🔗 ChatGPTのしくみとAI理論の根源に迫る:(13/16)ChatGPTは実際にどう動いているのか(翻訳)
人間の言語と、それを生み出す人間の思考プロセスは、いつの時代も、あらゆる事象の中で究極的に複雑なものであるとみなされてきました。そして、人間の脳が持つネットワークを構成しているのが、「わずか」一千億個のニューロン(と100兆個の接続)に過ぎないにもかかわらず、それほどのものを人間の脳が実現できているのは、ある意味で驚異だと考えられていました。
そういうわけで、「脳には単なるニューラルネットを超える、何らかの秘密が潜んでいるのではないか」「もしかすると、脳の中には未知の物理学的な層のようなものが隠れているのではないか」と想像されていたこともありました。
しかし今やChatGPTによって、私たちは新しい重要な情報を手にしたのです。人工ニューラルネットワークの規模が、人間の脳内のニューロンとほぼ同じ規模の接続数に達すれば、人間の言語を驚くほど見事な形で生成できることがわかったのですから。
この人工ニューラルネットは依然として大規模かつ複雑なシステムであることは確かです。ニューラルネットの重みパラメータ数は、現代世界に出回っているテキストで使われている語数に匹敵しています。
しかし、ある意味では、これほど豊穣な言語と、言語で表現可能な事象のすべてを、高々この程度の有限のシステムに封じ込めることが可能であるというのは、今もにわかには信じがたいことです。
原注
そのシステムの中で起きていることの一部は、まぎれもなく、「計算プロセスは、たとえその基礎となるルールが単純であっても、システムの見かけ上の複雑さが非常に高まる可能性がある」という、普遍的な現象を反映しています。この現象は、私の著書『A New Kind of Science』のルール30の例で初めて明らかにしました。
しかし実際には、本記事のこれまでの章で議論したように、ChatGPTで使われているような種類のニューラルネットでは、トレーニングをしやすくする目的で、そうした現象の影響や、それに関連する計算的還元不可能性(computational irreducibility)の影響を制限する形で構成される傾向があります。
では、ChatGPTのようなものが言語の分野においてこれほどの成果を上げられている理由はどこにあるのでしょうか?
基本的な回答として、言語というものは根本的なレベルにおいて、実は見た目よりもずっと単純である、ということだと私は考えます1。
つまり、ChatGPTは、そのニューラルネット構造が極めて単純であるにもかかわらず、人間の言語と、その背後にある思考の何らかの「本質」を捉えることについては、見事に成功しているということです。さらにChatGPTは、人間の言語(および思考)を実現するための規則性を、「暗黙的な」学習を通じて何らかの形で発見しているのです。
ChatGPTの成功は、科学において、ある根本的かつ重要な証拠を示していると私は考えています。すなわち、今後発見されるべき新たな「言語の重要な法則」や「思考の重要な法則」といったものが、まだどこかに未発見のまま存在する可能性があるということを示しています。
ニューラルネットとして構築されたChatGPTの中にそうした法則が潜んでいるとすれば、そうやって暗黙的に学習したものぐらいしかないでしょう。しかし暗黙の法則を何らかの方法で明確に言語化できれば、ChatGPTが行っていることを、より直接的に、効率よく、しかも透過的・汎用的な方法で実現できるかもしれません。
しかし、それはいったいどんな法則なのでしょうか?
