概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: How Algolia Built Their Realtime Search as a Service | StackShare
- 原文公開日: 2018年(日付表示なし)
- 著者: Yonas -- StackShareのCEOです。
- サイト: https://stackshare.io/ -- ツールやサービスの新情報や主要なユーザーなどの情報を提供するサービスです。
日本語タイトルは内容に即したものにしました。
インタビューにもあるように、AlgoliaのフロントにはRailsも使われています。
stackshare.ioより
インタビュー: 超高速リアルタイム検索APIサービス「Algolia」の作者が語る高速化の秘訣(翻訳)
原文編集メモ: Nicolas Dessaigne氏はAlgoliaの共同創立者にしてCEOです。Julien LemoineはAlgoliaの共同創立者にしてCTOです。お二人は共にフランスのパリ出身で、現在はカリフォルニア州サンフランシスコ在住です。
Algoliaは、オフライン検索の改善を図るアプリ向けのモバイルSDKとして出発しました。これをネット上の検索サービスとして使いたいという引き合いが複数の顧客から来るようになると、二人は直ちにこの製品は単なるモバイルアプリを凌駕する可能性に気が付きました。今や同社は、Pebble、WeFunder、CodeCombat、HackerNewsといったWebアプリのホストの検索機能を強化しています。私たちはお二人と座ってくつろぎつつ、同社の検索製品と、それを支えるテクノロジーについて学びました。
本インタビューは以下の2つで構成されています。
- Algoliaの立ち上げと、他社技術との違いについて
- Algoliaを支える技術
StackShare(SS): まずはAlgolia創業当時のお話から。このアイデアをどこから得ましたか?
Julien(J): 元々はベイエリアでスタートアップ企業のコンサルティング業務から出発しました。スタートアップ企業のひとつがGoogle App Engineを採用していて、App Engineのインデックス機能を検索機能に用いた開発を進めていたんです。その当時の問題は、App Engineが提供するドキュメント検索機能のつくりが古風で、人の名前や曲のタイトルといったデータベース内の少数のレコードを「入力と同時に」リアルタイム検索するのに向いていなかったのです。私がこれまでに検索エンジンを3つ開発してきたのもあって、このニーズに合うきわめて小規模な検索用データ構造の開発を依頼されました。
Nicolas(N): Julienはかれこれ10年以上も情報取得や自然言語処理に携わってきています。ちなみに私は15年以上ですが。
SS: それほど長期に渡って検索に携わった末に、もっとよい検索手法が必要だとお考えになったんでしょうか?
N: Julienがそのコンサルティング業務で構築した検索エンジンは実に軽量で、これはもしかするとモバイルアプリにうってつけなんじゃないかと気づきました。この直感は、StackOverflowで見かけた「モバイルアプリに検索エンジンを直に埋め込む方法」の大半にまったく回答が付いていないことで裏付けられました。みんなLuceneを埋め込みたいと思いながら、それまで誰ひとり成功していませんでした。それを元にモバイルアプリに埋め込める検索エンジンSDKの開発にゴーサインを出しました。そんなわけで私たちの最初の製品は、実際にはオフライン検索エンジンだったのです。
J: 元々のアイデアは、開発者がこのSDKを自分たちのモバイルアプリで使えるようになればというものでした。特定の検索バックグラウンドを用いずに、数分で自分たちのアプリに統合できるようにしなければならなかったのです。
N: で、この製品をiOS/Android/Windows Phoneで使えるようにすべく、2012年に会社を立ち上げました。実際、技術的にはきわめて大きな成功を収めましたし、多くの開発者が愛用してくれました。しかし、当時はこの製品を売るためのマーケットがなかったのです。
SS: そのSDKはどんな企業に使われていましたか?
