの歴史をパッケージ化する(packaging up the past)」手法です。
本記事の第2章で、2-gram確率を用いて直前の語に基づいて次に続くべき語を選ぶ方法について説明しましたが、トランスフォーマーに存在する「アテンションメカニズム(attention mechanism、注意機構とも)」のおかげで、直前の語のみならず、それよりずっと前に出現した語にも「注意を向ける」ようになるのです。このようにして、たとえば動詞が、それよりずっと以前に出現していた名詞を参照することが可能になります。
もっと細かなレベルで説明すると、アテンションヘッドは、さまざまなトークンに(特定の重み付けで)関連付けられる埋め込みベクトルをチャンクに分割したものを、再結合していると言えます。
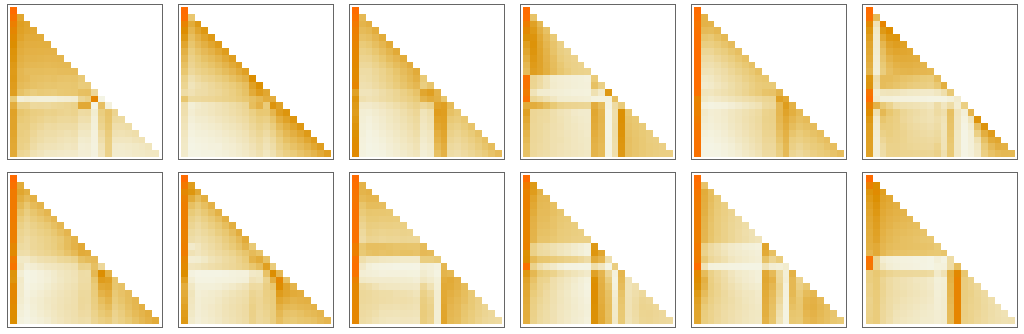
たとえばGPT-2の第1のアテンションブロック内に12個存在しているアテンションヘッドは、先ほどの"hello" 10個と"bye" 10個の文字列に対して「トークンシーケンスの冒頭まで遡る」パターンの「再結合重み(recombination weights)」を、以下の図のような形で持ちます。
アテンションヘッドによる処理を経て得られる「再重み付け済み埋め込みベクトル(re-weighted embedding vector)」(GPT-2では768個、ChatGPTのGPT-3では12,288個)は、標準的な完全接続のニューラルネット層に渡されます6。この層が何をやっているかを理解するのは困難ですが、そこで使われている768×768の重み行列を以下に図示します(これはGPT-2の場合)。

しかし上の図で64×64の移動平均(moving average)を取ると、ある種の(ランダムウォーク的な)構造が模様のような形で姿を表し始めます。
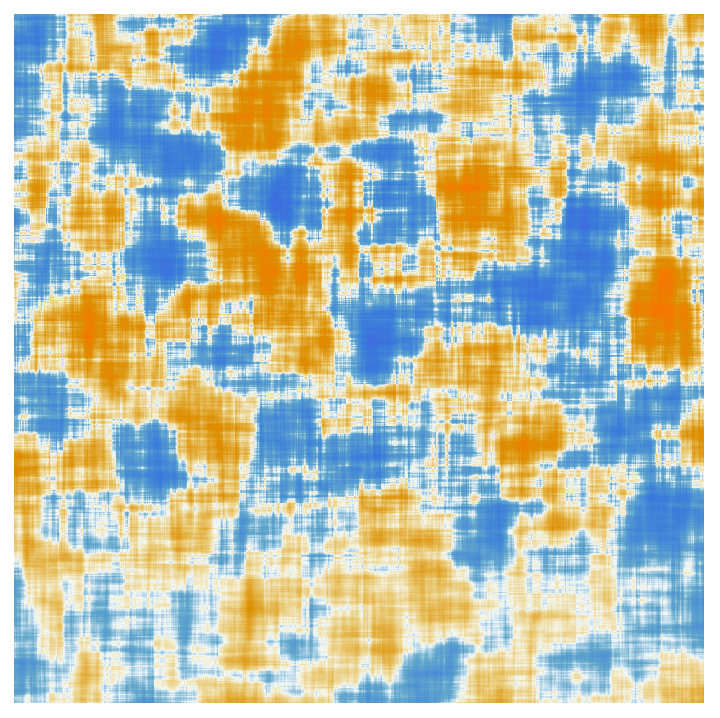
では、この構造は何によって決定づけられているのでしょうか?突き詰めれば、おそらく人間の言語の特徴(feature)を何らかの形で「ニューラルネットにエンコーディングしたもの」ということになるのでしょう。しかしその特徴が何なのかは、現時点では皆目見当がつきません。
私たちは確かにChatGPTの(少なくともGPT-2の)頭蓋骨の蓋を開いて脳みその中身を覗いているのですが、ChatGPTの中身はどうにも込み入っていて何もわからない、ということを発見することになります。ChatGPTの脳みそが人間に理解可能な言語を生成しているにもかかわらず、です。
さて、1個のアテンションブロックで処理が終わると、そこから新たな埋め込みベクトルを得られます。これは後続の追加アテンションブロック(GPT-2では合計12個、ChatGPTのGPT-3では合計96個)に次々に渡されます。「注意」と「完全接続」の重みのパターンは、アテンションブロックごとに移り変わります。
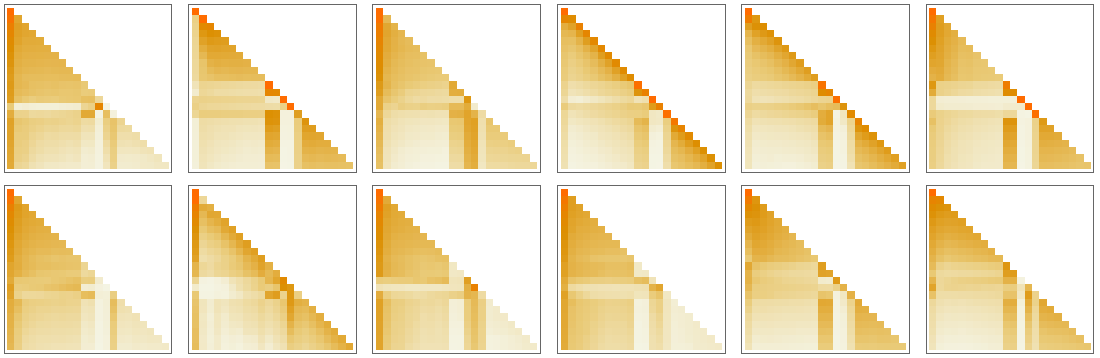
