こんにちは、hachi8833です。今回は「A Rubyist's Guide to Postgresql's Explain」の翻訳記事をお届けいたします。
EXPLAINはSQLの構文なので、本記事では元記事のタイトルとコードを除き大文字で表記します。
概要
原著者の許諾を得て翻訳・公開いたします。
- 元記事: A Rubyist's Guide to Postgresql's Explain
- 原著者: Starr Horne
- 元サイト: RubyLetter -- 週一ペースで多くの良記事が公開されています。おすすめです。
なお、翻訳では元記事にないコードのハイライトをスクリーンショットとして追加しています。
RubyistのためのPostgreSQL EXPLAINガイド
PostgreSQLにはEXPLAINと呼ばれるささやかな機能があります。ささやかですが、「このところなぜかデータベースクエリが遅い」という問題を解決するうえで最強の武器にもなります。
EXPLAINのしくみは単純です。PostgreSQLにクエリをどのように実行するかを問い合わせると、PostgreSQLがクエリプランを表示してくれます。そのクエリを実際にEXPLAINで実行して、実際のパフォーマンスと比較することもできます。
なかなか使いやすそうだけど?
EXPLAINという機能があることは何となくご存じのRailsエンジニアもいると思います。実はRails 3.2というかなり早い時期から、クエリ実行時間が500msを超えたときに自動的にEXPLAINが実行されるようになっているのです。
問題があるとすれば、EXPLAINの出力が少々込み入ってることぐらいでしょう。出力例として、当サイトのRails開発ブログから出力結果を引っ張ってきました。
% User.where(:id => 1).joins(:posts).explain
EXPLAIN for: SELECT "users".* FROM "users" INNER JOIN "posts" ON "posts"."user_id" = "users"."id" WHERE "users"."id" = 1
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop Left Join (cost=0.00..37.24 rows=8 width=0)
Join Filter: (posts.user_id = users.id)
-> Index Scan using users_pkey on users (cost=0.00..8.27 rows=1 width=4)
Index Cond: (id = 1)
-> Seq Scan on posts (cost=0.00..28.88 rows=8 width=4)
Filter: (posts.user_id = 1)
(6 rows)
さて、この出力から一体何を読み取ればよいのでしょうか?
本記事ではこうした出力結果を解釈する方法をご紹介いたします。特に、クエリがRubyを用いたWeb開発にいかに大きな影響を与えるかという点に重点を置きます。
EXPLAIN出力の構文
既にRailsをお使いであれば、以下のようにActive Recordのクエリに.explainを追加するだけで簡単にEXPLAINを実行できます。
![]()
> User.where(id: 1).explain
User Load (10.0ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 [["id", 1]]
=> EXPLAIN for: SELECT "users".* FROM "users" WHERE "users"."id" = $1 [["id", 1]]
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=812)
Index Cond: (id = 1)
(2 rows)
#explainメソッドはお手軽ですが、PostgreSQLで直接EXPLAINを実行する場合に使える高度なオプションには残念ながらアクセスできません。
PostgreSQLでEXPLAINを直接実行したい場合は、psql -d データベース名でpostgres clientを開き、以下のように実行するだけで済みます。
explain select * from users where id=1;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=812)
Index Cond: (id = 1)
(2 rows)