N: 基本的にはコンシューマ向けアプリで、オフラインデータを扱うアプリが主でした、旅行ガイドとか。たとえばパリに旅行するとして、実際に現地に到着したら地元の情報をいろいろ見たいのにローミング費用が惜しいとしましょう。ガイド情報をモバイルデバイスにダウンロードしておけば、パリに着いてから自由にオフライン検索できます。これは実に大きな価値をもたらしてくれました。
当時の問題は、開発者(特にAndroid)がSDKにお金を払ってくれる状態ではなかったことです。オフラインデータにがっつり依存するアプリはほとんどありませんし、開発者はSQLiteで超基本的な検索機能を提供することを好むので。
N: それと同時に、多くの人からこの製品で得られるエクスペリエンスに対する好意的な評価がたくさん押し寄せたのですが、どの方もこのエンジンのオンライン版を欲しがりました。オンライン版で自分たちの全データを同じエクスペリエンスで提供したいということだったのです。
私たちが構築した検索エンジンはモバイルを念頭に置いたもので、スマホのキーボードでタイポしまくっても許容してくれる即時検索でした。
しかしこの検索エクスペリエンスの構築は、モバイルアプリ開発に限らず、多くの開発者にとってどうやらあまりに難しかったようです。開発者たちが実際に価値を見出していたのは、REST APIを自分たちのオンラインデータでさくっと使えるようにすることでした。
基本的にはそのタイミングで、私たちは同製品のSaaS版を構築することを決定しました。2013年前半のことです。3月には開発を開始し、多くの好意的な評価を得ました。そしてこの製品が昔から実によくあるひとつの問題を解決していることに気づいたのです。そこからは、製品の差別化に専念し、ドキュメントではなくデータベースをターゲットに定めました。
SS: モバイルアプリが出発点だったからこそ、ドキュメントではなくデータベースに注力したということですね?
N: おっしゃるとおりです。モバイルアプリを手がけたのは、私たちが求めていたデータの性質から言って当然でした。モバイルデバイスで検索するものといえば、連絡先だの位置情報だのといった類です。モバイルデバイスで使いこなしようもない巨大なドキュメントを検索したいなんて思わないでしょう。エンジンはその用途に最適化していて、SaaS版に移行したときもそれと同じコアテクノロジーを用いたわけです。データベース内での全文検索実行は実に良好でした。すなわち私たちのコアバリューは、データベースレコード向けに設計・最適化されたエンジンの価値にあります。これまで構築してきたものは例外なく、常にデータベースを目標に据えることを念頭に置いています。
SS: エクスペリエンスという観点において、御社の製品が従来のものとどう異なるかをご説明いただいてもよろしいでしょうか?より高速なデータベース検索結果のあたりを中心に、相違点とか、お二人がどうお考えになっているかについて。
N: はい、その違いについて語る人は多くはありませんので、違いをきっちり説明することが重要ですね。多くの検索エンジンは、ドキュメントを対象として設計されているのです。
どういうことかというと、たとえば検索結果をランキングするのであればドキュメントを対象に設計されたランキング規則を使うことになるわけです。このランキングでは、各ドキュメント内のクエリに出現する用語数をカウントし、TF-IDFに基いて統計処理を行います。入力したクエリの用語をなるべく多く含むドキュメントを上位のランクにしたいというわけです。つまりこれは、ドキュメント単位のスコアを生成する統計公式の一種です。このスコアは少々謎めいていて、公式を微調整することで多少ましにはなるものの、最終的に得られるスコアは理解が非常に困難です。ドキュメント向け検索エンジンとして使い物になるよう公式を調整するのは実に困難です。さらに、単語が完全なら問題なく動作するのですが、語の入力途中など、語の冒頭部分ではうまく動きません。
