🔗 ChatGPTのしくみとAI理論の根源に迫る:(9/16)「埋め込み」の概念を学ぶ(翻訳)
ニューラルネットの原理は、少なくとも現状では、数値に基づいています。ということは、ニューラルネットをテキスト処理に用いるには、何らかの形でテキストを数値で表現する必要があるということです。
もちろん、(ChatGPTが基本的にやっているのと同様に)辞書内のあらゆる語(word)に通し番号を振る形で作業を開始することも一応可能ですが、それよりもずっと重要な概念があります。それが、ChatGPTなどの生成AIの中核を占めている「埋め込み(embedding)」というアイデアです。
埋め込みは、何らかの「本質」を数値の配列で表現する方法とみなすことが可能であり、2つの数値が互いに近い位置にある場合、2つの数値が表す内容も意味的に近い、という性質を持っています。
たとえば、語の埋め込み(word embedding)とは、ある種の「意味空間」内に語を配置する試みであると考えられます。この埋め込みの中では、意味的に近い語同士は、互いに近い場所に配置されます。ChatGPTなどで実際に使われている埋め込みでは、数値リストの規模が大きくなる傾向にあります。しかしこれを以下のように2次元に投影することで、埋め込み内で語がどのように配置されているかという例を見ることが可能です。

上の図の中にある語の配置を見てみると、種類が近い語同士が寄り集まっていて、たしかに語の典型的な印象をうまい具合にキャプチャしているように思えます。しかしこのような埋め込みはどうやったら構築できるのでしょうか?
大まかに説明すると、大量のテキスト(ここではWebからかき集めた50億語分のテキスト)内で、それらの語が出現する「環境」が「どのぐらい似ているか」を調べるという方法です。
たとえば、爬虫類であるアリゲーター(alligator)とクロコダイル(crocodile)は、似たような文脈で互いに取り替え可能な形で出現することが多くなります。しかし作物であるカブ(turnip)と鳥類であるワシ(eagle)は、似たような文脈に登場することがあまりないので、埋め込みの2次元図では互いに離れた場所に配置されます。
しかし、こうした埋め込み2次元図のようなものをニューラルネットで実装するにはどうすればよいのでしょうか?
そこで、最初は語の埋め込みではなく、画像の埋め込みで考えてみることにしましょう。つまり、「似ていると思われる画像」同士には値の近い数値リストを割り当てる形で、数値のリストを用いて特徴づける(characterize)方法を見つけたいのです。
さて、「画像が似ていると思われる」と一口に言っても、何を手がかりにすれば画像が似ている度合いを判断できるのでしょうか?
たとえば、手書き数字の認識問題であれば、2つの画像が同じ数字を表している場合は「2つの画像は似ているとみなす」という判断基準を使えそうです。本記事ではこれまでに、手書き数字を認識するようトレーニングされたニューラルネットについて考察してきました。このニューラルネットは、与えられた画像を数値を表す10個の容器に振り分けるようセットアップされていると考えられます。
しかしここで、「この画像は"4"である」と判定される直前の段階で、ニューラルネット内部を「覗き込んで」みたと想像してみたらどうでしょう?そのニューラルネットの中には、おそらく「これはほぼ"4"と思われるが、少しばかり"2"のようにも思える」といった感じで画像を特徴づける数値のリストが見えることでしょう。このような数値を拾い集めて埋め込みの要素として活用するという考え方なのです。
考え方としては以下のようになります。