そのような法則が存在するのであれば、最終的に、「言語はどのように構成されているのか」「人間が言語で伝える内容はどのように構成されているのか」を理解するためのヒントを私たちに与えてくれるはずです。これについては今後の章で、「ChatGPTの中を覗き込む」ことでヒントを得られる可能性や、(私がWolfram言語という)計算言語を構築した知見によって示唆される今後の方向性について考察する予定です。
さしあたって今は、「言語の法則」として古くから知られている2つの例を取り上げて、それらがChatGPTの動作とどのように関連しているかを考えていくことにしましょう。
言語の法則例その1は、言語の構文(syntax)です。
言語は、単なる語の寄せ集めではなく、さまざまな種類の語をどのように組み合わせるかについて(かなり)明確な文法規則が存在しているものです。
英語であれば、「名詞の前には形容詞を置ける」「名詞の後ろには動詞を置ける」「ただし2つの名詞を隣り合わせに置くことは正しくないのが普通」といった具合です。
このような文法構造は、(少なくとも近似的には)「構文解析木(parse tree)」と呼ばれるものの組み合わせ方法を定義する一連の規則によってキャプチャできます。
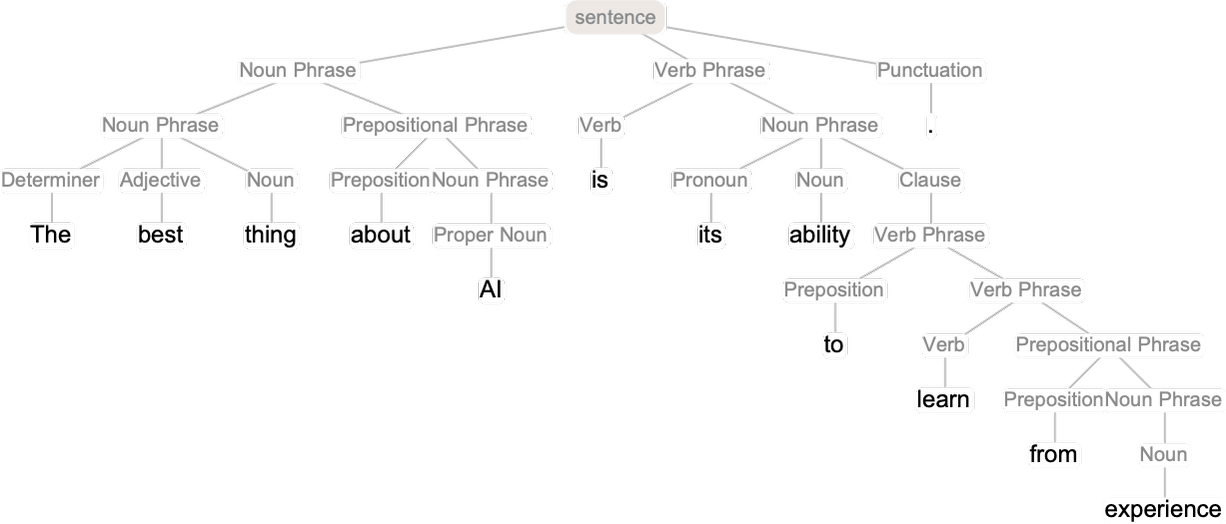
ChatGPTはこのようなルールを「知識として」明示的に人間から教わったわけではありません。しかしChatGPTは、トレーニングを重ねるうちに、そうした文法知識を何らかの形で暗黙的に「発見」していて、しかもそうやって自分で発見した文法知識に従うことが得意らしいのです。
では、学習を通じて文法を暗黙的に学習するしくみは、どのようなものなのでしょうか?「全体像」レベルでははっきりしていませんが、理解を深めるために、もっとシンプルな、単語すら登場しない特殊な言語の例を見てみましょう。
以下のように、開きかっこ(と閉じかっこ)のシーケンス(sequence: 連なり)だけでできた言語を考えてみましょう。この言語には、「開きかっこと閉じかっこが常に対応していなければならないという文法」があるとします。
この構文解析木は、以下のように表現できます。

さて、ニューラルネットをトレーニングすると、この文法に沿った丸かっこの「正しい」シーケンスを自力で生成できるようになるのでしょうか?