このあたりを適切に修正するには多少のハックが必要です。
J: これは、莫大なテキストを抱えているWikipediaのようなWebページなど、巨大なテキストを検索対象として設計されていたためでした。そのような場合ならこうした統計手法を用いるのは自然です。私たちのようにデータベースを対象とする場合は、まったく異なります。たった1つのシンプルな製品名を検索するだけなら、そうした制約はありません。
N: 対象データが違うのですから、結果のランキング手法も根本的に異なるものを用いる必要がありました。どちらかというと、人間が考えるときの方法に近いやりかたです。たとえば、eコマースWebサイトでiPhoneを1件検索するとしましょう。欲しい結果は、iPhoneという単語を含むタイトルであって、説明文の末尾にあるiPhoneという単語ではないでしょう。つまり、出現回数よりも、その語が結果内のどの位置にあるのかという情報の方がずっとずっと重要なのです。
さらに、iPhone 3Gの検索結果なんか欲しくもないでしょう。欲しいとすれば一番人気の最新型iPhone 5Sです。データベースの対象をこうした点に絞り込むメリットは、この種の情報に配慮できるところです。これは、ドキュメント向け検索エンジンではきわめて困難です。
さらに、クエリで明らかにスペルミスしたときなんかには他の要素にも気を利かせて欲しいものです。eコマースの会社であれば、そんなときに売上一位の製品をトップに表示して欲しいでしょうし、こうしたさまざまな要素の一切合財を組み合わせて欲しいでしょう。こうした組み合わせはあまりに複雑なので、ドキュメント向け検索エンジンでは手に余ります。そこで私たちは、こうした多くの判断基準のすべてを極めて明確な手法によって面倒を見る、新種のアプローチを開発しました。検索で得られる結果セットがそのようになった理由や、そのようにランキングされた理由は、誰でもひと目で理解できます。
SS: その大半はカスタマイズされたものですよね?大半は御社のアプリに特化した形で。具体的にはどんなふうにやっていますか?
J: 他のエンジンと比べて、カスタマイズは本当に楽です。他のソリューションならカスタマイズ項目が数千件にのぼりますが、私たちのはほんのちょっとです。カスタマイズが楽勝でできますし、お客様のデータを元に優秀な検索エクスペリエンスを構築する方法もきちんと説明できます。
N: デフォルトのランキングは、ユースケースの90%で良好な結果を示しています。良好な検索結果を得るには、基本的には次の2つの設定を行います。
- インデックス化したいさまざまな属性の重要度を指定する。たとえば、製品名の方が説明文やコメントよりも重要度が高い、とか。
-
対象の人気指標(popularity)を定義する。たとえば売上個数とか、「いいね!」の数とか。
この2つを設定すれば、既にこのうえもなく良好な妥当性を誇る検索エンジンを基本的に手にすることができます。
J: たとえば、シリーズもののTV番組を検索するエンジンのデモページをユースケースのひとつとして公開しています。1番目の設定では俳優の名前よりTV番組名の方が重要であること、2番目の設定では人気指標としてフォロワー数を定義してあります。この2つを設定しておけば、後はキーを数回打つだけで的確な結果が飛び出してきます。
N: これだけではありません。たとえば入力に応じて一致する分野名を表示したいのであれば、APIからそれ用の高度な設定を得られます。管理インターフェイスもあるので、あらゆる設定はオンラインで完了します。
SS: 凄いですね!次はそれを支える技術についてお願いします。
J: 基本的には大きく2つの部分に分けられます。顧客が使うAPIと、管理インターフェイスの使えるWebサイトです。この2つのアーキテクチャは大きく異なっています。
