- #1 処理時間とレスポンス時間
- #2 バッチ処理とオンライン処理(本記事)
- #3 バッチ処理を設計するときの注意点
- #4 オンライン処理とUXの工夫
- #5 Railsのジョブ管理システムと注意点
- #6 バッチ処理ですぐに使えるノウハウ、まとめ
「バッチ処理」と「オンライン処理」の違いを理解する

バッチ処理とオンライン処理は対になる考え方です。
バッチ処理

ある程度の量のデータをまとめて処理することを「バッチ処理」と呼びます。「一括処理」と呼ばれることもあります。
バッチ処理はある程度(数分〜数時間)時間のかかる処理に用いられるため、案件にもよりますが、一般にある程度長めの処理時間が許容されます(もちろん顧客への説明と了解も必要です)。計算量の多い処理や、日次/月次/年次といった締め処理は多くの場合バッチ処理で行われます。
「数時間かかるバッチなら営業時間が始まるまでに終了して欲しい」「1時間に1回実行するバッチなら数分または数秒以内で終わって欲しい」などがよくあるパターンです。
バッチ処理の場合、実行結果や経過の表示はシンプルにログファイルや終了時通知を用いることがよくあります。その分ユーザーにとっては見えにくいものになります。
オンライン処理
ユーザーからのリクエストをその場で処理して処理結果を返すことを「オンライン処理」と呼びます。情報処理試験などでは「対話型処理」という用語が使われることもあります。
ユーザーは結果が返されるのを待つため、短時間で処理を終えることが求められます。Webアプリの場合、ほとんどのユーザー操作がこのオンライン処理に相当しますので、処理に時間がかかるとユーザーエクスペリエンスが低下します。
現在はコンピュータの速度が向上したこともあって、Webアプリに限らず、昨今はほとんどの処理をオンライン処理として実装することが求められるようになっています。
なお、コンピュータサイエンス(CS)系のOS分野では、リアルタイム処理という用語を厳密に「実時間処理」という意味で使います。その文脈では、単に応答が速いだけでは多くの場合リアルタイム処理とは言えず、たとえば「この処理は1msec以内に必ず応答を返す」というように応答時間の保証を伴います。
僕はOS系の研究室にいたのでどうしてもオンラインリアルタイム処理をリアルタイムと略すのに抵抗を感じてしまいます 💦
# 「Linux」じゃなくて「GNU/Linux」と呼べ!みたいなもんです。多分
補足「非同期処理」とは

SPA(シングルページアプリケーション)などで多用される非同期処理は、バッチ処理とオンライン処理の両方の特徴を備えています。
ここでいう同期とは「(処理の完了を)待つ」ということです。つまり非同期は「処理の完了を待たずに、相手に任せて次の処理に進む」ということになります。
Railsでは、バックグラウンドジョブの非同期処理のためにRedisやSidekiqなどを使うこともよくあります。
※非同期処理の終了確認の方法が必要で、RedisにはPush通知機能(Pub/Sub)があります
たとえばAjaxによるブラウザ操作の非同期処理は、ユーザー側から見ればすぐ次の操作を行えるのでオンライン処理的ですが、サーバー側にとっては呼び出されたした別リクエストは裏でバッチ的に処理されるので、両方のいいとこ取りとも言えます。しかし非同期処理を実装するには、オンライン処理とバッチ処理の両方を理解する必要がありますし、Ajaxを含む非同期処理は難易度も上がり工数も増えることに留意しましょう。
非同期処理は正常系だけ見ればどうってことないのですが、例外処理を考え始めると途端に考えることが増えます。
代表的なものだけでも以下のようなものがあります。
* ユーザーが非同期処理の実行中にブラウザウィンドウを閉じてしまったら処理結果はどうする?
* バッチ的な処理の場合、同じ処理を複数(または同じ)ユーザーが同時に実行してしまったらどうする?(定時バッチと違い、複数同時実行のケアが必要)
* 長い非同期処理を走らせる場合、非同期処理のWorker数やタイムアウトの設定はどうする?(長い処理が他の非同期処理をブロックしてしまう可能性がある)
* 非同期処理の実行状態をどのように管理する?エラー処理は?