これで、PostgreSQLがクエリをどのように実行するかというプランの情報を得られます。クエリプランには、実行に要する最短時間の予測も含まれています。
クエリを実際に実行して最短時間の見積もりと比較するには、EXPLAIN ANALYZEを使います。
explain analyze select * from users where id=1;
QUERY PLAN
------------------------------------------------------------------------------------
Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=812) (actual time=0.043..0.044 rows=1 loops=1)
Index Cond: (id = 1)
Total runtime: 0.117 ms
出力結果を読み取る
PostgreSQLはよくできていて、クエリを効率よく実行する可能な限り最適な方法を見つけてくれます。言い換えると、EXPLAINコマンドを実行するだけでPostgreSQLが「クエリプラン」を作って出力してくれるのです。
以下の出力結果を読み取ってみましょう。
# explain select * from users order by created_at limit 10;
QUERY PLAN
-------------------------------------------------------------------------
Limit (cost=892.98..893.01 rows=10 width=812)
-> Sort (cost=892.98..919.16 rows=104 width=812)
Sort Key: created_at
-> Seq Scan on users (cost=0.00..666.71 rows=104 width=812)
(4 rows)
クエリプランは以下の2つの要素で構成されています。
- ノードリスト(node list): クエリ実行に必要な操作(action)の順序を示します
- パフォーマンス予測(performance estimate): リストの各項目の実行にかかるコストを示します
訳注: 以下に追加したスクリーンショットでは、黄色がノードリスト、青がパフォーマンス予測です。

ノードリスト
ノードリスト部分を読みやすくするために、先ほどのクエリプランからパフォーマンス予測を取り除いてみました。
Limit
-> Sort (Sort Key: created_at)
-> Seq Scan on users
ノードリストは、言ってみればPostgreSQLがクエリ実行のために自動生成した一種のプログラムです。この場合はLimit、Sort、Seq Scanという操作を行います。
また、子ノードの出力は親ノードにパイプで接続されます。
このノードリストを仮にRubyで書き換えると次のような感じになります。
all_users.sort(:created_at).limit(10)
PostgreSQLはクエリプランでさまざまな種類の操作を利用します。すべての操作の意味を知っておく必要はないと思いますが、よく使うものを以下にまとめました。
Index Scan- インデックスを利用してレコード(複数可)をフェッチします
Rubyで言うと、ハッシュで項目を検索するような感じです Seq Scan- レコードセットに対してループを回してレコードをフェッチします
Filter- レコードセットから条件を満たすレコードのみを選択します
Sort- レコードセットをソートします
Aggregatecount、max、minといった操作に使われますBitmap Heap Scan- レコードのマッチをビットマップで表現します
論理積や論理和といった操作は、実際のレコードよりもビットマップの方が簡単になることがあります
もちろん、この他にもたくさんの操作があります。
パフォーマンス予測
ノードリスト上の各ノードの後ろには、以下のようにパフォーマンス予測が追加されます。
Limit (cost=892.98..893.01 rows=10 width=812)
各項目の数字の意味は次のとおりです。
cost- 操作の実行に要する作業量を表します
数値に単位はなく、cost間の比較でのみ意味を持ちます rows- 行数の予測値です
操作の実行に必要なループ処理を行う行数の予測値を表します width- 各行のサイズ予測値(単位はバイト)です
筆者の場合、最もよくチェックするのはrowsです。クエリがちゃんとスケールしているかどうかの確認にrowsが大変便利です。