このサービスのWebサイトや管理インターフェイスを最初に見てみると、UIがRailsとBootstrapで構築されているのがわかります。ホスティング先として、AWSのRDS(MySQL)とEC2を複数のavailability zoneに配置し、ELBでロードバランシングしています。私たちのAWSインスタンスはUS-Eastに配置されており、さらに全アセットをCloudFrontに保存して、世界中どこからでも素晴らしいエクスペリエンスを提供できるようにしています。
J: ダッシュボードでのデータのナビゲーションや利用については、JavaScriptクライアント経由で弊社独自のREST APIを利用しています。ここではAPIから直接取得した分析情報や利用状況の情報もリアルタイムで表示しています。
APIサーバーの方ですが、こちらではリアルタイムデータの一部をRedisに保存し、最新の相互API呼び出しのログを取っています。APIのカウントもリアルタイムで保存しているので、何か操作を行うたびにRedisのカウンタが増加してリアルタイム情報を提供できるしくみになっています。
SS: そのあたりのデータ保存方法についてもう少し詳しくお願いします。
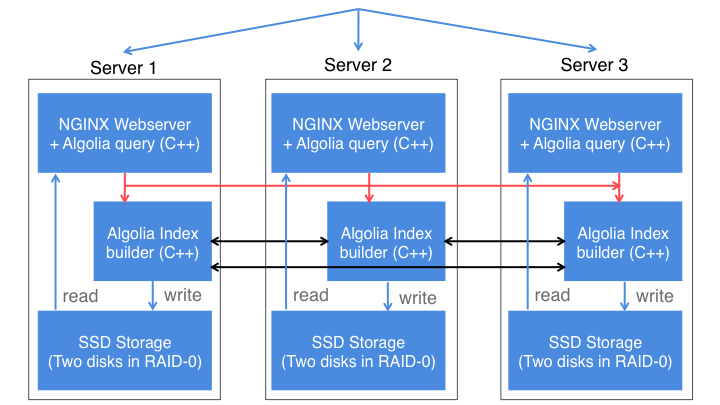
J: ユーザーがデータを私たちのAPIに送信すると、私たちの側では3つの異なるホスト(いずれもAPIサーバー)にデータをレプリケーションします。インデックス作成もそれぞれのホストで独自に行われます。同期を確認するために、RAFTと呼ばれる一種のコンセンサスアルゴリズムを用いています。これはPaxosアルゴリズムの一種でもあります(訳注: いずれもブロックチェーン方面で使われることの多いアルゴリズムです)。
これと同種のアルゴリズムが、Amazon S3やGoogle App Engineでも用いられています。3つの異なるクラスタが完全に同期していることを確認する必要があります。その中のひとつがときおりダウンするとか再起動するなどの事態が発生したとしても、同期が完全であることを確認できなければなりません。
APIに書き込み操作を行うと、3つの異なるサーバーに送信し、この書き込みのトランザクションのIDが影響を受けます。このIDは、コンセンサス(アルゴリズム)によって決定される3つのホストからなるクラスタ全体に渡ってカウントアップされる整数です。このAPIを呼び出すと、ジョブが少なくとも2つのホストに書き込まれた時点でタスクIDが1つ返されます。これにより、ジョブがインデックス化されるタイミングをこのタスクIDでチェックできるようになります。
訳注: 原文では画像リンク切れのため、画像検索で復元しました。以降の画像も同様です。
N: データがレプリケーション完了したことはもちろん、それが完全に同じ順序になっていることも確認しなければなりません。つまり、3つのホストはいついかなる場合であっても同期し、ステートも同じでなければならないのです。
J: これは高可用性のために行っています。ホストの1つがダウンしようと、プロバイダのavailability zoneがダウンしようと、サービスが動き続ける必要があります。つまりS3とまったく同様、常にどれかが動き続けられるようにするために同じ情報を3回レプリケーションしているのです。
この冗長性はパフォーマンス上のためでもあります。というのも、3つの異なるホスト全体でクエリを共有しているからです。たとえば1秒間に1000件のクエリを受信すると、各ホストに33%ずつクエリを送信する形になります。
私たちの検索エンジンはC++モジュールになっており、Nginxに直接埋め込まれています。つまりクエリがNginxに到達すると、そこで検索エンジンが走って結果をクライアントに送り返すのです。
処理速度を落とすような層は存在しません。システムはこのクエリのために徹底的に最適化されています。
SS: データを送信してから戻ってくるまでの流れを説明していただけますか?