ここに挙げたものはサーバー側の非同期処理の話ですが、フロントエンド側もSPAになるとフロントエンド側の非同期処理(Service Worker利用など)も出てきてさらに複雑になってきます。
基本的には非同期処理よりも同期処理の方がシンプルで考えることが少なく、バグも作り込みにくいです。初心者であれば、まずは多少動いてなくても影響の小さそうな処理から非同期処理の実装を初めて見るのが無難かと思います。
「バッチ処理」と「オンライン処理」のどちらを選ぶべきか

戦略としては、基本として「オンライン処理」を選択します。
Webシステムでは「何か操作を行ったらすぐに反応を得られる」というユーザーエクスペリエンスが求められるのが普通ですし、オンライン処理ではリクエスト/レスポンスの中ですべての処理が完結するのでバッチ処理に比べてずっとエラーを追いかけやすいなど、メリットが圧倒的に大きくなります。
たとえばWebアプリの入力フォームから確認フォームへの遷移でエラーが発生したのであれば、どこでエラーが発生したのかがすぐ見当が付きます。
バッチでエラーが発生した場合、たとえばバリデーションのエラーなのかコミット時のエラーなのかを調べるにはコードやログを追いかける必要があります。
バッチ処理は、オンライン処理では実現が難しい場合にはじめて検討します。
- オンライン処理を高速化するための事前処理
- オンライン処理では難しい大規模なトランザクション処理(伝票の月次締め処理など)
- 外部APIとの接続にバッチ処理が指定されている場合
この辺りは開発の経験をどのような環境で積んできたかによって、エンジニアによっても意見が分かれるところかと思います。
なんでもバッチ処理に寄せたがるエンジニアもいれば、バッチ処理でもよさそうなこと(定時処理など)をオンライン処理から実行させるような設計を好むエンジニアもおり、この辺りは価値観により千差万別です。
ここで挙げた「基本はオンライン処理」は恐らく一般的と思われる設計方針ですが、システムの性質、ユーザーの慣れているUI、フレームワークやライブラリとの相性などによってもどのやり方がベストになるかは変わります。
色々な選択肢がある中で、今開発しているシステムにはどのような設計が適してるのかを考えて選ぶ力がシステムアーキテクトには求められます。
「オフラインバッチ」と「オンラインバッチ」
バッチ処理は、さらに「オフラインバッチ」と「オンラインバッチ」の2種類に分けられます。
(1)オフラインバッチ
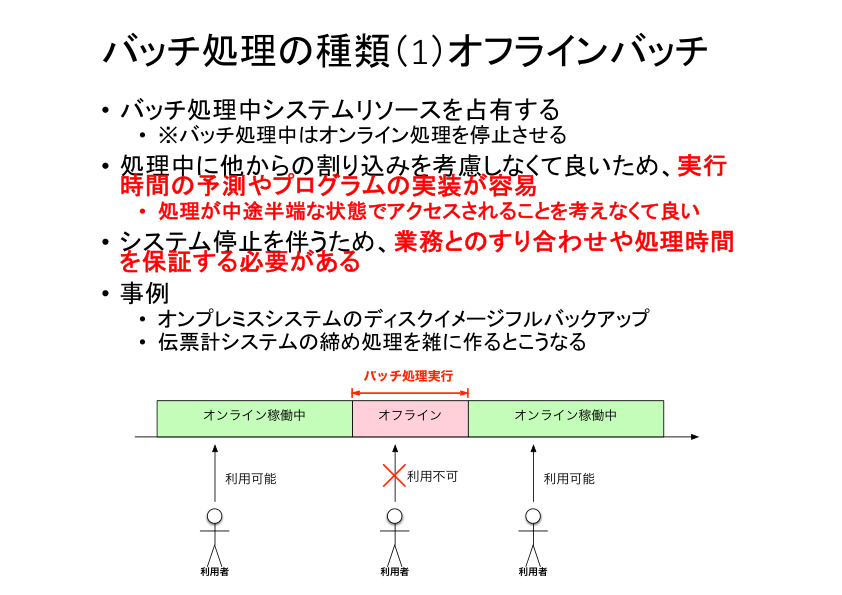
オフラインバッチは最も直接的なバッチ処理の形態です。バッチ処理の間はオンライン処理を停止しておき、バッチがシステムリソースを安全に専有できるようにします。
オンライン処理に邪魔される心配がないため、安全かつ実装しやすく、実行時間も予測しやすいという大きなメリットがあります。
バッチの同時実行がない環境であれば、バッチ処理中のデータ競合を気にしなくてよいため、DBのロックをそこまで意識せずにバッチを書くことも可能です(失敗時ロールバックの考慮は必要)。ディレクトリの下の多数のファイルを書き込み/更新するなどの処理でも、作業中のファイルロックやファイルの追加を気にせずに済みます。
その代り、顧客がオンライン処理の停止を許容しなければこの戦略は使えません。昨今のWebサービスは年中無休で運用されることが増えているので、以前に比べてオフラインバッチは行いにくい傾向があります。オフラインバッチを許容してもらえる見込みがあるなら、頑張って交渉しましょう。
オフラインバッチはその時間サービスが止まるので、ユーザーにとって不便が生じますが、「メンテナンス時間」を設けることで安全にバッチ処理を行えるようにする戦略も検討の余地があります。
