複雑なファイル処理をサーバーレスでシンプルにする方法(翻訳)
はじめに
複雑なファイル処理は、サーバーレスソリューションを使えば手軽に行えますが、アップロードしたファイルに対してさまざまな操作を行う場合は、統合しやすい堅牢なシステムも必要になってきます。複雑なサービスを作成したければ、いくつかのファイル処理ツールや手法も知っておく必要があります。本記事では、日々大量のファイルを処理しているPlaybookを見ていくことにしましょう。ボーナスとして、Google Cloud Platform1のサーバーレスアプリの例も紹介します。このアプリは、ファイルの非同期処理と結果を保存するための小さなフレームワークを備えています。
🔗 複雑なファイル処理とは
複雑なファイル処理の例を説明してみましょう。
Benはお気に入りのブラウザを起動して、写真を共有するあなたのWebアプリを開きます。Benが愛犬の写真をアップロードすると、小さなサムネイル画像、GPS位置情報、画像の寸法、AI生成による説明文が表示されます。
本質的には、これがファイル処理の実際です。EXIF情報やファイル容量を表示するようなシンプルな処理もあれば、画像認識、サイズ変更、色調整、その他AIにヒントを得たような想像を絶する高度な操作もあります。
しかし、そうした複雑なサービスを構築するとなれば、何らかのファイル処理ツールや手法を使いこなせるように準備しておく必要があります。
さらに、ユーザーが満足し、今後も満足し続けてくれるレベルの仕上がりにしたいでしょう。これが可能になるのは、高速・安価・拡張可能なソリューションが使える場合なので、そのためのインフラストラクチャを徹底的に検討しておく価値があります。
ファイル処理をWebアプリケーションの目玉機能に据えて販売する計画があるなら、ファイル処理を高速かつ安定させておくことが非常に重要となります。
現代は、最新のテクノロジー(NoSQLデータベースやリトライ可能なキュー、コードの非同期実行など)を元にして独自のシステムを構築することが可能です。あらゆるタスクに対応できるソリューションも多数あるので、必要なのはそれらを1個のアプリに接続することだけです。
サーバーレス関数が救いの神となるのです!
そうしたサーバーレス関数には、さまざまなAPIやテクノロジーが共通のインターフェイス内にカプセル化されています。この方法によって開発速度が向上し、アプリ内で多数のサービスを連携させようとするときにイライラの元となる露骨なミスを防げるようになります。
🔗 サーバーレスのセールスポイント
まずはサーバーレスの嬉しい点からお話ししましょう。
サーバーレスソリューションでは、「認証」「認可」「サーバーの自動スケーリング」といったあらゆる周辺ロジックを気にする必要がないので、アプリの実際のコードがシンプルになります。そのおかげで、実現したい機能の重要な部分に専念できるようになります。つまり、関数コードを書いたら、その関数コードを実行するタイミングや方法をサーバーレスプロバイダに指示することになります。
この手法ではサーバーを実装していないので、当然ながらサーバーの待機時間に課金される必要もありません。課金が必要なのは、コードが実際に実行されるときに割り当てられるリソースに対してだけです。
この方法は課金が使用量に完全に依存するので、専用サーバーによるソリューションよりも安価になることが見込まれます。
さらに、サーバーレスソリューションは、プロバイダの既存のインフラストラクチャに手軽に組み込めます。
たとえば、AWS S3からのイベントをAWS Lambdaで受信できます。自分のS3ストレージにファイルがアップロードされると、その直後にAWS Lambdaが自分たちの関数を呼び出します。言い換えれば、イベントの配信はクラウドプロバイダが行うので、開発者が配信の面倒を見る必要はありません。
🔗 事例: Playbookのファイル処理サービスを拡張・改善する
背景情報の説明: Playbookは、アップロードされたファイルに対して、AIベースの画像認識やメタデータ解析、ファイル変換、サムネイル生成といったさまざまな処理を実行するサービスです。
Evil Martiansは、Playbookのチームが既存のファイル処理サービスを拡張・強化するのを支援いたしましたので、その中で得た知見の一部を皆さんと共有できる状態にあります。
このファイル処理システムは、GCP(Google Cloud Platform)で実行されるサーバーレスアプリケーションとしてデプロイされます。
