こんにちは。見習いエンジニアのwestです。
PDFファイルって、皆さん使いますか?
仕様書、説明書、論文、電子書籍など…
おそらく避けては通れないファイルフォーマットだと思います。
そんな身近なPDFですが、内部の構造はどのようになっているのか?そもそも中身って見られるのか?
案外知らないものです。私も知りませんでした。
今回はそんなPDFの構造を、実践を交えて簡単にご紹介します。
PDFの基本的な構造を知っておくと、物知りになれますし、PDFを処理するソフトを作るときなどに役立つはずです。
踏み込むとかなりディープになってしまうので、あくまで基本構造の理解に必要な内容のみピックアップします。
目次
- PDFファイルの基本的な構造
- PDFファイルを構成する4セクション
- PDFファイルの本体 = オブジェクトのグラフ
- PDFファイルの中身をテキストエディタ+フリーソフトで見てみる
- PDFファイルをテキストエディタ+フリーソフトで自作してみる
PDFファイルの基本的な構造
PDFファイルを構成する4セクション
PDFファイルは、大きく分けて4つのセクションから成り立ちます。
任意のPDFファイルをメモ帳などのテキストエディタで開くと、一部文字化けしますがこの構造を確認できます。
PDFファイルの上から順に、1~4のセクションが書かれています。
1. ヘッダ / File Header
1行目にPDFのバージョンが指定されています。
2行目はバイナリーデータで、PDFファイルがバイナリファイルとして認識されるために記述します。
テキストエディタでは文字化けして表示されます。
%PDF-1.6
%����
2. 本体 / File Body
その名の通り、ファイルの本体です。
オブジェクトという基礎単位の並びで構成されています。
ページコンテンツやグラフィックスコンテンツなどが、それぞれオブジェクトとして記述されています。
1 0 obj
<<
/Kids [2 0 R]
/Count 1
/Type /Pages
>>
endobj
2 0 obj
<<
/Parent 1 0 R
/Resources 3 0 R
/MediaBox [0 0 612 792]
/Contents [4 0 R]
/Type /Page
>>
endobj
(以下略)
3. 相互参照テーブル / Corss-Reference Table
ファイル内の各オブジェクトの位置を一覧化したものです。
この相互参照テーブルがあるおかげで、PDFファイルではランダムアクセス※が可能です。
※ランダムアクセス
先頭から順にアクセスするのでなく、すぐに目的のページや位置にアクセスすること。
例えばPDFファイルの15ページ目を読みに行くとき、1~14ページを全て読み込んでから15ページ目を読み込むのでなく、すぐに15ページ目のみを読みに行ける。
無駄な読み込み処理が省かれるため、処理が速くなる。
xref
0 6
0000000000 65535 f
0000000015 00000 n
0000000074 00000 n
0000000182 00000 n
0000000281 00000 n
0000000399 00000 n
4. トレーラ / File Trailer
特殊なオブジェクトを読み取るためのものです。
相互参照テーブルの開始位置や、ファイル内に格納されたメタデータ※の位置を保持します。
ファイルの最終行を示す%%EOFもここに記載されます。
※メタデータ
ファイルの情報が書かれているデータ。
タイトル、作成者、作成日時、変更日時などが記載されている。
trailer
<<
/Root 5 0 R
/Size 6
>>
startxref
449
%%EOF
PDFファイルの本体 = オブジェクトのグラフ
PDFファイルは、オブジェクトという基礎単位からなる有向グラフで形作られています。
ここで言うグラフとは、円グラフや棒グラフではなく、グラフ理論で出てくるようなグラフです。