rowsが1の場合: クエリは高い性能を発揮できますrowsがテーブルのレコード数と同じ場合: 巨大なデータセットで性能が落ちる可能性があります
実際のパフォーマンス値
EXPLAIN ANALYZEでクエリを実際に実行すると、次のように数字が2セット表示されます。最初のものは上述のような予測値であり、次のものが実測値です。
訳注: 以下に追加したスクリーンショットでは、青が予測値、緑が実測値です。

# explain analyze select * from users order by created_at limit 10;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Limit (cost=892.98..893.01 rows=10 width=812) (actual time=22.443..22.446 rows=10 loops=1)
-> Sort (cost=892.98..919.16 rows=10471 width=812) (actual time=22.441..22.443 rows=10 loops=1)
Sort Key: created_at
Sort Method: top-N heapsort Memory: 31kB
-> Seq Scan on users (cost=0.00..666.71 rows=10471 width=812) (actual time=0.203..15.221 rows=10472 loops=1)
Total runtime: 22.519 ms
(6 rows)
実測値の項目は次のとおりです。
actual time- 操作の実行に要した時間をmsで表します
rows- 実際に処理した行数です
loops- 操作のループが発生した場合、1より大きな値になります
詳細出力
EXPLAINのデフォルト出力はある程度要約されていますが、必要に応じて詳細な出力も得られます。出力をJSONやYAML形式に整形することもできます。
# EXPLAIN (ANALYZE, FORMAT YAML) select * from users order by created_at limit 10;
QUERY PLAN
------------------------------------------
- Plan: +
Node Type: "Limit" +
Startup Cost: 892.98 +
Total Cost: 893.01 +
Plan Rows: 10 +
Plan Width: 812 +
Actual Startup Time: 12.945 +
Actual Total Time: 12.947 +
Actual Rows: 10 +
Actual Loops: 1 +
Plans: +
- Node Type: "Sort" +
Parent Relationship: "Outer" +
Startup Cost: 892.98 +
Total Cost: 919.16 +
Plan Rows: 10471 +
Plan Width: 812 +
Actual Startup Time: 12.944 +
Actual Total Time: 12.946 +
Actual Rows: 10 +
Actual Loops: 1 +
Sort Key: +
- "created_at" +
Sort Method: "top-N heapsort" +
Sort Space Used: 31 +
Sort Space Type: "Memory" +
Plans: +
- Node Type: "Seq Scan" +
Parent Relationship: "Outer"+
Relation Name: "users" +
Alias: "users" +
Startup Cost: 0.00 +
Total Cost: 666.71 +
Plan Rows: 10471 +
Plan Width: 812 +
Actual Startup Time: 0.008 +
Actual Total Time: 5.823 +
Actual Rows: 10472 +
Actual Loops: 1 +
Triggers: +
Total Runtime: 13.001
(1 row)
上のようにEXPLAIN (ANALYZE, VERBOSE, FORMAT YAML) select ...を使うことで、さらに多くの情報を出力できます。
ビジュアル表示ツール
EXPLAINでは大量の出力が生成されるので、クエリが複雑になると解析作業だけでうんざりしてしまいます。