ニューラルネットでシーケンスを処理する方法はいろいろありますが、ここではChatGPTでも使われている「Transformerネット」を使うことにしましょう。シンプルなTransformerネットがあれば、文法的に正しい丸かっこのシーケンスをトレーニング用サンプルとして入力できます。
原注
このとき、コンテンツトークン(content tokens)(ここでは(と))の他に、終端を表すEndトークンも含める必要があります。これは、出力がこれ以上続かないことを示します(ChatGPTの場合は、「ストーリーはここで終わり」であることを示します)。これは、人間にもChatGPTにも共通する微妙な点です。
さて、Transformerネットを構築したとします。そのTransformerネットに、「8つのヘッド」「長さ128の特徴ベクトル(feature vector)」2を持つアテンションブロックが1個しかない場合は、この「丸かっこ言語」を十分に学習できないようです。
しかしアテンションブロックを2個に増やすと、少なくともサンプルを1000万個ほど与えれば学習プロセスは収束するようです(Transformerネットによくあることですが、与えるサンプル数をさらに増やすと、パフォーマンスはむしろ悪化するようです)。
つまりTransformerネットワークは、ChatGPTがやっているのと似たような処理を実行可能であり、次にどんなトークンが来るかという確率を丸かっこのシーケンスという形で質問できるのです。
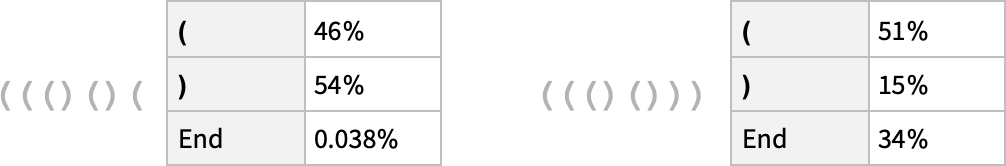
例1(上図の左)では、ネットワークはシーケンスがその位置で終了しないことを確率的に「ほぼ確信している」と言えます。ここで終了してしまうと丸かっこの対応が崩れてしまうので、これは望ましい答えです。
しかし例2(上図の右)では、ネットワークはシーケンスがそこで終了することを「正しく認識しています」が、それと同時に、そこからさらに(と)を追加する形で続行できることも確率の形で「指摘します」。
ここまではよかったのですが、残念ながら、せっかく苦労してトレーニングした約40万個もの重み付きデータを使っても、その続きに来るはずのない閉じかっこ)が来る確率が15%もあると答えています。これでは丸かっこの対応が崩れてしまうので、この答えは正しくありません。
ここで、(のシーケンスを徐々に増やしていったときに、それぞれについて、その続きに来る補完として最も確率が高いのはどんなシーケンスかを尋ねると、以下の結果になります。

たしかに、(のシーケンスをある程度の長さまで増やしているうちは期待通りに動いています。しかしその長さを超えると、ネットワークは正常に動かなくなります。
これはニューラルネット(あるいは機械学習全般)において「精密な」結果を求めようとするときに起きがちな現象です。
人間がひと目でわかるようなものであれば、ニューラルネットでも解けます。
しかし、丸かっこの開きと閉じを明示的に数え上げて対応しているかをチェックするような、アルゴリズム的に精密な処理を行わせようとすると、ニューラルネットでは「計算量が浅すぎる(too computationally shallow)」ため、精密に実行できないのです3。
このことは、ChatGPTなどのAIや、英語などの言語構文においてどのような意味があるのでしょうか?
ここで取り上げた人工的な丸かっこ言語は「厳密」で、普通の言語よりも「アルゴリズム的な要素」がかなり強くなっています。
しかし英語のような自然言語では、そうした厳密さよりも、局所的に選ばれた語やその他のヒントに基づいて、文法的に適合するものを「推測」できる方がずっと現実的です。そしてニューラルネットは、確かにこの点においてはるかに優れています。その代わり、人間でも見逃しそうな「形式的に正しい」ケースについては見落とす可能性もあります。
しかし重要なのは、言語には全体的な構文構造(および、それが示唆するあらゆる規則も含めます)というものが存在していて、そのことが、ある意味でニューラルネットが学習しなければならない「量」を制限していることです。
もうひとつ重要な「自然科学的」観察として、ChatGPTのようなニューラルネットのTransformerアーキテクチャは、入れ子になったツリー上の構文構造をうまく学習できているらしいという点があります。この特性は、あらゆる人間の言語に(少なくともある程度は)存在すると思われます。
構文は、言語にある種の制約を加えますが、文を生成するには構文だけでは足りないことは明らかです。
