Railsスケーリング(2): アムダールの法則で高速化とコンカレンシーの関係を理解する(翻訳)
本記事は、「Railsをスケーリングする」シリーズのパート2です。

Pumaの設定を微調整するときに操作できるパラメータは、以下の2つしかありません。
- プロセス数
- プロセスごとに持てるスレッド数
Railsをスケーリングする」シリーズのパート1では、適切なプロセス数について考察しました。今回は、プロセスごとに持てるスレッド数について見ていきましょう。
🔗 アムダールの法則
アプリケーションには、「順序を保って(serial order)」実行しなければならない部分と、「パラレル化可能(parallelizable)」な部分があるものです。これをざっくりと絵にすると以下のような感じになります。
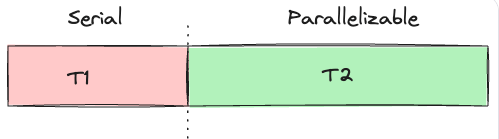
アプリケーションの実行時間のうち、シリアル実行しかできない部分の実行時間をT1、パラレル化可能な部分の実行時間をT2としたとき、それらを強化したものを(ここではプロセス内のスレッドを増加したことを意味する)、それぞれT1'とT2'とします。
T1は実行順序を変えられない、つまりパラレル化できない部分なので、強化後のT1'も時間は短縮されず、同じままです。
T2はパラレル化可能な部分なので、強化後のT2'では時間が短縮されます。
パラレル化完了前(図上)と完了後(図下)の所要時間を図に表すと以下のようになります。
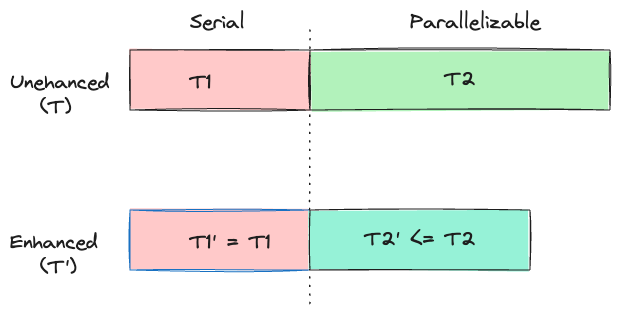
この図からわかるように、パラレル化でT2の部分をどれほど高速化しようとも、シリアル部分T1によって高速化の限度が定まってしまいます。
コンピュータ科学者のジーン・アムダール(Gene Amdahl)が提唱したアムダールの法則は、達成可能な高速化の上限を数学的に与えます。
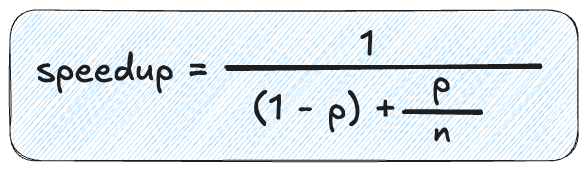
この式がどのようにして生み出されたかを解説する動画も作成しました。
アムダールの法則は、パラレル化によって得られる理論的な高速化は、プログラム内における「順次実行コード」の割合によって直接決まる、つまり順次実行コードの割合が多ければ多いほどパラレル化による高速化が弱まることを示しています。
それでは、アムダールの法則を用いて理想的なスレッド数を決定する方法を見てみましょう。
この場合、パラレル化可能な部分とは、アプリケーションがI/O処理に時間を費やす部分です。
パラレル化不可能な部分とは、アプリケーションがRubyコードを実行するのに費やす時間です。
GVLが存在するため、プロセス内でCPUにアクセスできるスレッドは、常に1つだけであることを思い出しましょう。
次に、アプリの実行時間のうち、I/O処理に費やしている時間が占める割合を把握する必要があります。これは動画で示されているp値になります。
本シリーズの後半では、RailsアプリケーションがI/Oに費やしている時間の割合を計算する方法を紹介する予定です。本記事では、アプリケーションが処理時間の37%をI/Oに費やしている、つまりpの値は0.37と仮定します。
それでは、1スレッド(n=1)の場合にどの程度高速化されるかを計算してみましょう。次にn=2に変更して高速化の値を得、同様にn=15までの高速化の値を記録します。
ここで、全体的な速度向上とスレッド数の関係を示すグラフを描いてみましょう。
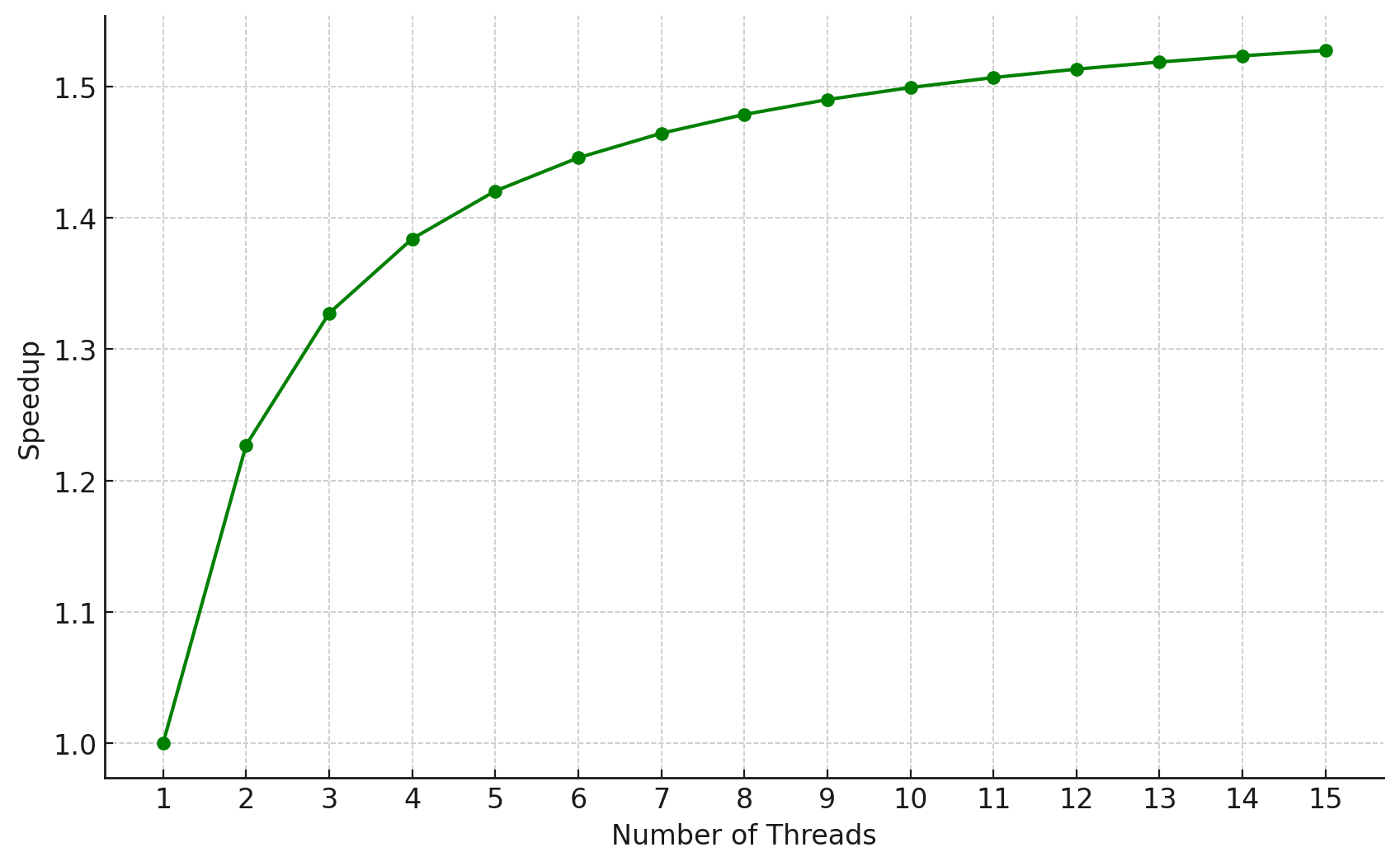