J: 私たちはデータセンターごとにクラスタを配置しており、各クラスタは3つの異なるホストで構成されています。私たちのクラスタの大半はマルチテナント型で、複数クライアントをホストします。
使っているのは極めてハイエンドなコンピュータです。基本的に1サーバーあたり256GBのRAM、1TBのRAID-0 SSD、16コア(3.5GHz以上)を用いています。私たちはEC2に頼ることはせず、複数のプロバイダで専用サーバーを運用しています。
クラスタに関連して、通信帯域幅もがっつり確保しています。1クラスタあたりの専用帯域幅は4.5Gbpsとなっており、これもサービスの品質を高く保ちたいがためです。究極のサービスを提供するため、ハードウェアや帯域幅については一切妥協しませんでした。
各インデックスは、弊社独自のフォーマットを持つ1つのバイナリファイルです。情報は特定の順序を保ってここに保存されており、インデックスへのクエリは極めて高速です。このアルゴリズムは私たちがモバイルで培ったものです。
弊社のNginx向けC++モジュールは、このインデックスファイルをメモリマップモードで直接オープンし、Nginxの異なるプロセス間でメモリを共有して、クエリをメモリマップデータ構造に適用できるようにしています。
ロードバランシングを異なる3つのサーバー間で行うため、APIクライアントコード(JavaScriptなど)内で直接ロードバランシングを行っています。埋め込まれているこのJavaScriptコードはサーバーをランダムにひとつ選択し、必要に応じて別のサーバーにフェイルオーバーします。

N: ロケット科学のようなものではありませんが、ハードウェアによるロードバランサーのSPOF(単一障害点)を回避するうまい手法です。弊社のAPIクライアントはMITライセンスでGitHub上に公開されていますので、github.com/algoliaで誰でもご覧いただけますよ。
APIのユーザーは、自分たちのバックエンドのプログラミング言語に合ったAPIクライアントを用いることができます。おすすめの利用法は、このAPIクライアントをインデックス作成やデータのプッシュに用いることです。ただしクエリの実行にはWebアプリケーション向けのJavaScriptクライアント(またはiOSではObjective-C、Windows PhoneならC#)を用いることを強くおすすめいたします。これは、エンドユーザーのブラウザから弊社のサーバーにクエリを直接送信することで途中のホップでの速度低下を回避するためです。
J: これは、極めて良好なパフォーマンスを得るための方法のひとつです。私たちはNginx層でありとあらゆる最適化を施しました。しかし途中に別の層(APIユーザー独自のサーバーなど)が挟まってしまうと、このエクスペリエンスは得られなくなります。そうしたわけで、私たちとしてはぜひともJavaScriptクライアントをお使いいただきたいのです。
SS: ジョブをインデックス化するキューみたいなものはありますか?
J: 正確にはキューではなく、コンセンサスですね。Nginxからのインデックス化ジョブを受け取るビルダープロセスがサーバーごとにあります。インデックス化ジョブを1つ追加すると、ジョブを受け取ったNginxが3つの異なるビルダープロセスに送信してコンセンサスを起動します。言ってみれば、一意のIDを持つ3つの異なるビルダー間で「投票」を行っているわけです。そしてコンセンサスはある種の「選挙」アルゴリズムを元にしていて、どの時点においてもマスターとなるビルダーが1つ、スレーブとなるビルダーが2つ必要です。マスターがダウンすると、生き残りの2つのスレーブ同士が自動的に投票を行ってマスターを選出します。マスターは一意のIDを割り当て、インデックス化キュー内の一時ジョブをすべてのビルダーに移動します。3つのホストのうち2つがこの操作を完了すると、ユーザーに応答を通知します。こうしたID割り当てに使えるオープンソースソフトウェアがあり、その中でもよく知られているのがApache Zookeeperです。Zookeeperの薄い層をクラスタの分散情報に用いることができます。つまり、たとえばクラスタ内でどれがマスターであるかという情報を共有できるわけです。