幸いなことに、解析に便利なフリーのビジュアル表示ツールがいろいろあります。こうしたツールを使ってEXPLAINの出力を解析し、使いやすいダイヤグラムを生成できます。さらに、潜在的なパフォーマンス上の問題までハイライトしてくれます。
以下は筆者が愛用している「Postgres EXPLAIN Visualizer (pev)」というWebサービスのスクリーンショットです。
訳注: 上のサービスには少なくともJSON形式の出力を貼る必要がありました。
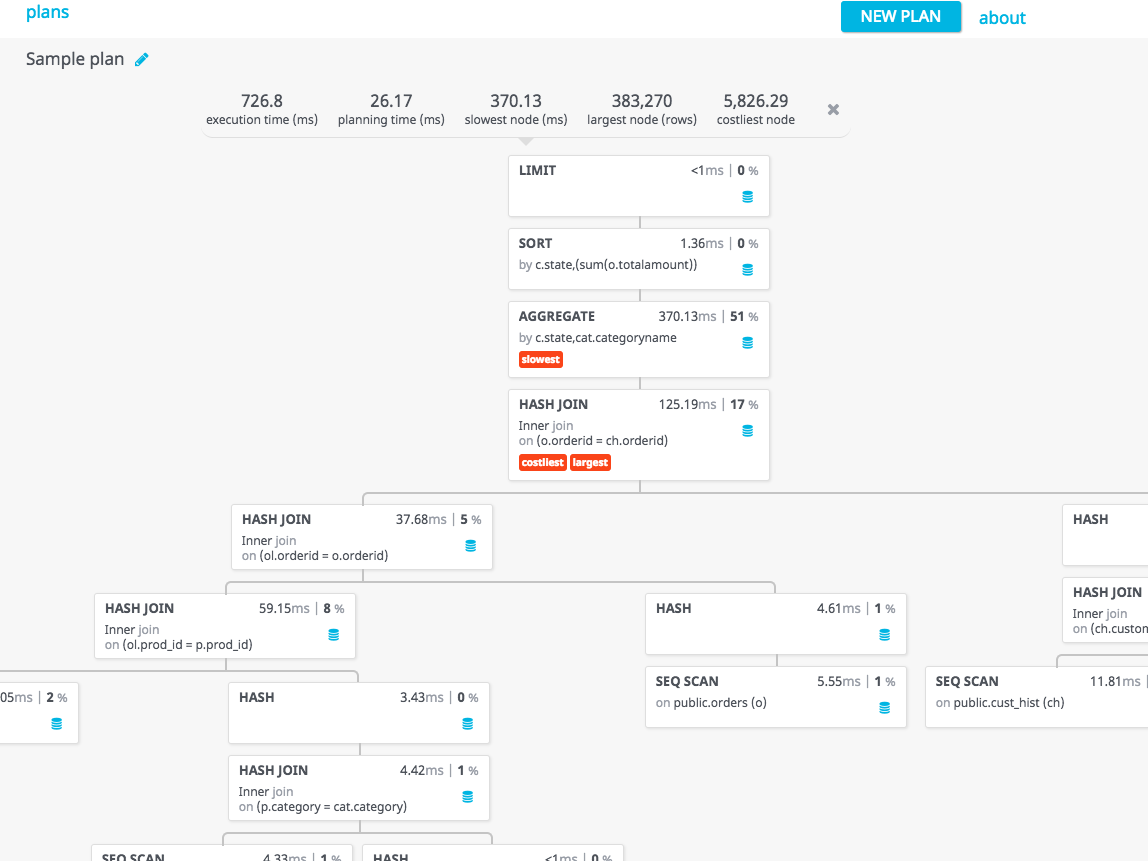
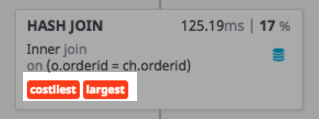
訳注: このツールではクエリの問題点を以下のように赤くハイライトしてくれます。
クエリプランを出力して結果を読み取ってみよう
以下に実例を用意しましたので、実際にやってみましょう。Railsで広く使われている定番コードの中に、スケールしない残念なデータベースクエリを生成するものがいくつもあるのをご存知でしたでしょうか?
#countメソッドの残念なクエリ
以下のようなコードは、Railsアプリのビューで使われまくっています。
Total Faults <%= Fault.count %>
このコードでは次のようなSQLが出力されます。
select count(*) from faults;
さっそくEXPLAINでどうなっているか調べてみましょう。
# explain select count(*) from faults;
QUERY PLAN
-------------------------------------------------------------------
Aggregate (cost=1840.31..1840.32 rows=1 width=0)
-> Seq Scan on faults (cost=0.00..1784.65 rows=22265 width=0)
(2 rows)
こ、これは...!ちっぽけな#countメソッドのクエリで、何と22,265回ものループが発生しています。
この回数はテーブルの行数そのものです。つまり#countメソッドは呼ばれるたびにレコードセット全体をループしているのです。
ソートの問題
フィールドを指定してソートしたリストを取り出す場合、以下のようなコードが非常によく使われています。
Fault.order("created_at desc").limit(10)
取り出すのはたったの10レコードですが、10レコードを取り出すためにテーブル全体のソートが発生します。以下のSortノードにも示されているように、22,265行を処理しなければならなくなります。
# explain select * from faults order by created_at limit 10;
QUERY PLAN
----------------------------------------------------------------------------
Limit (cost=2265.79..2265.81 rows=10 width=1855)
-> Sort (cost=2265.79..2321.45 rows=22265 width=1855)
Sort Key: created_at
-> Seq Scan on faults (cost=0.00..1784.65 rows=22265 width=1855)
インデックスを追加すれば、Sortよりはるかに高速なIndex Scanが使われるようになります。
# CREATE INDEX index_faults_on_created_at ON faults USING btree (created_at);
CREATE INDEX
# explain select * from faults order by created_at limit 10;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Limit (cost=0.29..2.66 rows=10 width=1855)
-> Index Scan using index_faults_on_created_at on faults (cost=0.29..5288.04 rows=22265 width=1855)
(2 rows)
まとめ
本記事が皆さまの役に立ち、EXPLAINコマンドでいろんなことを試してみようという意欲につながれば幸いです。アプリケーションのデータ量が増大したときにアプリがどうスケールするかを理解することは、開発における基本中の基本といってよいでしょう。