PDFファイルの場合、ノードがオブジェクト、リンクが間接参照に相当します。
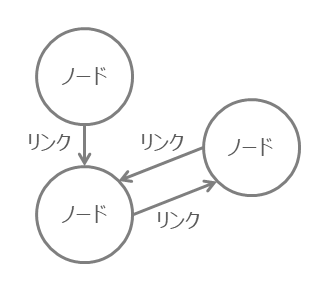
オブジェクト
基本的なオブジェクトには、以下の5種類があります。
- 整数・実数
- 文字列
- 名前
- ブーリアン値
- nullオブジェクト
また、以下3つの複合オブジェクトもあります。
- 配列:他のオブジェクトを複数格納した、順序付きコレクション
- 辞書:名前とオブジェクトの対応付けをする、順序なしコレクション
- ストリーム:バイナリデータとともにデータの長さや圧縮パラメータなどを格納した辞書のセット
間接参照
間接参照によって、あるオブジェクトから他のオブジェクトへのリンクを作成できます。
例えば6 0 Rと書くと、オブジェクト6への間接参照を示します。
6はオブジェクト番号、0は世代番号(大抵の場合0、説明割愛)、Rは間接参照を意味するキーワードです。
これを踏まえて、改めてPDFファイルの本体セクション全体を見てみましょう。
1 0 obj
<<
/Kids [2 0 R]
/Count 1
/Type /Pages
>>
endobj
2 0 obj
<<
/Parent 1 0 R
/Resources 3 0 R
/MediaBox [0 0 612 792]
/Contents [4 0 R]
/Type /Page
>>
endobj
3 0 obj
<<
/Font
<<
/F0
<<
/BaseFont /Times-Italic
/Subtype /Type1
/Type /Font
>>
>>
>>
endobj
4 0 obj
<<
/Length 65
>>
stream
1. 0. 0. 1. 50. 700. cm
BT
/F0 36. Tf
(Hello, World!) Tj
ET
endstream
endobj
5 0 obj
<<
/Pages 1 0 R
/Type /Catalog
>>
endobj
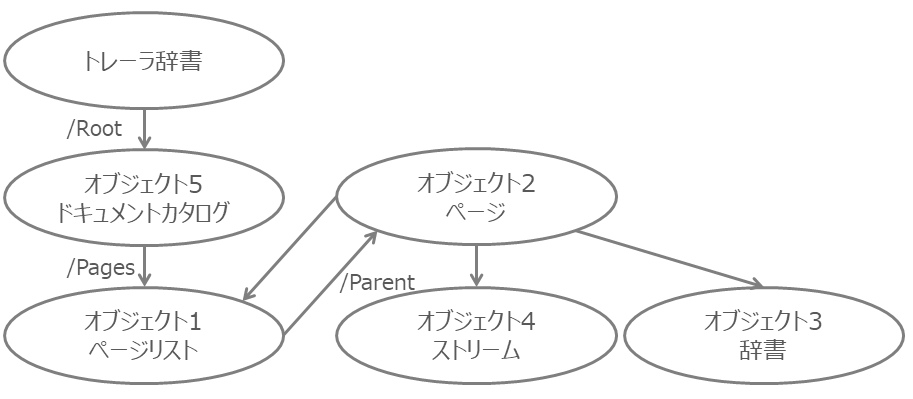
例えば、オブジェクト1:1 0 obj の部分に、/Kids [2 0 R]と書かれています。
このことから、オブジェクト1からオブジェクト2への参照があると分かります。
今回の場合、参照先オブジェクト2はKids(子オブジェクト)、オブジェクト1はParent(親オブジェクト)です。
他のオブジェクトについても、同じように構造をたどって行けるはずです。
このPDFファイルをグラフで図示すると、下図のようになります。(用語はあまり気にしないでください)
PDFファイルの中身をテキストエディタ+フリーソフトで見てみる
基本的な構造がわかったところで、実際にPDFファイルをテキストエディタで見てみましょう。
適当なPDFファイルをVisual Studio Codeで開いてみます。
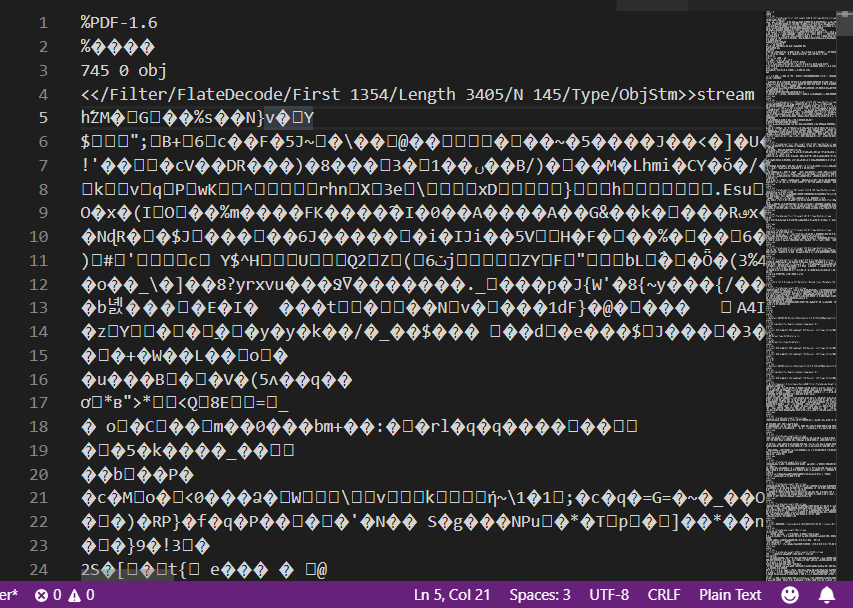
…つらい。
文字化けが激しいですが、これはストリームオブジェクトが圧縮されているためです。
ストリームには、大きなサイズのバイトデータを格納できて、大抵そのバイトデータは圧縮されています。
現にストリーム以外の、1行目のPDFバージョンやobjなどは読めますよね。
このストリームを読むには、気合い…ではなくフリーソフトを活用しましょう。
PDFtkという、コマンドラインからPDFを編集できる高機能なフリーソフトを使います。
ダウンロードページでは"Windows 8まで利用可"となっていますが、Windows10でも利用できました。
PDFtkをインストールして、コマンドプロンプトでこちらのコマンドを実行すると、圧縮データが展開されて読めるようになります。
pdftk 元のファイル.pdf output 書き出すファイル.pdf uncompress
早速先ほどのファイルにこのコマンドを実行すると、

ストリームが展開されたファイルができました!