以下の12個の図は、GPT-2の1番目のアテンションヘッドに"hello" 10個と"bye" 10個の文字列を入力したときに、アテンションの重みがアテンションブロックごとにどう変化しているかを順に示したものです。
そして、完全接続の各層における移動平均を取った「行列」は、以下のようになります。
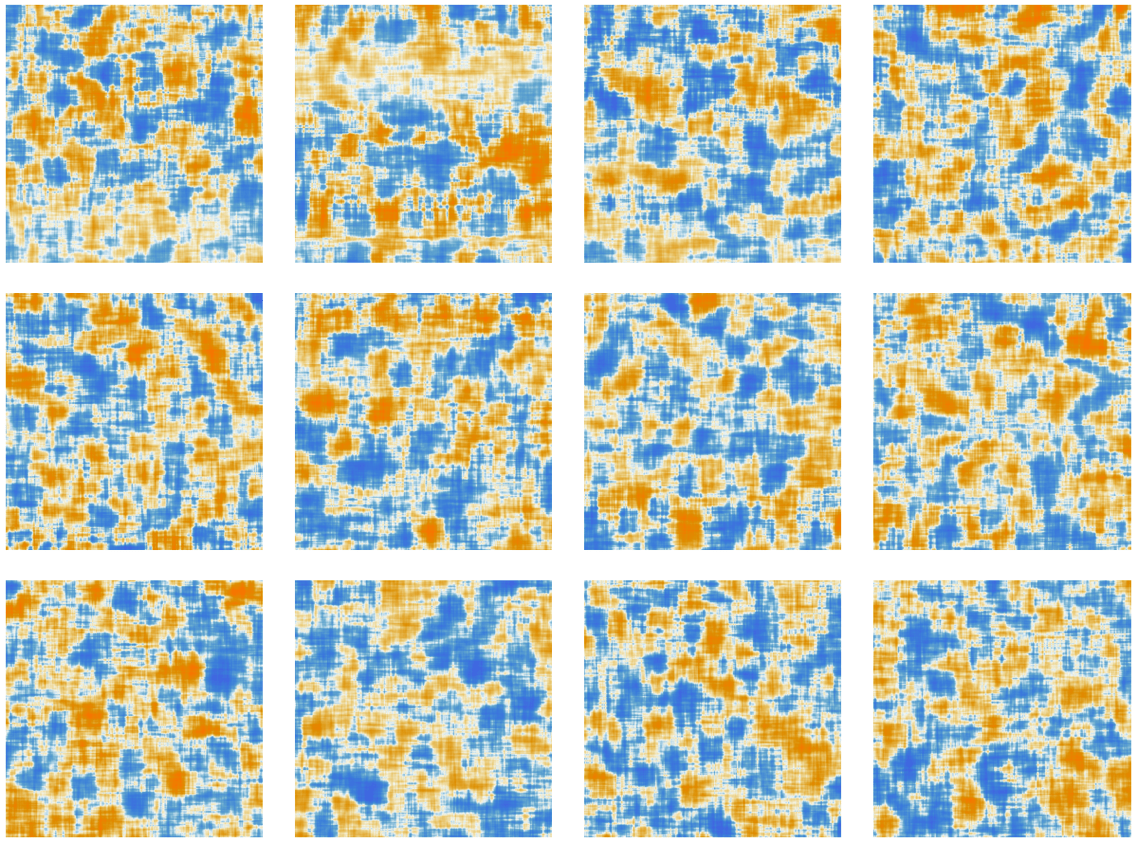
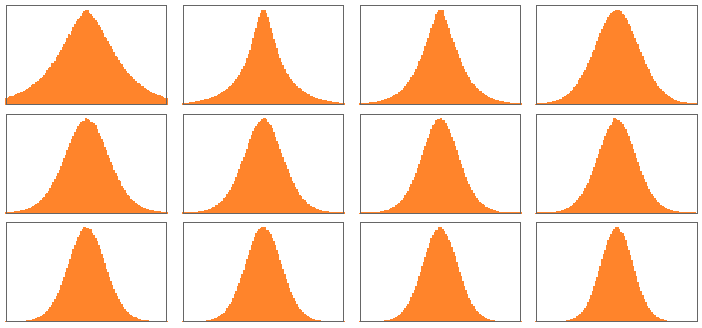
ここで興味深いのは、12個のアテンションブロックにおける「重み行列」の見た目が互いに似ているにもかかわらず、それぞれの重みのサイズの分布を取ってみると、以下の図のように分布にどことなく違いが生じることです(ガウス分布になるとも限りません)。
では、すべてのアテンションブロックを通過して処理を終えたときに、トランスフォーマーの最終的な効果はどのように現れるのでしょうか?
トランスフォーマーの最終的な機能とは、トークンシーケンスに対する元の埋め込みのコレクションを、最終的なコレクションに文字通り変換(transform)することです。そしてChatGPTの特徴的な振る舞いとして、このコレクションから末尾の埋め込みを拾い上げてそれをデコードし、元のテキストの続きとしてどんなトークンが来るかを表す確率のリストを生成します。
以上が、ChatGPT内部で行われている処理の概要です。
一見複雑なことをしているようでいて(「エンジニアリング上の選択」の大半が、根拠のない恣意的なものにならざるを得ないので、なおさら複雑に見えるでしょうが)、実のところ、ChatGPTの処理を構成する最終的な要素は、どれもこれも驚くほどシンプルです。
私たちが扱っているのは、結局「人工ニューロン」でできたニューラルネットにすぎず、個別の人工ニューロンは「入力で受け取った数値のコレクションを、特定の重みに基づいて結合する」ことをひたすら実行しているだけなのです。
ChatGPTに渡される元の入力は、ただの数値の配列(=それまでの文をトークン化したものに対応する埋め込みベクトル)です。
ChatGPTが「動いて」新しいトークンを生成するときにやっているのは、入力された数値を「さざ波のように」ニューラルネット製の層から層へと進めることです(前方伝播)。その途中の各ニューロンは、「自分がやるべきこと」を粛々と行って、結果を次の層のニューロンに渡します。
これらの処理のどこにも「戻りの経路」は存在しません。すべてはネットワークの中を前へ前へと進むしかありません7。
このような作りは、チューリングマシンのような典型的な計算システムとまるで異なっています。チューリングマシンは、同じ計算要素を用いて、処理を何度でも「再処理」するのが普通です。
しかしChatGPTのようなトランスフォーマーでは、個別の計算要素(つまりニューロン)は、少なくとも1個の出力トークンを生成するときには、どれもたった1度しか使われません。