ファイルがアップロードされるたびに処理フローがトリガーされ、ファイルに対して何らかの処理を行ってから結果を保存します。後でこれらの結果を取得してアプリケーションで利用することになります。
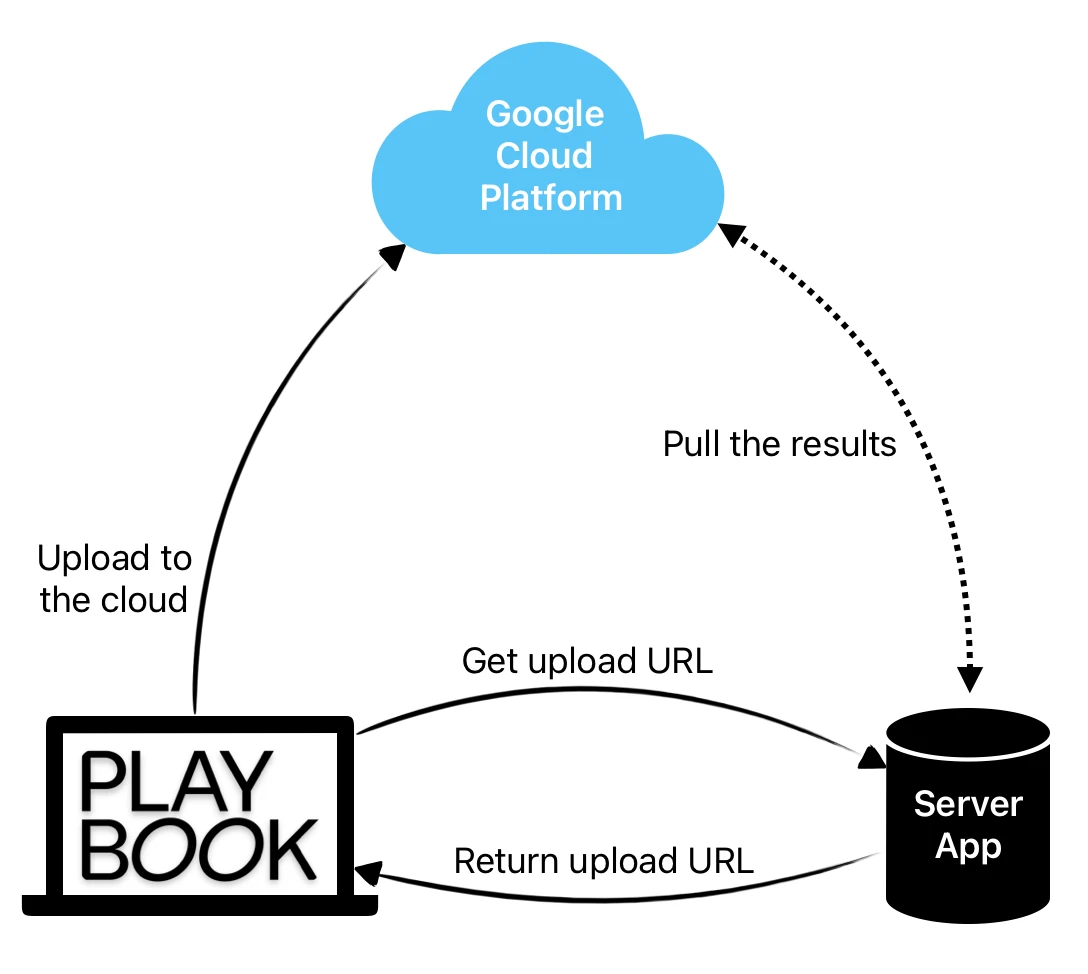
処理のフローは以下のようになります。
- クライアントはWebサーバーに一意のGCS(Google Cloud Storage)アップロードURLを生成して署名するようリクエストします。
- クライアントはGCSへのアップロードをシーケンシャルに実行します。
- クラウド関数がファイルを処理します。
- スケジューリングされたワーカーがGCPから処理結果をフェッチします。
この処理をスムーズに行うため、スケーラブルで便利なファイル処理ソリューションを提供するちょっとしたフレームワークをGCP上で構築しました。ファイルを1件アップロードするたびに、処理のパイプラインがトリガーされます。
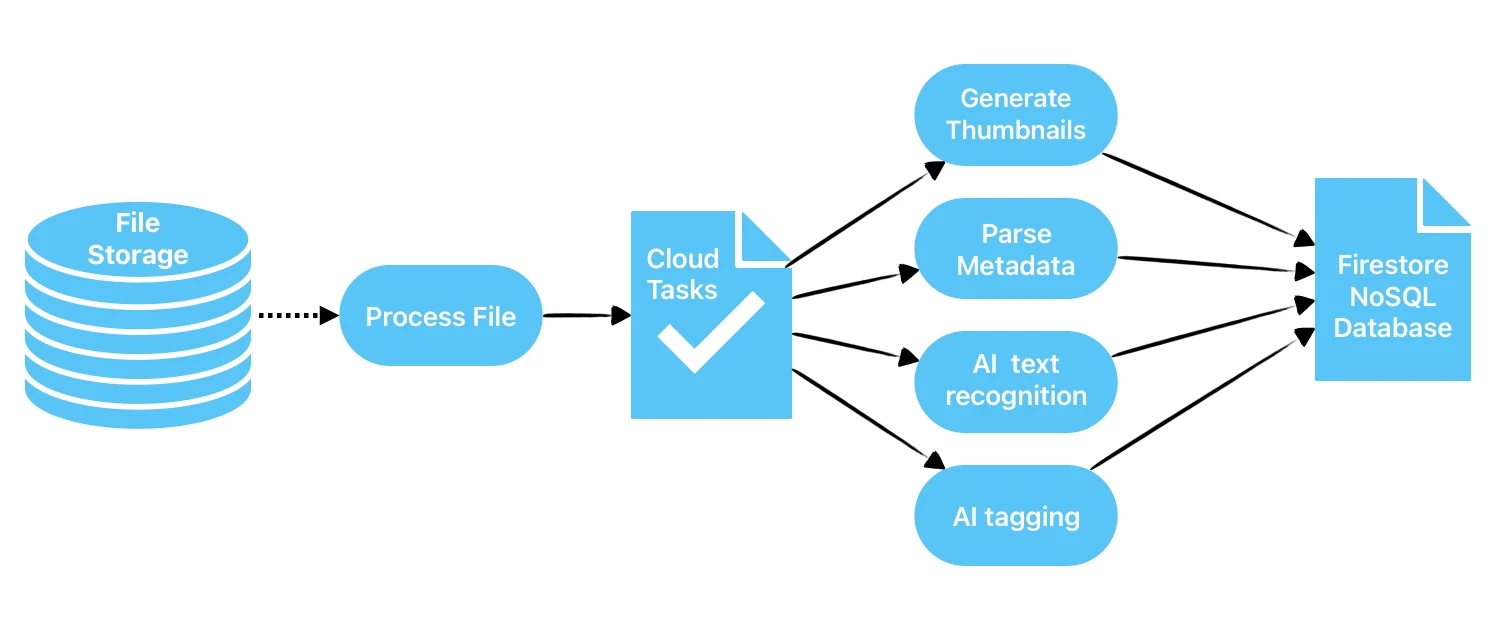
この仕組みは以下のようになります。
- ファイルがアップロードされるたびにクラウドの関数がトリガーされ、Cloud Tasksサービスで非同期処理用のタスクを作成します。
-
Cloud Tasksサービスが処理用の関数を呼び出します。予期しないエラーが発生した場合は、Cloud Tasksが関数呼び出しを再試行します。
-
Cloud Functionsは、「テキスト生成」「タグ生成」「サムネイル画像生成」「NSFW(職場や学校などでの閲覧に適していないコンテンツ)検出」など多数のタスクを実行します。
-
関数は、パイプライン内で別の関数をトリガーすることもあれば、処理結果をCloud Firestore(NoSQLクラウドデータベース)に保存することもあります。
処理が完了したら、結果の処理に取りかかります。メインアプリケーションはSidekiqワーカー(クラウド関数呼び出し経由で結果を取得する)を実行し、結果を処理するSidekiqワーカーをキューに入れてから、処理した結果を別のクラウド関数呼び出しでクリアします。
一部の関数がファイルの処理をまだ終えていない場合は、次のワーカーが実行されるときにその結果を取得します。個別の処理結果は独立かつ完全なので、処理とクリーンアップは既に安全に行えます。
Playbookは、Cloud Functionsでファイル処理を実行することで、メインアプリケーションのリソースを節約し、処理リソースの管理やスケーリングをGCPに任せられるようになりました。
このように分割したことで処理のロジックをカプセル化可能になり、アプリケーションとファイル処理システム間の癒着を軽減できるようになりました。
🔗 お次はコード
ここでは小さなサーバーレスアプリケーションを例に使い、2つの関数を書くことにします。
1つ目はストレージ上に新規作成されたアセットを処理する関数、2つ目はそれらを処理する関数です。
完全なサンプルリポジトリについては以下をご覧ください。

この処理のために、ささやかなフレームワークを書くことにします。このフレームワークは、Google Cloud Tasks APIとFirestoreデータベースを用いて処理のジョブ実行と結果の保存を行います。こうすることでソリューションがスケールするようになり、多数の処理関数を非同期に呼び出せるよういになります。
🔗 セットアップ
GCPで利用するAPIを有効にしておく必要があります。そのために、空のプロジェクトのGoogle Cloud Consoleで以下を実行します。
- ストレージバケットを作成する
(アップロードしたファイルはここに保存される) - Cloud Functions APIを有効にする
(今回利用する主なAPIの1つ) - Cloud Tasks APIを有効にする
(このAPIは、非同期フレームワークで処理関数をトリガーするのに使う) - Cloud Deployment Manager APIを有効にする
(このAPIはコードのデプロイに使う) - メインのサービスアカウントで使うJSONキーを生成する
(このcredentialはデプロイで必要)
この設定はIAM & Admin -> Service Accountsにある
後でデプロイに失敗した場合は、正しいパーミッションを付与するか、APIをさらに有効にすることで簡単に修正できます。
🔗 設定