ちなみに、PDF Stream Dumperというフリーソフトを使うと、より簡単に中身を確認できます。
こちらはGUIツールで、対象PDFファイルを開くだけで中身(オブジェクト同士の関連、圧縮されたストリームの展開など)をわかりやすく表示してくれます。
ただ残念なのは、PDF Stream DumperはWindows7までにしか対応していないことです。
実際にWindows10で試してみましたが、インストールに失敗しました。
PDFファイルをテキストエディタ+フリーソフトで自作してみる
ここまで、既にあるPDFファイルの中身を見てきましたが、自分でもPDFファイルを作ることができます。
試しに"Hello, World!"が記載されている、ごく簡単なPDFファイルを作ってみましょう。
まずメモ帳などのテキストエディタで、以下のように書いてみましょう。
前述の4セクション(ヘッダ、本体、相互参照テーブル、トレーラ)が含まれていることが分かると思います。
書けたら、ファイル名"helloworld-source.pdf"、文字コード"UTF-8"で保存します。
%PDF-1.6
1 0 obj
<<
/Type /Pages
/Count 1
/Kids [2 0 R]
>>
endobj
2 0 obj
<<
/Type /Page
/MediaBox [0 0 612 792]
/Resources 3 0 R
/Parent 1 0 R
/Contents [4 0 R]
>>
endobj
3 0 obj
<<
/Font
<<
/F0
<<
/Type /Font
/BaseFont /Times-Italic
/Subtype /Type1
>>
>>
>>
endobj
4 0 obj
<<
>>
stream
1. 0. 0. 1. 50. 700. cm
BT
/F0 36. Tf
(Hello, World!) Tj
ET
endstream
endobj
5 0 obj
<<
/Type /Catalog
/Pages 1 0 R
>>
endobj xref
0 6
trailer
<<
/Size 6
/Root 5 0 R
>>
startxref
0
%%EOF
大まかな構造はできていますが、実はまだこれでは不十分です。
Adobe Reader等の寛容なPDFリーダーではこのファイルを開けてしまうのですが、他のビューワーでの挙動は保証されておらず、完全なPDFではありません。
PDFファイルをテキストエディタで見ると、ヘッダー2行目に文字化けしているバイナリーデータがありましたね。
ファイルがバイナリファイルとして認識されるために、このデータを付加する必要があります。
他にも、ストリームの長さなどの情報も必要です。
これらを自力で補うのは難しいので、足りない情報を補完するために、前述のPDFtkを使います。
コマンドプロンプトで
pdftk helloworld-source.pdf output helloworld.pdf
を実行すると、PDFtkにより情報が補完されたhelloworld.pdfが生成されます。
helloworld.pdfをPDFビューアーで開くと…
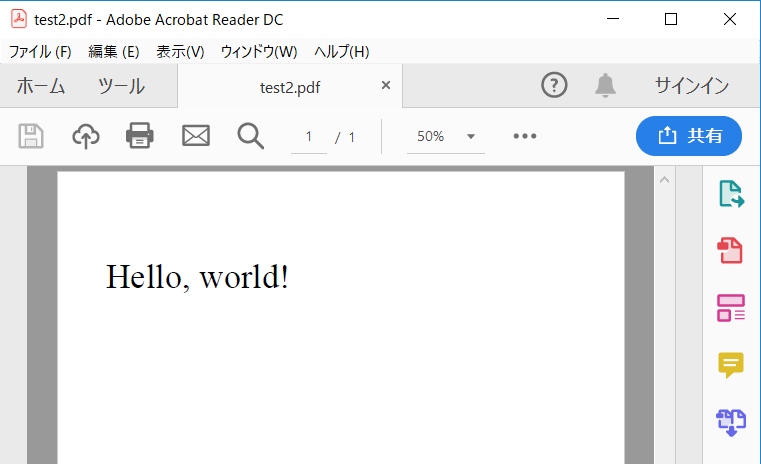
できました!これで完成です。
まとめ
PDFは、多機能ゆえに少々ややこしいファイルフォーマットです。
しかし、基本的なファイル構造:
- 4セクション(ヘッダ、本体、相互参照テーブル、トレーラ)で成り立っていること
- オブジェクトを間接参照で結んだグラフで形作られていること
を頭の片隅に置いて、便利ツールを活用すれば、大まかに中身を理解することができます。
PDFtk等のフリーソフトも活用しながら、PDFファイルと仲良くしましょう。
参考文献
- 『PDF構造解説』John Whitington著、村上雅章 訳、O'REILLY
…更に詳しくPDF仕様を知りたい方におすすめです。 - Portable document format - Part1:PDF 1.7