「どの画像がどの画像と似ているか」をいきなり特徴づけようとするのではなく、代わりに、明示的なトレーニング用データを入手可能で、かつ定義の明確なタスク(ここでは手書き数字の認識)を考察することにします。そのうえで、このタスクを実行するときにはニューラルネットが必ず「画像同士の近さの判定」に相当するタスクを行うことを利用します。
つまり、「この画像とこの画像は似ているのか」という判定基準を明らかにする必要はなく、「この画像はどの数字に対応するのか」という具体的な問いかけに専念し、画像同士が"近い"とはどういうことかについては、ニューラルネットに暗黙的に決定させるということです。
では、手書き数字認識用のニューラルネットは、詳しくはどのように機能するのでしょうか?このネットワークは、以下の図のように連続する11の層とみなせます。各層の機能は、以下のようにアイコン的に要約できます(活性化関数は個別の層として表現されています)。

最初に、11の層のうち冒頭の第1層に実際の画像を入力します。この画像は、ピクセル値の2次元配列で表されています。
最後に、11の層の末尾にある第11層から、10個の値の配列が出力されます。
出力の配列に含まれる10個の値は、入力された数字画像が、0から9のうちどれが「最も確からしい」と考えられるかを、0〜9の数字ごとに配列内で順に示すものと考えてよいでしょう(訳注: 配列の数字が大きいほど確信度が大きいことになります)。
たとえば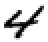 という画像を入力に与えたときに、末尾の第11層のニューロンが返す値は以下のような配列になります(訳注: 配列の位置は冒頭を0として数えるので、上の行が0,1,2,3,4に、下の行が5,6,7,8,9に対応します)。
という画像を入力に与えたときに、末尾の第11層のニューロンが返す値は以下のような配列になります(訳注: 配列の位置は冒頭を0として数えるので、上の行が0,1,2,3,4に、下の行が5,6,7,8,9に対応します)。
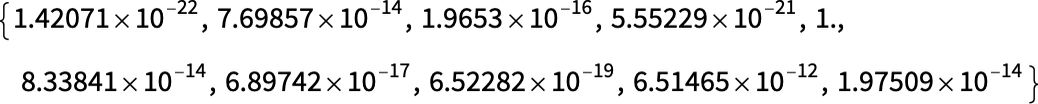
配列で4に相当する値(1行目の一番右)が1で、それ以外の値が1よりもずっと小さいということは、このニューラルネットはこの時点でこの数字画像が4であることを「相当強く確信している」ことになります。これで、後は配列の中から最大値を持つニューロンの位置を見つければ、その値が配列の何番目であるかが、ここで欲しい答え、すなわち4となるわけです。
しかし、1つ前の第10層を覗き込んでみたらどんなふうになっているでしょう?このニューラルネットの最後の処理である第11階層ではsoftmaxと呼ばれる、「確実性の強制(force certainty)」を試みる操作が行われています。しかし、第11階層の直前である第10階層のニューロンは、こんな値になっていて少々様子が異なります。
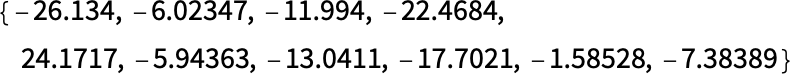
4に該当するニューロンの値は第10階層でも他より高い値になっていますが、他の数字に相当する位置の値にも、他の数字に関するニューロンの情報が含まれています。
つまり、このような値のリストは、ある意味で手書き数字画像の「本質」を特徴づけるのに利用できるということでもあります。言い換えれば、この値のリストは埋め込みに利用できるということです。
たとえば、以下に4の手書き画像がいくつかありますが、それぞれの数字には「シグネチャ(signature)」(特徴埋め込み(feature embedding)とも呼ばれます)が対応付けられています。そして、4のように見える手書き画像のシグネチャ(訳注: ここでは横に並んだ色の模様で表現されています)は、8のように見える末尾の2つのシグネチャと大きく異なっています。