Zookeeperの問題は、トポロジーが変更されたときの検出に長時間かかる可能性がある点です。たとえばあるホストがダウンすると、検出までに何10秒もかかるかもしれません。1秒間に数千件ものインデックス化ジョブをクラスタで処理するのですから、これでは時間がかかりすぎですし、それらを処理するためにIDを指定するマスターが必要です。そこで弊社ではRAFTをベースに独自の選挙アルゴリズムを構築しました。このアルゴリズムによって、3つの異なるホスト全体で一貫している1つのIDアロケータを持つことができました。このリーダーがダウンすれば、数ms以内に別のリーダーが選出されます。
デプロイも実に簡単で、ビルドプロセスをkillしてシグナルを送ることでNginxをホットリロードします。ビルドプロセスをkillすることで選挙アルゴリズムを常に自動テストしているので、テストのためにホストの停止を待つことはしません。このアプローチはproductionのプロセスをランダムに停止するという点でNetflixのChaos Monkeyに似ています。
SS: なるほど。データをインデックス化する方法を万全にしてからクエリをかけるということですね。
J: 弊社のアーキテクチャにはさらに3番目の要素があります。productionでは重要ではありませんが、テストで重要な要素です。
SS: お、ちょうど御社のビルド/デプロイ/テストプロセスについてお話を伺おうと思っていたところでした。
J: 弊社が提供するAPIステータスページには、サービスの測定結果がリアルタイムで表示されます。このためにGoogle App Engine上で動作するプローブを開発しました。これらのプローブはすべてのクラスタに対して常にインデックス化やクエリを実行し続け、あらゆる問題を自動で検出します。
弊社では特定ユーザー向けに専用のステータスページも提供しています。たとえばHacker News様専用ページです。もちろん自社インフラを抱える大企業のお客様も対照としています。お客様が専用サーバーをお求めの場合は、こうした専用ステータスページも合わせてご提供しております。
それからデプロイですね。GitHubには3つのコードをプッシュしています。主にAPIクライアント向けに、単体テストやリグレッションテスト(non-regression test)のセットを備えたCIも用意しています。どのテストもTravis CIを用いてコミット時に適用されます。コード品質についてはCode Climate、カバレッジについてはCoverallsをそれぞれ用いています。
production向けには、デプロイ前に大規模な単体テストやリグレッションテストを自動適用するデプロイスクリプトも用意しています。また、バージョンが新しくなって問題が発生した場合に自動でロールバックするスクリプトもあります。
SS: ということはstaging環境もありますか?
J: はい。弊社にはテスト専用のクラスタが1つあります。productionアプリは多岐にわたるため、重要なproductionクラスタの他に、staging用のクラスタもあります。
N: アップデートの重要度によっては、最も重要なクラスタでは動かしません。
J: 現時点では、弊社の検索でダウンタイムが生じたことはありません。2013年のサービス開始以来、インデックス化で8分間の問題が1度生じたきりで、ほぼ40億件に近いAPI呼び出しをこなしてきました。
N: このダウンタイムも本当にインデックス化の部分だけで検索は影響を受けませんでしたし、しかも生じたのは1つのクラスタだけでしたので、すべてのお客様に影響が生じたわけではありません。その8分間に影響を受けた可能性のあるお客様は15〜20社ほどでしたでしょうか。これらのお客様に即座に連絡を取ったところ、20社のうち問題の発生に気づいたのはわずか2社で、しかも弊社の迅速な対応にむしろお喜びいただけました。
J: 弊社の透明性を信じています。弊社は、発生した問題と解決方法についてきちんと説明したいと考えました。
N: そこで事後報告としてブログ記事を1本書きました。
SS: ログ機能も提供しているんですか?