このグラフから、スレッド数を増やすに連れて速度向上が増加しますが、スレッド数の増加に伴って速度向上率が鈍っていることがわかります。これは、シリアル部分の処理時間は一定で、スレッド数の増加の影響を受けないためです。
| スレッド数(N) | 高速化(S) | 直前の結果からの改善率(%) |
|---|---|---|
| 1 | 1.000 | - |
| 2 | 1.227 | 22.7% |
| 3 | 1.366 | 11.3% |
| 4 | 1.456 | 6.6% |
| 5 | 1.518 | 4.2% |
| 6 | 1.562 | 2.9% |
| 7 | 1.594 | 2.0% |
| 8 | 1.619 | 1.6% |
グラフを調べると、4スレッドまではスレッド数の増加によって著しく速度が向上しているように見えますが、それ以上増やしても速度向上の増分ははかばかしくありません。
これはアムダールの法則に基づく理論上の最大値であることを覚えておきましょう。実際には、Rubyのスレッド数を増やすとメモリ使用量とGVL競合が増加し、レイテンシが急上昇する可能性があるため、スレッド数を理論値よりも少なめにしておく必要があります。
スレッド数を増やすと、Pumaが同時に処理できるリクエスト数が増えるのは明らかです。つまり、リクエストの処理待ちの Puma スレッドが増えるため、ロードバランサー層でのリクエストの待機時間が短くなります。
しかし、パート1で説明したように、スレッド数を増やしても処理速度が速くなるとは限らず、GVLを待つ他のスレッドを増やしてしまう結果になるかもしれません。
Webサーバーがレスポンスを敏速に返せないのであれば、リクエストを受け付ける意味はありません。max_threadsの値を小さめにした場合、リクエストはロードバランサー層でキューイングされるので、アプリケーションサーバーの負荷をむやみに増やすよりはマシです。
しかしロードバランサーレベルで待機するリクエスト数が増えれば、リクエストキューにとどまる時間が急増します。この問題を解決する適切な方法は、Pumaプロセスを追加することです。Pumaサーバーのキャパシティを増やすには、スレッド数を増やすよりも、プロセスを追加するのがおすすめです。
以下のミドルウェアは、リクエストキュー時間をトラッキングするのに使えます。なお、このコードはjudoscaleからの引用です。
参考: middleware.rb
なお、リクエストキュー時間(Request Queue Time)はリクエストが処理のために取得されるまでの待機時間を表します。
このミドルウェアは、ロードバランサーがHTTP_REQUEST_STARTヘッダーを追加している場合にのみ動作します(Herokuはこのヘッダーを自動的に追加します)。
このミドルウェアを利用するには、config/application.rbのコンフィグファイルを開いて以下を追加する必要があります。
config.middleware.use RequestQueueTimeMiddleware
本記事でわかりにくい点がありましたら、LinkedIn、Twitter、BigBinaryサイトまでお問い合わせください。私たちは、Railsアプリケーションをスケールさせる方法を誰もが理解できるよう、わかりやすく書くことを目指しています。
概要
元サイトの許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。
参考: アムダールの法則 - Wikipedia