例えばJR東日本のえきねっとは今でも(2018年11月)毎日システムが一部利用できないメンテナンス時間があります。20世紀のWebシステムではこうした毎日メンテナンスを行うシステムも多く、社会的に受け入れられていましたが、昨今ではこうしたシステムは「普通」ではなく「不便」と言われるようになりました。
堅い系システムの代表格である銀行系ですら、最近全銀の他行振込が24時間に対応しましたので、システムに関する常識というのは変わっていくものだなあとしみじみ感じます(おっさん感
とはいえ、日本で営業時間にしか使われないシステムであれば今でもオフラインバッチは現役なので、システムの複雑さを下げる一つの手段としては手札に持っておくと良いでしょう。
(2)オンラインバッチ
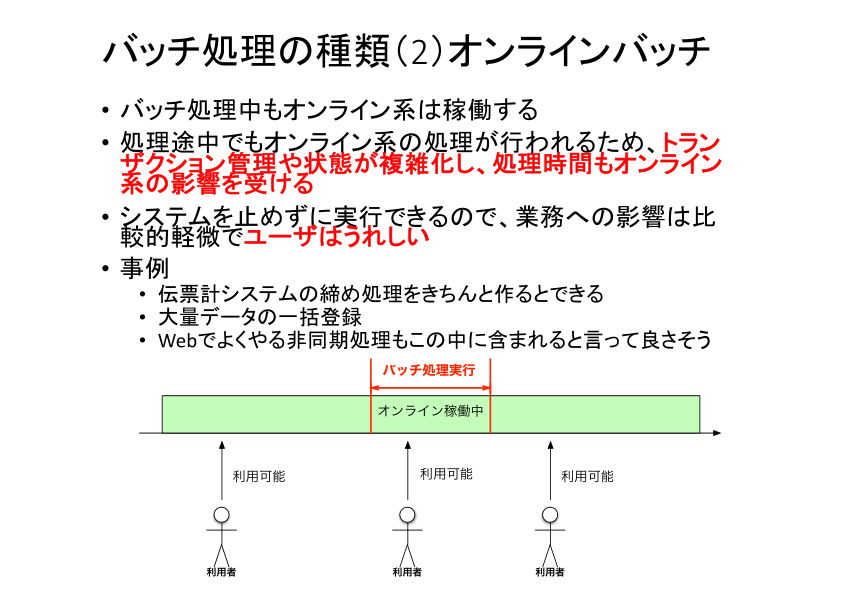
オンラインバッチは上と対照的に、オンライン系を停止せずに実行します。
サービスが停止しない前提なのでユーザーや顧客にとってはメリットがあります。
その代りオフラインバッチに比べて考慮点が増えるため、難易度は上がります。バッチ処理中にもトランザクションや状態を綿密に管理しなければならなくなるため複雑になりますし、オンライン処理に影響されて実行時間も予測しづらくなります。
きちんと設計と、バッチ処理中に発生したデータやファイルの変更や増減を取りこぼす可能性があります。処理中に消されたファイルを開こうとしてエラーで落ちるというのはありがちなシナリオです。
なおWebでの非同期処理は、オンラインバッチの一種とみなすこともできます。
処理時間が数秒程度と短いうちはオフラインバッチとオンラインバッチでそれほど実際の影響が出ることは少ないのですが、オンラインバッチは時間が長くなればなるほどデータ不整合が障害が発生する可能性が上がります。
また、運用開始時は処理時間が短くても、数年運用するうちに処理時間が長くなり、今までたまたま踏んでなかったバグを踏むようになるというケースもわりとあるあるな話なので、設計時には注意しましょう。
- #1 処理時間とレスポンス時間
- #2 バッチ処理とオンライン処理(本記事)
- #3 バッチ処理を設計するときの注意点
- #4 オンライン処理とUXの工夫
- #5 Railsのジョブ管理システムと注意点
- #6 バッチ処理ですぐに使えるノウハウ、まとめ
おたより発掘
この連載よくまとまってて良い:) / Webのバッチ処理とオンライン処理のポイントとシステムの応答性能を学ぶ#2(社内勉強会) https://t.co/PLJRaFRB6T
— ごまてゃんさん (@gomachan46) January 9, 2019
バッチ処理で最も一般的なのはCronなどによる定時実行(毎日1時に実行、など)です。
複雑な要件になってくるとジョブネット(次回以降解説予定)などの待ち合わせ処理も出てきたりしますが、どうしても必要な場合以外はあまりバッチの実行条件を複雑にしない方が良いことが多いです。
なぜなら、バッチ処理は大抵とても大事な処理を扱うので、複雑であることはそのままオペレーションミスに繋がる可能性があるからです。
典型的なユースケースとして「毎日の注文一覧を集計してメールする」というバッチ処理があった場合「注文が0件だった場合にはメール送信しない」という条件をつけると一件管理者にとって便利に思えますが、この仕様にしてしまうと**バッチ自体が失敗したのとの区別がつかなくなってしまいます**。
こうした「うまく動かなかったときに大きな問題となる機能」についてはオンライン処理でも同じですが、多少慎重すぎるくらいにログや通知を設計しておくのが良いでしょう。