しかしここでChatGPTのコアの話、つまり各トークンを生成するときに繰り返し使われるニューラルネットの話に戻ることにしましょう。
ChatGPTで使うニューラルネットは、まったく同じ作りの人工ニューロンの集合体なので、ある意味きわめてシンプルです。
また、このネットワークの中には(完全接続の)ニューロン層だけでできている部分もあり、その層にあるすべてのニューロンは、その直前の層にあるあらゆるニューロンと(何らかの重み付けによって)網の目のように接続しています。
しかし、特にトランスフォーマーアーキテクチャを採用しているChatGPTの場合、層ごとに特定のニューロンだけが接続されるという、より構造化の進んだ部分も持ち合わせています。
原注
もちろん、「すべてのニューロンが接続されている」と見なすことも可能ですが、重みゼロの(つまり事実上接続されていない)ニューロンも存在しています。
さらに、ChatGPTのニューラルネットには、「均質な」層だけで構成されているとは考えにくい側面もあります。
たとえば、上に再録した前述のアテンションブロックの模式図に示されているように、アテンションブロック内部には「入力データのコピーを複数作り出す」場所があり、それぞれ異なる「処理パス」に枝分かれしています。この枝分かれした処理は複数の層にまたがっていることもありますが、後に単純に合流して再結合されています。
これはこれで、ChatGPTのトランスフォーマーで行っている処理の実装を理解するには便利ですが、概念上はこれらの構造はいつでも「密に詰まった」層(=完全接続)とみなしても構いません。つまり、すべてのニューロンを網羅的に接続したうえで、使わない接続の重みをゼロにすれば同じ結果を得られるということです。
ChatGPTの処理パスの中で最も長いものは、約400個の(コア)層が関連しています。ある意味、この層の数は大きくありませんが、ニューロンについては数百万個、接続数は合計1750億個、そして重みパラメータ数も1750億個にものぼります。
そして、ChatGPTは新しいトークンを生成するたびに、この膨大な重みパラメータすべてについて計算を実行しなければならないことをぜひとも知っておくべきです。
これら計算は、実装上は何らかの形で「層ごとに組織化され」、GPUで計算しやすい高度に並列化した配列操作になります。しかし生成されるトークン1個につき1750億個もの計算(最終的にはもう少し増えますが)を行わなければならない点は同じです。
したがって、ChatGPTで長いテキストを生成するのに時間がかかるのは当然です。
しかしChatGPTで最終的に注目すべき点は、個別の操作は実にシンプルでありながら、それらの操作をすべて寄せ集めることで、「まるで人間が書いたような」品質のよいテキストを確かに生成できていることです。
ここで改めて強調しておきたいのは、これらがなぜうまく行くのかを説明できる「究極の理論的根拠」は存在しないということです(少なくとも私たちが知る限りでは)。