このserverlessフレームワークを、GCPとTypeScriptと共に使うために設定しましょう。
secretは利便性とセキュリティのため、.envファイルに保存することにします。
Google Cloud Functionsが認識できるのははNodeJSランタイムだけなので、コードをJavaScriptに変換する特殊なserverless-plugin-typescriptプラグインを使う必要があります。
# serverless.yml
service: file-processing
useDotenv: true
frameworkVersion: "3"
plugins:
- serverless-google-cloudfunctions
- serverless-plugin-typescript
provider:
name: google
runtime: nodejs18
region: us-central1
project: my-project-0172635 # ここは実際のプロジェクトIDに差し替えること
credentials: ${env:GCLOUD_CREDENTIALS}
environment:
BUCKET: ${env:BUCKET}
FIRESTORE_DATABASE: ${env:FIRESTORE_DATABASE}
GCLOUD_SERVICE_ACCOUNT_EMAIL: ${env:GCLOUD_SERVICE_ACCOUNT_EMAIL}
GCLOUD_TASKS_QUEUE: ${env:GCLOUD_TASKS_QUEUE}
PROJECT_ID: ${self:provider.project}
REGION: ${self:provider.region}
STAGE: ${opt:stage}
functions:
# イベントでトリガーされる関数
# 関数はファイルがアップロードに成功するとトリガーされる
process_file:
handler: processFile
events:
- event:
eventType: google.storage.object.finalize
resource: projects/${self:provider.project}/buckets/${env:BUCKET}
# HTTPリクエストでトリガーされる関数
# 関数はGoogle Tasksからトリガーされる
parse_metadata:
handler: parseMetadata
events:
- http: parse_metadata
🔗 クラウド関数
それでは2つのクラウド関数を実装しましょう。
processFile関数は処理フローを開始します。
parseMetadata関数は処理を実行します。
// src/processFile.ts
import enqueue from './lib/enqueue';
interface EventFunction {
(data: Record<string, any>, context: any, callback: Function): Promise<void>;
}
export const processFile: EventFunction =
async (data: Record<string, any>, _context: any, callback: Function) => {
const { name } = data;
// parse_metadata関数への非同期呼び出しを行う
await enqueue('parse_metadata', { name });
callback(); // success
};
このparseMetadata関数ではさまざまな処理ステップが存在する可能性があることを前提としており、いくつかの処理をパラレルに実行してから、結果に応じてさらに処理を実行するために別のクラウド関数をエンキューします。
しかし、この小さなサンプルコードでは「ファイルのメタデータを解析する」というシンプルな処理だけを追加してみましょう。
// src/parseMetadata.ts
import { Request, Response } from 'express'; // 型のためにここでのみ使う
import * as processors from './processors';
interface HttpFunction {
