こんにちは、BPSの福岡拠点として一緒にお仕事させて頂いてます、株式会社ウイングドアの坂本です。
日頃よくお客様から「OCR(光学的文字認識)をつかって画像から文字を抽出して〜(うんぬんかんぬん)」
という要望を頂きます。
以前は少しハードルが高く感じていましたが最近はいくつかのサービスでOCRのAPIを提供されており、
大分手を出しやすくなったのではないでしょうか?
先日、RailsでそのGoogle CloudのVision APIを利用した検証用デモを作成しました。
意外とRubyの記事は少なかったため少しでも役に立てばと実装例と使ってみた所感をご紹介したいと思います。
前提
- デモ作成の目的はOCRで以下の要件が満たせそうか検証すること。
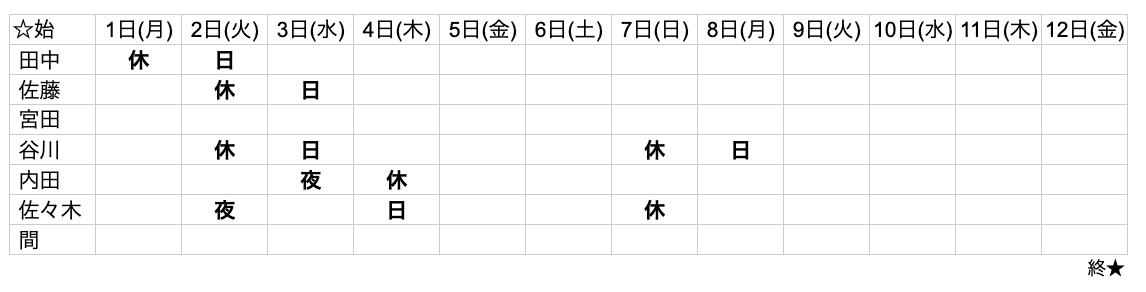
そのため以下の要件を意識しながらデモを作成しています。- 日本語を含む手書きの表を読み取れること(今回はシフト表を想定)
- 表の中身の項目は複数ある文字パターンの1つが入る
- 文字パターンは表毎に変動
- 文字数は今回考慮しない
- 表形式に出力できること
- あくまで「検証用」ということでレイアウトはほとんど調整出来ていません。
- この検証は2019年5月の実装時点のものです。パラメータなどの詳細は公式ドキュメントを参照下さい。
作ったもの
1. 入力画面
2. 画像アップロード後
アップロードし、APIの結果が取得できると上から以下の項目が表示されます
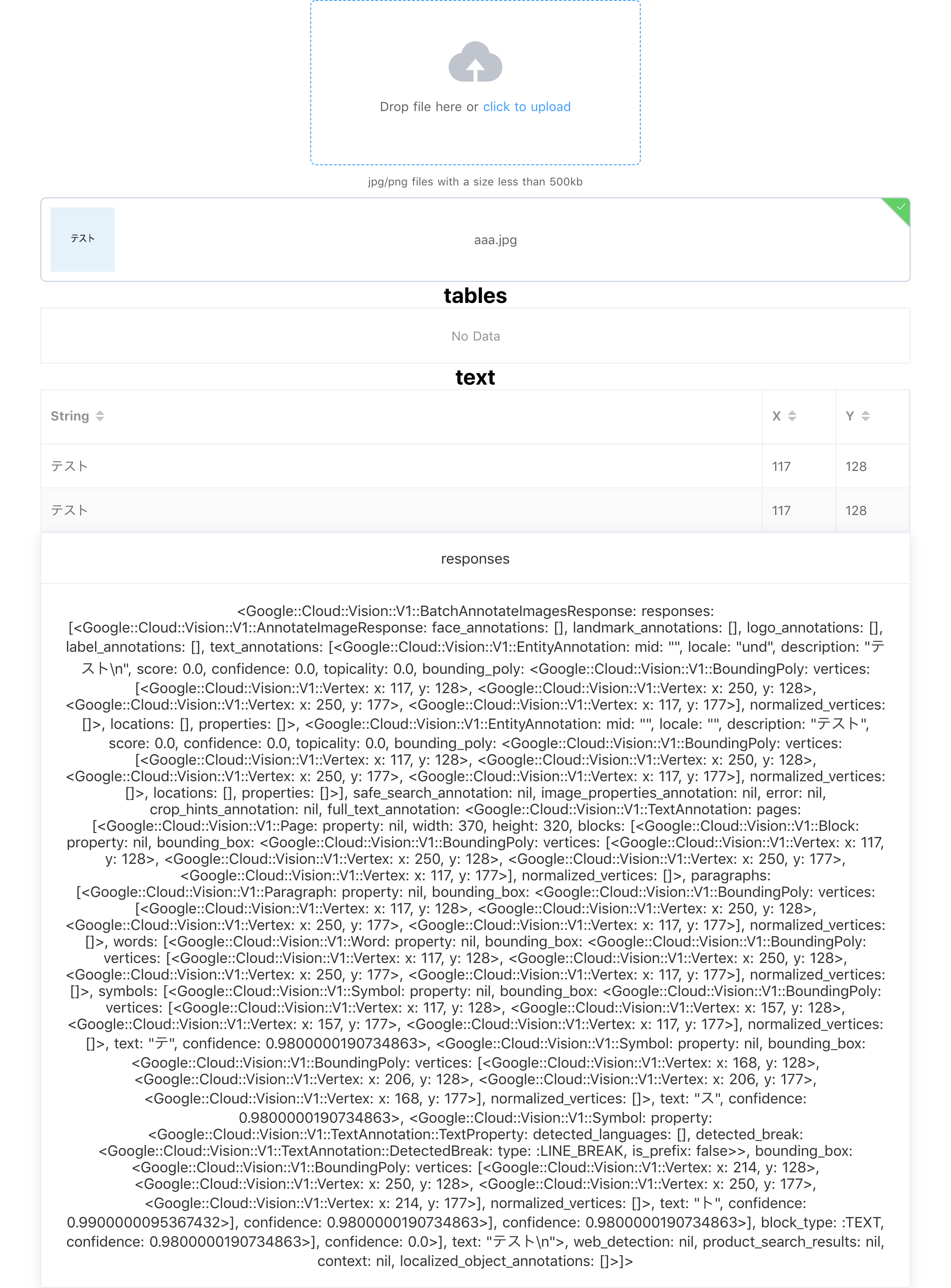
3. アップロードの結果
- 結果を表形式に成形したもの
※上記の画像は読み取り用の記号がないため「No Data」と表示されています - APIから帰ってきた文字とその左上の座標(x, y)
- 結果のオブジェクトをベタで表示したもの
to_sの内容をそのまま表示しています
実装
1. アカウントの設定
GCPを利用できるようにGoogleや環境変数などの設定を行います。
- クイックスタート: クライアント ライブラリの使用 | Cloud Vision API | Google Cloud
- Vision API クライアント ライブラリ | Cloud Vision API ドキュメント | Google Cloud -- Ruby向け(一部クイックスタートと重複)
gem追加
Google Cloud Vision APIのgemを追加します。
# Gemfile
gem 'google-cloud-vision'
3. フロントを作成
今回はNuxt.jsでお手軽に画面を作成。 詳細は割愛します。
4. API作成
画像がアップロードされた時のAPIを作成します。
アップロードされた画像を取得し、Cloud Visionの「ドキュメント テキスト検出」を呼び出しています。
# app/controllers/google_api/vision_controller.rb
module GoogleApi
class VisionController < ApplicationController
# Imports the Google Cloud client library
require 'google/cloud/vision'
def upload
images = []
upload_file = params[:file]
if upload_file != nil
images << upload_file.path
end
responses = send_images(images)
results = format_result(responses)
render json: {results: results, responses: responses.to_s}
rescue => e
render status: 500, json: {status: 'ERROR', result: e.to_s}
end
def send_images(images)
image_annotator_client = Google::Cloud::Vision::ImageAnnotator.new
image_annotator_client.document_text_detection images: images, image_context: {language_hints: [:ja, :en]}
end
def format_result
# 以下略
end
end
アップロードされたファイルをメソッドsend_imagesに渡して、メソッドformat_resultでテーブルで表示できるように成形してjson形式で返すようにしています。
responsesを渡してるのはデバッグ用のおまけです。
送信の処理はこれだけ。
def send_images(images)
image_annotator_client = Google::Cloud::Vision::ImageAnnotator.new
image_annotator_client.document_text_detection images: images, image_context: {language_hints: [:ja, :en]}
end
image_annotator_client.document_text_detection images: images だけドキュメント テキスト検出APIの呼び出しが可能ですが、 language_hintsで日本語を指定しました。
language_hintsなどのオプションの指定は、Rubyのドキュメントが見つからず他の言語のドキュメントやソースコードを見比べたりして辿りつきました。
document_text_detectionをtext_detectionに入れ替えれば「テキスト検出」を呼び出すようにもできます。
検証結果
入力した画像と、表部分の出力結果は以下のような形になりました
1. アルファベット 1文字
真ん中あたりが空白。 大分文字を取りこぼしているようです。
入力画像
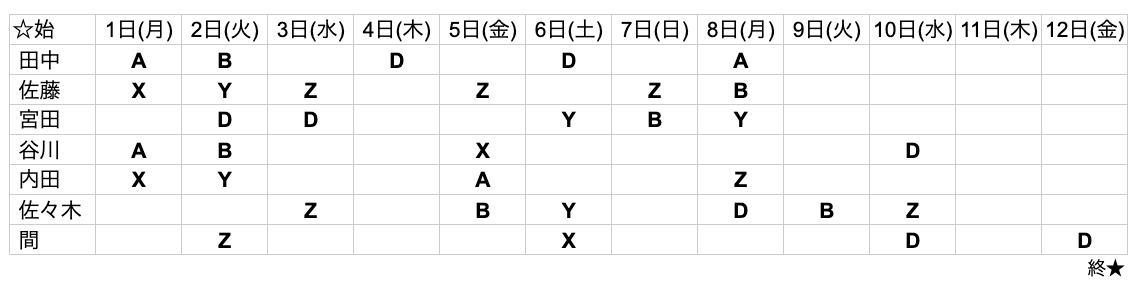
出力結果(表)