「好奇心に満ちた電子は魚の代わりに青い理論を食べる(Inquisitive electrons eat blue theories for fish)」といった文章は、いくら文法的に正しくても人間は合格にしないでしょうし、ChatGPTがこんなものを生成したら失敗とみなされるでしょう。文中で使われている語の意味から考えて、これは基本的に無意味な文です。
しかし、そもそも文に意味があるかどうかを機械的に判定する一般的な方法というものは存在するのでしょうか?そのための伝統的かつ包括的な理論は、残念ながら存在しません。しかしChatGPTは、Webから得た数十億もの(おそらく意味のある)文をさんざん学んだ結果、意味のある文を生成するための理論を自分の中に暗黙的に「構築した」と考えられます。
そのような理論が存在するとしたら、どんなものになるでしょうか?基本的に2000年も前から知られている、その名も論理学(logic)というささやかな分野が存在します。そして、アリストテレスが発見した三段論法の形式では、論理学とは基本的に、ある文が特定のパターンに従っていれば妥当であり、従っていなければ妥当でない、とする方法です。
したがって、たとえば「すべてのXはYである。これはYではない。すなわちXではない」というパターンに沿った主張は妥当ということになります(例:「すべての魚は青い。これは青くない。すなわち魚ではない」)。
「きっとアリストテレスは、たくさんのレトリックをサンプルとして(まるで機械学習のように)三段論法を発見したんだろう」と想像するのは自由ですし、それと同じように「ChatGPTもWeb上にある大量のテキストを調べることで三段論法を自力で発見できるだろう」と想像するのも自由です。そこから、ChatGPTが三段論法などに基づいた「正しい推論」を含むテキストを生成できることを期待するのも自由です。
しかしさらに高度で洗練された形式論理となると話はまったく別です。上述の丸かっこ言語で失敗したように、高度で洗練された形式論理についても、首尾一貫した文章の生成には失敗するだろうと私は予想しています。
しかし論理という狭い世界の例を超えたときに、十分に意味のあるテキストをシステマチックに構成する方法について、どんなことが確実に言えるでしょうか?
たしかに、きわめて限定的な「フレーズのテンプレート」を使うMad Libsというテキスト穴埋めゲーム4のようなものは、穴埋めに使う語次第では予想を超えた面白みを感じさせることすらあります。しかし、ChatGPTは一体どのようにしてか、それと同じようなことを非常に汎用性の高い形で実現する方法を、誰も教えていないのに暗黙のうちに身に付けているのです。
そしてChatGPTがそれをどのように実現しているかについては、「ニューラルネットの重みが1750億個ぐらいの規模になると、どういうわけかそうなる」以上のことは、おそらく何も言えないでしょう。しかし私は、その背後には、想像以上にずっとシンプルで、力強いストーリーが隠れているのではないかと睨んでいます。
関連記事
- 訳注: これは、言葉を話したり書いたり読んだりする行為は、情報処理としては一般に思われているほど高度な部類ではない、ということでもあります。 ↩
- 原注: ChatGPTでも長さ128の特徴ベクトルを使っていますが、アテンションブロックは96個もあり、それぞれに96個のヘッドがあります。 ↩
- 原注: ちなみに現時点の完全なChatGPTですら、丸かっこの長いシーケンスの開きと閉じを正しく対応付けるのに苦労しています。 ↩
- 訳注: Wikipedia: Mad Libs、動画: Mad Libs The Game from Looney Labs ↩
概要
原文サイトのCreative Commons BY-NC-SA 4.0を継承する形で翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。原文が長大なので、章ごとに16分割して公開します。
スタイルについては、かっこ書きを注釈にする、図をblockquoteにするなどフォーマットを適宜改善し、文面に適宜強調も加えています。
元記事は、2023年2月の公開時点における、ChatGPTを題材とした生成AIの基本概念について解説したものです。実際の商用AIでは有害コンテンツのフィルタなどさまざまな制御も加えられているため、そうした商用の生成AIが確率をベースとしつつ、確率以外の制御も加わっていることを知っておいてください。
本記事の原文を開いて、そこに掲載されている図版をクリックすると、自分のコンピュータでもすぐに実行して試せるWolfram言語コードが自動的にクリップボードにコピーされるようになっています。
コモンズ証 - 表示 - 非営利 - 継承 4.0 国際 - Creative Commons