(request: Request, response: Response): Promise<void>;
}
export const parseMetadata: HttpFunction =
async (request, response) => {
const { name } = request.body;
// プロセッサをパラレル実行する
const result = await processors.call({
name,
processors: [processors.metadataParser],
tag: 'metadata',
});
response.status(200).send(result);
return Promise.resolve();
};
🔗 フレームワーク
関数を非同期呼び出し可能にして、その実行結果をどこかに保存可能にするために、ここでは小さなフレームワークを構築することにします。
このフレームワークではパイプフローとパラレルフローを両方サポートするので、任意のパイプラインを作成可能になります。
このパイプフローは、クラウド関数から別のクラウド関数への呼び出しをエンキューする形で実装します。
このパラレルフローでは、コンカレントに実行される非同期関数の結果をPromiseで取得します。
このenqueue関数は、Cloud Tasks APIを用いてCloud Functionsへの非同期呼び出しを行い、キャッチされない例外を処理します(この場合は呼び出しを再試行します)。これは、コードと無関係なハプニング(例: クラウド関数から他のサービスを呼び出したときに発生した、キャッチされないネットワーク問題)の解決に有用です。
// src/lib/enqueue.ts
import { CloudTasksClient } from '@google-cloud/tasks';
const client = new CloudTasksClient();
// ... CLOUD_FUNCTIONS_URL、QUEUE、GCLOUD_SERVICE_ACCOUNT_EMAILの定義
export default function enqueue(functionName: string, args: any) {
const url = CLOUD_FUNCTIONS_URL + functionName;
const message = {
httpRequest: {
httpMethod: 1, // "POST"
url,
oidcToken: {
serviceAccountEmail: GCLOUD_SERVICE_ACCOUNT_EMAIL,
},
headers: {
'Content-Type': 'application/json',
},
body: Buffer.from(JSON.stringify(args)).toString('base64'),
},
};
return client.createTask({ parent: QUEUE, task: message });
}
このprocessors.call関数は、すべてのステップをPromiseでパラレル実行し、結果をFirestoreデータベースに保存します。この結果は別のクラウド関数にエンキューするときにも利用可能です。
import { Firestore } from '@google-cloud/firestore';
// FIRESTORE_COLLECTIONとSTAGEの定義
const firestore = new Firestore({
projectId: PROJECT_ID,
timestampsInSnapshots: true,
ignoreUndefinedProperties: true,
});
const collection = firestore.collection(FIRESTORE_COLLECTION);
export interface ProcessorFunc {
(file: StorageFile): Promise<any>;
}
interface ProcessorOptions {
name: string;
processors: Array<ProcessorFunc>;
tag: string;
}
export async function call({ name, processors, tag }: ProcessorOptions): Promise<any> {