ここでは手書き数字画像の特徴づけのために基本的に10個の数字を用いていますが、実際にはずっと多くの数字を使う方が多くの場合効果的です。
たとえば、手書き数字認識ネットワークでは、直前の層から500個の数字の配列を取得できます。この配列は、おそらく「画像埋め込み」用に適しているでしょう。
手書き数字を「画像空間」上で明示的にビジュアル表示したい場合は、取得した500次元のベクトルを、たとえば以下のように3次元空間に投影する形で「次元を削減」する必要があります。
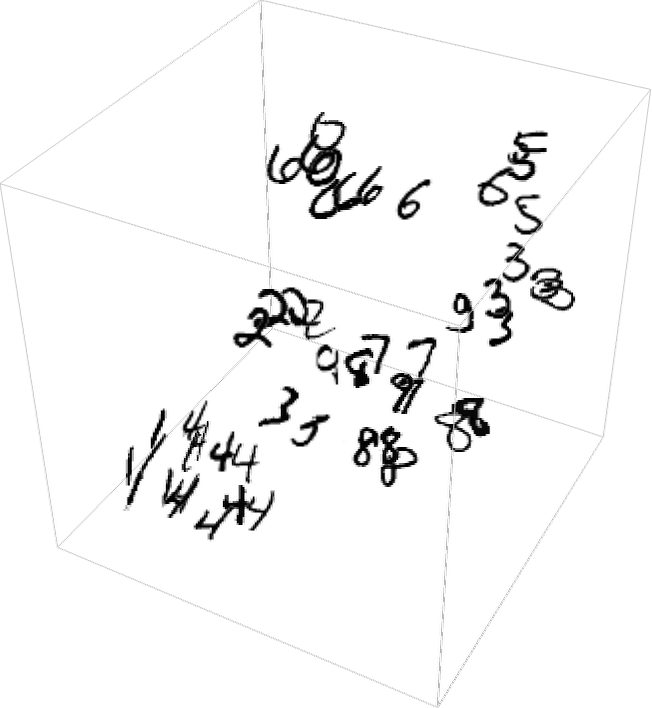
ここまでに説明した画像の特徴づけ(および埋め込み)の作成方法は、画像が同じ手書きの数字に対応するかどうかを(トレーニングセットに基づいて)判断することで画像同士がどの程度似ているかを識別するというアイデアに基づいています。
たとえば、一般的な物体(ネコ、イヌ、椅子など)の画像が5000種類あり、その中のどれであるかを識別するトレーニングセットがあれば、これと同じ画像認識をさらに一般的な形で実行できるわけです。
このようにして、人間が認識する身近な物体を識別して「アンカリング(anchored: いわゆるラベル付け、タグ付け)」を行った画像の埋め込みを作成すると、以後はニューラルネットの振る舞いに応じて、学習したもの以外の画像についても一般化されます。
ここで重要なのは、ニューラルネットの振る舞いが、人間が画像を認識して解釈する方法と一致している限り、その埋め込みは「人間にとって正しいと思われる」ものとなりますし、実際に「人間の判断に近い」タスクを実行するうえで有用であるということです1。
なるほど、画像についてはわかりました。では、埋め込みたいものが語(word)の場合は、同じような路線でどんな方法を採用すればよいのでしょうか?ここで重要なのは、最初は人間がニューラルネットを楽にトレーニングできるタスクを行うことです。トレーニングしやすいタスクといえば、いわゆる「単語予測(word prediction)」が定番です。
たとえば、「the ___ cat」という穴埋め問題が与えられたとしましょう。
Web上の膨大なテキストコンテンツのような大規模なテキストコーパス(corpus)を元にした場合、穴埋めに使われるさまざまな語の確率はそれぞれどのぐらいか?
あるいは、「___ black ___」という穴埋め問題があたえられた場合、左右の穴埋めに使われるさまざま語の組み合わせの確率は、それぞれどのぐらいか?
この問題をニューラルネットでセットアップするには、最終的にはすべてを数値で表現する必要があります。
数値化する方法の1つは、英語で頻出する約5万語の語に一意の番号を割り振ることです(例: "the"は914、前にスペースが付いている" cat"は3542...)。ちなみに、この数字は実際にGPT-2で使われているものです。
つまり、「the ___ cat」穴埋め問題であれば、入力は  となるでしょう。このときの出力は、約5万語の数値のリストに、「穴埋め」に使われうる確率を効果的に各語に表したものになるでしょう。
となるでしょう。このときの出力は、約5万語の数値のリストに、「穴埋め」に使われうる確率を効果的に各語に表したものになるでしょう。
そして語の埋め込みを見つけるときにも、画像のときと同様に、ニューラルネットワークが「判定を下す」直前の層でニューラルネットワークの「内部」を「覗き込んで」、そこに出現する「各語を特徴付ける」と考えられる数字のリストを取得します。
ところで、この特徴づけとやらは、いったいどういうものなのでしょうか?