2. アルファベット 2文字
なぜかアルファベット1文字の時よりずれた結果になりました。
入力画像
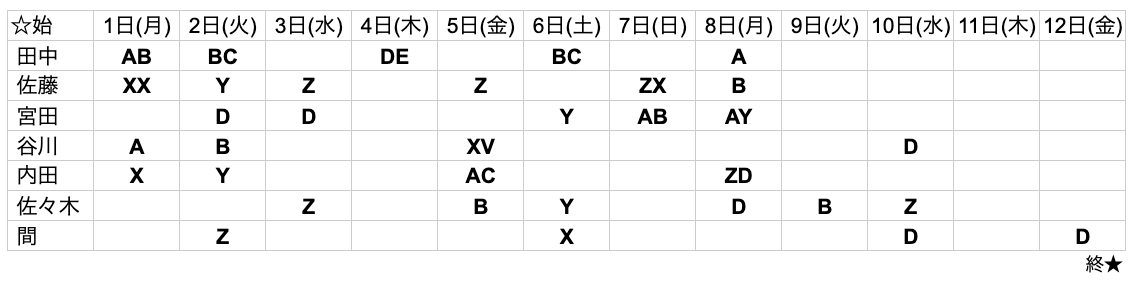
出力結果(表)
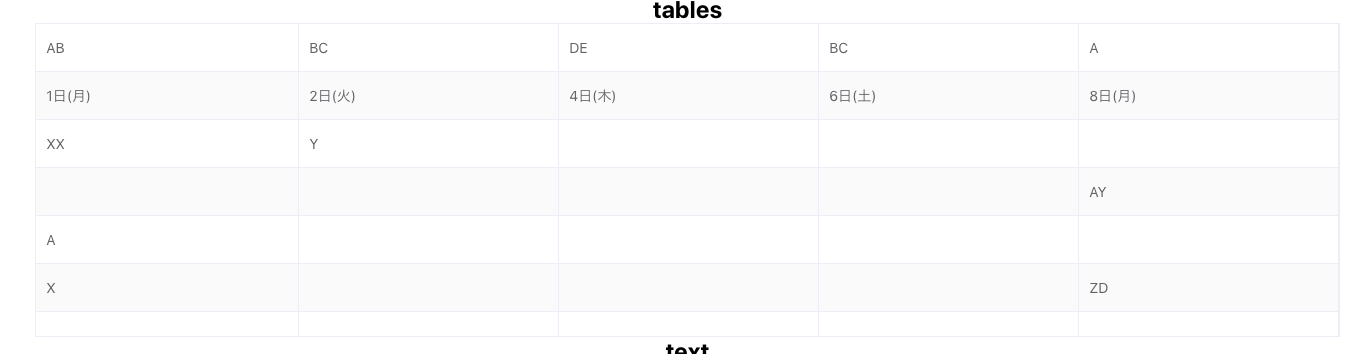
3. 漢字 1文字
1行消えてる上、複数の文字が連結されています。
入力画像
出力結果(表)