const file = await getGCSFile(name);
let attributes: any = {};
await Promise.all(
processors.map(async (process) => {
const result = await process(file);
attributes = {
...attributes,
...result,
};
})
);
if (Object.keys(attributes).length === 0) {
return {};
}
const res = await collection.add({
tag,
name,
createdAt: Date.now(),
environment: STAGE,
attributes,
});
return attributes;
}
話を簡単にするため、getGCSFileのコードは省略しました。実装を確認したい場合はソースコードを参照できます。
保存した結果は、後でフェッチしてアプリで利用できます(このタスクには、スケジューリングされたSidekiqワーカーを利用できます)。この方法によって、結果を一括で取得しつつデータベースの負荷を制御できるようになります。
解析はmetadataParser関数で行います。この関数では、sharpパッケージでファイル(メディアファイルを想定しています)からメタデータを取得します。
import * as path from 'path';
import * as fs from 'fs';
import sharp from 'sharp';
interface Metadata {
width?: number | string;
height?: number | string;
format?: string;
channels?: number | string;
hasAlpha?: boolean;
orientation?: number;
}
export const metadataParser: ProcessorFunc = async function (file): Promise<Metadata> {
// Destination path without nesting.
const destination = `/tmp/${path.parse(file.name).base}`;
try {
await file.download({ destination });
const { width, height, format, channels, hasAlpha, orientation } =
await sharp(destination).metadata();
return {
width,
height,
format,
channels,
hasAlpha,
orientation,
};
} catch (e) {
console.error('Error working with file', e.message);
return {};
} finally {
if (fs.existsSync(destination)) {
fs.unlinkSync(destination);
}
}
};
これは、ファイル処理をサーバーレスとGoogle Cloud Platformで整理する方法のシンプルなコード例です。ここでは、スケーラブルで、極めて高度な処理フローをサポートする処理フレームワークを、基本的なアイデアとして用いています。
🔗 結果
Google Cloud StorageのWebインターフェイスにファイルをアップロードすると、間もなくFirestoreデータベースに以下のレコードが表示されます。
ライブファイル処理のデモ
このファイルは後でフェッチすることも、アプリケーションで処理が終わったら直ちに削除することもできます。処理結果を取得・削除する関数についてはGitHub上のサンプルアプリを参照してください↓。
私たちEvil Martiansは、成長段階のスタートアップ企業をユニコーン企業に飛躍させるためにサポートいたします。開発ツールの構築やオープンソース製品の開発も行っています。ワープの準備が整ったお客様、ぜひフォームまでご相談をお寄せください!
概要
元サイトの許諾を得て翻訳・公開いたします。