J: 弊社ではユーザーの直近のログ、直近のエラーログ、そしてカウンタをRedisに保存しています。実際のAPIサーバーでは、どのユーザーについても直近のアクティビティだけを保存しています。その後弊社は、ユーザーのダッシュボードに統計情報や分析結果を表示するためにすべてのログを処理する専用クラスタを設置しました。
N: 分析は2種類あります。まず、ダッシュボードにその日のレスポンスタイムを表示するための生分析があり、そこではレスポンスタイムの他に、レスポンスタイムの99%パーセンタイルも表示されます。
現在、クエリのコンテンツを対象とするより高レベルの分析にも取り組んでいます。最も頻度の高いクエリ、結果抜きで最も頻度の高いクエリなどを知ることができるというものです。現在作業中ですが、いずれお目にかけられるはずです。
SS: 監視についてですが、皆さんはどういったサーバー監視をお使いですか?
J: 弊社のサーバー監視にはServer Densityを用いています。フロントエンド側にはCloudWatchも使っています。
SS: 他にお使いのサービスなどありましたらどうぞ。
N: 各クラスタにはホストが3つずつ配置されていますが、ヨーロッパ/米国/アジアなどさまざまな地域のデータセンターにまたがる検索も行います。この検索はこうしたさまざまなデータセンターに分散可能です。したがって、エンドユーザーからのクエリは最寄りの地域にあるクラスタに投げられます。これにはAWSのRoute 53を用いています。
J: はい、これはエンドユーザーの地理上の位置に強く依存していて、Route 53が最寄りのサーバーを検出してユーザーをそちらに導くのです。弊社Webサイトにあるデモではまさにこれを行っているので、常に良好なレスポンスタイムを体験できます。
J: ダッシュボード内では、Intercomを用いてユーザーが学べるようにしています。メトリクスの成長のトラッキングや、隘路内の改善可能な手順の特定にはGoogle AnalyticsやKISSmetricsを使っています。
社内ではHipChatを使っていて、例外発生時や新規サインアップ時や支払い時などのデータがすべてダンプされる専用のチャットルームがあります。とりたてて珍しいことではありませんが、HipChatはユーザーサポートにも活用しています。弊社Webサイトを開けば、私たちとチャットできるようになっています。チャットルームでは、大勢のユーザーが同じチャットルームに同時参加できます。私たちはここでお客様とチャットし、時にはコードをハイライト付きでそこに投げることもあります。開発者のサポートにはなかなかよいと思います。
プローブが問題を検出したときのSMS送信にはTwilio、支払いにはStripeをそれぞれ使っています。この他にも便利なサービスをいろいろ使っています(Algoliaで使われている全サービスのリストについてはこちらを参照)。
SS: 他にもまだ説明いただいていない、重要かつ非常に有用なオープンソースツールがもしありましたらどうぞ。
J: Google SparseHashライブラリはかなり使っていますね。このライブラリは極めて低レベルかつ高パフォーマンスのハッシュテーブルで、低レベルのC++コードでは全面的に使っています。効率の高さは凄いですよ。
オープンソースのライブラリは他にも山ほど使っています。全部リストアップしたら相当な長さになるでしょうね😀。
その他に、開発者のコミュニティへの支援もささやかながら行っています。つい最近はDepstackで支援を行いました。これは人気の高いライブラリを検索したり投票したりできるサイトです(訳注: depstack.ioはサイトがありませんでした)。このときは、さまざまな言語(Ruby、Python、Goなど)について検索できるさまざまなライブラリをすべてインデックス化する作業を裏方として行いました。皆さんもGitHubアカウントでサインアップすればライブラリに投票できますよ。また、どのGitHubプロジェクトがどのライブラリを用いているかを検出してそれらへの投票をカウントすることも行っています。
このように、誰でも利用頻度の高いベストなライブラリを見つけられるよう作業しています。
SS: クールですね!ぐっと親しみが湧いてきました😀。
J: Depstackなどでコミュニティを率先してサポートする作業は今後も続けます。そうそう、弊社のAlgoliaはコミュニティのプロジェクトに無償で提供しているんですよ。
Algoliaユーザーによる全レビューはこちらでご覧いただけます