4. 日本語 2文字
1行消えていますが、表の中身きちんと取り込めています。
1文字の時のように隣接するマスとの連結もありません。
入力画像

出力結果(表)

所感
ほとんどの結果で中身が空白の行のラベルを取りこぼしていたり、余分な文字がついていたりしました。
こちらは表出力のロジックも含めて修正が必要そうです。
他にもテストを繰り返して(正確に数えていないのですが検証パターン数が20 ~ 50程度だったと思います)
以下のような知見を得ました。
- 文字数が多いほうが正しい値が検出されやすい
language_hintでen(英語)を優先度を高くすると罫線が「、|、」、Tなどとして検出される場合がある- アルファベット
検出されやすい?: ABD、XYZ、H
検出されにくい: C、E - 記号
- ○:
0、Oと混ざる。隣接するマスとまとめられる - ●: ほぼ取得不可。 「
・」 として検出されることも - □■▲△: 取得不可
- ☆、★: 日本語と隣接しているとほぼ取れる
- 時刻の形式「
12:00」などよくあるパターンだと正しく取り込まれる
- ○:
- 日本語
- 1文字より2文字以上の場合が読み取りやすい
まとめ
英数字や記号の方が精度が高いと思っていましたが、他の文字と認識されることが多く精度が確保できないのが意外でした。
特に表形式ですと罫線が認識されてしまい、除外したりするのがとても難しかったです。逆に、難しいだろうと思っていた日本語の方が精度が高く、2文字以上になるとほとんど読み取ってくれたのには驚きました。
機械学習でカバーしてくれるんでしょうか?
表だともう少し工夫が必要そうですが、文章だったらますます精度が高くなって使いやすそうです。
他にも顔検出やラベル検出など興味深い項目がたくさんありますので、
これからも機会を見つけてぜひ触ってみたいと思います!

株式会社ウイングドアでは、Ruby on RailsやPHPを活用したwebサービス、webサイト制作を中心に、
スマホアプリや業務系システムなど様々なシステム開発を承っています。