実際、私としては、本記事のこの後の章で議論するように、これは(もしかすると驚異的な)科学的大発見と見なすべきなのではないかと思っているのです。つまり、人間の脳が言語を生成するときに行っている情報処理の本質を、ChatGPTのようなニューラルネットで捉えることが可能になるということです。
関連記事
- 訳注: これは元記事執筆時点での話です。 ↩
- 訳注: 完全接続ネットワークのニューロンは遠くにも近くにもすべて接続されるので、パラメータ数が増えて計算コストが増えます。画像認識の例で説明すると、完全接続ネットワークは特定の構造に限定されない分汎用性が高すぎ、同じ顔でも画像内で違う位置に表示される場合はそれらをすべて学習しなければならなくなり、学習コストが高くなります。 ↩
- 訳注: 畳み込みニューラルネットは遠くのニューロンに接続しなくなるので、計算コストを下げられます。画像認識の例で説明すると、畳み込みニューラルネットは強い帰納バイアス(Inductive Bias)(局所性と平行移動不変性)を持ち、 同じフィルタ(重み)を画像全体で共有するため、同じ顔が画像の上下左右どの位置にあっても自然に顔の特徴を検出できます。 ↩
- 訳注: いずれにしろ完全接続ネットワークではありません。 ↩
-
訳注: この図で言うと、赤で囲んだ部分がhelloに相当する埋め込み、青で囲んだ部分がbyeに相当する埋め込みです。埋め込みベクトルは巨大なので、図では下の部分が省略されています。
 ↩
↩
- 訳注: つまり渡す先が畳み込みニューラルネットではないということです。 ↩
- 訳注: ここで説明されているフィードフォワード処理は、トランスフォーマーを「実行するとき(=推論時)」の話であることにご注意ください。トランスフォーマーが学習するときには、バックプロパゲーション(誤差逆伝播法)のようなフィードバックが行われるのが普通です。 ↩
概要
原文サイトのCreative Commons BY-NC-SA 4.0を継承する形で翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。原文が長大なので、章ごとに16分割して公開します。
スタイルについては、かっこ書きを注釈にする、図をblockquoteにするなどフォーマットを適宜改善し、文面に適宜強調も加えています。
元記事は、2023年2月の公開時点における、ChatGPTを題材とした生成AIの基本概念について解説したものです。実際の商用AIでは有害コンテンツのフィルタなどさまざまな制御も加えられているため、そうした商用の生成AIが確率をベースとしつつ、確率以外の制御も加わっていることを知っておいてください。
本記事の原文を開いて、そこに掲載されている図版をクリックすると、自分のコンピュータでもすぐに実行して試せるWolfram言語コードが自動的にクリップボードにコピーされるようになっています。
コモンズ証 - 表示 - 非営利 - 継承 4.0 国際 - Creative Commons