この10年間というもの、word2vec、GloVe、BERT、GPTなどのさまざまなシステムが開発されており、基本となるニューラルネットワークへのアプローチもそれぞれ異なっています。しかし結局、どれも1語あたり数百〜数千個の数値リストを与える形で語を特徴づける点は同じです。
このようにしてできた「埋め込みベクトル(embedding vector)」を眺めただけでは、これといっためぼしい情報は見当たりません。たとえば、GPT-2が3つの単語について生成した埋め込みベクトルを表示すると、以下のような感じになります。
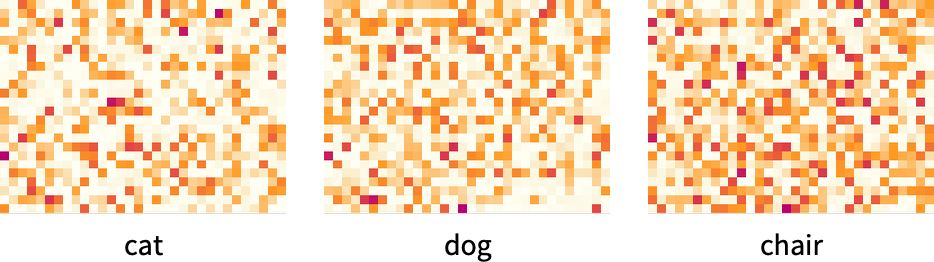
これらのベクトル同士の距離を数学的に測定すれば、語同士の「近さ(nearness)」を見いだせます。このような埋め込みが「認知的に」どのような重要性を持つかについては後ほど議論しますが、さしあたって重要な点は、語を「ニューラルネットに適した」数値の集合に変換する方法が存在するということです。
しかし、特徴づけに使えるのは語だけではありません。語と語のつながりや、テキストブロック全体を特徴づけることも可能です。
そしてChatGPTの内部では、まさにこのような方法で処理を行っているのです。
ChatGPTは、取得したテキストを入力として受け取り、テキストを表現する埋め込みベクトルを生成します。その目的は、次に出現する可能性のあるさまざまな語の確率を求めることです。そして、得られた答えを、次に出現する可能性のある約5万語のリストに、それぞれ確率を割り振った数値リストとして表現します。
原注
厳密に言うと、ChatGPTが扱っているのは語(word)ではなく、トークン(token)を扱います。トークンとは、語全体を扱うことも、"pre"や"ing"や"ized"といった語の一部を扱うこともできるので、言語処理の単位として便利です。ChatGPTはトークン単位で処理することで、さまざまな目新しい語や複合語、英語以外の語も生成できますし、時には良くも悪くも新しい語をひねり出すこともあります。
関連記事
- 訳注: 画像が客観的に正しいかどうかは重要ではありません。たとえ錯視の画像であっても、人間とニューラルネットが両方ともイヌだと判定するなら、ニューラルネットのその判定は妥当だということです。 ↩
概要
原文サイトのCreative Commons BY-NC-SA 4.0を継承する形で翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。原文が長大なので、章ごとに16分割して公開します。
スタイルについては、かっこ書きを注釈にする、図をblockquoteにするなどフォーマットを適宜改善し、文面に適宜強調も加えています。
元記事は、2023年2月の公開時点における、ChatGPTを題材とした生成AIの基本概念について解説したものです。実際の商用AIでは有害コンテンツのフィルタなどさまざまな制御も加えられているため、そうした商用の生成AIが確率をベースとしつつ、確率以外の制御も加わっていることを知っておいてください。
本記事の原文を開いて、そこに掲載されている図版をクリックすると、自分のコンピュータでもすぐに実行して試せるWolfram言語コードが自動的にクリップボードにコピーされるようになっています。
コモンズ証 - 表示 - 非営利 - 継承 4.0 国際 - Creative Commons